






引言:作者相信在不久的将来,Ai就如同手机一般会成为人类必不可少的工具,而针对个体(社会,企业,家庭...)的Ai市场必然会成为巨大的需求缺口,而模型代训练将会是一个风口,本文章采用unity引擎的ml-agent机器学习工具包,讨论设计和模型优化,不涉及教程。
模型训练与优化的基本概念:相信很多学习机器学习和深度学习的小伙伴都有训练模型的烦恼,有时候训练1亿次电脑都跑蓝屏了,还是训练出个250,完完全全达不到自己的训练要求,而博主采用的优化概念是引导式训练,并且达到了一个十分不错的效果,而引导式训练又是什么呢?这个作者的灵感来源于婴儿训练,我们要教婴儿去说话,去走路等等,当然婴儿或许可以自学,但效果远不如有大人教的好,而我们的模型训练则需要去告诉我们的模型,你要去做什么。
项目背景介绍:警察抓贼
玩法对抗介绍:一个警察需要抓走两个贼,当警察抓到其中一个贼,另外一个贼需要绕开警察解救被抓到的贼,则贼队加1分,警队扣1分。当警队抓获所有贼则警队加1分,贼队扣1分。抓捕过程采用时间机制,贼逃跑每秒增加0.01分。
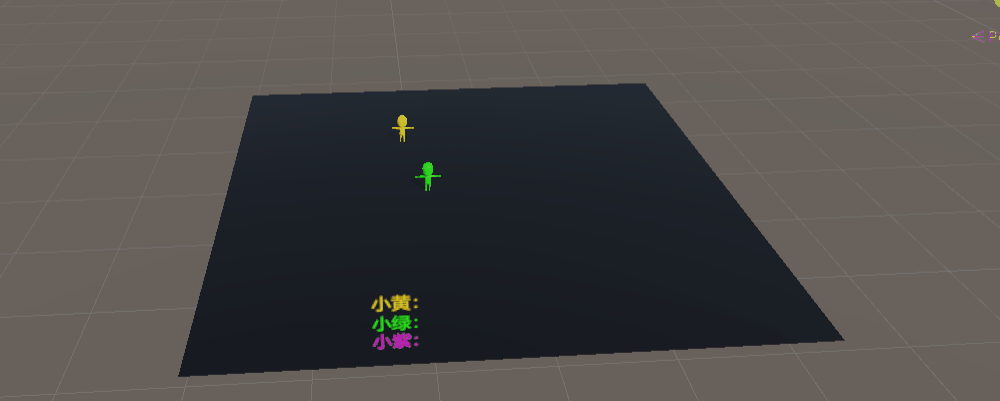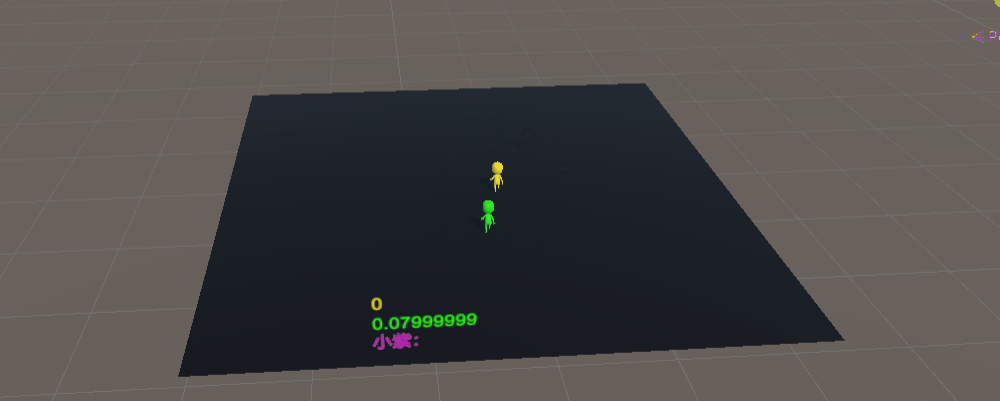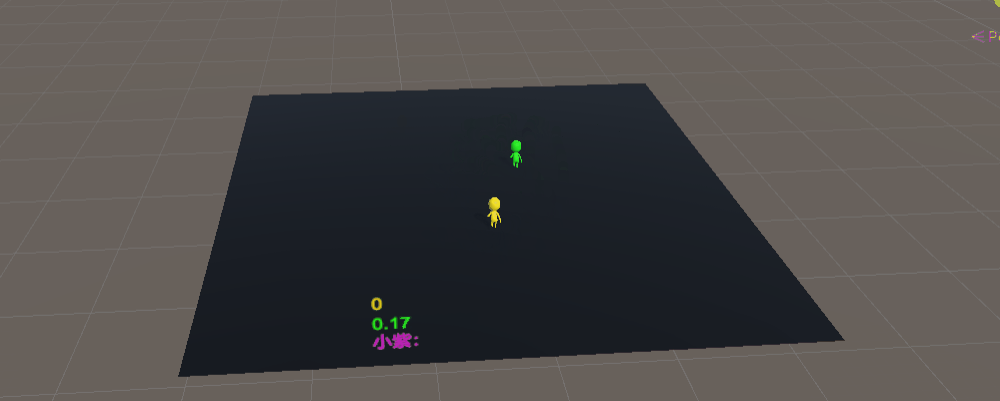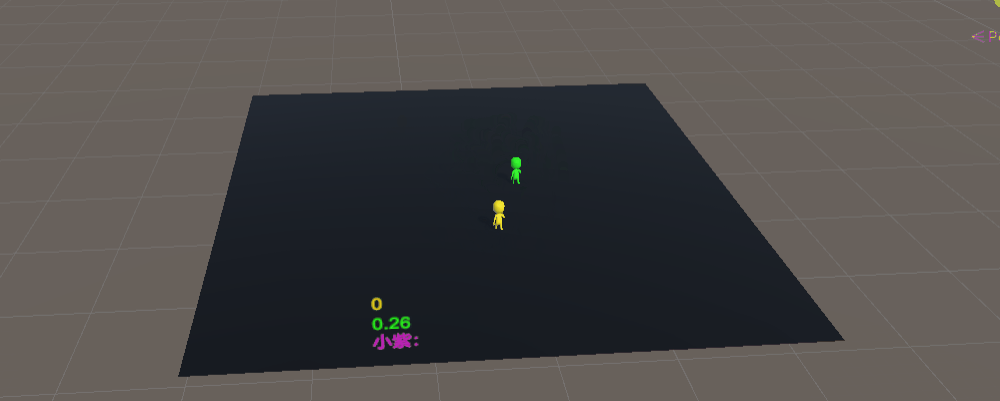
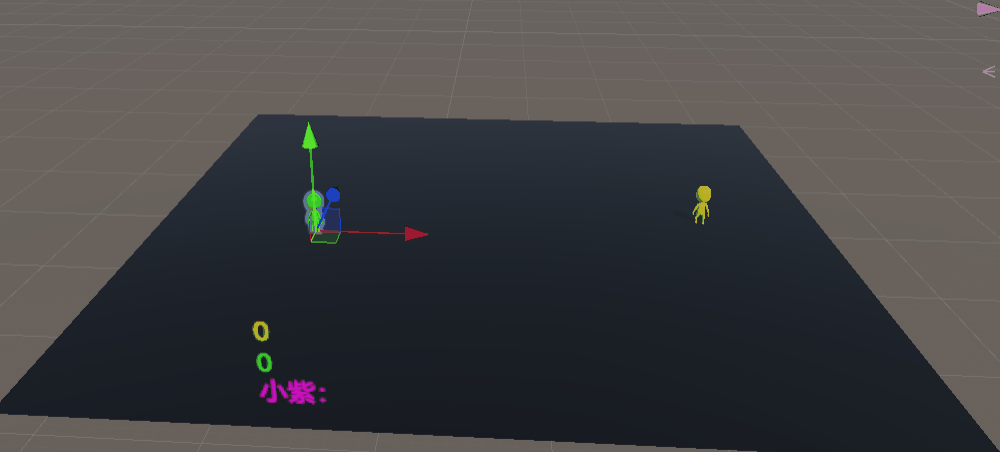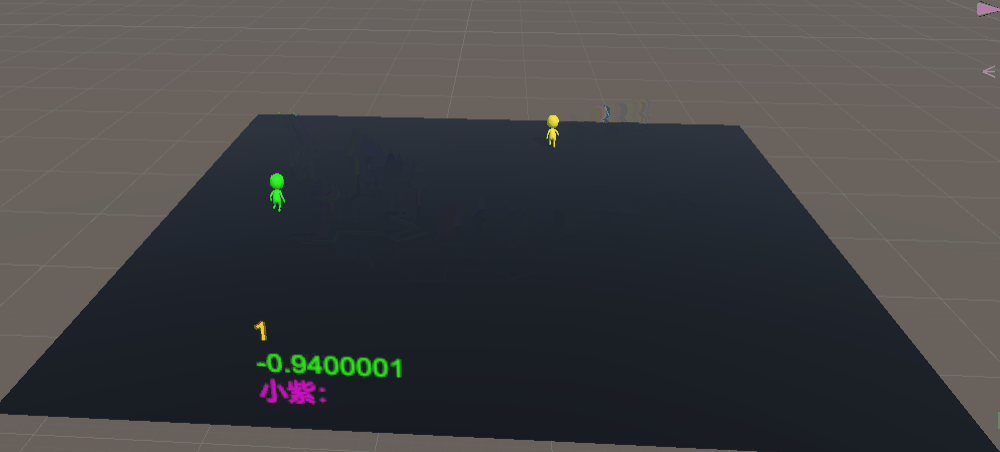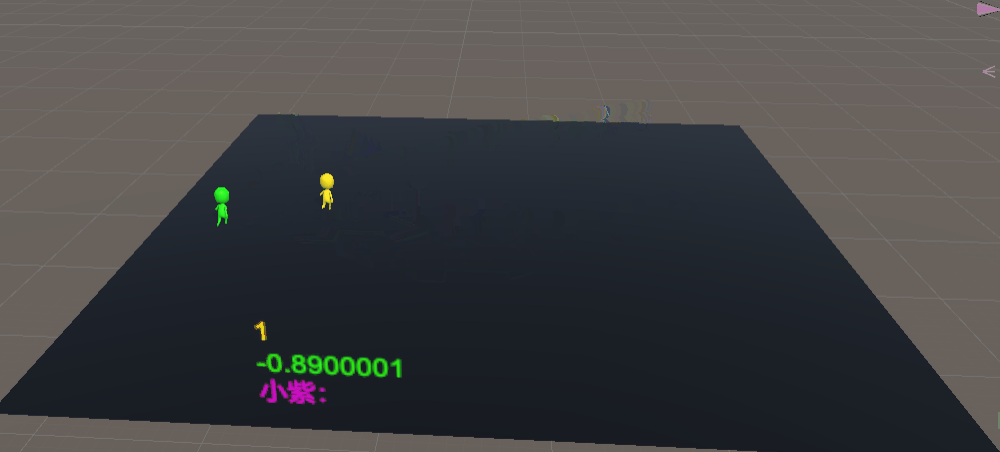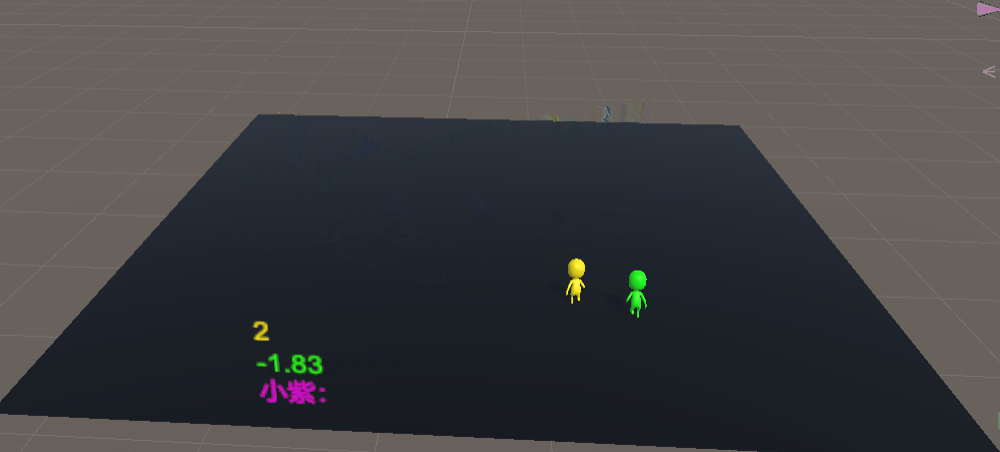
未优化前训练5000万次数据:
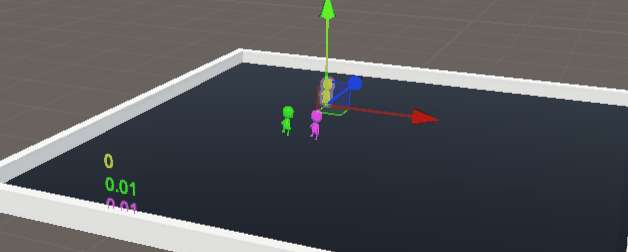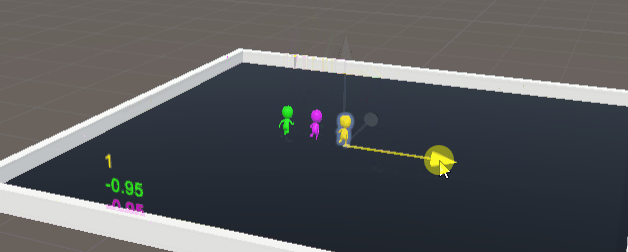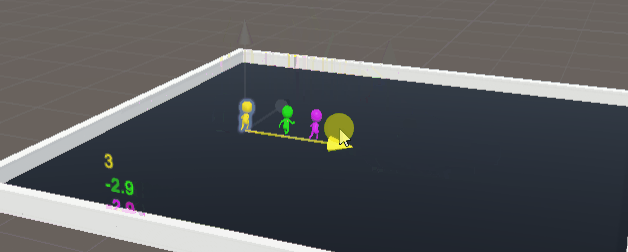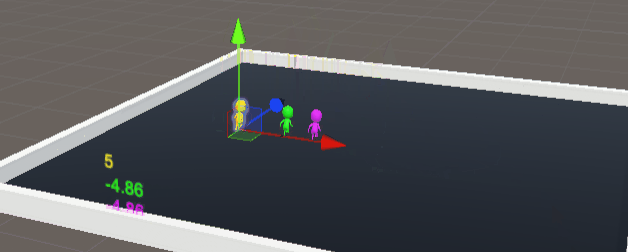
警察(黄色),贼1(绿色),贼2(紫色)
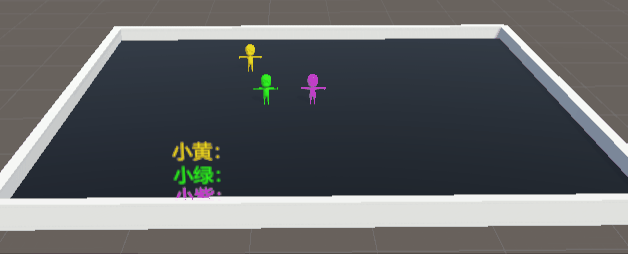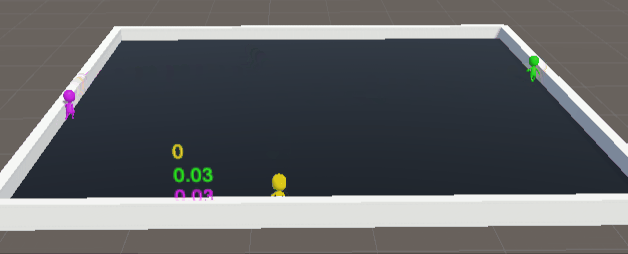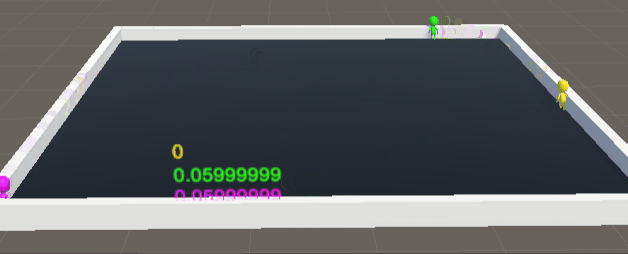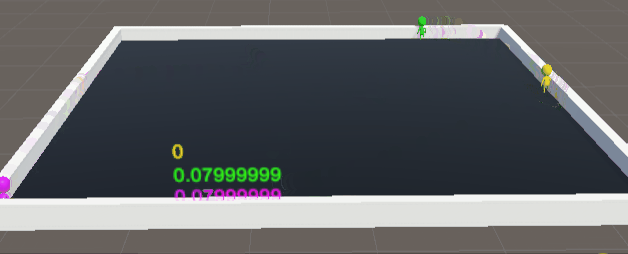
简直就是三个250,完完全全达不到博主想要的效果
再来看训练数据(TensorBoard):
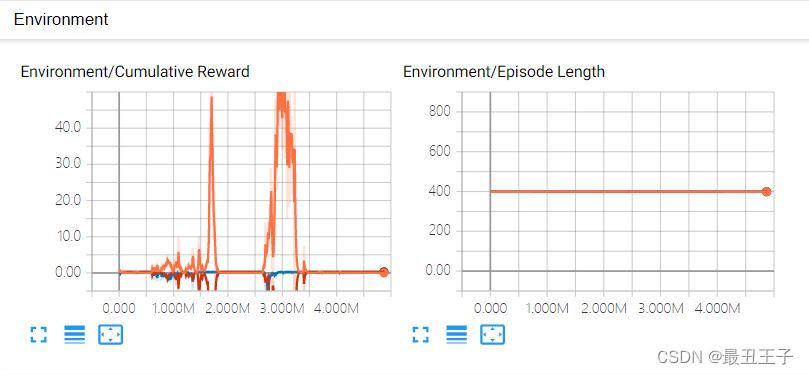
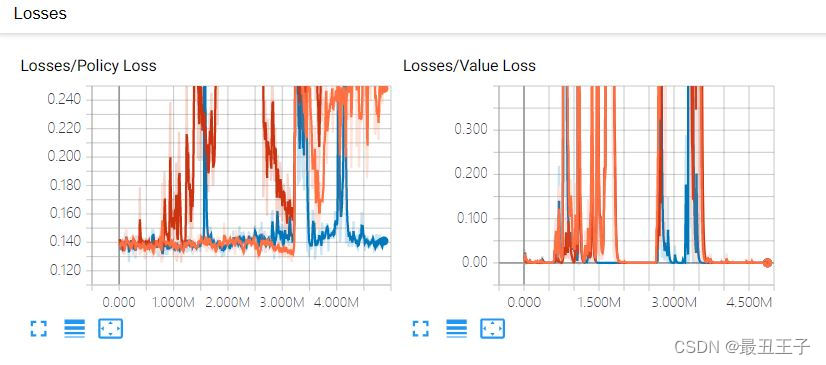
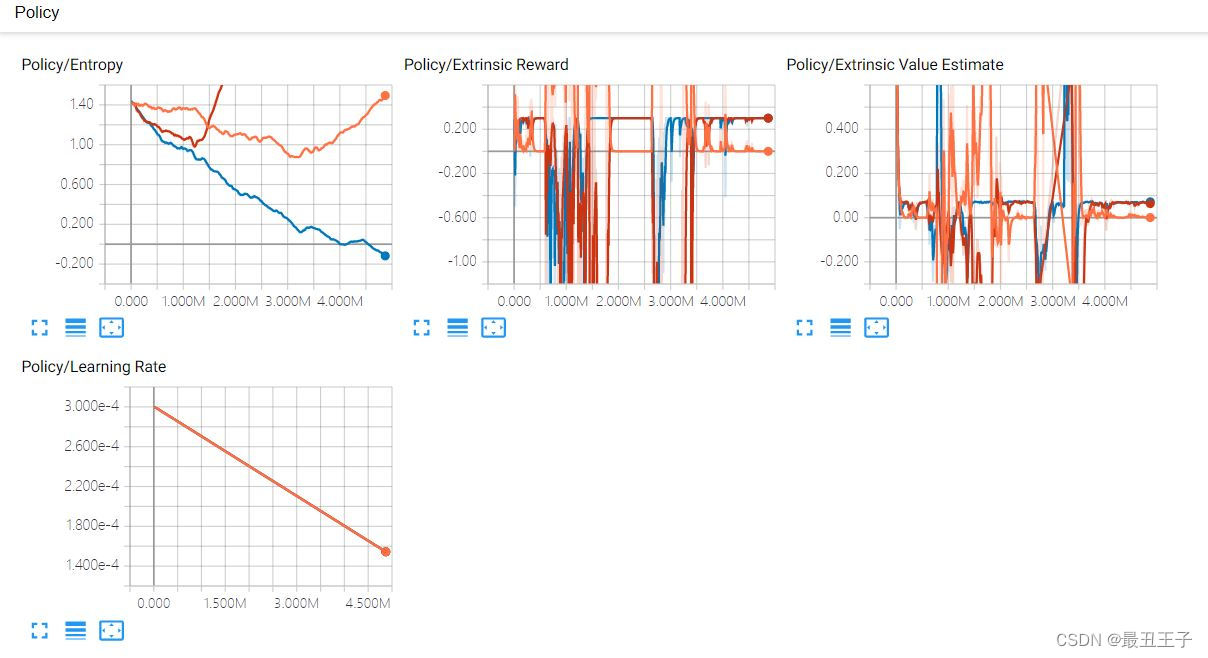
尝试引导式训练优化:我们去告诉智能体,“你”需要去做些什么,解除两个贼的神经网络,让它停止活动,让警明白,需要抓到两个贼才有奖励。
-
if(villager1.PoliceWin == true && villager2.PoliceWin == true) { AddReward(+1f); PolicScore += 1; EndEpisode(); } - 手动测试一下源码是否有问题
没有问题就开始我们的训练,训练次数设置为1000万次,然后开始我们的训练
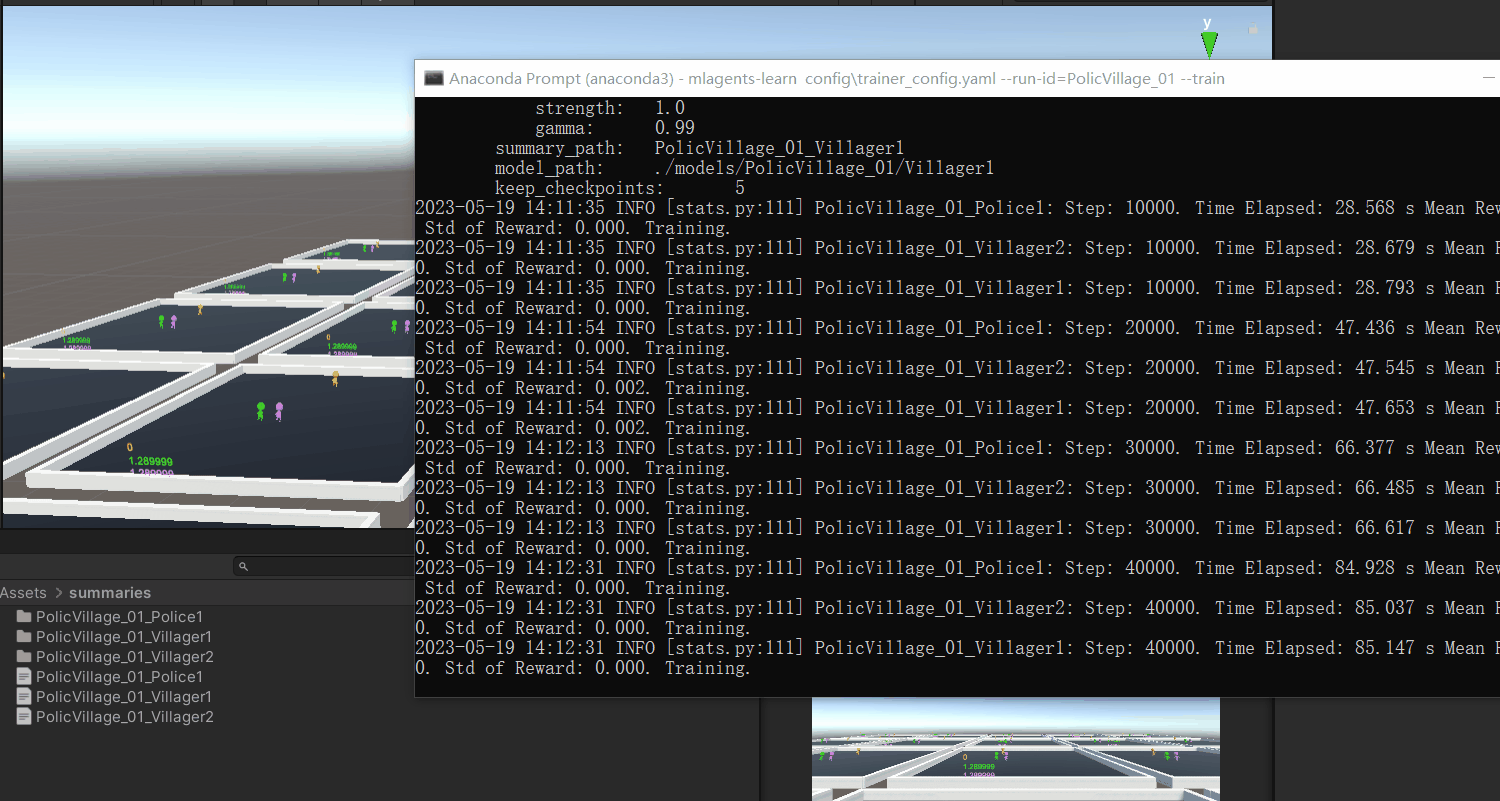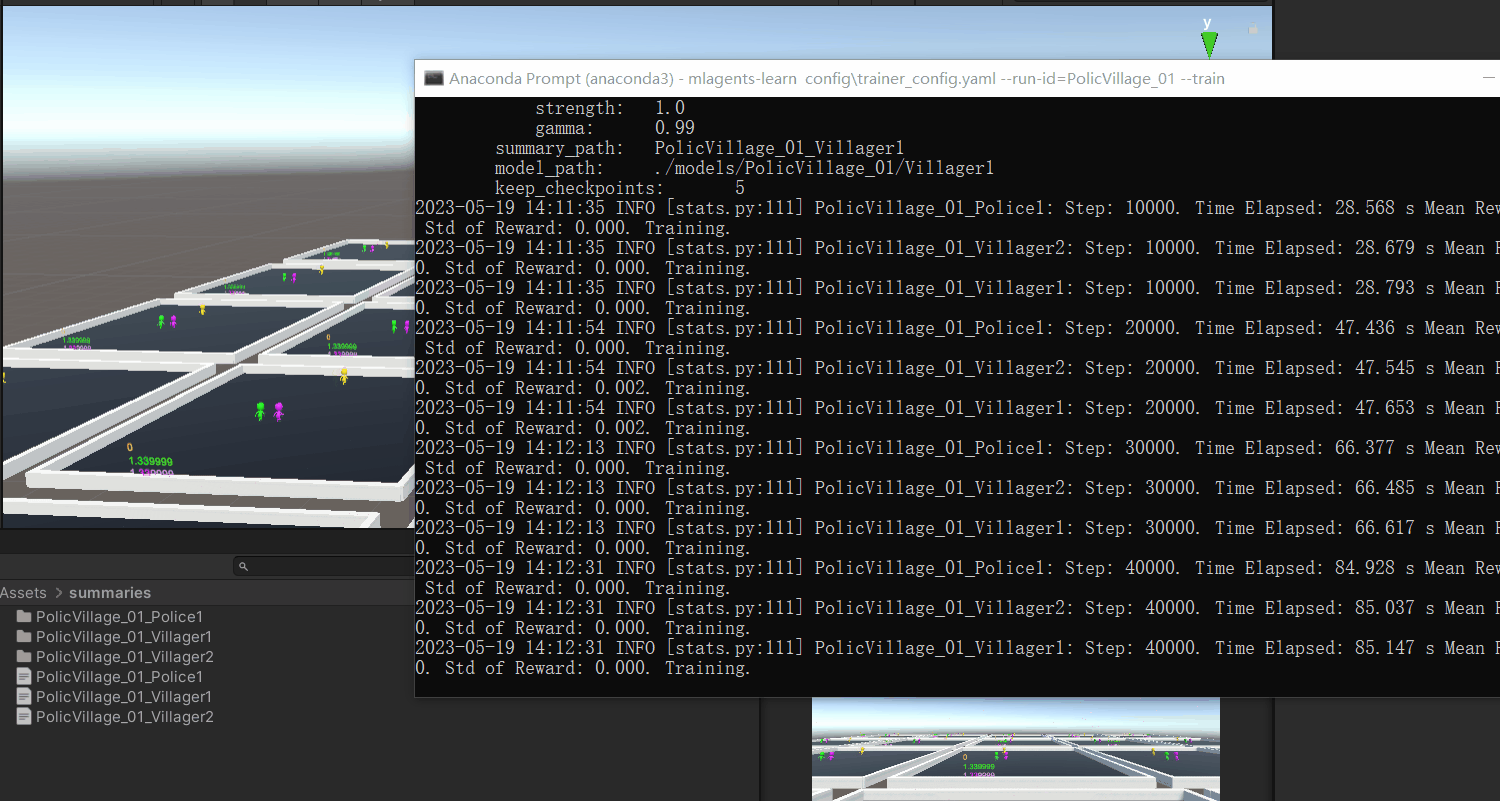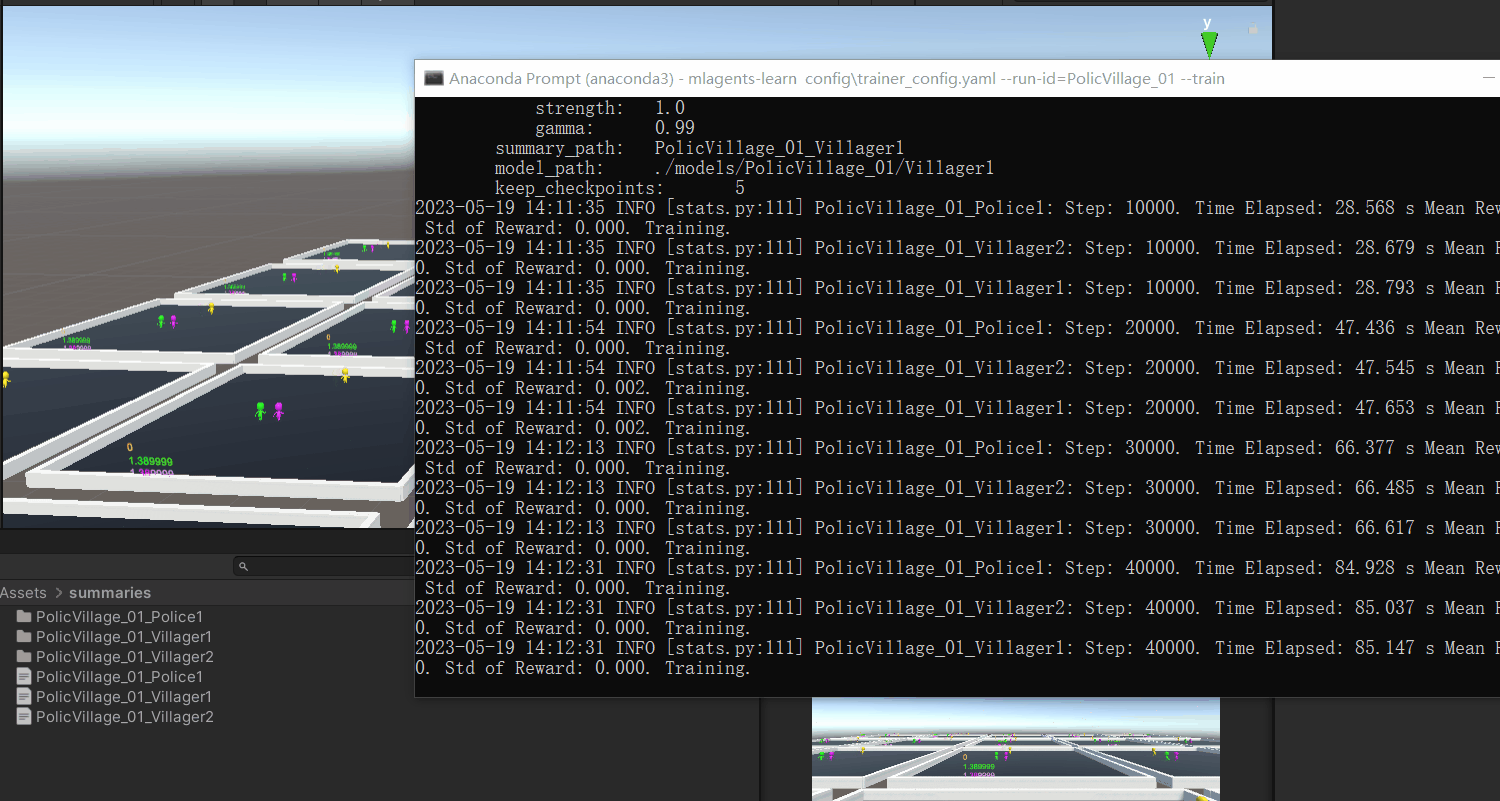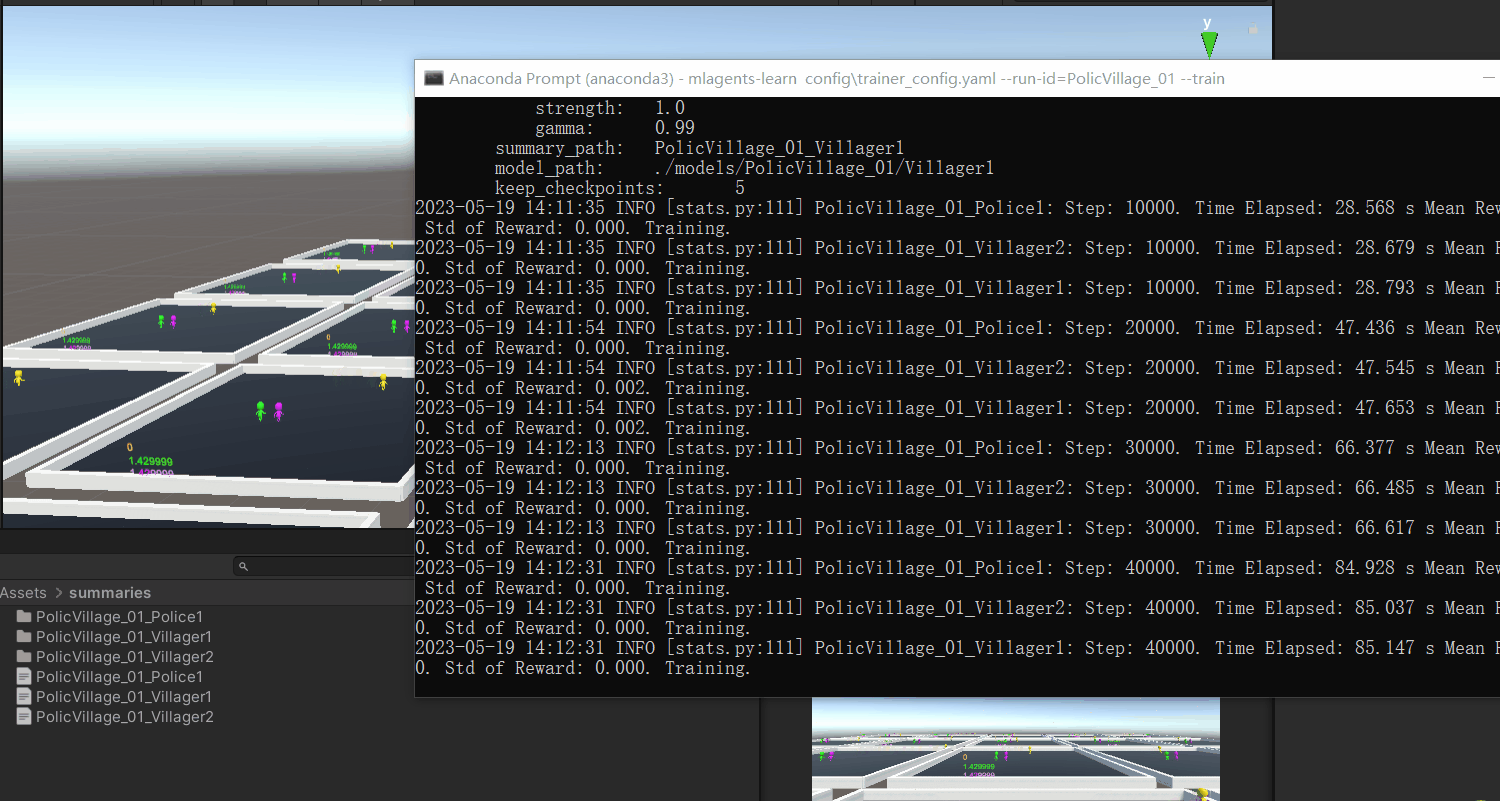
但是训练似乎还是受限制,警察不知道该如何获取分数,就算是无意中获取到了,警察也不能很好的继续延续下去,可能问题就是出现在这,或许是因为算法不合适导致的缘故。
既然如此,只能从更细微的事情开始引导训练,让警察知道要去抓小偷
下面是警察单独引导训练200万次结果,警察已经知道要去抓小偷。
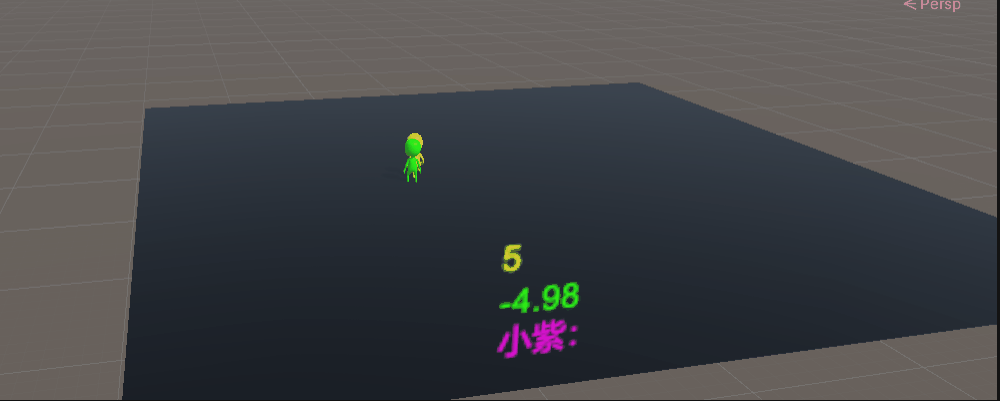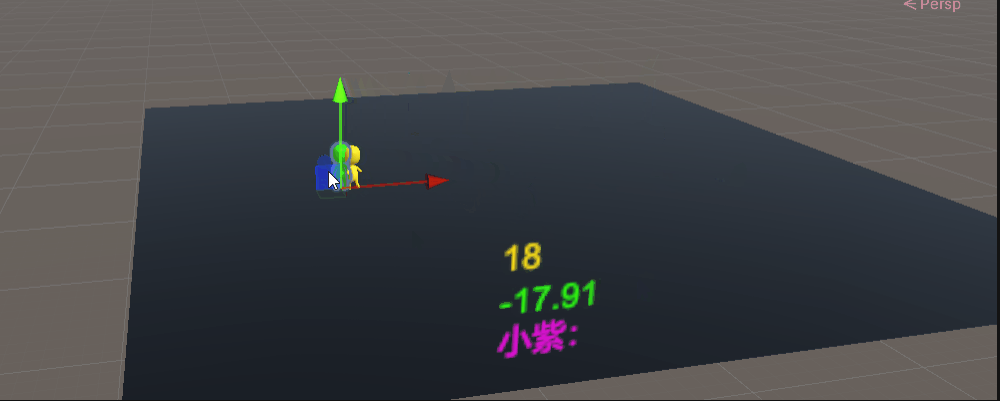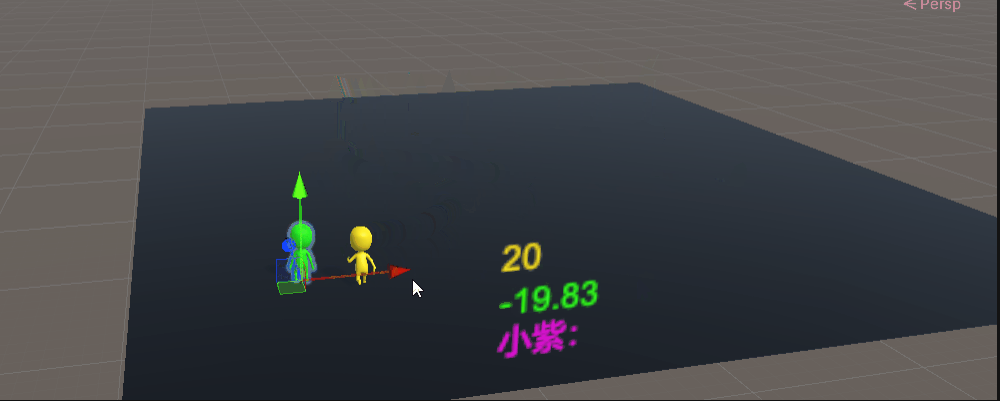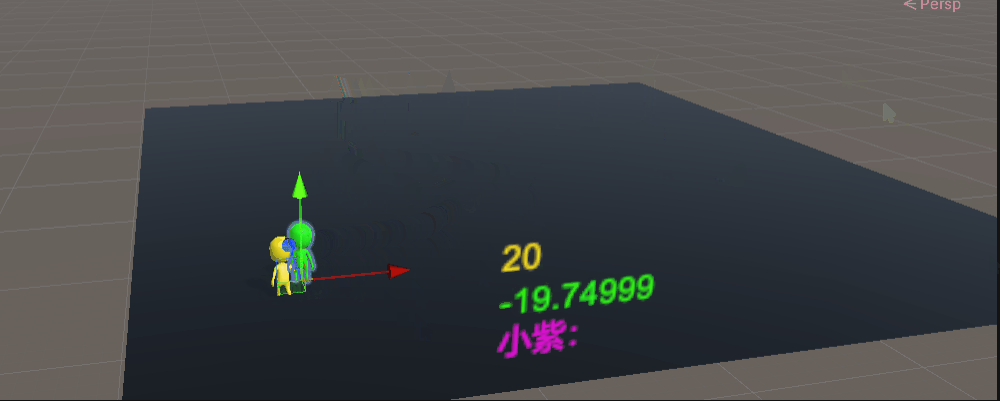
基于上面的模型我们开启小偷的神经网络进行对抗训练200万次
结果,小偷已经明白要躲避警察,还训练出蛇皮走位
很明显它们已经知道自己要干什么了,但基于训练量不够的缘故,还是会做出意想不到的事情,比如小偷“跳楼”躲避警察。
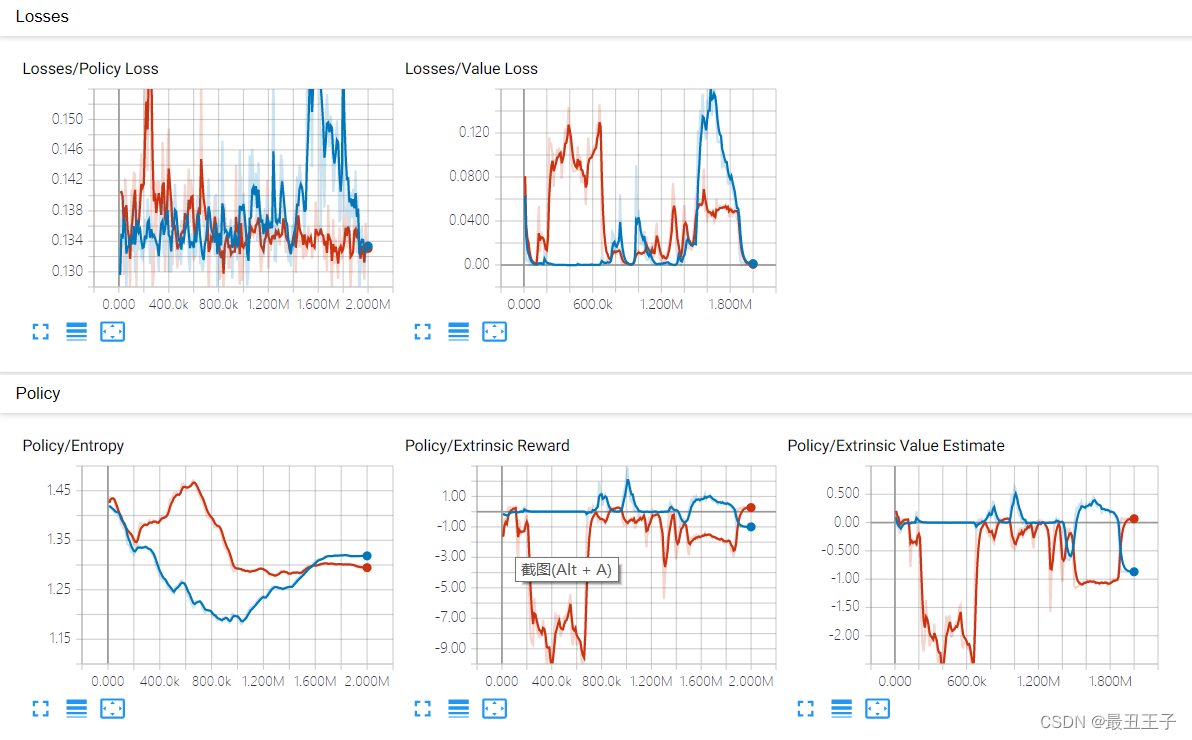
对比最初训练1000万次还是个只会“跳楼”的智能体我觉得是质的飞越,加入了引导式训练,大大减少了训练量,两个智能体也已经知道自己要做些什么。
继续扩大实验我们的项目
这次我们添加生成位置随机,使两个智能体的训练模式更为多元化和准确性
public override void OnEpisodeBegin()
{
float Px = UnityEngine.Random.Range(-25f, 25f);
float Pz = UnityEngine.Random.Range(-25f, 25f);
float Vx = UnityEngine.Random.Range(-25f, 25f);
float Vz = UnityEngine.Random.Range(-25f, 25f);
Villager1.transform.localPosition = new Vector3(Px, 0, Pz);
Villager1.velocity = Vector3.zero;
Villager1.rotation = Quaternion.Euler(Vector3.zero);
Villager1.angularVelocity = Vector3.zero;
Police1.transform.localPosition = new Vector3(Vx, 0, Vz);
Police1.velocity = Vector3.zero;
Police1.rotation = Quaternion.Euler(Vector3.zero);
Police1.angularVelocity = Vector3.zero;
}
可以看到我们的智能体在随机生成位置
大约500万次训练结果,可以看到我们的警察(有辅助训练)已经明白什么该做,什么不该做了,分数也在逐步增加,而小偷还在“跳楼”躲避警察。
训练1000万次结果,小偷学会了“跳楼躲避追缉”,警察已经知道自己不能够“跳楼”,而是要逮捕小偷。
可能是小偷没有辅助学习的缘故导致,我们加入小偷的辅助学习(取消警察神经网络,使用unity原生组件NavMashAgent,使警察只会跟随小偷)
可以看到,小偷已经会躲避警察的追捕,说实话,看到这一幕我的内心很激动,眼眶有点湿润,这证明了引导式训练这个思想是有效的 ,迫不及待,加上我们训练好的警察模型试试
警察小偷都明白自己要做什么了,我们在这基础上训练个1000万次试试
训练完成后,只有小偷的模型训练的很棒,警察会飞天,所以改用最初的模型,可以看到小偷已经会卡身法挑衅警察了哈哈哈哈,对比一下很容易就看出双方模型训练量了
基于这个模型,我们训练200万次
可以看到,警察已经会找到了方法,故意拉开身位去逮捕小偷,小偷也很谨慎,但不如警察智能体聪明
尾言:作者始终认为,每个行业都是在分歧中成长,到一致里落幕,因为这句话作者以前想去区块链,web3行业里发展,但那里让我感受到了迷茫看不到未来,我无法理解区块链为什么变成金融的衍生品,Ai行业我找到了很明确的目标,我知道我要去做什么,我能看到属于这个行业的未来,或许20年后我可能只是某个小区的保安,但这是我的落幕,不是行业的落幕。
说说警察抓贼这个项目我研究的经历吧,因为训练的缓慢,加上每次新想法实施后的失败,网络上关于训练优化的帖子少之又少,也没有老师伙伴去交流想法,最令我印象深刻的是有一天晚上舍友都不在,我一个人呆呆的看着电脑,在自言自语,记不清我说了什么,只记得我有这样过,上一次这样还是我炒股票的时候,新想法一次次满怀期待被错误的结果所击败,或许是因为我笨的原因吧哈哈哈,但好在我坚持了下来,这次学习的经历给我最大的礼物,我觉得不是训练成果,而是我明白了做事一定要从小事做起,先把小事做好。
知识是一个人面对困难的底气,而不是成为一个人的优越感,授人以鱼不如授人以渔,这才是我写文章的初衷
人生的幸福之一莫过于自己有明确的目标















 3164
3164











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









