






简要介绍图中的优化算法,编程实现并2D可视化
1. 被优化函数 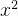
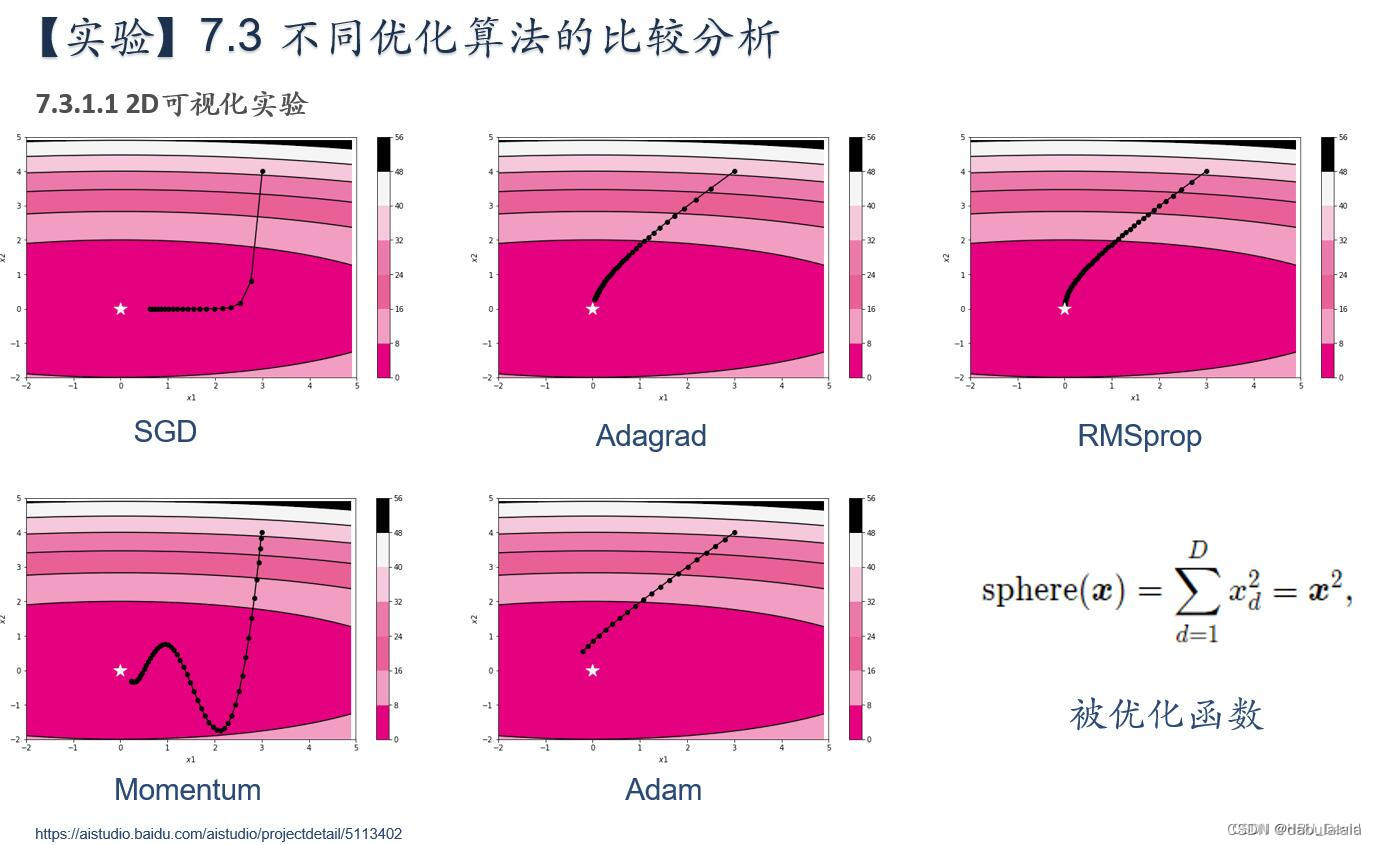
(1)SGD(随机梯度下降法)
每次迭代采集1个随机样本
from nndl.op import Op
import torch
import numpy as np
from matplotlib import pyplot as plt
from nndl.opitimizer import SimpleBatchGD
# 被优化函数
class OptimizedFunction(Op):
def __init__(self, w):
super(OptimizedFunction, self).__init__()
self.w = w
self.params = {'x': 0}
self.grads = {'x': 0}
def forward(self, x):
self.params['x'] = x
return torch.matmul(self.w.T, torch.tensor(torch.square(self.params['x']), dtype=torch.float32))
def backward(self):
self.grads['x'] = 2 * torch.multiply(self.w.T, self.params['x'])
# SGD梯度更新
import copy
def train_f(model, optimizer, x_init, epoch):
x = x_init
all_x = []
losses = []
for i in range(epoch):
all_x.append(copy.copy(x.numpy()))
loss = model(x)
losses.append(loss)
model.backward()
optimizer.step()
x = model.params['x']
print(all_x)
return torch.tensor(all_x), losses
# 可视化
class Visualization(object):
def __init__(self):
"""
初始化可视化类
"""
# 只画出参数x1和x2在区间[-5, 5]的曲线部分
x1 = np.arange(-5, 5, 0.1)
x2 = np.arange(-5, 5, 0.1)
x1, x2 = np.meshgrid(x1, x2)
self.init_x = torch.tensor([x1, x2])
def plot_2d(self, model, x, fig_name):
"""
可视化参数更新轨迹
"""
fig, ax = plt.subplots(figsize=(10, 6))
cp = ax.contourf(self.init_x[0], self.init_x[1], model(self.init_x.transpose(0, 1)),
colors=['#e4007f', '#f19ec2', '#e86096', '#eb7aaa', '#f6c8dc', '#f5f5f5', '#000000'])
c = ax.contour(self.init_x[0], self.init_x[1], model(self.init_x.transpose(0, 1)), colors='black')
cbar = fig.colorbar(cp)
ax.plot(x[:, 0], x[:, 1], '-o', color='#000000')
ax.plot(0, 'r*', markersize=18, color='#fefefe')
ax.set_xlabel('$x1$')
ax.set_ylabel('$x2$')
ax.set_xlim((-2, 5))
ax.set_ylim((-2, 5))
plt.savefig(fig_name)
plt.show()
def train_and_plot_f(model, optimizer, epoch, fig_name):
"""
训练模型并可视化参数更新轨迹
"""
# 设置x的初始值
x_init = torch.tensor([3, 4], dtype=torch.float32)
print('x1 initiate: {}, x2 initiate: {}'.format(x_init[0].numpy(), x_init[1].numpy()))
x, losses = train_f(model, optimizer, x_init, epoch)
print(x)
losses = np.array(losses)
# 展示x1、x2的更新轨迹
vis = Visualization()
vis.plot_2d(model, x, fig_name)
# 固定随机种子
torch.manual_seed(0)
w = torch.tensor([0.2, 2])
model = OptimizedFunction(w)
opt = SimpleBatchGD(init_lr=0.2, model=model)
train_and_plot_f(model, opt, epoch=20, fig_name='opti-vis-para.pdf')
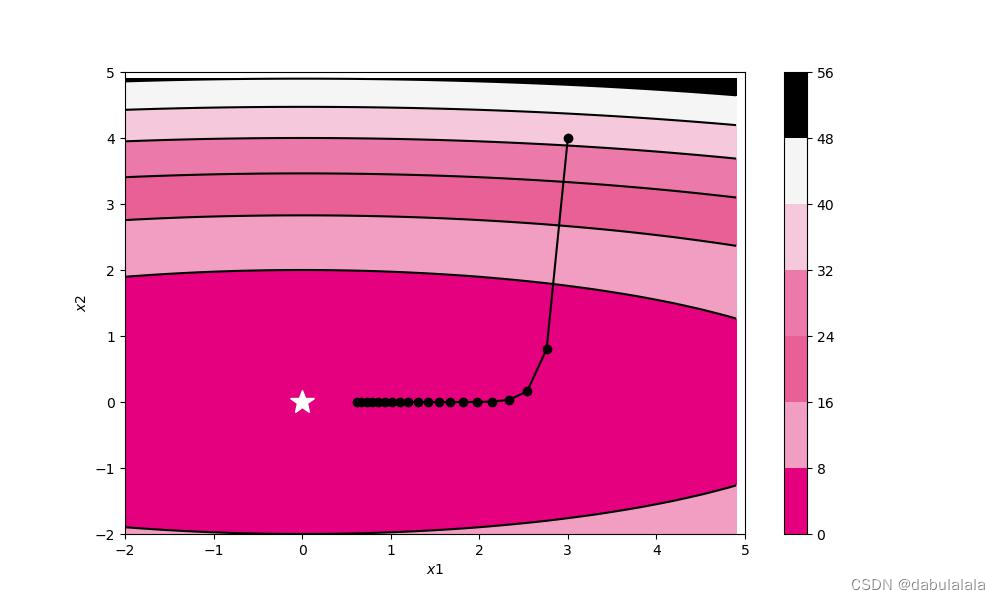
(2)AdaGrad(自适应梯度算法)
借鉴正则化的思想,每次迭代时自适应地调整每个参数的学习率。
如果某个参数的偏导数累计比较大,其学习率相对较小
如果某个参数的偏导数累计比较小,其学习率相对较大
这意味着按参数的元素进行学习率衰减,可以使变动大的参数学习率逐渐减小
class Adagrad(Optimizer):
def __init__(self, init_lr, model, epsilon):
"""
Adagrad 优化器初始化
输入:
- init_lr: 初始学习率
- model:模型,model.params存储模型参数值
- epsilon:保持数值稳定性而设置的非常小的常数
"""
super(Adagrad, self).__init__(init_lr=init_lr, model=model)
self.G = {}
for key in self.model.params.keys():
self.G[key] = 0
self.epsilon = epsilon
def adagrad(self, x, gradient_x, G, init_lr):
"""
adagrad算法更新参数,G为参数梯度平方的累计值。
"""
G += gradient_x ** 2
x -= init_lr / torch.sqrt(G + self.epsilon) * gradient_x
return x, G
def step(self):
"""
参数更新
"""
for key in self.model.params.keys():
self.model.params[key], self.G[key] = self.adagrad(self.model.params[key],
self.model.grads[key],
self.G[key],
self.init_lr)
torch.manual_seed(0)
w = torch.tensor([0.2, 2])
model = OptimizedFunction(w)
opt = Adagrad(init_lr=0.5, model=model, epsilon=1e-7)
train_and_plot_f(model, opt, epoch=50, fig_name='opti-vis-para2.pdf')
plt.show()
(3)RMSprop(均方根传递法)
计算每次迭代梯度平方的指数衰减移动平均
与AdaGrad的区别:梯度更新值的计算由累计方式变成了指数衰减移动平均
在鱼书上有:RMSprop不再将所有的梯度进行一视同仁的相加,而是逐渐地遗忘过去的梯度,在做加法运算时将新梯度的信息更多的反应出来。
class RMSprop(Optimizer):
def __init__(self, init_lr, model, beta, epsilon):
"""
RMSprop优化器初始化
输入:
- init_lr:初始学习率
- model:模型,model.params存储模型参数值
- beta:衰减率
- epsilon:保持数值稳定性而设置的常数
"""
super(RMSprop, self).__init__(init_lr=init_lr, model=model)
self.G = {}
for key in self.model.params.keys():
self.G[key] = 0
self.beta = beta
self.epsilon = epsilon
def rmsprop(self, x, gradient_x, G, init_lr):
"""
rmsprop算法更新参数,G为迭代梯度平方的加权移动平均
"""
G = self.beta * G + (1 - self.beta) * gradient_x ** 2
x -= init_lr / torch.sqrt(G + self.epsilon) * gradient_x
return x, G
def step(self):
"""参数更新"""
for key in self.model.params.keys():
self.model.params[key], self.G[key] = self.rmsprop(self.model.params[key],
self.model.grads[key],
self.G[key],
self.init_lr)
# 固定随机种子
torch.manual_seed(0)
w = torch.tensor([0.2, 2])
model = OptimizedFunction(w)
opt = RMSprop(init_lr=0.1, model=model, beta=0.9, epsilon=1e-7)
train_and_plot_f(model, opt, epoch=50, fig_name='opti-vis-para3.pdf')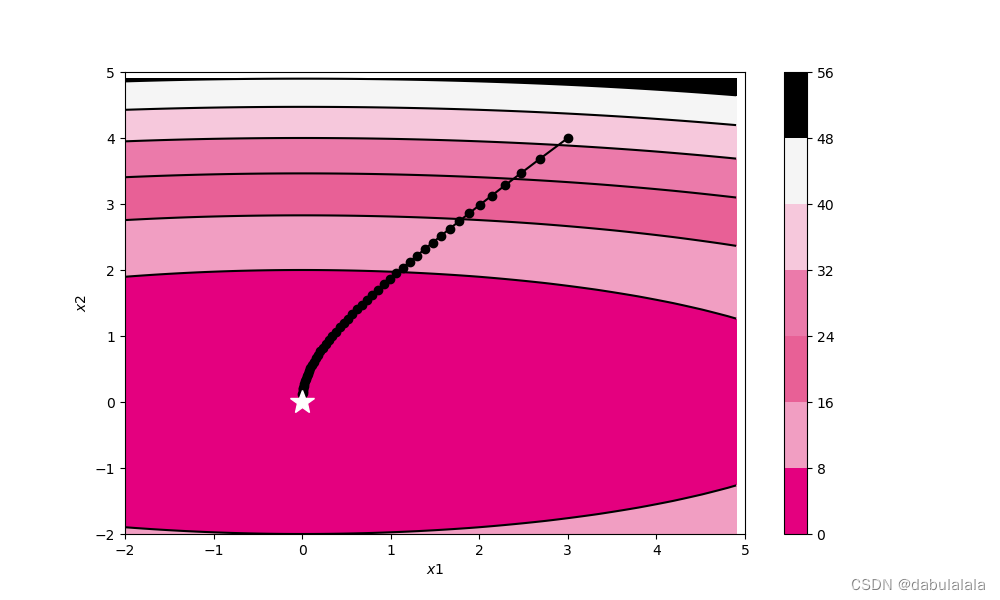
(4)Momentum(动量法)
用之前积累动量代替真正的梯度
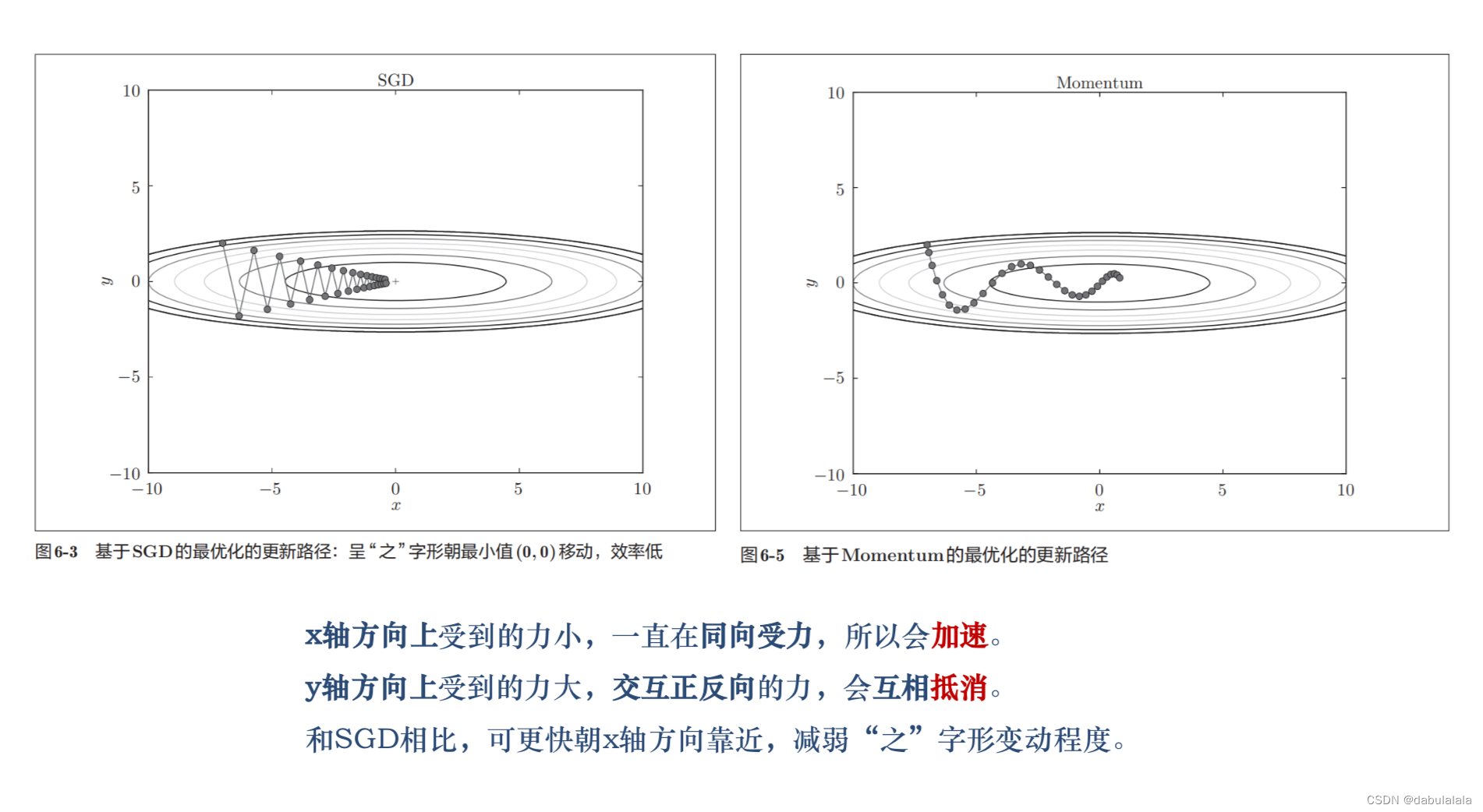
在迭代时,计算负梯度的指数加权移动平均作为参数的更新方向
某个参数在最近一段时间内的梯度方向:
不一致:参数更新幅度变小,动量法会起到减速作用,增加稳定性,减少震荡。
一致:参数更新幅度变大,动量法会起到加速作用,可以更快地到达最优点。
动量法的梯度更新方式,类似于力的叠加
class Momentum(Optimizer):
def __init__(self, init_lr, model, rho):
"""
Momentum优化器初始化
输入:
- init_lr:初始学习率
- model:模型,model.params存储模型参数值
- rho:动量因子
"""
super(Momentum, self).__init__(init_lr=init_lr, model=model)
self.delta_x = {}
for key in self.model.params.keys():
self.delta_x[key] = 0
self.rho = rho
def momentum(self, x, gradient_x, delta_x, init_lr):
"""
momentum算法更新参数,delta_x为梯度的加权移动平均
"""
delta_x = self.rho * delta_x - init_lr * gradient_x
x += delta_x
return x, delta_x
def step(self):
"""参数更新"""
for key in self.model.params.keys():
self.model.params[key], self.delta_x[key] = self.momentum(self.model.params[key],
self.model.grads[key],
self.delta_x[key],
self.init_lr)
# 固定随机种子
torch.manual_seed(0)
w = torch.tensor([0.2, 2])
model = OptimizedFunction(w)
opt = Momentum(init_lr=0.01, model=model, rho=0.9)
train_and_plot_f(model, opt, epoch=50, fig_name='opti-vis-para4.pdf')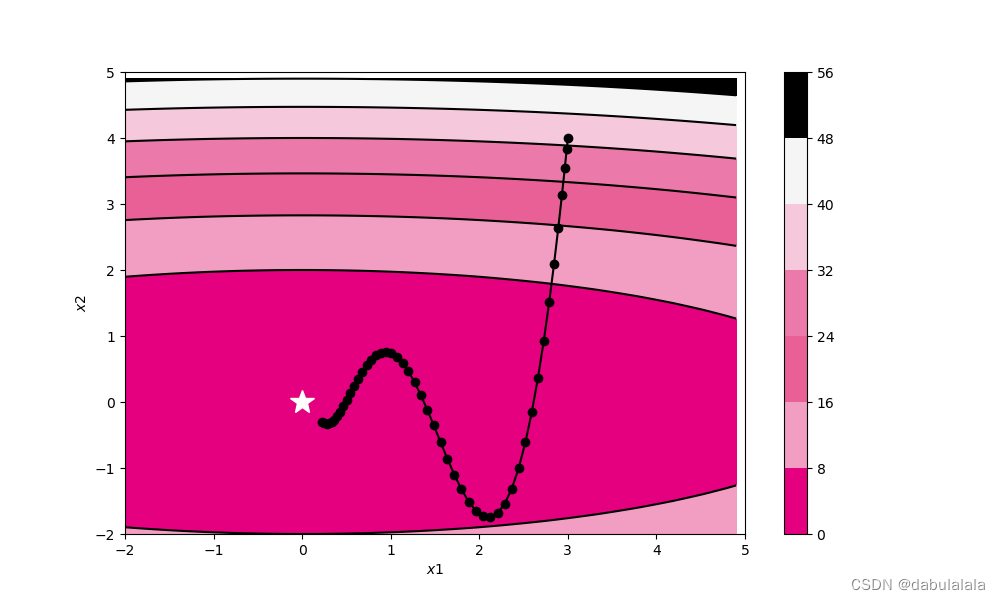
(5)Adam(自适应矩估计)
可以看作是动量法和 RMSprop 法的结合,不但使用动量作为参数更新方向,而
且可以自适应调整学习率。
class Adam(Optimizer):
def __init__(self, init_lr, model, beta1, beta2, epsilon):
"""
Adam优化器初始化
输入:
- init_lr:初始学习率
- model:模型,model.params存储模型参数值
- beta1, beta2:移动平均的衰减率
- epsilon:保持数值稳定性而设置的常数
"""
super(Adam, self).__init__(init_lr=init_lr, model=model)
self.beta1 = beta1
self.beta2 = beta2
self.epsilon = epsilon
self.M, self.G = {}, {}
for key in self.model.params.keys():
self.M[key] = 0
self.G[key] = 0
self.t = 1
def adam(self, x, gradient_x, G, M, t, init_lr):
"""
adam算法更新参数
输入:
- x:参数
- G:梯度平方的加权移动平均
- M:梯度的加权移动平均
- t:迭代次数
- init_lr:初始学习率
"""
M = self.beta1 * M + (1 - self.beta1) * gradient_x
G = self.beta2 * G + (1 - self.beta2) * gradient_x ** 2
M_hat = M / (1 - self.beta1 ** t)
G_hat = G / (1 - self.beta2 ** t)
t += 1
x -= init_lr / torch.sqrt(G_hat + self.epsilon) * M_hat
return x, G, M, t
def step(self):
"""参数更新"""
for key in self.model.params.keys():
self.model.params[key], self.G[key], self.M[key], self.t = self.adam(self.model.params[key],
self.model.grads[key],
self.G[key],
self.M[key],
self.t,
self.init_lr)
# 固定随机种子
torch.manual_seed(0)
w = torch.tensor([0.2, 2])
model = OptimizedFunction(w)
opt = Adam(init_lr=0.2, model=model, beta1=0.9, beta2=0.99, epsilon=1e-7)
train_and_plot_f(model, opt, epoch=20, fig_name='opti-vis-para5.pdf')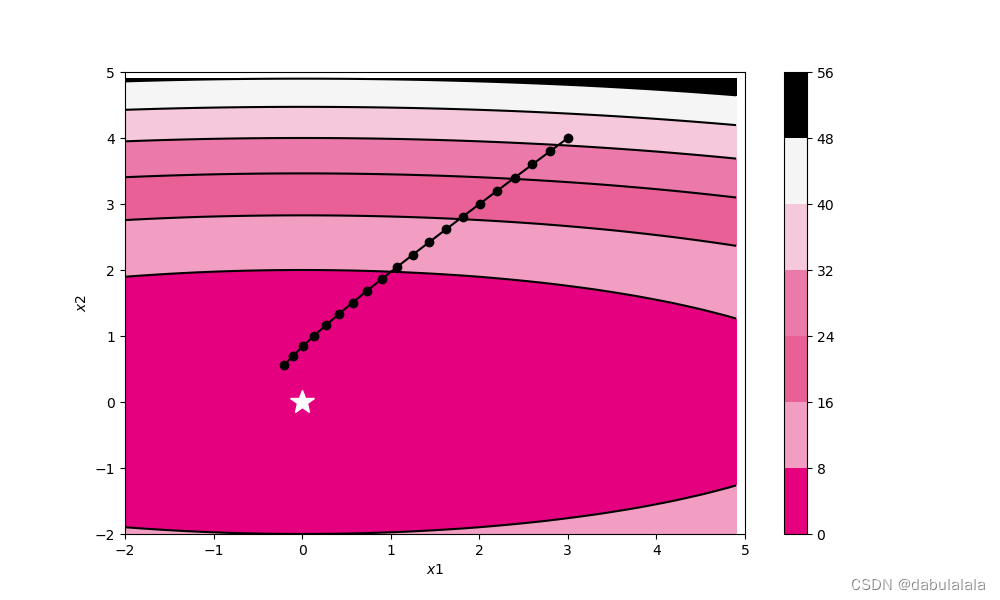
2. 被优化函数 
# coding: utf-8
import numpy as np
import matplotlib.pyplot as plt
from collections import OrderedDict
class SGD:
"""随机梯度下降法(Stochastic Gradient Descent)"""
def __init__(self, lr=0.01):
self.lr = lr
def update(self, params, grads):
for key in params.keys():
params[key] -= self.lr * grads[key]
class Momentum:
"""Momentum SGD"""
def __init__(self, lr=0.01, momentum=0.9):
self.lr = lr
self.momentum = momentum
self.v = None
def update(self, params, grads):
if self.v is None:
self.v = {}
for key, val in params.items():
self.v[key] = np.zeros_like(val)
for key in params.keys():
self.v[key] = self.momentum * self.v[key] - self.lr * grads[key]
params[key] += self.v[key]
class Nesterov:
"""Nesterov's Accelerated Gradient (http://arxiv.org/abs/1212.0901)"""
def __init__(self, lr=0.01, momentum=0.9):
self.lr = lr
self.momentum = momentum
self.v = None
def update(self, params, grads):
if self.v is None:
self.v = {}
for key, val in params.items():
self.v[key] = np.zeros_like(val)
for key in params.keys():
self.v[key] *= self.momentum
self.v[key] -= self.lr * grads[key]
params[key] += self.momentum * self.momentum * self.v[key]
params[key] -= (1 + self.momentum) * self.lr * grads[key]
class AdaGrad:
"""AdaGrad"""
def __init__(self, lr=0.01):
self.lr = lr
self.h = None
def update(self, params, grads):
if self.h is None:
self.h = {}
for key, val in params.items():
self.h[key] = np.zeros_like(val)
for key in params.keys():
self.h[key] += grads[key] * grads[key]
params[key] -= self.lr * grads[key] / (np.sqrt(self.h[key]) + 1e-7)
class RMSprop:
"""RMSprop"""
def __init__(self, lr=0.01, decay_rate=0.99):
self.lr = lr
self.decay_rate = decay_rate
self.h = None
def update(self, params, grads):
if self.h is None:
self.h = {}
for key, val in params.items():
self.h[key] = np.zeros_like(val)
for key in params.keys():
self.h[key] *= self.decay_rate
self.h[key] += (1 - self.decay_rate) * grads[key] * grads[key]
params[key] -= self.lr * grads[key] / (np.sqrt(self.h[key]) + 1e-7)
class Adam:
"""Adam (http://arxiv.org/abs/1412.6980v8)"""
def __init__(self, lr=0.001, beta1=0.9, beta2=0.999):
self.lr = lr
self.beta1 = beta1
self.beta2 = beta2
self.iter = 0
self.m = None
self.v = None
def update(self, params, grads):
if self.m is None:
self.m, self.v = {}, {}
for key, val in params.items():
self.m[key] = np.zeros_like(val)
self.v[key] = np.zeros_like(val)
self.iter += 1
lr_t = self.lr * np.sqrt(1.0 - self.beta2 ** self.iter) / (1.0 - self.beta1 ** self.iter)
for key in params.keys():
self.m[key] += (1 - self.beta1) * (grads[key] - self.m[key])
self.v[key] += (1 - self.beta2) * (grads[key] ** 2 - self.v[key])
params[key] -= lr_t * self.m[key] / (np.sqrt(self.v[key]) + 1e-7)
def f(x, y):
return x ** 2 / 20.0 + y ** 2
def df(x, y):
return x / 10.0, 2.0 * y
init_pos = (-7.0, 2.0)
params = {}
params['x'], params['y'] = init_pos[0], init_pos[1]
grads = {}
grads['x'], grads['y'] = 0, 0
learningrate = [0.9, 0.3, 0.3, 0.6, 0.6, 0.6, 0.6]
optimizers = OrderedDict()
optimizers["SGD"] = SGD(lr=learningrate[0])
optimizers["Momentum"] = Momentum(lr=learningrate[1])
optimizers["Nesterov"] = Nesterov(lr=learningrate[2])
optimizers["AdaGrad"] = AdaGrad(lr=learningrate[3])
optimizers["RMSprop"] = RMSprop(lr=learningrate[4])
optimizers["Adam"] = Adam(lr=learningrate[5])
idx = 1
id_lr = 0
for key in optimizers:
optimizer = optimizers[key]
lr = learningrate[id_lr]
id_lr = id_lr + 1
x_history = []
y_history = []
params['x'], params['y'] = init_pos[0], init_pos[1]
for i in range(30):
x_history.append(params['x'])
y_history.append(params['y'])
grads['x'], grads['y'] = df(params['x'], params['y'])
optimizer.update(params, grads)
x = np.arange(-10, 10, 0.01)
y = np.arange(-5, 5, 0.01)
X, Y = np.meshgrid(x, y)
Z = f(X, Y)
# for simple contour line
mask = Z > 7
Z[mask] = 0
# plot
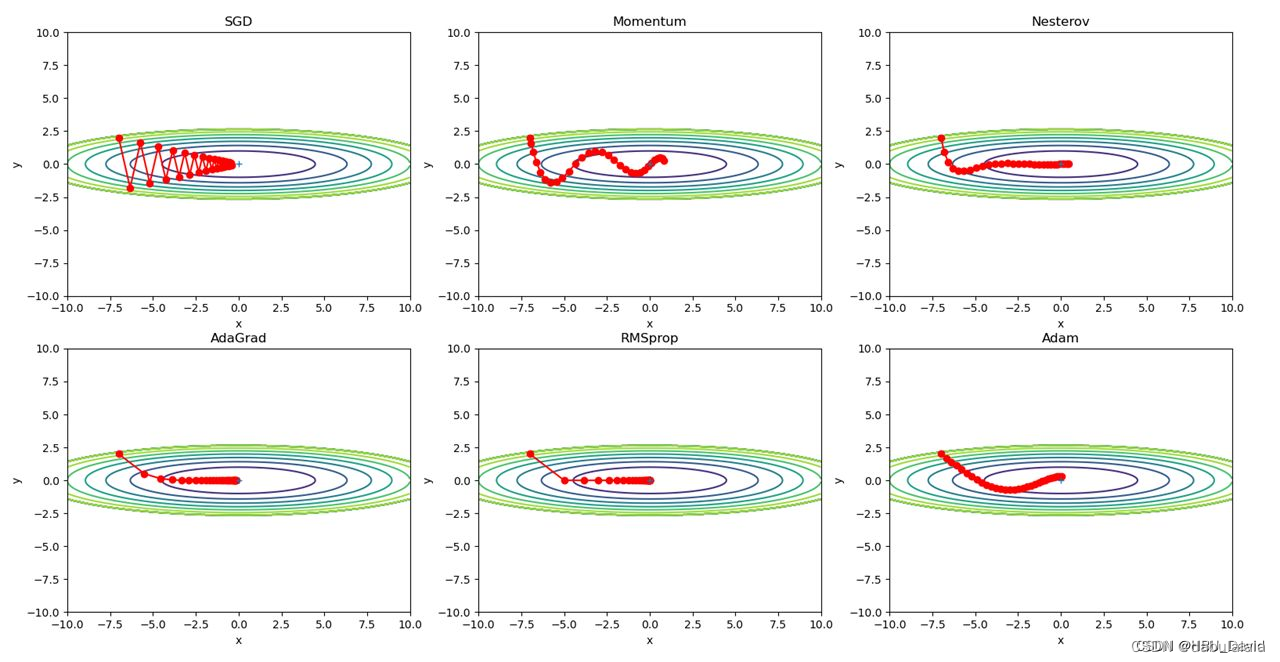
plt.subplot(2, 3, idx)
idx += 1
plt.plot(x_history, y_history, 'o-', color="r")
# plt.contour(X, Y, Z) # 绘制等高线
plt.contour(X, Y, Z, cmap='gray') # 颜色填充
plt.ylim(-10, 10)
plt.xlim(-10, 10)
plt.plot(0, 0, '+')
# plt.axis('off')
# plt.title(key+'\nlr='+str(lr), fontstyle='italic')
plt.text(0, 10, key + '\nlr=' + str(lr), fontsize=20, color="b",
verticalalignment='top', horizontalalignment='center', fontstyle='italic')
plt.xlabel("x")
plt.ylabel("y")
plt.subplots_adjust(wspace=0, hspace=0) # 调整子图间距
plt.show()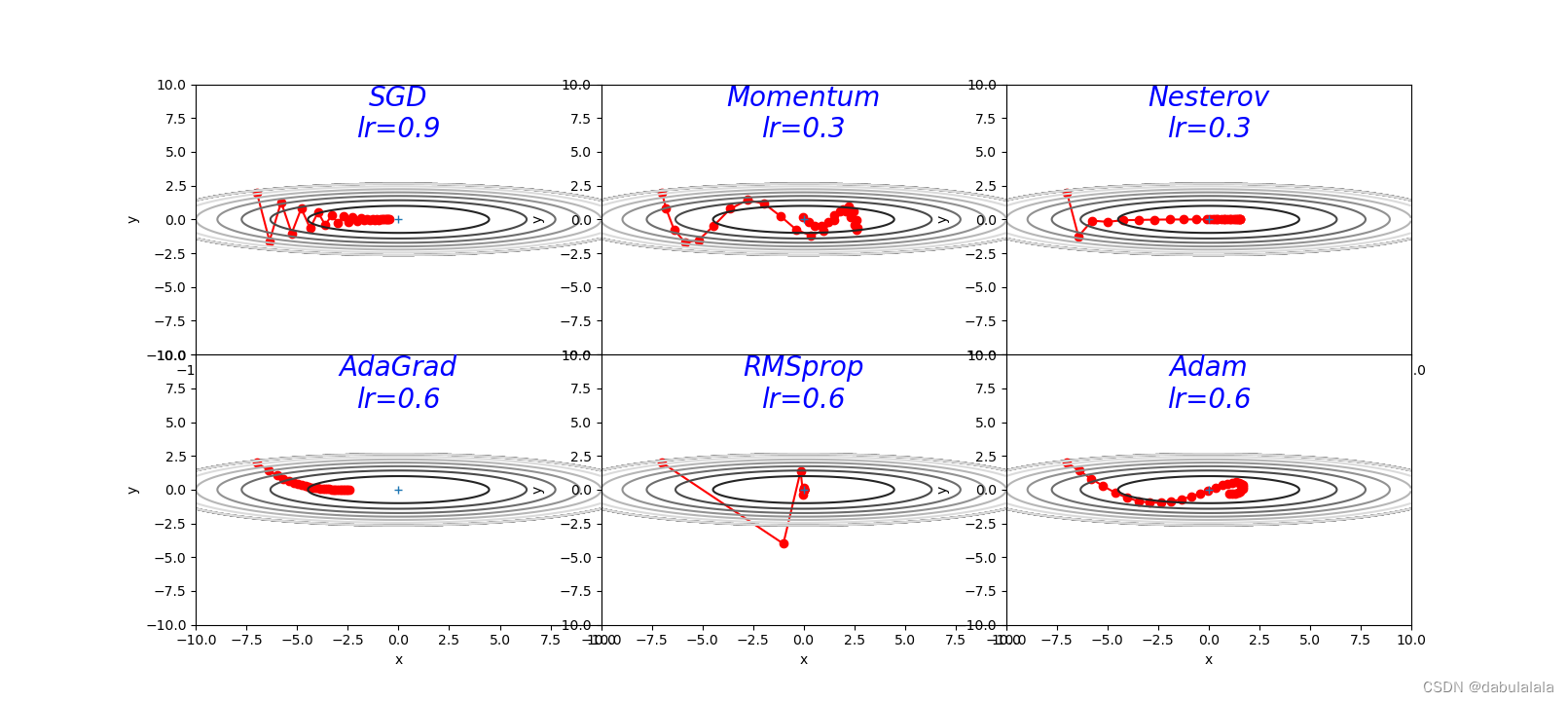
3. 解释不同轨迹的形成原因
(分析各个算法的优缺点)
SGD:
收敛轨迹呈“之”字形
优点:
计算效率高:每次迭代只需要计算一个样本的梯度,计算量较小,适用于大规模数据集。
收敛速度快:SGD每次只考虑一个样本,因此更容易跳出局部最优点,从而找到全局最优解。
缺点:
更新不稳定:由于SGD只考虑一个样本,因此每次更新都有一定的随机性,导致更新不稳定。
容易陷入局部最优:虽然SGD容易跳出局部最优,但是由于随机性的影响,也容易陷入局最优点。
需要调整学习率:SGD的收敛速度很快,但是需要调整学习率,否则可能导致模型无法收敛或收敛速度过慢。
(2)AdaGrad
优点:
自适应算法:AdaGrad算法根据每个参数的历史梯度信息来自适应地调整学习率,使得梯度不会太大或太小。
收敛快速:由于学习率的自适应调整,AdaGrad在训练初期可使用较大的学习率,有助于收敛速度的提升。
缺点:
学习率衰减过快:随着训练的进行,AdaGrad会累积历史梯度的平方和,导致学习率不断减小。在训练后期,学习率可能会变得非常小,甚至接近于零,导致训练过早停止。
在非凸问题中,AdaGrad可能会受到累积梯度平方的影响,导致陷入局部最优解。
(3)RMSprop
优点:
自适应学习率: RMSprop根据梯度的大小调整学习率,可以导致更高效的训练。
收敛效果好,快而稳定: 它在实践中表现良好,对于各种问题,特别是在循环神经网络中,收敛速度较快。解决了AdaGrad的早衰问题,对于具有嘈杂或稀疏梯度的问题,也特别有效。
避免梯度消失和梯度爆炸: 通过对梯度进行归一化,RMSprop有助于保持稳定的优化过程
缺点:
超参数调整: 虽然它减少了对全局学习率的微调需求,但引入了需要配置的移动平均衰减的新超参数。
(4)Momentum
优点:
更快的收敛速度:特别是对于具有许多不规则表面或在一个维度上非常陡峭而在另一个维度上非常平坦的问题(鞍点等)。并且由于动量项维持了运动,能够更有效地收敛至局部最小值或平坦区域。
稳定性强:减少垂直于梯度方向的振荡,导致更稳定的更新。
缺点:
引入了一个额外的超参数(动量系数):需要进行配置,这可能会使调整变得更加复杂。如果动量系数设置得太高,可能导致超过最小值,如果不适当控制甚至可能导致发散。
在高度凸问题或需要精确收敛到确切最小值的情况下,可能效果不佳。
(5)Adam
优点:
超参数具有很好的解释性,且通常无需调整或仅需很少的微调
更新的步长能够被限制在大致的范围内(初始学习率)
能自然地实现步长退火过程(自动调整学习率)
适用于不稳定目标函数
适用于梯度稀疏或梯度存在很大噪声的问题
缺点:
在非凸函数上可能不会收敛到全局最小值。
参考文章:
【23-24 秋学期】NNDL 作业12 优化算法2D可视化-CSDN博客
【NNDL 作业】优化算法比较 增加 RMSprop、Nesterov_随着优化的进展,需要调整γ吗?rmsprop算法习题-CSDN博客
NNDL 作业11:优化算法比较_"ptimizers[\"sgd\"] = sgd(lr=0.95) optimizers[\"mo-CSDN博客















 727
727











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









