






目录
赛题背景
在电动汽车充电站运营管理中,准确预测充电站的电量需求对于提高充电站运营服务水平和优化区域电网供给能力非常关键。本次赛题旨在建立站点充电量预测模型,根据充电站的相关信息和历史电量数据,准确预测未来某段时间内充电站的充电量需求。根据赛题提供的电动汽车充电站多维度脱敏数据,构造合理特征及算法模型,预估站点未来一周每日的充电量(以天为单位)。
Task1
-
跑通实践基线Baseline,获得自己的成绩
-
提交任务一打卡,查看个人成绩排行榜
Baseline精读
warnings.filterwarnings('ignore')忽略UserWarning警告
train_power_forecast_history = pd.read_csv('./训练集/power_forecast_history.csv') # 站点运营数据
train_power = pd.read_csv('./训练集/power.csv') # 站点充电量数据
train_stub_info = pd.read_csv('./训练集/stub_info.csv') # 站点静态数据train_df = train_power_forecast_history.groupby(['id_encode', 'ds']).head(1)
del train_df['hour']通过groupby函数根据'id_encode'和'ds'两列对数据进行分组,然后使用head(1)选择每个组的第一行数据,确保在训练中每个充电站在每天只有一个样本
删除hour是因为预估的充电量以天为单位,不需要hour这个特征
tmp_df = train_power.groupby(['id_encode', 'ds'])['power'].sum()
tmp_df.columns = ['id_encode', 'ds', 'power']
'''
output:
id_encode ds
0 20220415 2288.2240
20220416 2398.5730
20220417 2313.0330
20220418 2095.3259
20220419 1834.3590
...
499 20230410 653.9099
20230411 663.0800
20230412 678.3201
20230413 704.5300
20230414 658.4100
Name: power, Length: 149044, dtype: float64
'''对'id_encode'和'ds'两列对数据进行分组,并计算每个组中'power'列的总和
这里不显示power的列名是因为tmp_df是Series对象,是一维数据结构,不包含列名
# 合并充电量数据
train_df = train_df.merge(tmp_df, on=['id_encode', 'ds'], how='left')
# 合并数据
train_df = train_df.merge(train_stub_info, on='id_encode', how='left')
test_df = test_df.merge(test_stub_info, on='id_encode', how='left')以'id_encode'和'ds'两列为连接键,在左连接(how='left')的方式下,将充电量数据合并到训练集中的相应日期和充电站
左连接:左表中的每一行都会与右表中具有相同连接键的行进行匹配。如果右表中有多个匹配行,左表中的每一行都会和这些匹配行进行合并,并生成多行结果。如果右表中没有匹配的行,左表中的行也会被保留,但右表中的列将为空值
'train_stub_info'中没有'ds'特征
cols = ['power']
# 遍历id_encode的五个值,画前5天的图
for ie in [0, 1, 2, 3, 4]:
# 获取train_df中id_encode为当前值ie的所有行,并重置索引
tmp_df = train_df[train_df['id_encode'] == ie].reset_index(drop=True)
# 再次重置索引,并为新索引添加一个名为'index'的列
tmp_df = tmp_df.reset_index(drop=True).reset_index()
# 遍历要绘制的列
for num, col in enumerate(cols):
# 设置图的大小
plt.figure(figsize=(20, 10))
# 创建子图,总共有4行1列,当前为第num+1个子图
plt.subplot(4, 1, num + 1)
# 绘制图形:x轴为'index',y轴为当前列的值
plt.plot(tmp_df['index'], tmp_df[col])
# 为当前子图设置标题,标题为当前列的名称
plt.title(col)
# 显示图形
plt.show()
# 创建一个新的图,大小为20x5
plt.figure(figsize=(20, 5))第一次重置索引是因为tmp_df此时的索引不连续、乱序:
'''
MultiIndex([( 0, 20220415),
( 0, 20220416),
( 0, 20220417),
( 0, 20220418),
( 0, 20220419),
( 0, 20220420),
( 0, 20220421),
( 0, 20220422),
( 0, 20220423),
( 0, 20220424),
...
(499, 20230405),
(499, 20230406),
(499, 20230407),
(499, 20230408),
(499, 20230409),
(499, 20230410),
(499, 20230411),
(499, 20230412),
(499, 20230413),
(499, 20230414)],
names=['id_encode', 'ds'], length=149044)
'''重置索引可以更方便地进行数据操作和分析,尤其在可视化和绘图时,使用新的连续索引可以更准确地表示数据的顺序关系和趋势。再次重置后的索引:
'''
index id_encode ... ac_equipment_kw dc_equipment_kw
0 0 0 ... 0.0 1440.0
1 1 0 ... 0.0 1440.0
2 2 0 ... 0.0 1440.0
3 3 0 ... 0.0 1440.0
4 4 0 ... 0.0 1440.0
.. ... ... ... ... ...
360 360 0 ... 0.0 1440.0
361 361 0 ... 0.0 1440.0
362 362 0 ... 0.0 1440.0
363 363 0 ... 0.0 1440.0
364 364 0 ... 0.0 1440.0
[365 rows x 16 columns] <--一年365天
RangeIndex(start=0, stop=365, step=1)
'''plt.subplot(4, 1, num + 1) 创建了一个 4 行 1 列的子图布局。这意味着会创建一个包含 4 个子图的图形画布,这四个子图是按照从上到下的顺序排列的。当 num 的值为 0 时,表示第一个子图,位于布局的第一个位置(从上往下数)。当 num 的值为 1 时,表示第二个子图,以此类推
但是代码在这的col只有一个'power',所以只有一个子图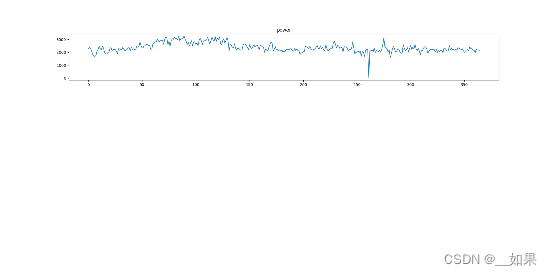
所以图片会显示在上部
# 数据预处理
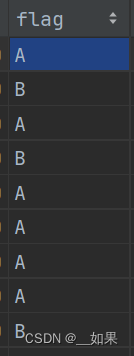
train_df['flag'] = train_df['flag'].map({'A': 0, 'B': 1})
test_df['flag'] = test_df['flag'].map({'A': 0, 'B': 1})
train_df.head() # 显示数据的前n行,默认前5行stub文件中的flag

def get_time_feature(df, col):
df_copy = df.copy() # 复制输入的数据框,以免直接修改原始数据
prefix = col + "_" # 前缀用于构造新的特征列名
df_copy['new_' + col] = df_copy[col].astype(str) # 新建一列,将原始时间列转换为字符串格式
# 此时的col:20220415
col = 'new_' + col # 更新要操作的列为新建的列
df_copy[col] = pd.to_datetime(df_copy[col], format='%Y%m%d') # 将字符串格式的时间列转换为日期格式
# 此时的col:2022-04-15
df_copy[prefix + 'year'] = df_copy[col].dt.year # 提取年份特征
df_copy[prefix + 'month'] = df_copy[col].dt.month # 提取月份特征
df_copy[prefix + 'day'] = df_copy[col].dt.day # 提取日期特征
df_copy[prefix + 'dayofweek'] = df_copy[col].dt.dayofweek # 提取星期几特征
df_copy[prefix + 'is_wknd'] = df_copy[col].dt.dayofweek // 6 # 提取是否为周末特征
df_copy[prefix + 'quarter'] = df_copy[col].dt.quarter # 提取季度特征
df_copy[prefix + 'is_month_start'] = df_copy[col].dt.is_month_start.astype(int) # 提取是否为月初特征
df_copy[prefix + 'is_month_end'] = df_copy[col].dt.is_month_end.astype(int) # 提取是否为月末特征
del df_copy[col] # 删除原始时间列
return df_copy # 返回包含新特征的数据框副本将原始时间'ds'的类型是<class 'pandas.core.series.Series'>,不转成str也可以,lightgbm 会自动处理整数类型的特征
format='%Y%m%d'指年月日
dt.is_month_end和dt.is_month_start提取出的数据类型为bool,用astype转为int
def cv_model(clf, train_x, train_y, test_x, seed=2023):
# 定义折数并初始化KFold
folds = 5
kf = KFold(n_splits=folds, shuffle=True, random_state=seed)
# 初始化oof预测和测试集预测
oof = np.zeros(train_x.shape[0])
test_predict = np.zeros(test_x.shape[0])
cv_scores = []
# KFold交叉验证
for i, (train_index, valid_index) in enumerate(kf.split(train_x, train_y)):
print('************************************ {} ************************************'.format(str(i + 1)))
trn_x, trn_y, val_x, val_y = train_x.iloc[train_index], train_y[train_index], train_x.iloc[valid_index], \
train_y[valid_index] # 将训练集划分为训练集和验证集
# 转换数据为lightgbm数据格式
train_matrix = clf.Dataset(trn_x, label=trn_y)
valid_matrix = clf.Dataset(val_x, label=val_y)
# 定义lightgbm参数
params = {
'boosting_type': 'gbdt',
'objective': 'regression',
'metric': 'rmse',
'min_child_weight': 5,
'num_leaves': 2 ** 7,
'lambda_l2': 10,
'feature_fraction': 0.8,
'bagging_fraction': 0.8,
'bagging_freq': 4,
'learning_rate': 0.1,
'seed': 2023,
'nthread': 16,
'verbose': -1,
# 'device':'gpu'
}
# 训练模型
model = clf.train(params, train_matrix, 3000, valid_sets=[train_matrix, valid_matrix], categorical_feature=[])
# 获取验证和测试集的预测值
val_pred = model.predict(val_x, num_iteration=model.best_iteration)
test_pred = model.predict(test_x, num_iteration=model.best_iteration)
oof[valid_index] = val_pred
test_predict += test_pred / kf.n_splits
# 计算并打印当前折的分数
score = np.sqrt(mean_squared_error(val_pred, val_y))
cv_scores.append(score)
print(cv_scores)
return oof, test_predictoof是训练集的交叉验证预测
for i, (train_index, valid_index) in enumerate(kf.split(train_x, train_y)):这里的kf.split是用于把整个训练集切分为k份,也就是将train_x与train_y分别分割成k份,k-1份作为训练集,剩余的1份作为验证集
parameters:
-
boosting_type:指定了 boosting 算法的类型,这里是 'gbdt',表示使用基于梯度提升的决策树算法。 -
objective:指定了模型的目标函数,这里是 'regression',表示进行回归任务。 -
metric:指定了模型的评估指标,这里是 'rmse',表示使用均方根误差(Root Mean Squared Error)作为评估指标。 -
min_child_weight:决定了叶子节点分裂的最小样本权重和。这个参数设置为 5,意味着一个叶子节点至少需要包含 5 个样本才会继续分裂。 -
num_leaves:控制了每棵树的叶子节点个数,这里设置为2 ** 7,即 128。 -
lambda_l2:L2 正则化的参数,用于控制模型的复杂度。 -
feature_fraction:每次迭代时使用的特征的比例。这里设置为 0.8,表示每棵树可以使用 80% 的特征进行训练。 -
bagging_fraction:每次迭代时用于训练的样本的比例。这里设置为 0.8,表示每棵树可以使用 80% 的样本进行训练。 -
bagging_freq:控制了进行 bagging 的频率。这里设置为 4,表示每 4 个迭代进行一次 bagging。 -
learning_rate:控制了每次迭代时模型权重更新的步长。这里设置为 0.1,表示每次迭代权重更新的步长为 0.1。 -
seed:随机种子,用于控制模型的随机性。 -
nthread:指定进行多线程训练的线程数量。 -
verbose:控制了训练过程中的打印信息的详细程度。设置为 -1 表示不打印训练过程中的任何信息。
对上面的参数:
Bagging 的频率控制了进行 Bagging 的次数或间隔,在模型训练过程中,每次进行 Bagging 实际上是对训练数据进行了随机采样,通过采样得到的子样本训练出一个决策树模型
clf.train中valid_sets 参数用于传入验证数据集,我感觉按理来说是不应该传train_matrix进去的,但是实践后发现传不传影响都不大;categorical_feature 参数用于指定分类特征,categorical_feature=[] 的空列表表示没有显式地指定任何特征为分类特征,即所有特征都被当做连续值处理。
num_iteration=model.best_iteration:如果在训练过程中启用了提前停止, 可以用 .best_iteration 从最佳迭代中获得预测结果
知识深究
groupby
作用:进行数据的分组以及分组后地组内运算
单类分组
如果我们想按照性别分组:
A.groupby("性别").describe().unstack()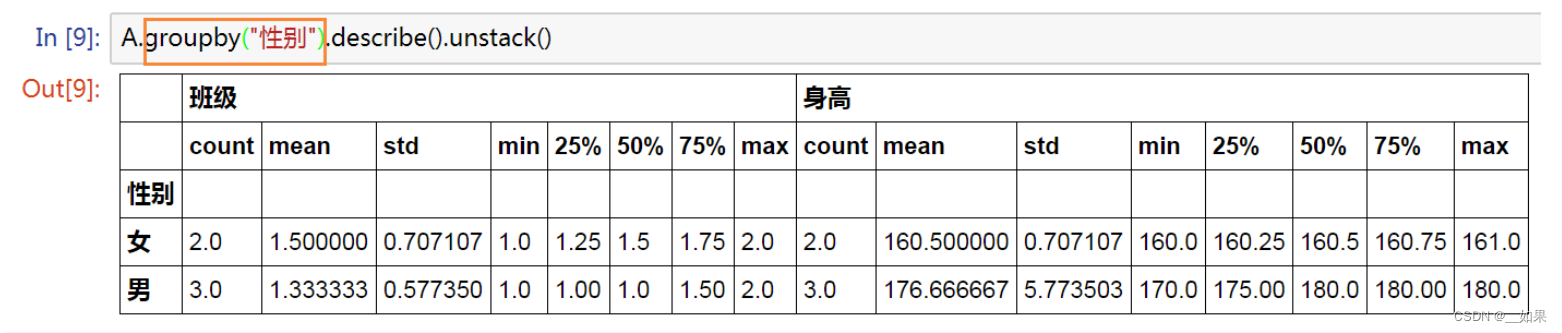
从左边一列可以看出已经按照男女分组了
这里的姓名没了是因为describe只统计数字类型的列数据
unstack函数用于将最内层的行索引变成列
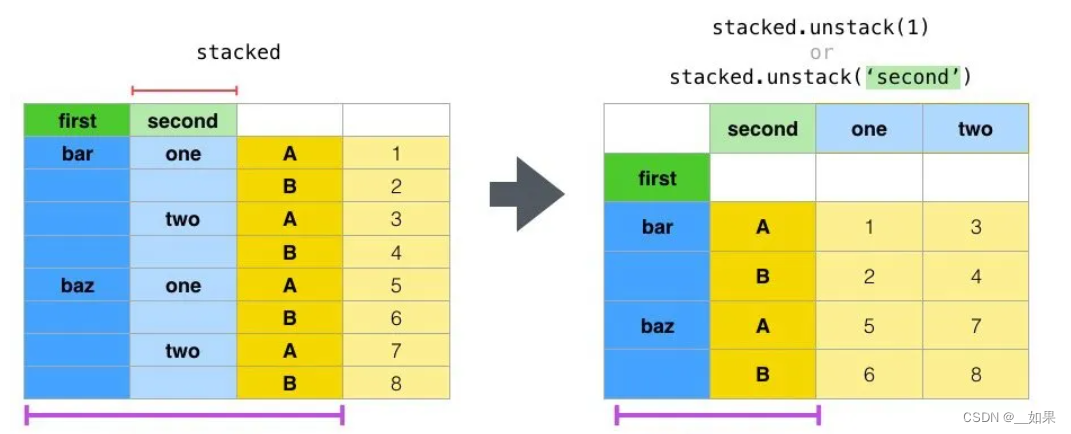
如果我们只需要身高的话:
A.groupby("性别")["身高"].describe().unstack()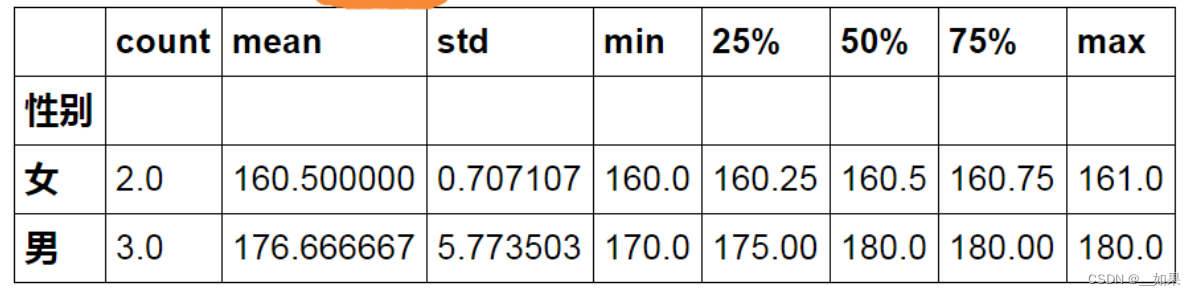
多类分组
A.groupby( ["班级","性别"])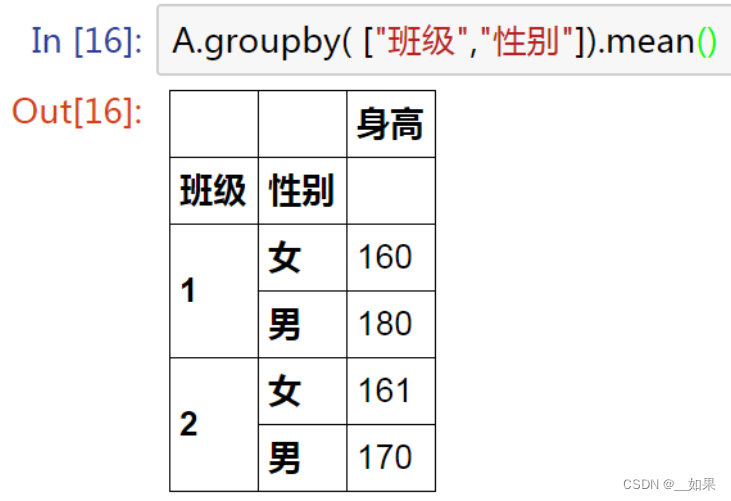
一次运用多个函数计算:
A.groupby( ["班级","性别"]).agg([np.sum, np.mean, np.std]) # 一次计算了三个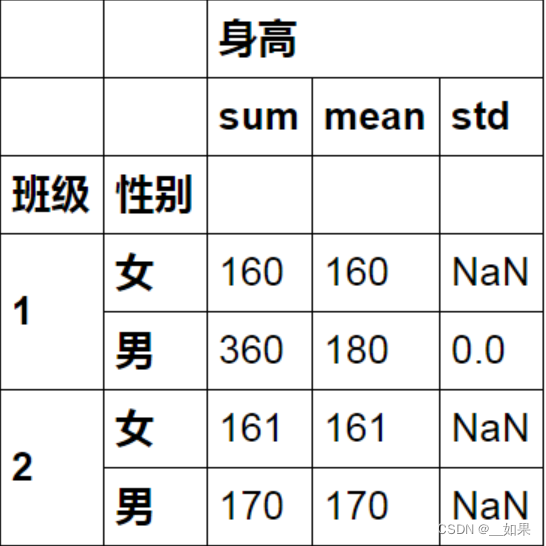
代码实操:
1、按照【生日】的【年份】进行分组,看看有多少人是同龄?
A["生日"] = pd.to_datetime(A["生日"],format ="%Y/%m/%d") # 转化为时间格式
A.groupby(A["生日"].apply(lambda x:x.year)).count() # 按照【生日】的【年份】分组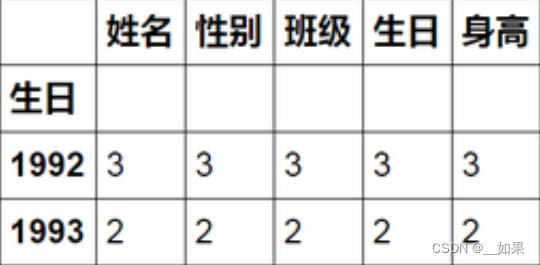
2、同一年作为一个小组,小组内生日靠前的那一位作为小队长
A.sort_values("生日", inplace=True) # 按时间排序
A.groupby(A["生日"].apply(lambda x:x.year),as_index=False).first() # 或者head(1)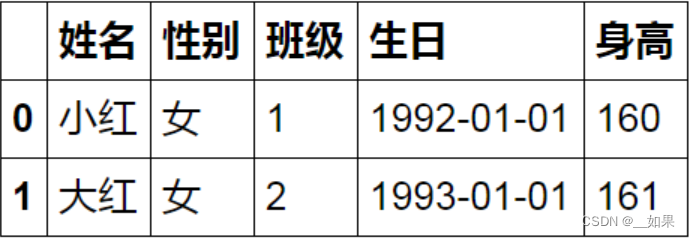
as_index=False :保持原来的数据索引结果不变
first() :保留第一个数据
tail(n=1) :保留最后n个数据
3、想要找到哪个月只有一个人过生日
A.groupby(A["生日"].apply(lambda x:x.month),as_index=False) # 到这里是按月分组
A.groupby(A["生日"].apply(lambda x:x.month),as_index=False).filter(lambda x: len(x)==1)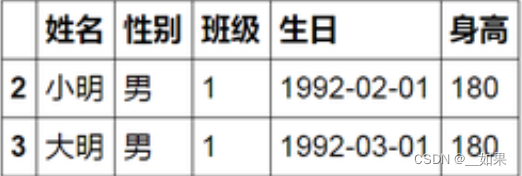
filter() :对分组进行过滤,保留满足()条件的分组
单类与多类对比
指定多个列名个单个列名后的区别在于,分组的主键或者索引(indice)将一个是单个主键,另一个则是一个元组的形式
其它知识
(1)通过groupby()函数分组得到的是一个DataFrameGroupBy对象,而通过对这个对象调用get_group(),返回的则是一个DataFrame对象,而DataFrame对象按照列名进行索引实际上就是得到了Series的对象
(2)如果DataFrameGroupBy对象可以使用的函数无法满足你的需求,你也可以选择使用聚合函数aggregate,传递numpy或者自定义的函数,前提是返回一个聚合值
def getSum(data):
total = 0
for d in data:
total+=d
return total
print(grouped.aggregate(np.median))
print(grouped.aggregate({'Age':np.median, 'Score':np.sum}))
print(grouped.aggregate({'Age':getSum}))aggregate函数不同于apply,前者是对所有的数值进行一个聚合的操作,而后者则是对每个数值进行单独的一个操作
(3)可视化操作
对组内的数据绘制概率密度分布
grouped['Age'].plot(kind='kde', legend=True)
plt.show()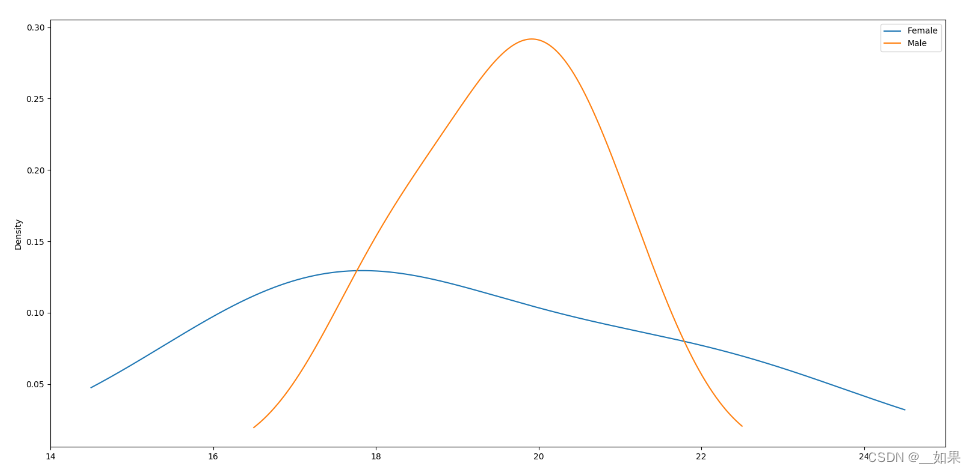
pandas .dt.
1.dt.date 和 dt.normalize(),他们都返回一个日期的 日期部分,即只包含年月日。但不同的是date返回的Series是object类型的,normalize()返回的Series是datetime64类型的。
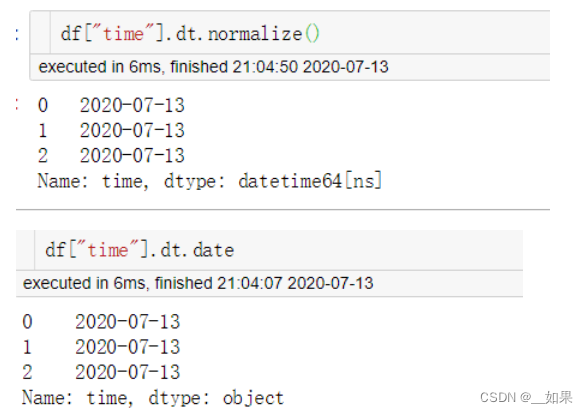
2.dt.year、dt.month、dt.day、dt.hour、dt.minute、dt.second、dt.week (dt.weekofyear和dt.week一样)分别返回日期的年、月、日、小时、分、秒及一年中的第几周
3.dt.weekday(dt.dayofweek一样)返回一周中的星期几,0代表星期一,6代表星期天,dt.weekday_name返回星期几的英文
4.dt.dayofyear 返回一年的第几天,dt.quarter得到每个日期分别是第几个季度
5.dt.is_month_start和dt.is_month_end 判断日期是否是每月的第一天或最后一天,可以将month换成year和quarter相应的判断日期是否是每年或季度的第一天或最后一天
6.dt.is_leap_year 判断是否是闰年
7.dt.month_name() 返回月份的英文名称
8.pd.to_datetime
pd.to_datetime(
arg,#int, float, str, datetime, list, tuple, 1-d array, Series DataFrame/dict-like
errors='raise',# {'ignore', 'raise', 'coerce'}, default 'raise'
dayfirst=False,
yearfirst=False,
utc=None,
format=None,#格式,比如 "%d/%m/%Y"
exact=True,
unit=None,#单位str, default 'ns',可以是(D,s,ms,us,ns)
infer_datetime_format=False,
origin='unix',#指定从什么时间开始,默认为19700101
cache=True,
)每日一问&群内讨论
【问题一】
Q:本次比赛的衡量指标是什么?和MSE的区别是什么?赛题中的评估指标常用于评测什么类型任务?由此可知比赛中应特别注意什么?
A:(1)RMSE均方根误差(2)在MSE基础上开了个方;RMSE 是均方误差的平方根,因此它具有与目标变量相同的单位,使得它更容易解释和比较(3)常用于评测回归任务,也就是预测连续数值型变量的值(4)由于RMSE是MSE的平方根,所以RMSE对异常值更加敏感,在比赛中应注意异常值的处理。
【问题二】
Q:下面两张图中,哪张欠拟合了,哪个过拟合了?为什么?
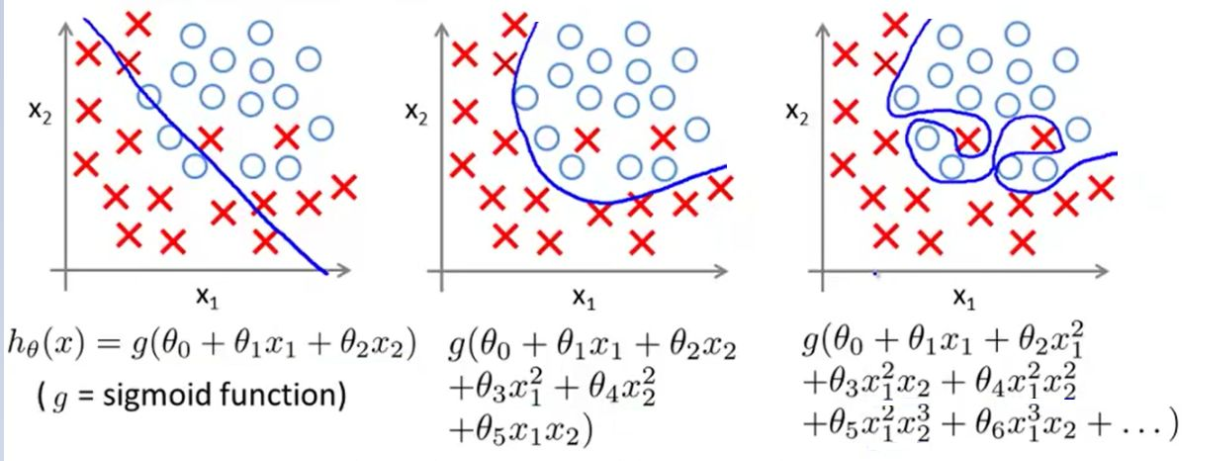
A:图片中的是多项式回归任务。图一左边的应该是欠拟合,没有将x与o正确分类,中间的是正常的,右边的是过拟合,原因在与x的n次方中的n这个超参数设置太大,导致对训练数据过于拟合,此时应引入正则化项来惩罚次数较高从而导致过大的系数;图二同理
【问题三】
Q:在机器学习中,以下哪些技术是数据清洗的相关技术?(需要解释选项)
A. 去除重复数据
B. 处理缺失值
C. 异常值处理
D. 数据标准化/归一化
A:ABC。数据归一化通常被认为是数据预处理的一部分,并不直接属于数据清洗的范畴。数据清洗是指通过检测和处理数据中的异常值、缺失值、重复值、错误值等问题,来提高数据的质量和准确性。尽管数据归一化可以帮助提高数据的可解释性和模型训练的效果,但它并不能解决数据中的异常或错误问题。数据清洗是在数据归一化之前进行的步骤,旨在处理和修复数据中的问题以确保数据的质量和准确性。
【问题四】
Q:在本赛题中你在数据探索方面做了哪些尝试?有什么感悟或者发现?
A:目前在数据探索的过程中发现,power字段有大量0值,并且存在长尾分布的现象,尝试进行对数转换后,对于lightgbm模型效果没有提升
——by张豆豆-国科大-北京
【问题五】
Q:
A:
群内讨论
数据挖掘全流程
Crisp-DM标准流程:
商业理解(行业)->数据理解(关系)->数据准备(质量)->建立模型(算法)->模型评估(标准)->发布模型
归一化 标准化的作用是啥?
将不同单位的指标可以进行比较(统一量纲);防止模型受个别数据的影响比重过大
xgboost,lightgbm是否需要提前归一化?是否需要onehot?



lightgbm与xgboost比较
时间序列不应该是预测未来吗?baseline用的是k折交叉验证,那不是有可能变成预测过去的某个时间了吗?

如果用错了模型,是不是再优化,也拿不到高分啊?

直播
之前随手写的笔记
在直播中学到了什么


直播资料
2023SEED大赛 - 新能源赛道数据探索_哔哩哔哩_bilibili
代码就不放出来了
Task2
| 任务2.1:
|
| 任务2.2:
|
| 任务2.3:
|
数据分析
数据探索性分析,是通过了解数据集,了解变量间的相互关系以及变量与预测值之间的关系,对已有数据在尽量少的先验假设下通过作图、制表、方程拟合、计算特征量等手段探索数据的结构和规律的一种数据分析方法,从而帮助我们后期更好地进行特征工程和建立模型,是机器学习中十分重要的一步。
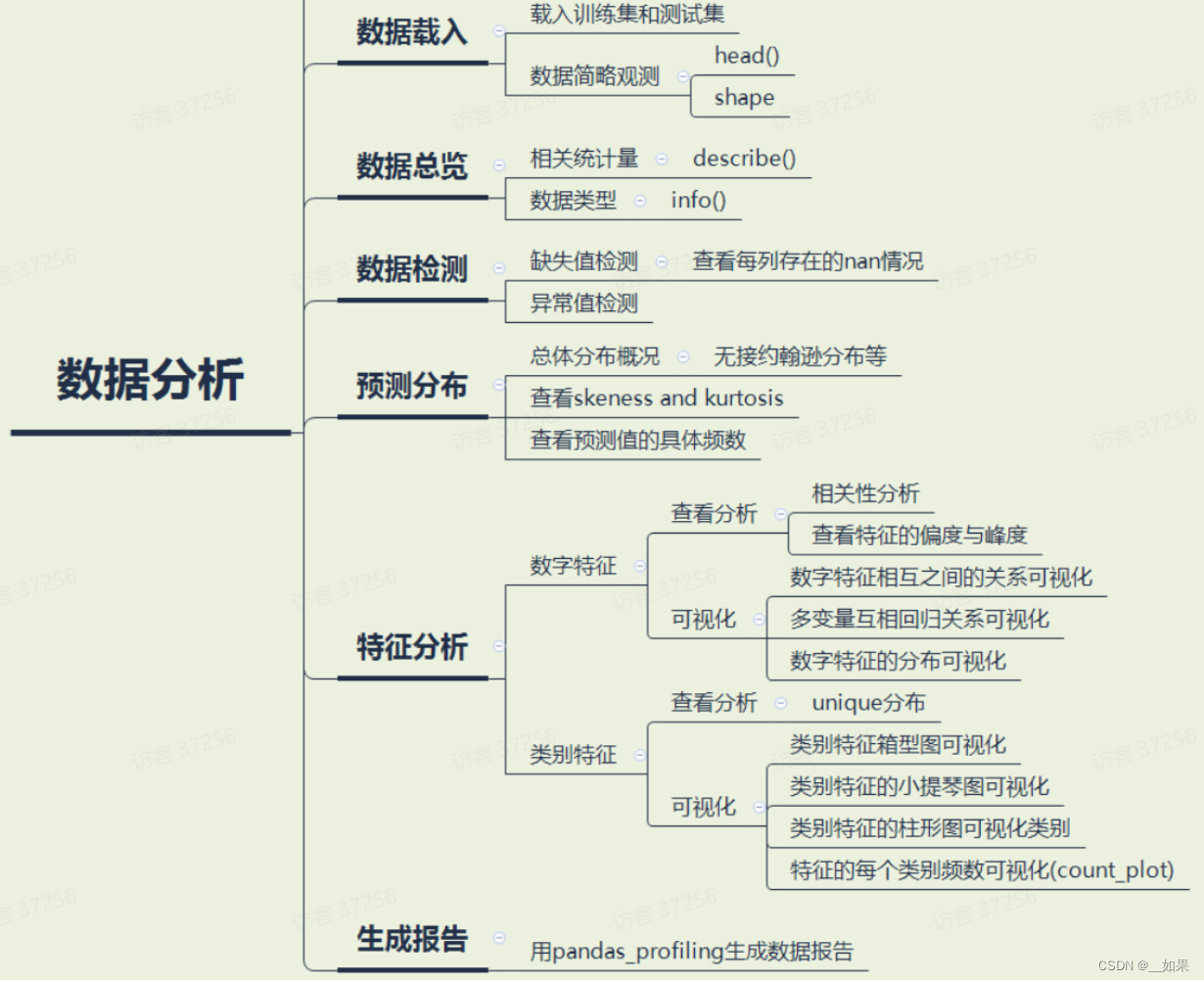
相关统计量
pandas describe:
import pandas as pd
c = pd.DataFrame({'categorical': pd.Categorical(['d', 'e', 'f']), 'numeric': [1, 2, 3], 'object': ['a', 'b', 'c']})
print(c)
desc = c.describe(include='all') # include='all',代表对所有列进行统计,如果不加这个参数,则只对数值列进行统计
print(desc)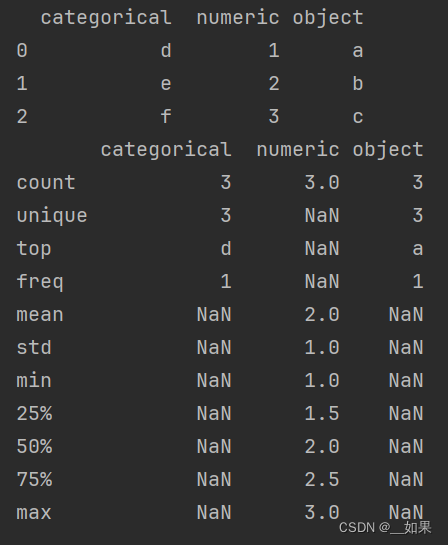
count~freq是对非数值数据进行describe,mean~max是对数值数据进行describe
count:数量统计,此列共有多少有效值
unipue:不同的值有多少个
std:标准差
min:最小值
25%:四分之一分位数
50%:二分之一分位数
75%:四分之三分位数
max:最大值
mean:均值top:出现最多的值
freq:最常见的值出现的频率
数据类型
DataFrame.info (self, verbose=None, buf=None, max_cols=None, memory_usage=None, null_counts=None)
int_values = [1, 2, 3, 4, 5]
text_values = ['alpha', 'beta', 'gamma', 'delta', 'epsilon']
float_values = [0.0, 0.25, 0.5, 0.75, 1.0]
df = pd.DataFrame({"int_col": int_values, "text_col": text_values,
"float_col": float_values})
df
df.info(verbose=True)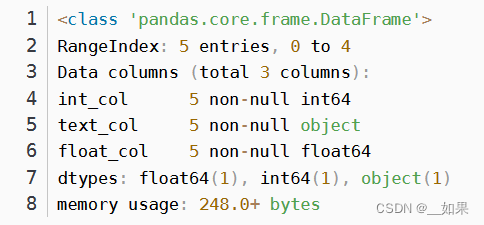
缺失值与异常值
之前做的笔记数据处理笔记(梧桐杯)-CSDN博客
lightgbm与xgboost是支持缺失值的

在LightGBM中默认是开启对缺失值进行处理的,不需要对缺失做额外操作,如果要将这个功能关闭可以通过参数完成use_missing=false,而关于0是否是缺失值,可以通过参数完成zero_as_missing=true, 默认情况下zero_as_missing=false
XGBoost处理缺失值的方法是将缺失值视为一个特殊的取值,在训练过程中通过学习一个默认分支来处理缺失值。具体来说,当在一个节点上遇到缺失值时,XGBoost会计算该特征在该节点上的权重,然后根据权重将样本分配到左子树或右子树。
LightGBM也使用了类似的方法来处理缺失值。它在选择切分点时,会考虑缺失值所在的特殊分支。LightGBM会为缺失值单独创建一个分支,让缺失值样本通过这个分支。同时,LightGBM也会计算缺失值在当前节点的权重,并根据权重进行样本的划分。
尽管XGBoost和LightGBM都利用了类似的思想来处理缺失值,但它们在具体实现上可能有一些细微的差别。此外,LightGBM还提供了一种更快速的方式来处理缺失值,称为直方图桶(Histogram Bucketing),它将连续特征的值按照一定的规则分桶,将缺失值单独作为一个桶进行处理。
lightgbm直方图加速
简单来说就是先对特征值进行装箱处理,形成一个一个的bins。对于连续特征来说,装箱处理就是特征工程中的离散化:如[0,0.3)—>0,[0.3,0.7)—->1等。在Lightgbm中默认的#bins为256(超参数)。对于分类特征来说,则是每一种取值放入一个bin,且当取值的个数大于max bin数时,会忽略那些很少出现的category值。
在节点分裂的时候,这时候就不需要按照预排序算法那样,对于每个特征都计算#data遍了,而是只需要计算#bins遍,这样就大大加快了训练速度。

最外面的 for 循环表示的意思是对当前模型下所有的叶子节点处理,需要遍历所有的特征,来找到增益最大的特征及其划分值,以此来分裂该叶子节点。
在某个叶子上,第二个 for 循环就开始遍历所有的特征了。对于每个特征,首先为其创建一个直方图。这个直方图存储了两类信息,分别是每个bin中样本的梯度之和,还有就是每个bin中样本数量
第三个 for 循环遍历所有样本,累积上述的两类统计值到样本所属的bin中。即直方图的每个 bin 中包含了一定的样本,在此计算每个 bin 中的样本的梯度之和并对 bin 中的样本记数。
最后一个for循环,遍历所有bin,分别以当前bin作为分割点,累加其左边的bin至当前bin的梯度和以及样本数量,并与父节点上的总梯度和以及总样本数相减,得到右边所有bin的梯度和以及样本数量,带入公式,计算出增益,在遍历过程中取最大的增益,以此时的特征和bin的特征值作为分裂节点的特征和分裂特征取值。
Q:如何将特征映射到bin呢?即如何分桶?对于连续特征和类别特征分别怎么样处理?
A:
-
连续特征的分桶:
- 对于连续特征,首先需要对其进行离散化处理,将连续的取值划分成多个桶。
- LightGBM中有几种离散化的方法可供选择,比如等频切分和等距切分。等频切分将特征值划分为相同数量的桶,而等距切分则根据特征值的范围和桶的数量来确定切分点。
- 另外,在LightGBM中,也实现了一种基于直方图的切分算法。该算法会根据特征值的分布情况,自适应地选择合适的切分点,使得每个桶的样本数量尽量均匀。
-
类别特征的分桶:
- 对于类别特征,每个取值都视作一个独立的桶。这意味着每个类别特征的取值都会映射到一个特定的桶中。
- LightGBM的处理方式是将类别特征的取值转换为整数编码,并直接作为桶的索引。
Q:如何构建直方图?直方图算法累加的g是什么?难道没有二阶导数h吗?
-
直方图构建步骤:
- LightGBM首先对每个特征进行分桶,将特征的取值划分为多个离散的桶。
- 然后,LightGBM将训练数据集中的样本按照特征的桶划分组织成直方图,将每个桶的样本计数器进行累加。
-
直方图中的g值:
- 在构建直方图的同时,LightGBM会为每个桶维护一个梯度统计量 g。
- g 值代表特征值所在桶中样本的梯度之和。在训练过程中,g 值是计算增益的重要参数之一。
-
梯度和二阶导数 h 的使用:
- LightGBM中的直方图算法主要利用一阶梯度 g 进行增益计算和分桶过程,而没有直接使用二阶导数 h。
- 具体来说,在计算增益时,LightGBM使用梯度 g 的平方来代替二阶导数 h 的概念,从而避免了对二阶导数的计算和存储开销。
总体分布状况
import scipy.stats as st
y = train_data['col']
plt.figure(1); plt.title('Johnson SU')
sns.distplot(y, kde=False, fit=st.johnsonsu) # 无接约翰逊分布
plt.figure(2); plt.title('Normal')
sns.distplot(y, kde=False, fit=st.norm) # 正态分布
plt.figure(3); plt.title('Log Normal')
sns.distplot(y, kde=False, fit=st.lognorm) # 对数正态分布通过观察画出来的拟合线与实际数据的贴合程度,可以初步判断数据的分布类型。
在这次的赛题中,power是符合无接约翰逊分布的
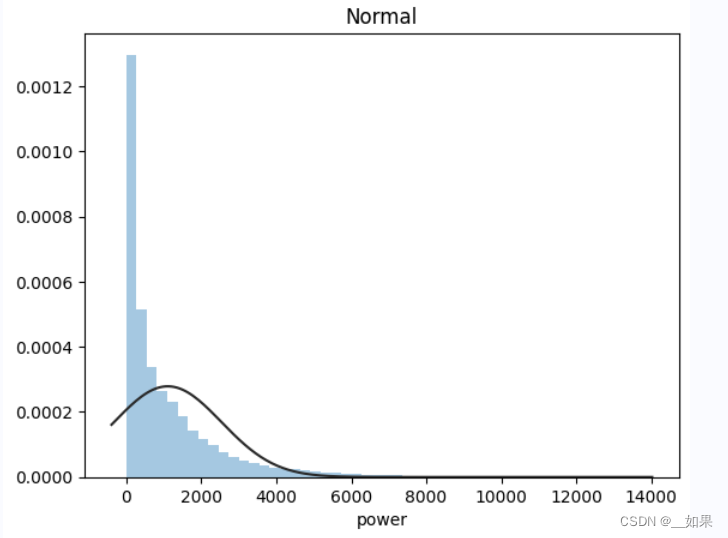
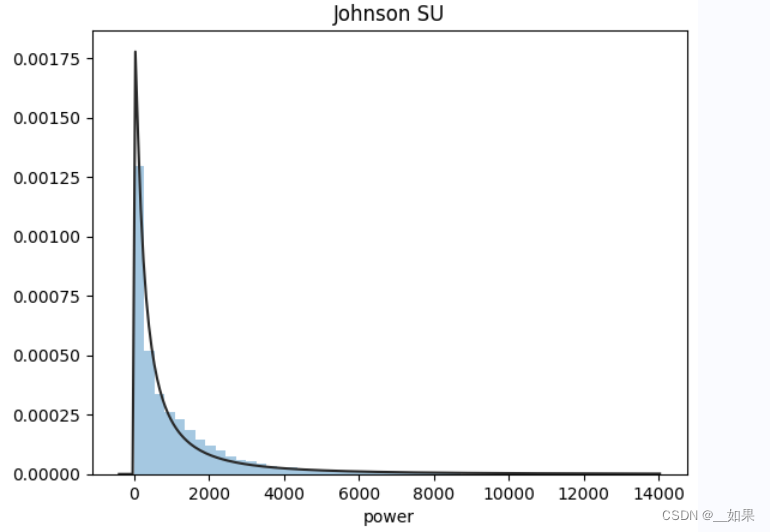
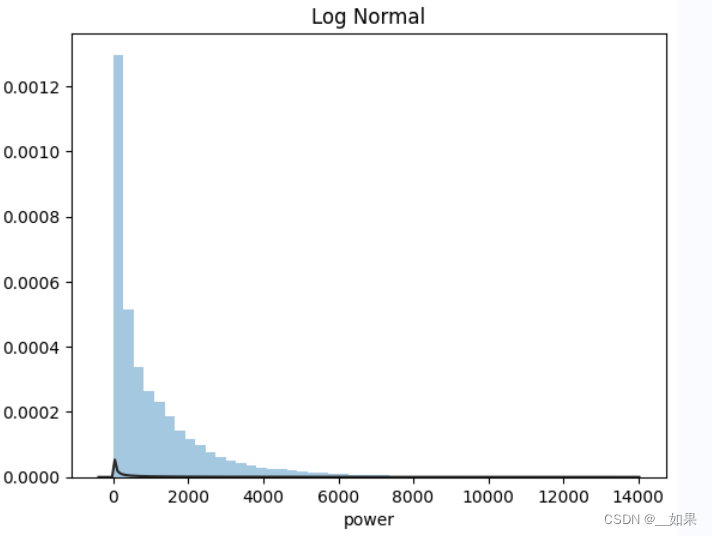
当样本数据表明质量特征的分布为非正态时,应用基于正态分布的方法会作出不正确的判决。约翰逊分布族即为经约翰变换后服从正态分布的随机变量的概率分布,约翰逊分布体系建立了三族分布,分别为有界SB对数正态SL和无界SU
skewness(偏度)与kurtosis(峰度)

sns.distplot(Train_data['col'])
print("Skewness: %f" % Train_data['col'].skew())
print("Kurtosis: %f" % Train_data['col'].kurt())
sns.distplot(Train_data.skew(),color='blue',axlabel ='Skewness')
sns.distplot(Train_data.kurt(),color='orange',axlabel ='Kurtness')本次比赛的skew图与kurt图:
预测值的具体频数
直方图:
plt.hist(Train_data['col'], orientation = 'vertical',histtype = 'bar', color ='red')
plt.show()
# log变换之后的分布较均匀,可以进行log变换进行预测,这也是预测问题常用的trick
plt.hist(np.log(Train_data['col']), orientation = 'vertical',histtype = 'bar', color ='red')
plt.show()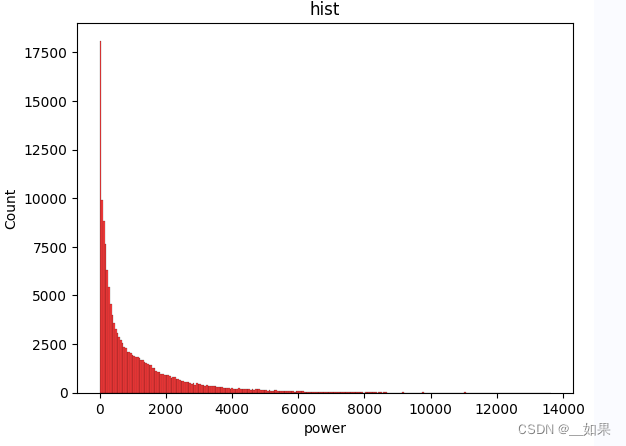
相关性分析
power = train_df['power']
correlation = train_df.corr()['power']
print(correlation.sort_values(ascending=False),'\n')
f, ax = plt.subplots(figsize=(7, 7))
plt.title('Correlation of Numeric Features with Power', y=1, size=16)
sns.heatmap(train_df.corr(), square=True, vmin=-1, vmax=1, cmap='coolwarm', annot=True, ax=ax)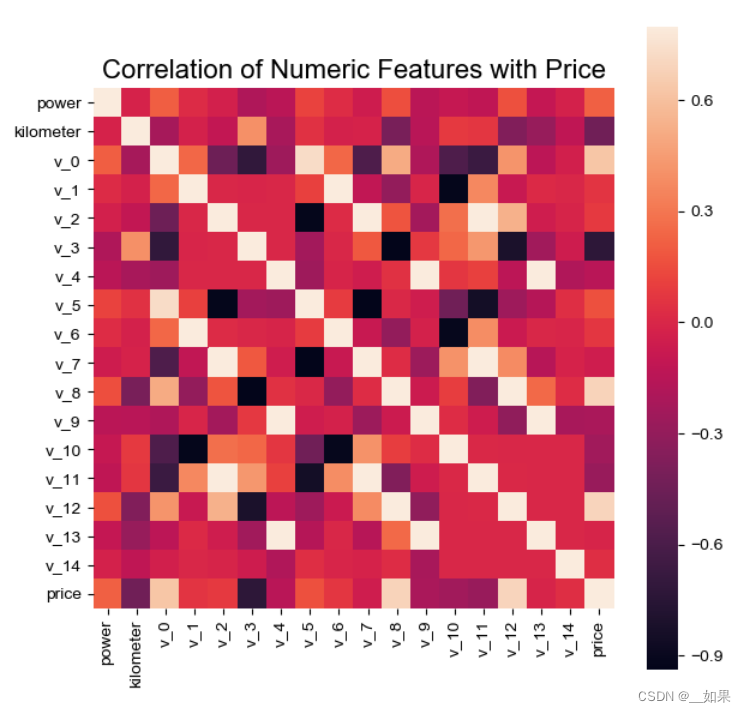
unique分布
pandas中Series和DataFrame的两种数据类型中都有nunique()和unique()方法。这两个方法作用很简单,都是求Series或Pandas中的不同值。而unique()方法返回的是去重之后的不同值,而nunique()方法则直接放回不同值的个数

如果Series或DataFrame中没有None值,则unique()方法返回的序列数据的长度等于nunique()方法的返回值(如上述代码中所展示的)。则当Series或DataFrame中有None值时,这两个就不一定相等了
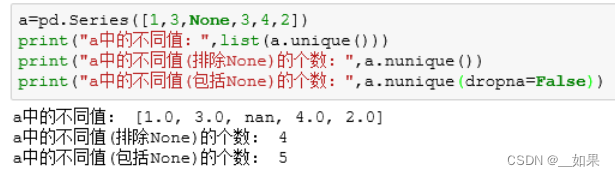
小提琴图
用于显示数据分布及概率密度,这种图表结合了箱形图和密度图的特征,主要用来显示数据的分布形状
catg_list = categorical_features
target = 'price'
for catg in catg_list :
sns.violinplot(x=catg, y=target, data=Train_data)
plt.show()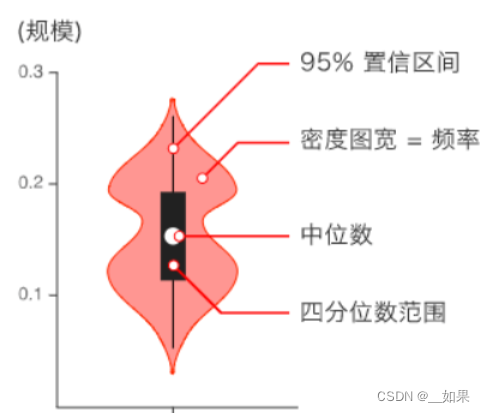
total_price数据太多了,一个个小提琴放一起变黑线了,一张图要跑蛮久的
数据清洗
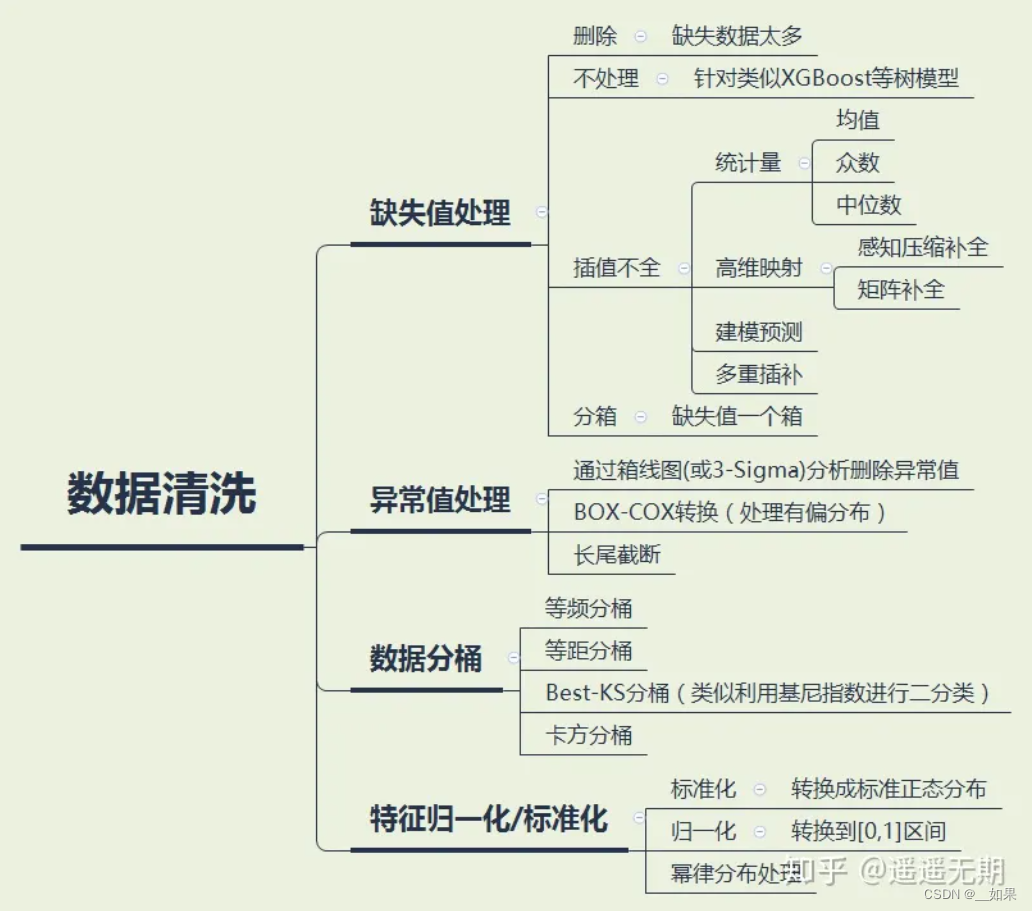
感知压缩补全
压缩感知:在采样过程中完成了数据压缩的过程
压缩感知理论:如果信号是稀疏的,那么它可以由远低于采样定理要求的采样点重建恢复
压缩感知的前提:
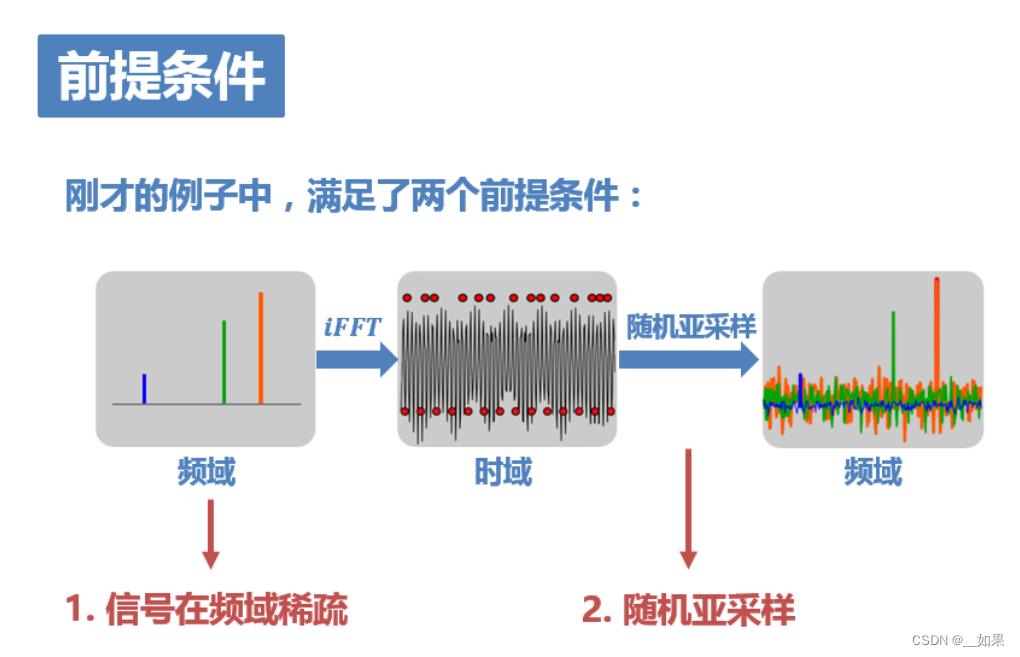
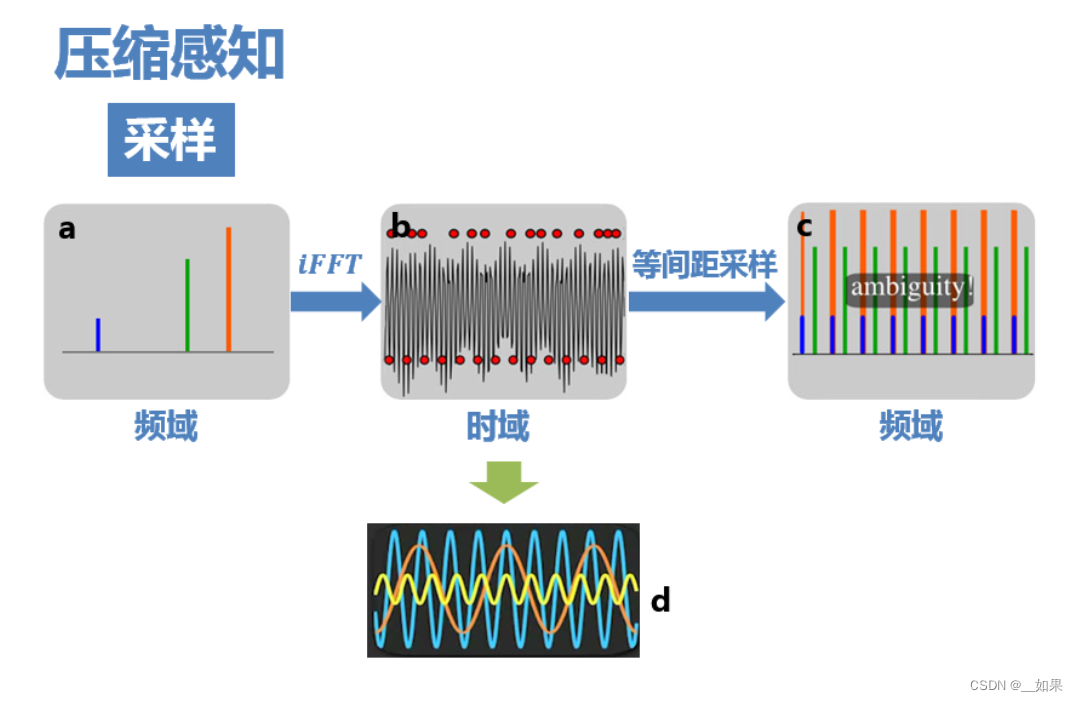
上图非常关键,它可以简单直观地表述压缩感知的思路。 如图b、d为三个余弦函数信号叠加构成的信号,在频域的分布只有三条线(图a)。 如果对其进行8倍于全采样的等间距亚采样(图b下方的红点),则频域信号周期延拓后,就会发生混叠(图c),无法从结果中复原出原信号
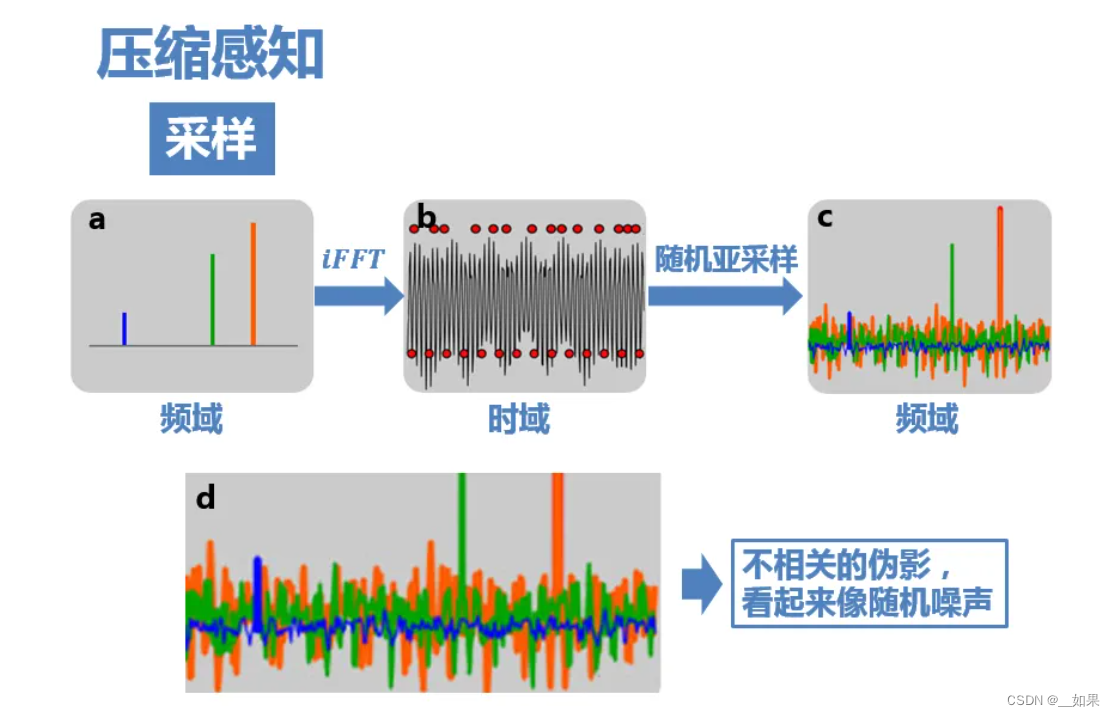
而如果采用随机亚采样(图b上方的红点),那么这时候频域就不再是以固定周期进行延拓了,而是会产生大量不相关(incoherent)的干扰值。如图c,最大的几个峰值还依稀可见,只是一定程度上被干扰值覆盖。这些干扰值看上去非常像随机噪声,但实际上是由于三个原始信号的非零值发生能量泄露导致的(不同颜色的干扰值表示它们分别是由于对应颜色的原始信号的非零值泄露导致的)
Q:为什么随机亚采样会有这样的效果?
A:这可以理解成随机采样使得频谱不再是整齐地搬移,而是一小部分一小部分胡乱地搬移,频率泄露均匀地分布在整个频域,因而泄漏值都比较小,从而有了恢复的可能。
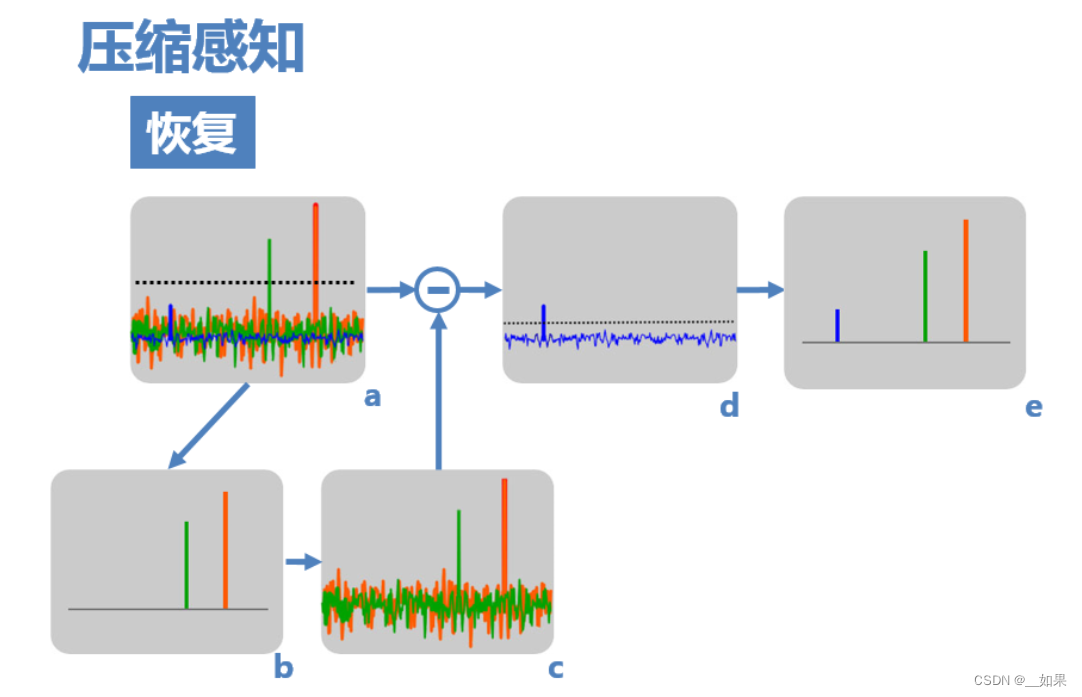
(1) 由于原信号的频率非零值在亚采样后的频域中依然保留较大的值,其中较大的两个可以通过设置阈值,检测出来(图a)。
(2) 然后,假设信号只存在这两个非零值(图b),则可以计算出由这两个非零值引起的干扰(图c)。
(3) 用a减去c,即可得到仅由蓝色非零值和由它导致的干扰值(图d),再设置阈值即可检测出它,得到最终复原频域(图e)
(4) 如果原信号频域中有更多的非零值,则可通过迭代将其一一解出。
压缩感知恢复数学原理:

矩阵补全
矩阵补全可以通过矩阵分解将一个含缺失值的矩阵 X 分解为两个(或多个)矩阵,然后这些分解后的矩阵相乘就可以得到原矩阵的近似 X',我们用这个近似矩阵 X' 的值来填补原矩阵 X 的缺失部分
数学支持:

缺失值分箱
data.x1 = data.x1.fillna(-1) # x1一般情况下只有正值
test.x1 = test.x1.fillna(-1)数据分桶
Q:为什么要将连续值经常离散化或者分离成“箱子”进行分析?
A:
- 离散后稀疏向量内积乘法运算速度更快,计算结果也方便存储,容易扩展;
- 离散后的特征对异常值更具鲁棒性,如 age>30 为 1 否则为 0,对于年龄为 200 的也不会对模型造成很大的干扰;
- LR 属于广义线性模型,表达能力有限,经过离散化后,每个变量有单独的权重,这相当于引入了非线性,能够提升模型的表达能力,加大拟合;
- 离散后特征可以进行特征交叉,提升表达能力,由 M+N 个变量变成 M*N 个变量,进一步引入非线形,提升了表达能力;
- 特征离散后模型更稳定,如用户年龄区间,不会因为用户年龄长了一岁就变化。但是处于区间连接处的值要小心处理,另外如何划分区间也是需要仔细处理。
等频分桶
将数据分成几等份,每等份数据里面的个数是一样的。比如说 N=10 ,每个区间应该包含大约10%的实例。pandas.qcut方法可以进行等频划分
df = pd.DataFrame([[22,1],[13,1],[33,1],[52,0],[16,0],[42,1],[53,1],[39,1],[26,0],[66,0]],columns=['age','Y'])
#print(df)
df['age_bin_1'] = pd.qcut(df['age'],3) #新增一列存储等频划分的分箱特征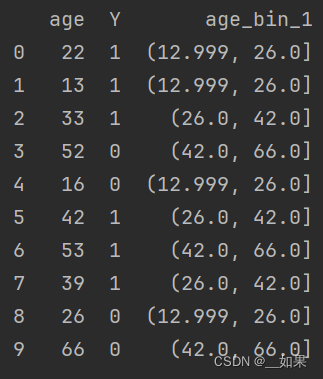
等距分桶
按照相同宽度将数据分成几等份。缺点是受到异常值的影响比较大。pandas.cut方法可以进行等距划分
df = pd.DataFrame([[22,1],[13,1],[33,1],[52,0],[16,0],[42,1],[53,1],[39,1],[26,0],[66,0]],columns=['age','Y'])
#print(df)
df['age_bin_2'] = pd.cut(df['age'],3) #新增一列存储等距划分的分箱特征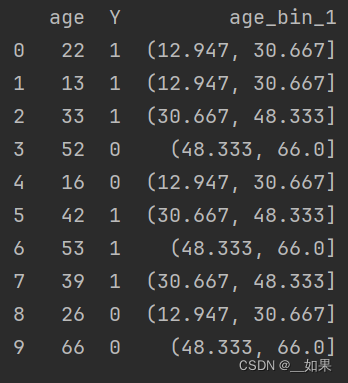
Best-KS分桶
KS(Kolmogorov-Smirnov)用于模型风险区分能力进行评估,指标衡量的是好坏样本累计部分之间的差距 。KS值越大,表示该变量越能将正,负客户的区分程度越大。通常来说,KS>0.2即表示特征有较好的准确率。强调一下,这里的KS值是变量的KS值,而不是模型的KS值。
BestKs方法其实就是找到变量中的最优KS值进行切分
计算方式:
(1)计算每个评分区间的好坏账户数。
(2)计算各每个评分区间的累计好账户数占总好账户数比率(good%)和累计坏账户数占总坏账户数比率(bad%)。
(3)计算每个评分区间累计坏账户比与累计好账户占比差的绝对值(累计good%-累计bad%),然后对这些绝对值取最大值记得到KS值。


卡方分桶
卡方分箱是自底向上的(即基于合并的)数据离散化方法。具有最小卡方值的相邻区间合并在一起,直到满足确定的停止准则。
基本思想:
对于精确的离散化,相对类频率在一个区间内应当完全一致。
因此,如果两个相邻的区间具有非常类似的类分布,则这两个区间可以合并;否则,它们应当保持分开。而低卡方值表明它们具有相似的类分布。
分箱步骤:
(1)设定卡方阈值
(2)根据要离散的属性值对实例进行排序
(3)计算每一对相邻区间的卡方值
(4)将卡方值最小的一对区间进行合并
(5)重复(3)(4)两步直至满足停止条件
归一化
如果数据集小而稳定,可以选择归一化

标准化
如果数据集中含有噪声和异常值,可以选择标准化,标准化更加适合嘈杂的大数据集

幂律分布处理
也被称为长尾分布,常用于风控类模型
事件发生的概率与事件大小的负指数成比例。事件越大,发生的可能性越小。


特征工程
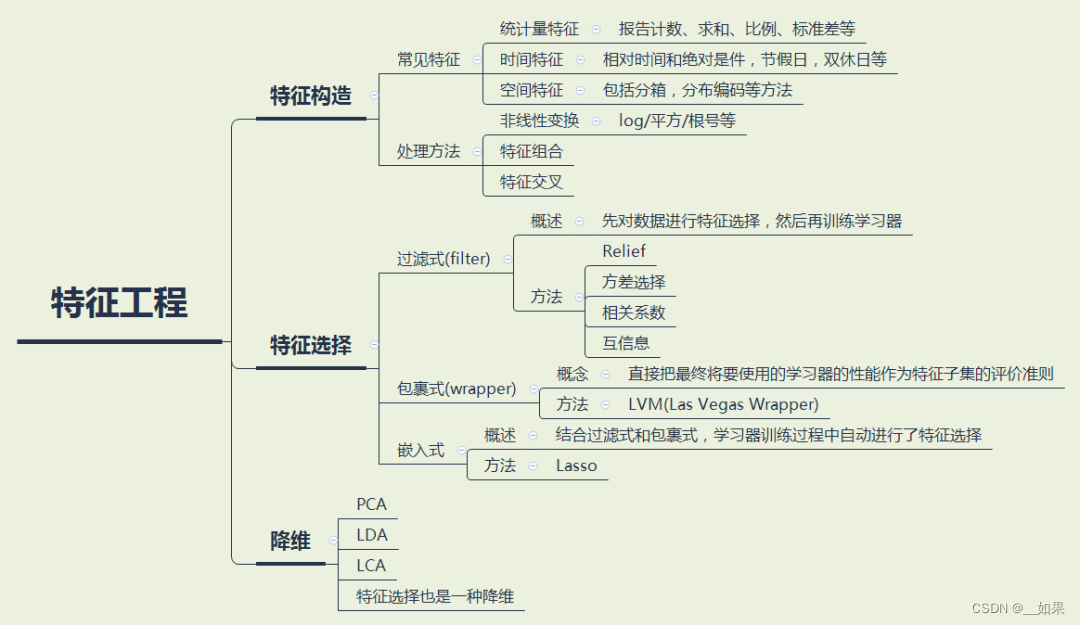
特征构造
常见特征:可学习joyful pandas:datawhalechina/joyful-pandas: pandas中文教程 (github.com)
特征组合:通过将单独的特征进行组合(相乘或求笛卡尔积)而形成的合成特征。特征组合有助于表示非线性关系。希望不同特征互补,表达出更复杂的关系
特征选择
过滤式(Filter):按照发散性或者相关性对各个特征进行评分,设定阈值或者待选择阈值的个数,选择特征。
包裹式(Wrapper):根据目标函数(通常是预测效果评分),每次选择若干特征,或者排除若干特征。
嵌入式(Embedded):先使用某些机器学习的算法和模型进行训练,得到各个特征的权值系数,根据系数从大到小选择特征。
降维
PCA:根据所选择的主成分的方差贡献来决定保留多少主成分。通过保留具有较高方差贡献的主成分,可以减少数据的维度,并保留尽可能多的信息
每日一问&群内讨论
【问题一】
1.线性回归算法的主要特点是()
A.可以拟合自变量和因变量的非线性关系。
B.可以寻找分类对象(数据)的最佳聚类。
C.可以拟合自变量和因变量间相互依赖的线性关系。
D.可以很好地拟合非线性数据。
答:C。线性回归肯定是拟合线性关系啊(doge)
【问题二】
2.请简述Python中常用的数据可视化库及其用途。
答:matplotlib、seaborn、plotly等。记得之前看过一篇文章横向对比各个画图的库,plotly算是表现最优秀的之一吧,有空学一下。可以画折线图折线图、散点图、柱形图、饼图、箱线图、直方图、热力图、散点图矩阵等来观察数据的趋势、关系、分布等
【问题三】
3.什么是数据标准化?数据标准化有什么好处?数据标准化有哪些常用的方法?
答:消除特征之间的差异性;Normalizer、StandardScaler、RobustScaler、MinMaxScaler、小数定标
【问题四】
下列哪些因素会影响 lightgbm 模型在时间序列预测中的性能?(多选)
A. 树的深度
B. 学习率
C. 特征选择
D. 数据平滑
答:ABCD。A树的深度太浅会无法很好地拟合,而过深则容易过拟合;B学习率不用多说了;C选择合适的特征可以避免一些无用特征的干扰,好的特征组合可以让模型更好的学习;D数据平滑可以减少噪声,对于时间序列来说,由于受周期变动和不规则变动的影响 ,起伏较大,不易显示出发展趋势时,可用数据平滑消除这些因素的影响
【问题五】
下列哪些方法可以用来检验时间序列数据的平稳性?(多选)
A. 单位根检验
B. 白噪声检验
C. 自相关图
D. 偏自相关图
下列哪些方法可以用来检验时间序列数据的平稳性?(多选)
A. 单位根检验
B. 白噪声检验
C. 自相关图
D. 偏自相关图
答:ACD。白噪声检验主要用于检验序列的随机性,而不是平稳性;单位根检验用来检验时间序列中是否存在单位根,从而判断序列的平稳性;通过观察自相关图中的相关系数大小和趋势,可以初步判断时间序列数据的平稳性; 偏自相关图可以帮助检查时间序列数据的部分自相关性,即在除去其他滞后项的影响下,当前时刻的值与前期时刻的值之间的相关性
【问题六】
下列哪些方法可以用来处理异常值?(多选)
A. 使用箱线图或3σ法则识别异常值
B. 使用平滑或变换方法减少异常值的影响
C. 使用分位数或截断均值替换异常值
D. 使用聚类或密度方法检测异常值
答:ABCD。
【问题七】
1. 剔除异常值,会影响时序特征吗? 因为时间本身有周期性规律,删除后会不会被打破?
答:对于ARIMA等统计学时序分析方法,直接剔除异常值会影响时间特征,所以建议用前后数据的均值替代异常值;但是对于XGB、LGB等树模型影响不大
【问题八】
2. 训练集rmse下降很快,但是验证集rmse下降很慢,后期都降不动了,这个是什么情况?
答:如果不是数据分布差异过大的问题,那就是过拟合了,可以考虑降低树的深度、增加正则化项惩罚权重大的系数等方法;如果划分训练集和验证集时数据分布差异过大,可以做一些数据同分布处理,比如采样算法等按测试集分布扩充训练
本文内容部分引用自:
pandas之分组groupby()的使用整理与总结-CSDN博客
python中groupby函数详解(非常容易懂) - The-Chosen-One - 博客园 (cnblogs.com)
Python数据分析库pandas高级接口dt的使用_pandas dt-CSDN博客
Pandas中的info()函数与describe()函数_pandas info-CSDN博客
还有人不懂XGBoost的缺失值处理?(全面解析篇) - 知乎 (zhihu.com)
Lightgbm 直方图优化算法深入理解_直方图算法-CSDN博客
Datawhale组队学习 Task2-数据分析_约翰逊分布族-CSDN博客
数据挖掘——EDA(数据探索性分析)_readdataestabcroisdynamic函数-CSDN博客
Pandas中的unique()和nunique()方法_pandas unique-CSDN博客
形象易懂讲解算法II——压缩感知 - 知乎 (zhihu.com)
8.特征工程 - 一、缺失值处理 - 《AI算法工程师手册》 - 书栈网 · BookStack















 2403
2403











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









