






神经网络分类是一种机器学习技术,用于对数据进行分类预测。它模仿人类大脑的工作原理,通过构建多层次的神经元网络来学习输入数据之间的复杂关系,并在训练过程中调整网络参数,使其能够准确地将输入数据映射到相应的类别。
神经网络分类通常包括以下关键步骤:
-
数据准备:收集和准备带有标签的数据集,确保每个样本都有对应的类别标签。
-
网络设计:选择合适的神经网络结构,包括输入层、隐藏层(可以有多个)和输出层。每一层都由多个神经元组成,神经元之间通过连接权重进行信息传递。
-
数据预处理:对输入数据进行预处理操作,如归一化、标准化、特征提取等,以便更好地训练神经网络模型。
-
网络训练:使用训练数据集来训练神经网络模型。通过反向传播算法不断调整网络中的权重和偏置,使得网络能够逐渐学习到数据的特征和规律。
-
网络评估:使用独立的测试数据集来评估训练好的神经网络模型的性能。通常包括计算分类准确率、混淆矩阵、精确率和召回率等指标。
-
模型应用:当模型训练和评估完成后,可以将其应用于新的未知数据,进行分类预测。
神经网络分类具有较强的非线性拟合能力和适应能力,可以处理复杂的数据关系和大规模数据集。它被广泛应用于图像识别、语音识别、自然语言处理等领域,并在许多实际应用中取得了良好的效果。
总的来说,神经网络分类是一种强大的机器学习技术,通过构建多层次的神经元网络来实现对数据的分类预测,具有广泛的应用前景和潜力,其和神经网络预测有点类似的,也是要输入大量训练数据,用误差来调节权值,有所区别的是使用到的。
在神经网络分类中,通常使用交叉熵损失函数(cross-entropy loss function)来衡量模型输出与真实标签之间的差异,同时使用softmax激活函数来将神经网络的输出转换为表示类别概率的形式。
在神经网络预测中,则通常使用均方误差(mean squared error)或其他回归损失函数来衡量模型输出与真实数值之间的差异。
在训练过程中,两者也有些微的差异,比如在数据预处理和评估指标的选择上可能会有所不同,但总体上来说,它们使用的算法是相似的,主要集中在神经网络的设计和训练上。
代码部分:
clc
clear
%这里的是matlabt提供红酒案例,在工作区会生成红酒178个案例有着13个特征的输入
%,每个案例都对应一个分类,这里分类成了三种红酒类别
load wine_dataset.mat %下载案例数据
input1 =wineInputs;
input = sparse(input1); % 将输入数据转换为稀疏格式
output=wineTargets;
for i=1:1:size(wineTargets,2)%size的用法是算出数组大小的,返回行和列的数目,2是返回列的数,总为178
output1(i) = find(wineTargets(:,i) == max(wineTargets(:,i)));%这里的作用就是把编码化为10进制的
end
output2=output1';%把列转置为行
winInput =wineInputs';%对把列转置为行
res=[winInput,output2];%把输入特征的和输出结果合并在一起
%%上述的转置合并,如果数据的行是特征值,列表示的是样本数,最后一列的是结果就不需要转置了
temp=randperm(178);%用于打乱数据集
%选择训练集数据,一般选取70%,这里有178个,所以测试样本为124个,
P_train = res(temp(1:124),1:13)';
T_train = res(temp(1:124),14)';%训练结果
M = size(P_train,2); %获取训练集的数目
%测试集
P_test = res(temp(125:end),1:13)';
T_test = res(temp(125:end),14)';%训练结果
N = size(P_test,2); %获取测试集的数目
%数据归一化
[p_train,ps_input]=mapminmax(P_train,0,1);
p_test =mapminmax('apply',P_test,ps_input);
t_train =ind2vec(T_train);%把数字编码化为010的形式
t_test =ind2vec(T_test );
%建立模型
net = newff(p_train, t_train, 6, {'tansig', 'logsig'}); % 设置隐藏层激活函数为tansig,输出层激活函数为logsig
% 设置输出层激活函数为softmax,损失函数为交叉熵损失函数
net.layers{end}.transferFcn = 'softmax';
net.performFcn = 'crossentropy';
%% 设置训练参数
net.trainParam.epochs =1000;%最大迭代次数
net.trainParam.goal=1e-6;%最大选代次数%目标训练误
net.trainParam.lr=0.01;% 学习率
% 训练网络
net =train(net,p_train,t_train);
%% 仿真测试
t_sim1 = sim(net,p_train);
t_sim2 = sim(net,p_test);
%% 数据反归一化
T_sim1 = vec2ind(t_sim1);
T_sim2 = vec2ind(t_sim2);
%数据排序
[T_train, index_1]= sort(T_train);
[T_test ,index_2]=sort(T_test );
T_sim1 =T_sim1(index_1);
T_sim2 =T_sim2(index_2);
%性能评价
error1 = sum((T_sim1 == T_train))/M*100;
error2 = sum((T_sim2 == T_test))/N*100;
%创建图表来观测准确率
figure
plot(1:M,T_train,'r-',1:M,T_sim1,'b-o','Linewidth',1)
legend('真实值','预测值')
xlabel('预测样本')
ylabel('预测结果')
str = sprintf('训练集预测结果对比\n准确率=%.2f%%', error1);
title(str)
xlim([1,N])
grid
%下列的是对训练好的模型输入新的数据进行分类
x = res(177, 1:13); %这个是截取了训练数据的输入
%下面是根据一个输入样本进行修改了的
x1=[14.77,4.39, 5.28,19.5,86,2.39,1.51, 0.48,0.64,9.8,1.57,1.2,450];
new_data_normalized = mapminmax('apply', x1', ps_input);
% 使用训练好的网络模型对新数据进行仿真测试
predicted_output = sim(net, new_data_normalized);
% 将仿真结果进行反归一化处理,得到最终预测结果
predicted_class = vec2ind(predicted_output);
disp('预测结果:');
disp(predicted_class);
运行结果:
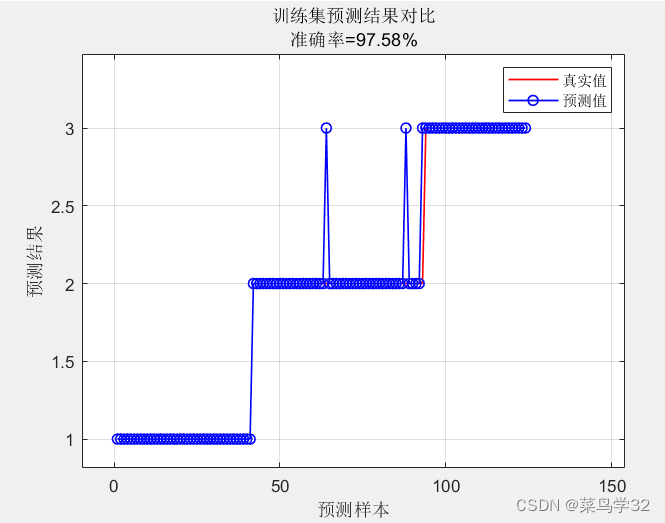
在124个训练样本训练出来的模型,用52个测试样本验证,准确率可达97.58%,准确率还是可以的。
使用新的且为和测试数据相近的数据输入到这个模型,也可以很好进行分类
















 5638
5638











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









