







目录
一:介绍
决策树( Decision Tree) 又称为判定树,是数据挖掘技术中的一种重要的分类与回归方法,它是一种以树结构(包括二叉树和多叉树)形式来表达的预测分析模型。其每个非叶节点表示一个特征属性上的测试,每个分支代表这个特征属性在某个值域上的输出,而每个叶节点存放一个类别。
一般,一棵决策树包含一个根节点,若干个内部结点和若干个叶结点。
叶结点对应于决策结果,其他每个结点对应于一个属性测试。每个结点包含的样本集合根据属性测试的结果划分到子结点中,根结点包含样本全集,从根结点到每个叶结点的路径对应了一个判定的测试序列。决策树学习的目的是产生一棵泛化能力强,即处理未见示例强的决策树。
使用决策树进行决策的过程就是从根节点开始,测试待分类项中相应的特征属性,并按照其值选择输出分支,直到到达叶子节点,将叶子节点存放的类别作为决策结果。
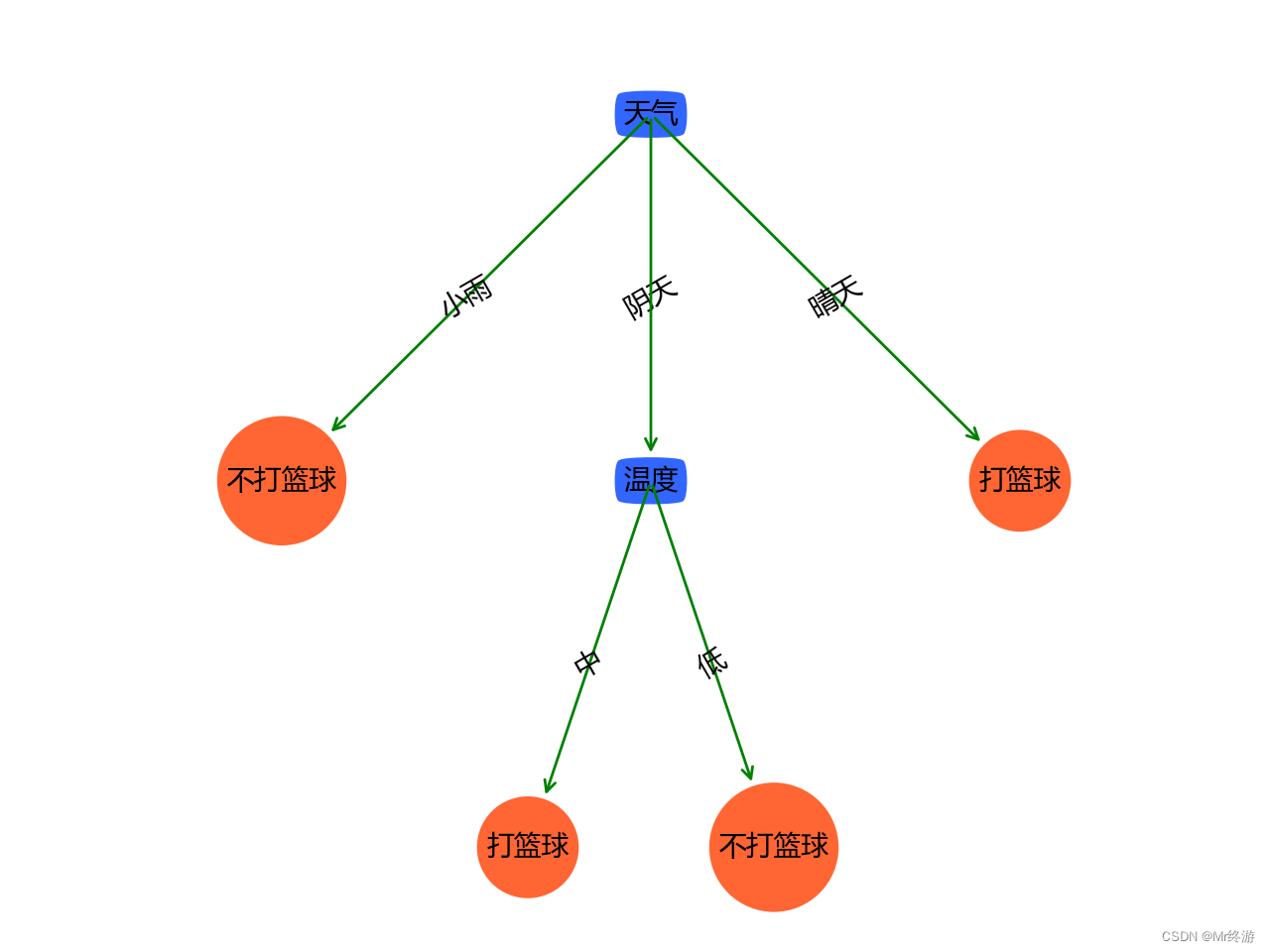
二:算法原理
1.熵和信息熵
熵:物理意义是体系混乱程度的度量。
信息熵:表示事物不确定性的度量标准,可以根据数学中的概率计算,出现的概率就大,出现的机会就多,不确定性就小(信息熵小)。
2.信息增益
信息增益是知道了某个条件后,事件的不确定性下降的程度。写作 g(X,Y)。它的计算方式为熵减去条件熵
举个栗子:现在又一个数据集E和特征A
熵的计算:
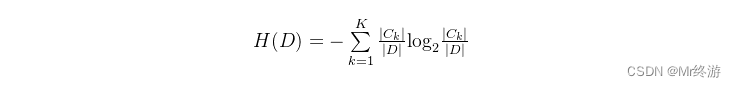
其中Ck是这个数据集中有多少类样本,D 为E中有多少个数据集
条件熵的计算:
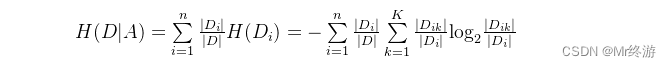
信息增益的计算:
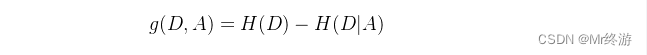
信息增益越大,使用特征A来划分获得的“纯度提升”越大。因此我们可以用信息增益来进行决策树属性选择,ID3决策树学习算法就是以信息增益为准则来选择划分属性的
三决策树分裂指标
1.信息熵:
在信息世界中,熵越高,则能传输越多的信息,熵越低,传输的信息越少。比如我们在买手机的时候,我们一般要看这个手机的摄像头像素、屏幕大小、运行内存RAM、机身容量ROM、CPU等,当要考虑的因素越多,不确定因素就越大,获取的信息越多,也就是熵越大。所以信息量=熵=不确定性。
2.Gini系数(CART)
基尼系数是指国际上通用的用来衡量一个国家或地区居民收入差距的常用指标。
国际上惯例:0.2以下为收入绝对平均,0.2-0.3为收入比较平均,0.3-0.4为收入相对合理,0.4-0.5收入差距较大,0.5以上为收入悬殊。基尼系数的实际值只能介于0-1之间,越小越平均,越大越不平均,国际上把0.4作为贫富差距的警戒线
在这里,基尼系数越小,代表集合中的数据越纯,我们可以计算分裂前的值在按照某个维度对数据集进行划分。

3.信息增益率
信息增益率在信息增益的基础熵增加了惩罚项,惩罚项是特征的固有值,
写作gr(X,Y)。定义为信息增益除以特征的固有值

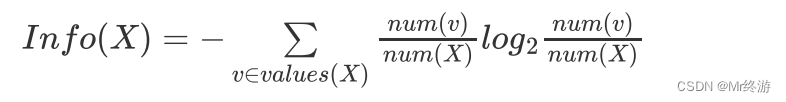
















 1104
1104

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









