






1、if,和elif的区别:
if如果满足条件则走当前分支,不满足则跳过
elif如果没有满足if 的分支,但是满足了elif的分支,则走elif,如果满足了 if分支,则不会再走elif,如果if和elif都没有满足,再走else分支
2、python封装,类中的函数如果要调用其他类的函数必须通过以下形式进行实例化方才有效
def __init__(self):
self.ProcessData = None
def add_tag(self,token,userid,tagNames:list):
api_set_tag = grdoc_url + 'api/user/setInfo'
self.ProcessData = ProcessData()
tagids = self.ProcessData.get_user_tags(tagnames=tagNames)不能直接在函数中没有self.就调用,会报语法错误比如
def add_tag(self,token,userid,tagNames:list):
api_set_tag = grdoc_url + 'api/user/setInfo'
ProcessData = ProcessData()
tagids = ProcessData.get_user_tags(tagnames=tagNam)同样也不能在函数外,类中调用,这样会报错type erro比如
class DoctorHandle:
ProcessData = ProcessData()
def add_tag(self,token,userid,tagNames:list):
tagids = ProcessData.get_user_tags(tagnames=tagNam)3、request请求,如果body的数据要求是json格式,使用json.dumps()转换后,需要在请求头加上"Content-Type": 'application/json'
4、python中包和目录的区别
python包中含有__init__.py文件,即使他是空的,而普通目录中没有改文件,有了该文件,对应包才可以被导入引用其中的模块,类和方法
5、通过引用A脚本中的变量,不能直接在B脚本中修改A脚本的变量,在B脚本中修改只是修改的引用模板而不是源文件的变量
6、同一个类中,不同函数之间的调用要加上self.
7、编写代码注意PEP8规范,目前最重要的是
一. 代码留白
对于 Python 而言,代码中的空白字符不仅在语法上相当重要,而且对于代码清晰度而言也必不可少。在使用空白时应遵循以下规则:
使用 sapce 空格来表示缩进,不要使用 tab 制表符
每行的字符数不应超过 79 个
对于多行的长表达式,除了首行之外的其余各行都应该在通常的缩进级别之上再加 4 个空格
模块中的函数和类应该使用两个空行隔开
在同一个类中,各方法之间应该使用一个空行隔开
为变量赋值的时候,赋值符号的左侧和右侧都应该添加一个空格
此外,还有两个和 : 有关的空白建议:
定义字典时,键与冒号之间不应有空格,冒号与值之间应留一个空格
给变量的类型做注解时,变量名和冒号之间不应有空格,冒号与类型之间应保留一个空格
总的来说,就是 : 左侧没有空格,空格加载 : 右侧。
my_dict = {'name': 'yamfish', 'age': 17}
def my_func(a: int, b: str):
pass二. 标识符命名
PEP 8 建议我们在为 Python 代码中的不同部分命名时,才用不同的命名方式。使得阅读代码的人可以根据这些名称获知它们在 Python 语言中所扮演的角色。
函数名、变量以及属性:应使用小写形式,并用
_拼接多个单词受保护属性:以
_开头私有属性:请
__开头类与异常:每个单词的首字母均应为大写形式
模块级别的常量:应使用大写形式,并用
_拼接多个单词实例方法:应把第一个参数命名为
self,表示对象本身类方法: 应把第一个参数命名为
cls,表示类本身
三. 表达式和语句
在使用行内否定时,请勿把否定词放在整个表达式前面。
if a is not b:
...上述的表达方式,要比把 not 放在最前面更加直白:
if not a is b:
...不要使用检测长度的办法来判断容器或序列是否为空,比如:
my_list = []
if len(my_list) == 0:
pass最简洁的方式应该采用 *if not my_list* 这样的写法,因为 Python 会将空值自动评估为 False。
同样的,判断容器或序列是否非空,也应相应地使用 *if my_list* 这样的形式,因为 Python 会将非空值自动评估为 True 。
对于跨越多行的长表达式,建议使用
()将表达式括起来,并适当地添加换行和缩进,使得表达式的阅读更加清晰,而不要使用\续行。
四. import 有关的建议
当我们在代码中引入和使用模块时,可以遵循 PEP 8 有关 import 的如下建议:
除非特殊情况,import 语句应位于 Python 文件的开头位置。引入模块时,应该总是使用绝对名称,而不应该根据当前模块的路径来使用相对名称。
推荐绝对引入:
from bar import foo即便当前路径在 bar 包中,也不推荐直接写为 *import foo* 。如果一定要使用相对导入,那么请使用明确的写法:
from . import foo此外,模块开头的 import 语句应该按顺序分为 3 个部分引入:
标准库模块
第三方模块
自定义模块
在各个部分中, import 语句应该按照字母顺序来排列。
8、yield和return的区别
yield和return在Python编程中都有返回值的功能,但它们在用法和行为上存在一些重要的区别。
函数行为:
return:当一个函数遇到return语句时,它会立即结束执行,并将控制权返回给调用者,同时返回指定的值。之后,该函数的所有后续代码都不会被执行。yield:yield用于定义一个生成器函数。当函数执行到yield语句时,它会暂停执行并“记住”当前的执行状态,然后返回一个值。当再次调用该生成器函数时,它会从上次暂停的位置继续执行,而不是从头开始。
返回值类型:
return:return返回的是一个具体的值,或者是None(如果没有指定返回值的话)。yield:yield每次调用返回的是一个迭代器,它允许你逐个地获取值,而不是一次性地获取所有值。这意味着你可以使用for...in循环来遍历由yield产生的值。
内存使用:
return:当返回大量数据时,return可能会导致大量的内存使用,因为它需要一次性地创建并存储所有返回的数据。yield:yield生成器函数则更为内存友好,因为它可以按需生成值,而不是一次性地生成所有值。这意味着在处理大量数据时,使用yield可以更有效地管理内存。
使用场景:
return:当你需要一次性地返回一个值时,使用return。yield:当你需要逐个地返回多个值,或者需要处理大量数据并希望节省内存时,使用yield。
总的来说,return和yield在Python中都是用于返回值的,但它们在函数行为、返回值类型、内存使用和使用场景上有所不同。选择使用哪一个取决于你的具体需求。
9、debug调试模式
1 设置断点
如下图,在pycahrm的界面中写了Pycharm_debug_test.py文件,在某处代码行(你需要停顿的位置)只要用鼠标点击图中的位置,出现一个红点,那么debug就会停顿在这,再次对着红点鼠标点击一下,红点会消失。需要停顿的位置可根据自己的调试需求自行更改。
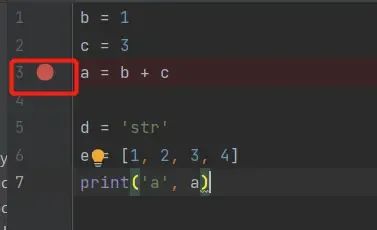
图1 设置断点
2 开始调试
按照图2的操作进入debug,程序下方弹出图2 b) 的界面。
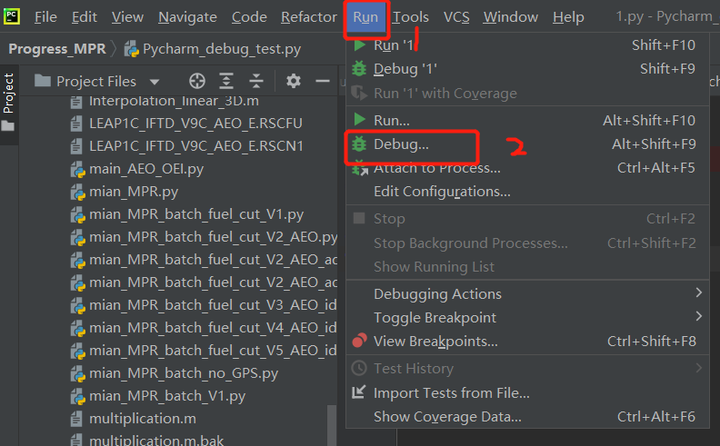
图2 a) 进入debug
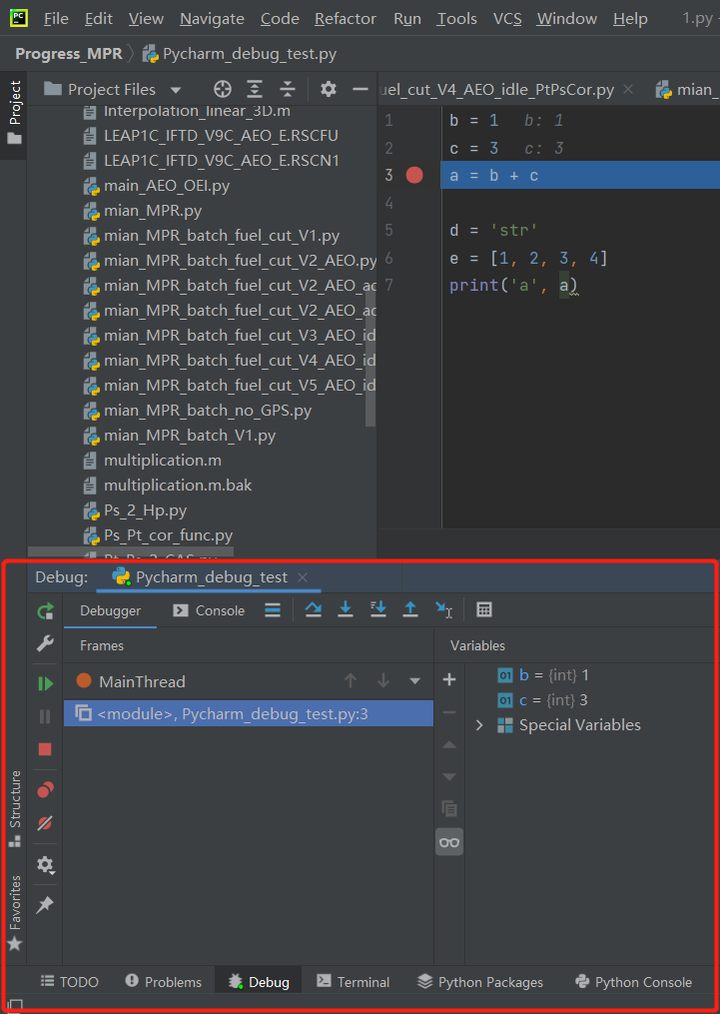
图2 b) 进入debug
根据图3 发现前面两行已经运行完,相应的变量已经在debug的界面显示,程序停在了第3行。
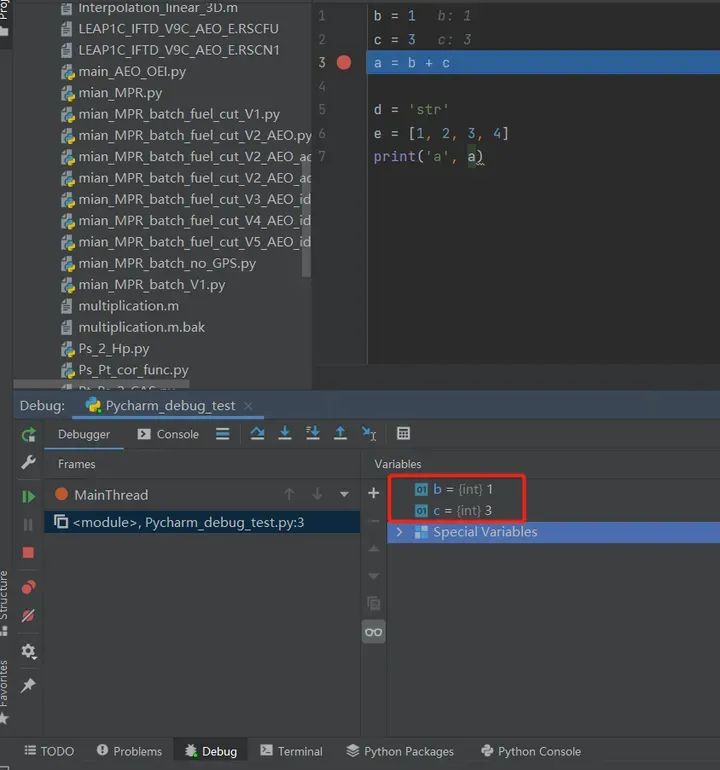
图3 debug界面
3 Debug调试
这一步是调试的精髓。通常程序出bug是因为变量的类型不对,导致出现问题,但又不知道哪出现问题,这面这一步可以让你在debug中交互,做些运算,了解类型等操作。
按照图4的点击顺序进入debug交互界面。Console -> Show Debug Console, 界面出现In[2]:,我们就可以在里面做运算啦。
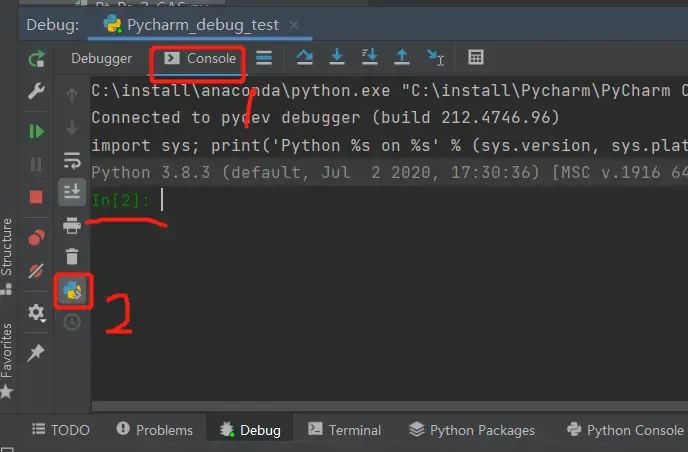
图4 debug交互界面
笔者做了如下运算,了解b的类型,b与c做了乘法,发现都能Out正确的值。
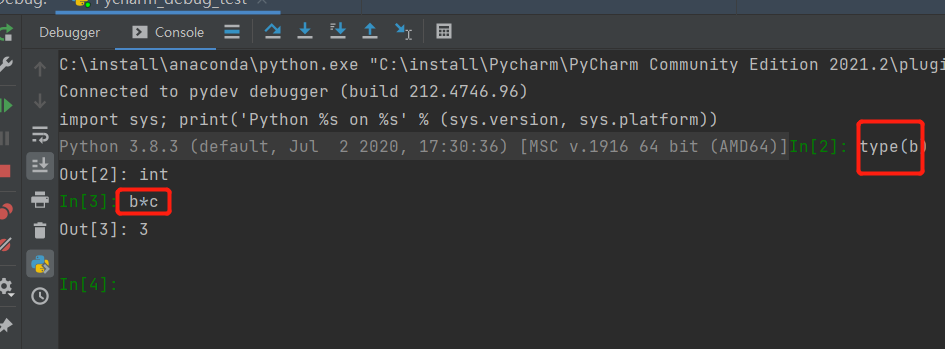
图5 Debug 交互
当然,以上的debug交互所用到的变量只能用到第3行之前的变量,因为debug停在了第3行(注意第3行没有运行),见图6输出a会报错
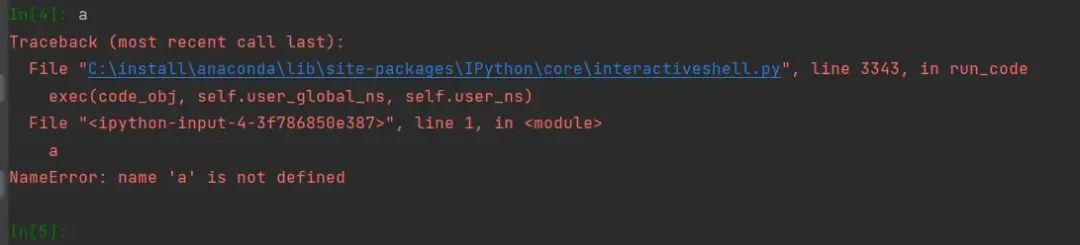
图6 输出a
那如何进行下一步呢,我们看到debug界面还有如图7的5个小图标
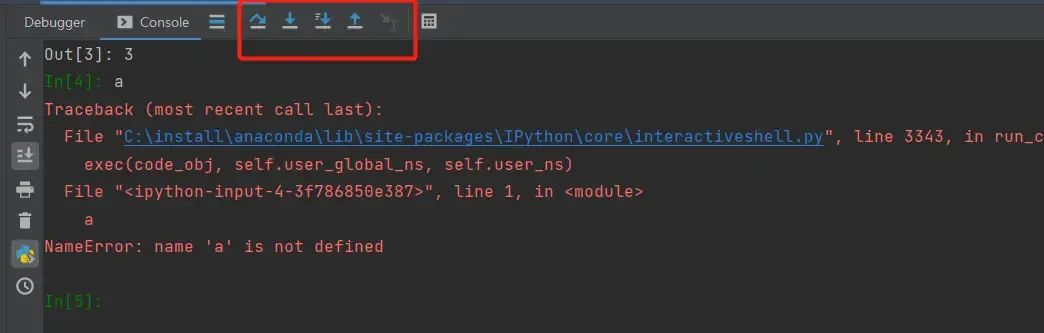
图8 Step Over
Step Over :进行debug到下一行,步进,只能一步一步的到下一行。
图9 Step Into
Step Into:进入函数里面
图10 Step Into My Code
Step Into My Code:调试过程中想跟着代码一步步走下去,可以一只按F7(Step Into),有时就会调到源代码里去执行,此时通过Step Into My Code可以让debug回到自己的代码并继续向下执行
图11 Step Out
Step Out: 跳出函数

图12 Run to Cursor
Run to Cursor:不步进,直接跳到下一个最近的红点(游标),即你设置的下一个的断点
4 小节
调试方式总结见下表
| 调试方式 | 快捷键 | 意义 |
|---|---|---|
| Step Over | F8 | 调试一行代码,不进入子函数;如果没有子函数,功能与Step Into一样 |
| Step Into | F7 | 单步执行,进入子函数 |
| Step Into My Code | Alt + Shift + F7 | 调试过程中想跟着代码一步步走下去,可以一只按F7(Step Into),有时就会调到源代码里去执行,此时通过Step Into My Code可以让debug回到自己的代码并继续向下执行 |
| Step Out | Shift + F8 | 运行断点后面所有代码;当单步执行到子函数内时,用step out就可以执行完子函数余下部分,并返回到上一层函数 |
| Run to Cursor | Alt + F9 | 一直执行,直到光标处停止;用在循环内部时,点击一次就执行一个循环 |
10、try...except...finally的用法和注意事项
用法
try 块
try 块用于包含可能会引发异常的代码。当这些代码执行时,如果发生异常,则控制流会立即转移到相应的 except 块。
except 块
except 块用于捕获并处理 try 块中抛出的异常。你可以指定要捕获的异常类型,或者简单地使用 Exception 来捕获所有类型的异常。
你可以有多个 except 块来捕获不同类型的异常,每个 except 块应该处理特定类型的异常。
try:
# 可能会引发异常的代码
...
except SpecificException as e:
# 处理 SpecificException 异常的代码
...
except AnotherException as e:
# 处理 AnotherException 异常的代码
...
except:
# 处理其他所有类型的异常
...finally 块
finally 块包含的代码无论是否发生异常都会执行。它通常用于清理资源,如关闭文件、释放锁或网络连接等。
try:
# 可能会引发异常的代码
...
except SpecificException as e:
# 处理 SpecificException 异常的代码
...
finally:
# 无论是否发生异常,这里的代码都会执行
...原理
当 Python 执行 try 块中的代码时,它会尝试执行这些代码,并监视任何异常。如果发生异常,则控制流会立即转移到与异常类型匹配的 except 块。如果没有找到匹配的 except 块,异常将被传递到上层调用栈,除非在 except 块中调用了 raise 语句重新抛出异常。如果找到了匹配的 except 块,则执行该块中的代码,然后继续执行 finally 块(如果存在)。无论是否发生异常,finally 块中的代码总是会被执行。
注意事项
**不要过度使用
except**:只捕获你确实知道如何处理并能从中恢复的异常。不要忽略异常:捕获异常后,最好总是以某种方式处理它,要么记录日志,要么向用户报告。
使用具体的异常类型:尽可能使用具体的异常类型而不是
Exception,这样可以更精确地处理不同类型的异常。不要忽略
finally块:finally块是执行清理操作的好地方,确保资源得到正确释放。避免在
finally块中引发新的异常:如果在finally块中引发异常,它会覆盖try或except块中引发的任何异常。不要在
finally块中调用可能引发异常的代码,除非你打算处理它,因为这会覆盖原始的异常。考虑使用
else块:else块在try块成功执行(即没有引发异常)时执行。这可以用于执行仅当没有异常时才应运行的代码。使用
raise重新抛出异常:如果你需要在except块中处理异常,但又不想完全终止程序,可以使用raise语句重新抛出异常。确保
try块中的代码尽可能少:只将可能引发异常的代码放在try块中,这样可以减少错误处理的复杂性。考虑使用上下文管理器(
with语句):对于资源管理,使用上下文管理器通常更为简洁和安全,因为它可以自动处理资源的获取和释放。
Python中的异常分类
BaseException: 所有异常和警告的基类。SystemExit: 解释器请求退出。通常由sys.exit()函数引发。KeyboardInterrupt: 用户中断执行(通常是Ctrl+C)。Exception: 所有标准异常的基类。ArithmeticError: 所有数值计算错误的基类。AssertionError: 断言语句失败。AttributeError: 对象没有这个属性。EOFError: 没有更多的输入,到达EOF标记。ImportError: 导入模块/对象失败。LookupError: 无效数据查找的基类。MemoryError: 内存不足。NameError: 未声明/初始化对象(没有这个名字)。ReferenceError: 弱引用引用到的对象已经被垃圾回收。RuntimeError: 一般的运行时错误。NotImplementedError: 尚未实现的方法。SyntaxError: Python语法错误。IndentationError: 缩进错误。TypeError: 对类型无效的操作。ValueError: 传入无效的参数。UnicodeError: Unicode相关的错误。ZeroDivisionError: 除(或取模)零。OverflowError: 数值运算结果太大,无法表示。UnderflowError: 数值运算结果太小,无法表示。FloatingPointError: 浮点运算错误。IndexError: 序列中没有此索引(index)。KeyError: 映射中没有这个键。UnboundLocalError: 访问未初始化的本地变量。TabError: Tab和空格混用。UnicodeDecodeError: Unicode解码错误。UnicodeEncodeError: Unicode编码错误。UnicodeTranslateError: Unicode转换错误。StopIteration: 迭代器没有更多的值。GeneratorExit: 生成器(generator)被关闭时引发。StandardError: 所有内置标准异常的基类(在Python 3中已被弃用,所有内置异常都直接继承自Exception)。
自定义异常类型
你可以通过继承Exception类或其子类来创建自定义异常类型。这允许你定义与你的应用程序或库相关的特定错误条件。
在Python的异常处理结构中,raise语句用于显式地引发(或重新引发)一个异常,而else块用于在try块中的代码成功执行(即没有引发异常)时执行一些额外的代码。下面我将详细解释这两个关键字在异常处理中的用法。
使用raise显式引发异常
raise语句用于在代码中显式引发一个异常。这通常在你检测到某个错误条件并希望程序以异常的方式停止执行时发生。raise语句可以不带任何参数调用,以重新引发当前异常(通常在一个except块中),也可以带有一个异常实例或异常类型与值来引发新的异常。
try:
# 尝试执行一些代码
x = 1 / 0 # 这将引发ZeroDivisionError
except ZeroDivisionError:
# 捕获ZeroDivisionError异常
print("不能除以零!")
# 重新引发该异常
raise
# 如果上面的代码执行到这里,将会引发ZeroDivisionError如果你想引发一个不同类型的异常,或者想在异常中附加一些额外的信息,你可以这样做:
try:
# 尝试执行一些代码
file = open("nonexistent.txt", "r")
except FileNotFoundError:
# 捕获FileNotFoundError异常
message = "文件不存在,请检查文件路径。"
# 引发一个新的ValueError异常,附带额外的信息
raise ValueError(message) from None使用else执行成功代码
else块是try/except结构的一个可选部分,它包含的代码块只有在try块中的代码成功执行(即没有引发任何异常)时才会被执行。这对于在异常处理结构中执行一些只有在没有错误时才需要的逻辑很有用。
try:
# 尝试执行一些代码
result = 2 + 2
except Exception as e:
# 捕获任何异常并处理
print(f"发生了异常: {e}")
else:
# 如果try块中的代码成功执行,则执行这里的代码
print("计算成功,结果是:", result)
finally:
# 无论是否发生异常,都会执行这里的代码
print("清理资源或执行最后的操作")在这个例子中,else块中的代码会在try块成功执行后执行,打印出计算的结果。而finally块则会在整个try/except/else结构结束时执行,无论是否发生了异常。
注意事项
raise语句通常不会出现在finally块中,因为finally块是为了执行清理操作而设计的,而raise会中断当前的执行流程。在
except块中使用raise时,如果不带任何参数,它将重新引发最近一次被捕获的异常。如果你想引发一个新的异常,同时保留原始异常的上下文,可以使用raise NewException from OldException的语法。else块是可选的,并且只会在try块成功执行后执行。如果try块中的代码引发了异常,并且该异常被except块捕获,则不会执行else块中的代码。finally块总是会被执行,无论try块是否引发了异常,无论except和else块是否存在或它们的代码是否执行。因此,finally块通常用于资源清理,如关闭文件、释放锁等。
11、变量相关
对于函数中的变量,如果中途需要修改,引用,建议首先定义一个初始变量
12、对象的应用
复习一下类和对象
应用场景,接口请求的某个字段的值为一个JSON或者叫字典吧,我们在处理这个函数的时候可以创建一个类,然后重写输出对象格式,如果不重写,打印出来的是一个模块名+类名+基类名+对象在内存中的地址格式
比如我要得到一个如下的格式对象
{
"id": str,
"num": int
}我们可以创建如下类来创建对象
class ServiceProject:
id: str
num: int
# 初始化,->None 是一个类型注解,表示这个函数不返回任何值,或者返回空值
def __init__(self, id: str, num: int) -> None:
self.id = id
self.num = num
# 重写类的输出格式
def to_dict(self):
return {"id": self.id, "num": self.num}如果要输出字符串或者格式字符串可以采用一下方法
class Person:
def __init__(self, name, age):
self.name = name
self.age = age
def __repr__(self): # 默认输出格式字符串
return f"Person(name='{self.name}', age={self.age})"class ServiceProject:
# ... 其他代码保持不变 ...
def __str__(self): # 这样也可以
return f"ServiceProject(id='{self.id}', num={self.num})"13 Python中的Typing模块
在Python中,typing 模块提供了很多有用的工具,用于类型注解和类型检查。Optional 和 List 是这个模块中两个常用的类型注解。
Optional
Optional 是一个泛型类型,用于表示一个值可以是某个类型,或者是 None。这在你想要明确表示某个变量或参数可以为空时非常有用。
例如,假设你有一个函数,它接受一个字符串参数,但这个参数是可选的,即可以传入一个字符串,也可以传入 None。你可以使用 Optional 来注解这个参数:
from typing import Optional
def greet(name: Optional[str] = None):
if name is None:
print("Hello, anonymous person!")
else:
print(f"Hello, {name}!")
greet() # 输出: Hello, anonymous person! greet("Alice") # 输出: Hello, Alice!在这个例子中,name 参数的类型是 Optional[str],意味着它可以是 str 类型或 None。
List
List 是一个泛型类型,用于表示一个列表,其中列表的元素可以是任何类型。通过指定 List 中的类型参数,你可以指定列表中元素的类型。
例如,如果你有一个包含整数的列表,你可以这样注解它:
from typing import List
def sum_numbers(numbers: List[int]) -> int:
return sum(numbers)
result = sum_numbers([1, 2, 3, 4]) # 输出: 10在这个例子中,numbers 参数的类型是 List[int],意味着它必须是一个整数列表。函数的返回类型注解为 int,表示这个函数返回一个整数。
使用类型注解的好处是它们可以提高代码的可读性和可维护性,同时也有助于在开发过程中捕获类型错误。虽然Python是一种动态类型语言,但类型注解可以帮助开发者明确意图,并且与一些工具(如类型检查器 mypy)结合使用时,可以在运行前发现潜在的类型问题。
在Python的typing模块中,除了基本的类型注解(如int, str, float等)外,还提供了一系列泛型类型(Generic Types)和特殊类型注解,用于增强代码的可读性和类型安全性。以下是一些常用的泛型类型和类型注解:
**List[T]**:表示元素类型为T的列表。例如,
List[int]表示整数列表。**Tuple[T1, T2, ...]**:表示元组,其中每个位置上的元素都有指定的类型。例如,
Tuple[str, int]表示一个字符串和一个整数组成的元组。**Dict[KT, VT]**:表示字典,其中
KT是键的类型,VT是值的类型。例如,Dict[str, int]表示键为字符串、值为整数的字典。**Set[T]**:表示元素类型为T的集合。
**Union[T1, T2, ...]**:表示值可以是多种类型之一。例如,
Union[int, str]表示值可以是整数或字符串。**Optional[T]**:表示值可以是类型T或者是
None。这是Union[T, None]的简写。Any:表示可以是任何类型。在需要忽略类型检查或者不确定类型时使用。
**Type[T]**:表示类型对象本身,而不是该类型的实例。例如,
Type[int]表示int这个类型本身。**Callable[..., ReturnType]**:表示可调用的对象,如函数和方法。
...表示参数类型,ReturnType表示返回类型。**Sequence[T]**:表示有序的元素集合,如列表或元组。它是
collections.abc.Sequence的泛型。**Mapping[KT, VT]**:表示映射类型,如字典。它是
collections.abc.Mapping的泛型。**MutableMapping[KT, VT]**:表示可变映射类型,如字典。它是
collections.abc.MutableMapping的泛型。**Iterable[T]**:表示可迭代对象,如列表、元组、字典、集合等。
**Generator[T, U, V]**:表示生成器,其中
T是yield类型,U是send类型,V是return类型。**NewType(name, tp)**:用于创建新的类型,它在运行时与基础类型
tp相同,但具有不同的类型标识。Pattern[str] 和 **Match[str]**:在Python 3.9及以后的版本中,用于正则表达式匹配的模式和匹配结果。
这些泛型类型和类型注解为Python提供了更强大的类型系统,使得代码更加清晰、易于理解和维护。同时,它们也可以与类型检查器(如mypy)一起使用,以在静态分析中捕获类型错误。
14 通过requests请求需要上传文件的接口
示例代码:
import requests
url = "https://example/upload"
# 假设您有一个名为 'path_to_your_file.ext' 的文件要上传
file_path = 'path_to_your_file.ext'
# 构造files参数
files = {
'fileInfo': (
'excel_file.xlsx', # 在服务器上保存的文件名,可以自定义
open(excel_file_path, 'rb'), # 打开文件对象以二进制模式读取
'application/vnd.openxmlformats-officedocument.spreadsheetml.sheet' # Excel文件的MIME类型
)
}
headers = {
'token': '60c42d521de020eca7322a0cce03d507',
'client': 'your_client_value', # 请将'{{client}}'替换为实际的client值
'User-Agent': 'Apifox/1.0.0 (https://apifox.com)'
}
# 发送POST请求,包含文件和其他可能的payload数据
response = requests.post(url, headers=headers, files=files)
# 打印服务器响应的文本内容
print(response.text)
# 确保关闭文件对象
with open(file_path, 'rb') as file:
pass # 文件在with块结束时自动关闭在构建files参数时,MIME类型用于指定上传文件的类型,这样接收方就能正确地解释和处理这些数据。MIME类型通常由两部分组成:主类型和子类型,它们之间用斜杠(/)进行分隔。主类型表示数据的一般性质,如文本、图像、音频、视频等;子类型则进一步细分了主类型,表示具体的数据格式或类型。
以下是一些常见的MIME类型及其代表的意义:
text/plain:表示纯文本文件,如ASCII码文件。text/html:表示HTML文档,这是用于创建网页的标准标记语言。text/css:表示CSS样式表,用于描述HTML文档的呈现样式。application/json:表示JSON数据,这是一种轻量级的数据交换格式。application/pdf:表示PDF文档,这是一种可移植文档格式。image/jpeg:表示JPEG图像,这是一种常用的图像压缩格式。image/png:表示PNG图像,这是一种支持无损压缩和透明度的图像格式。audio/mpeg:表示MP3音频文件,这是一种常见的音频压缩格式。application/octet-stream:表示任意的二进制数据流,通常用于不确定文件类型的情况。application/vnd.ms-excel(对于老版本的Excel文件,如.xls)application/vnd.openxmlformats-officedocument.spreadsheetml.sheet(对于较新版本的Excel文件,如.xlsx)
这些MIME类型不仅用于文件上传,还广泛应用于Web编程开发、电子邮件附件、多媒体资源识别等多个场景。当浏览器或其他客户端接收到这些MIME类型时,它们会根据类型来决定如何打开或显示文件内容。
在构建files参数时,你需要根据你的文件类型来指定正确的MIME类型。这有助于确保文件能够被正确地处理和解释。
注意事项:
1、构建files参数的时候requests期望的类型是一个字典
2、接口请求格式为的请求头为
multipart/form-data不需要手动设置Content-Type
15 Python中的日志
这里我就简单介绍一下简易日志的使用,以及重写自定义日志
import logging
import time
# 创建一个日志记录器
logger = logging.getLogger('my_logger')
logger.setLevel(logging.DEBUG)
# 创建一个日志处理器,用于将日志输出到控制台
handler = logging.StreamHandler()
# 定义一个日志格式,包含时间、日志级别和日志信息
formatter = logging.Formatter('%(asctime)s - %(levelname)s - %(message)s')
# 将定义的格式应用到处理器上
handler.setFormatter(formatter)
# 将处理器添加到记录器上
logger.addHandler(handler)
# 记录一条日志信息
logger.debug('This is a debug message')
logger.info('This is an info message')
logger.warning('This is a warning message')
logger.error('This is an error message')
logger.critical('This is a critical message')以上代码示例已经快包含了常用的logging模块的使用,常用方法
下面为重写日志示例,为什么要重写?为了节省代码不用每次记录日志都去配置一下
import logging
import os
#定义过滤日志
class LevelFilter(logging.Filter):
def __init__(self, level):
self.level = level
def filter(self, record):
return record.levelno == self.level
#重写信息
class CustomLogger:
def __init__(self, log_dir='./logs'):
self.log_dir = log_dir
self._create_log_dir()
self.logger = logging.getLogger(__name__)
self.logger.setLevel(logging.DEBUG)
self._add_file_handlers()
def _create_log_dir(self):
if not os.path.exists(self.log_dir):
os.makedirs(self.log_dir)
def _add_file_handlers(self):
log_levels = {
'debug': logging.DEBUG,
'info': logging.INFO,
'warning': logging.WARNING,
'error': logging.ERROR,
'critical': logging.CRITICAL
}
for level_name, level in log_levels.items():
file_handler = logging.FileHandler(os.path.join(self.log_dir, f'{level_name}.log'))
file_handler.setLevel(level)
formatter = logging.Formatter('%(asctime)s - %(levelname)s - %(message)s')
file_handler.setFormatter(formatter)
file_handler.addFilter(LevelFilter(level))
self.logger.addHandler(file_handler)
def debug(self, message):
self.logger.debug(message)
def info(self, message):
self.logger.info(message)
def warning(self, message):
self.logger.warning(message)
def error(self, message):
self.logger.error(message)
def critical(self, message):
self.logger.critical(message)
if __name__ == "__main__":
logger = CustomLogger()
logger.debug("Debug message")
logger.info("Info message")
logger.warning("Warning message")
logger.error("Error message")
logger.critical("Critical message")更多用法大家可以交流探索,查看官方文档















 5629
5629











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











