







引言
Python 自带的标准库能够解决一部分数据处理的任务,但面对大规模且复杂的数据集,我们往往就需要借助 Python 第三方库来实现。举个例子,如果我们需要通过 Python 程序进行一些数学运算,标准库中的 math 库就可以胜任,但是当我们面对的是一个包含多种数据类型的大规模数据集时,就需要用更多的数据结构和数据操作方法来处理该数据集,此时 Python 中的第三方库 Pandas 的实用价值就凸显出来了,作为 Python 数据处理和数据分析中最重要的库(没有之一),它的功能非常强大,不仅可以用于数据处理,还可以对数据进行统计分析和可视化。在数据处理方面,Pandas 提供了许多实用的功能,比如可以使用 Pandas 从 csv、Excel、数据库等多种数据源中读取数据,除此以外,Pandas 的数据处理非常完备,下面列举了常用的几个功能:
- 合并多个文件的数据,或者将数据拆分为多个独立文件
- 建立高效的索引,灵活地查询、筛选数据
- 对数据进行去重、填充、删除、替换、转换等操作
...
当然,Pandas 的功能远不止这些。可以说,掌握了 Pandas 能够让我们在数据处理和数据分析中如虎添翼,Pandas 有这么多的功能,要从何学起呢?我们基于这个出发点推出了 Pandas 教学系列文章,旨在从浅入深地介绍 Pandas 在数据处理中的应用,让你体验大数据处理的魔力。
Pandas 的由来
正式学习 Pandas 之前,笔者想先介绍一下 Pandas 库的由来。一说到 Pandas 这个词,我们第一个想到的应该就是国宝“熊猫”,但是实际上 Pandas 和熊猫无关,它来自于计量经济学中的术语“面板数据”(Panel data)。
Pandas 是由 Wes McKinney 在 2008 年开发的,McKinney 当时是一家纽约金融服务机构的金融分析师 ,他在自己的工作中遇到了一些数据操作问题,当时 Python 中已经有了 Numpy 这样在处理大规模数据方面有着不错表现的库,但是对于表格等结构化数据而言,Numpy 并不能完全胜任。于是 McKinney 开始着手研究一套解决方案,目的是为了在 Python 中提供一种更便捷的方式来处理结构化数据,最终 Pandas 就被开发出来了。
刚才我们提到了 Python 中的 Numpy 库,这个库的主要用途是以数组的形式进行数据操作和数学运算。实际上 Pandas 是以 Numpy 为基础设计的,Pandas 中 DataFrame 和 Series(下文介绍)这两种数据结构是利用了 Numpy 数组作为底层结构的,这也使得 Pandas 数据处理更加高效,同时基于这种数据结构,Pandas 也为 Numpy 的不足之处进行了一些改进,Pandas 比 Numpy 支持更多的数据类型,在数据处理中更加灵活。虽然 Pandas 是依赖于 Numpy 的,但是这不意味着必须要先掌握 Numpy 的功能,我们直接使用 Pandas 即可,在学习过程中有需要再补充相关内容。
Pandas 的数据结构
在介绍 Pandas 的数据结构之前,首先需要了解什么是数据结构。数据结构指的是组织数据、储存数据的方式,数据结构的选择直接影响了数据的处理效率和数据操作的灵活性。
我们日常接触最多的结构是数组(类似于序列),数组是由相同类型元素的集合组成,对每一个元素分配一个存储空间,并且每个空间会有一个索引(下文介绍)来标识元素的存储位置,我们可以通过索引来访问元素。实际数据往往是由多个数组组成,它们共用同一个行索引,组成了一个二维数组,这类似于 Excel 表格中用字母表示一列,用数字表示行号,这样就可以确定元素的具体位置。

数组中的元素可以是任何类型的数据,包括整数型、浮点数型、布尔型等等。但是数组中所有元素的数据类型必须是一致的(在 Numpy 中,通常是将类型强制转换为一致的类型后进行存储),这是因为数组需要先为所有元素在内存中分配相同的空间大小,以保证数据存储的连续性和高效性。
Pandas 提供了 Series 和 DataFrame 作为数组数据的存储框架,当数据以这两种结构存储后,我们就可以利用它们提供的强大功能对数据进行处理。下面具体来看这两种数据结构。
1、什么是 Series
Series 是 Pandas 最基础的数据结构。通俗来说,Series 是一种类似于一维数组的数据结构,其中每个元素都带有一个标签(下文统称为“索引”),下面我们来看一个简单的 Series。
import pandas as pd # 导入 pandas 模块,约定俗成,起别名为 pd
# 创建一个 Series,并且自定义数据索引
pd.Series([4010.4, 2318.02, 3873.16], index=['北京', '天津', '河北'])
在 Pandas 中使用pd.Series()函数来创建 Series,其中的参数index用于自定义数据的索引。创建的 Series 结果如下。
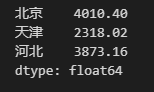
这个 Series 是 2019 年地区的采矿业的资产总计,第一列是 Series 的索引,它起到解释、定位数据的作用(如果不指定索引,默认从 0 开始编号),第二列是 Series 的值,最后一行dtype:float64表明该 Series 的类型统一为float64,表示占用 64 位(8字节)内存空间的双精度小数。
除了使用参数index,我们还可以使用字典直接创建带有自定义索引的数据,Pandas 会将字典的键作为索引,值作为对应的数据,得到的结果和上图一样,代码如下。
pd.Series({'北京':4010.4, '天津':2318.02, '河北':3873.16})
如果我们想要访问 Series 中的数据呢?这一点很简单,类似于 Python 中访问列表和字典元素的方式,只需要使用中括号加数据索引([数据索引])就可以实现,比如我们想要查看 2019 年河北省的资产总计,实现的代码如下。
# 将创建的 Series 赋值给变量 Value
Value = pd.Series({'北京':4010.4, '天津':2318.02, '河北':3873.16})
Value['河北'] # 输出:3873.16
可以看到无论是创建一个 Series 还是访问其中的元素时,都使用到了索引(index),实际在 Pandas 中索引是一个很重要的工具,索引相当于是一本书的书签,可以帮助我们快速找到想要查看的内容,通过索引我们不仅可以快速定位数据,还可以从 DataFrame 中选择特定的行数和列数等等。但是需要注意一点,在不同的场景中索引可能被称为其他名称,需要灵活理解和掌握,比如在二维数据结构中有行索引和列索引,行索引通常指的是每一行的索引,而列索引也被称为字段名、表头等。
2、什么是 DataFrame
实际中的数据大多是以二维表的形式存在的,类似于 Excel 的表格数据。在 Pandas 中二维数据是存储在 DataFrame 数据结构中的,换句话说,DataFrame(也称为“数据框”)其实就是一个m行 × n列的二维数据,下面我们创建一个 DataFrame,具体来看一下它的结构。
# 创建一个5行、5列的 DataFrame,赋值给变量 Data
data_list = [['110000','北京', 4010.4, 707.21, 1057.87],
['120000', '天津', 2318.02, 1423.45, 4051.2],
['130000', '河北', 3873.16, 1073.04, 2676.77],
['140000', '山西', 26229.57, 5951.44, 10415.53],
['150000', '内蒙古', 9945.73, 3029.35, 5764.29]]
Data = pd.DataFrame(data_list, columns=['省份代码', '省份名称', '资产总计', '固定资产净额', '固定资产原价'])
Data # 查看结果
结果如下:
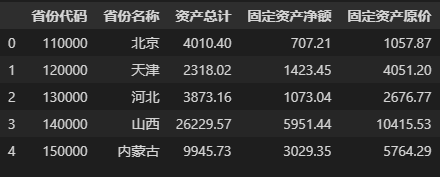
在 Pandas 中使用pd.DataFrame()函数来创建 DataFrame,我们在上面的代码中通过参数columns来指定数据框的列索引(也称为“字段名”或“列名”),上图最左侧一列为 Data 的行索引,默认是从 0 开始的自然数,也可以通过pd.DataFrame()函数中的参数index自定义索引值。
同时,在创建 Data 时我们使用的是一个列表 data_list,不难发现,这个嵌套列表中每一个子列表为 DataFrame 的一行,这和创建 Series 时类似,实际上 DataFrame 的每一行或者每一列都可以看作一个 Series,比如我们想查看“省份名称”这列数据,只需要通过代码Data[字段名]就可以实现,结果如下。
Data['省份名称']
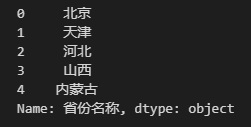
可以看到这就是一个由索引和对应数据构成的 Series,并且这个Series 使用的索引是 DataFrame 的行索引,所以 DataFrame 本质上可以看作由多个一维 Series 构成的二维数据,两者的关系可以通过下图来理解。

同理,DataFrame 的每一行也可以被视作一个 Series,这个 Series 的索引就是 DataFrame 的列索引(字段名)。示例如下。
Data.loc[2] # 得到 Data 的第二行
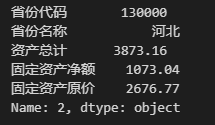
现在我们已经对 DataFrame 的结构有了初步的了解,下面再来看看创建 DataFrame 的方法。在 Pandas 中构建 DataFrame 的方法有很多,除了使用嵌套列表(多维列表),我们也经常使用字典来创建 DataFrame,使用字典生成本节中的 DataFrame 的代码如下。
# 使用字典创建一个 DataFrame
data_dict = {
'省份代码':['110000', '120000', '130000', '140000', '150000'],
'省份名称':['北京','天津','河北','山西','内蒙古'],
'资产总计':[4010.4, 2318.02, 3873.16, 26229.57, 9945.73],
'固定资产净额':[707.21, 1423.45, 1073.04, 5951.44, 3029.35],
'固定资产原价':[1057.87, 4051.2, 2676.77, 10415.53, 5764.29]
}
# 传入等长列表组成的字典
Data = pd.DataFrame(data_dict)
# 查看结果
Data
在这个代码中,我们将一个等长列表组成的字典传入pd.DataFrame()函数中,字典的键会作为 DataFrame 的列索引,字典的值为对应每一列的数据,这里我们是以列表作为字典的值,实际中也可以使用其他方式生成字典的值。需要注意一点,字典的每个值长度必须相等,否则无法成功创建 DataFrame。
Pandas 的字段类型
了解 Pandas 中的数据类型是必要的,这是因为在实际数据处理过程中,我们通常需要从多种数据源读取数据、并对数据进行合并等操作。我们应该知道 Excel 中每个单元格都有自己的数据类型(比如数值、文本、日期等等),相同的是 Pandas 数据结构中的每一个元素也有自身的数据类型,除此以外,Pandas 中每一个字段也具有类型属性,即字段类型,字段类型就是 Pandas 数据结构中一列的数据类型,也可以通俗理解为一列中所有数据的共性,Pandas 常见的字段数据类型如下表。
| DataFrame 字段类型 |
|---|
| float64 |
| int64 |
| bool |
| datatime64 |
| timedelta[ns] |
| object |
何时使用上表的字段类型呢?如果 Pandas 中一列数据都是浮点数,那么这一列的字段类型就为float64,如果一列数据全部都是整数,那么这一列的字段类型就是int64,同理,bool、datatime64和timedelta[ns]也是如此。
除了上面提到的五种常见的字段类型,Pandas 中还有一个特殊的字段类型:object。如果 Pandas 中一列的数据都是字符型或者这一列中除了数值型数据还存在一种或多种数据类型时,该列的字段类型就为object,仅通过这一句话你可能并不清楚这个数据类型的作用,为了更清楚地了解object这个类型,我们先输出上一章创建的 DataFrame 的数据类型,查看各字段类型的代码如下。
# pandas中使用.dtypes这个属性查看 DataFrame 每一列的数据类型
Data.dtypes
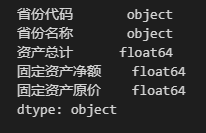
从上图可以看到,“省份代码”和“省份名称”这两列的字段类型均为object(根据创建 DataFrame 的代码,这两列数据值均为字符型),另外三列字段类型为float64(根据创建 DataFrame 的代码,这三列的数据均为浮点型)。现在我们对该 DataFrame 进行一些修改,代码如下。
# 导入 numpy库,使用 np.NaN 表示缺失值
import numpy as np
## “省份代码”中既有整型,也有字符型
## “资产总计”中既有浮点型,也有bool型
## “固定资产净额”中既有缺失值NaN,又有整型和浮点型
data_dict = {
'省份代码':[110000, 120000, 130000, 140000, '150000'],
'省份名称':['北京','天津','河北','山西','内蒙古'],
'资产总计':[True, 2318.02, 3873.16, 26229.57, 9945.73],
'固定资产净额':[np.NaN, 1423, 1073.04, 5951.44, 3029.35],
'固定资产原价':[1057.87, 4051.2, 2676.77, 10415.53, 5764.29]
}
Data = pd.DataFrame(data_dict)
Data
在上面的代码中,我们使用np.NaN表示缺失值,这是由于 Pandas 是基于 Numpy 开发的,所以 Pandas 表格中的缺失值默认是使用 Numpy 库的常量np.NaN来表示,np.NaN表示缺失值(NaN 即"Not a number",也就是数值无法精确表示或者不存在的值),它是一个特殊的浮点数。
更改后的 DataFrame 的数据类型如下。
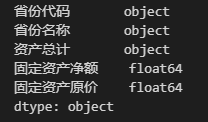
从结果来看,更改 DataFrame 前后的字段类型发生改变了,实际上 Pandas 已经对数据类型自动进行转换了,下面是更改后的数据集:
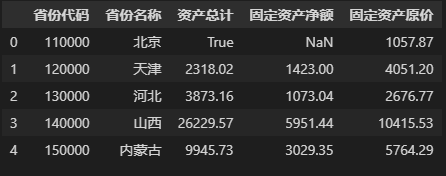
根据上面的两个结果,我们具体来看发生更改的列的情况:第一,对于包含整型、浮点型和 np.NaN 的“固定资产净额”列,当整型和浮点型同时存在一列中时,Pandas 会自动将整数型转换为浮点型(如整数1423转换为浮点数1423.00),此时该列的字段类型为float64(在 Pandas 中,np.NaN的数据类型为float);第二,从“省份代码”或“资产总计”列可以看到,当一列中出现了字符型、bool型的数据时,Pandas 指定该列的字段类型为object。结合以上两点,总结上面出现的 Pandas 的数据类型转换规则如下:
- 当缺失值
np.NaN、整型与浮点型三种数据中任意两种及两种以上共存于一列时,该列的字段类型就会转换为float64。 - 如果一列中存在字符型或者同时存在两种及两种以上数据类型时(整型与
np.NaN或浮点型共存于一列时,视为只有浮点型这一种数据类型),该列的字段类型就会转换为object。
通过上面这个例子,我们已经较为全面地了解了object这个字段类型,但是关于 object 类型我们需要注意一点,当我们在数据处理中需要进行数据合并等操作时,为了避免由于数据类型不一致导致的错误,我们建议大家在使用 Pandas 从csv/Excel 等其他数据源读取数据后,要注意数据类型的一致性问题,通过 Pandas 提供的数据类型转换方法(后续介绍),确保 Series 或 DataFrame 数据类型保持一致。
了解 Pandas 字段类型有什么作用呢?掌握常见的字段类型能够有助于我们检查数据中的错误或者缺失情况,实际中我们的数据通常会以列为单位,即一列的值是同一种数据类型,当我们使用 Pandas 读入数据后,可以通过dtypes属性检查一列数据的字段类型,比如一列数据均为数值型,那么该列的字段类型应该为int64/float64,如果该列的字段类型为object时,说明该列中可能出现了类型不一致的数值,此时需要检查并校正数据,这样能够保证我们在进行数据处理或分析之前数据的准确性。
数据的读取与导出
Pandas 强大的数据读取功能体现在其支持目前绝大多数主流的数据存储形式,如常见的 Excel、CSV 及多种数据库。那么 Pandas 是如何实现数据读取的?Pandas 通过读取函数读取数据表,在读取过程中将原始数据中的表格转换为 DataFrame 类型,然后我们就可以对读取后的 DataFrame 进行处理分析,最后调用 Pandas 中的数据导出函数将数据写入指定类型的文件。Pandas 针对不同的文件格式提供了相应的读取函数以及导出函数,下表列出 Pandas 中一些常见文件格式的读取与导出函数。
| 文件格式 | Pandas 读取函数 | Pandas 输出函数 |
|---|---|---|
| Excel | read_excel | to_excel |
| CSV、TXT | read_csv | to_csv |
| SQL 查询数据库 | read_sql | to_sql |
| DTA | read_stata | to_stata |
| 本地剪贴板 | read_clipboard | to_clipboard |
Pandas 中还有一些不太常用的文件格式的读取与写入函数,这里不再列举,上表中的函数已经足够我们日常使用了,在日常的工作学习中,Excel 工作表、 CSV 文件和 Stata 文件是我们经常使用的表格文件类型,所以下文我们详细介绍 Pandas 中读取这三种文件的read_excel()、read_csv()和read_stata()函数。
Pandas 读取CSV文本文件
为什么先介绍 Pandas 读取文本文件呢?因为实际中我们最常用的文件格式之一就是文本文件,这种文件格式的跨平台兼容性较好,并且文本文件的可读性强,可以使用任何文本编辑器打开。常见的表格形式的文本文件主要是 CSV 文件和 TXT 文件,其中以字符分隔的 CSV 文件是最常用的文件格式,Pandas 为读取 CSV 文件提供了强大的功能,下面我们详细介绍。
CSV(Comma-Separated Values)是用特定字符(一般情况是半角逗号)分隔表中不同单元格数据值的数据形式,其文件的扩展名为.csv。CSV 文件是以行作为单位存储数据的,每行数据用逗号分隔,文本的一行表示数据表的一行。下面是一个 CSV 文件示例(使用文本编辑器打开)。
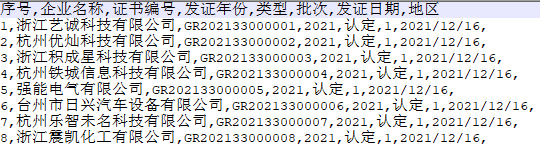
在这个示例中,第一行是标题行,表示数据表的字段名,下面的八行是数据行,每行都包含八个数据值(序号、企业名称...),一行中的不同值用逗号分隔。Pandas 中提供了read_csv()函数来读取 CSV 文件,该函数有四十多个参数,我们在这里仅介绍常用的参数,如下表所示。
| read_csv 函数的常用参数 | 用法 |
|---|---|
| filepath_or_buffer | 必需参数,CSV 文件所在的路径或返回文件对象的函数 |
| sep | 字符串,默认为逗号,用于字段之间的分隔符 |
| header | 整数,表示 CSV 文件中表头所在的行号,默认为0,即第一行为表头 |
| names | 用于将自定义的列名列表传递给 DataFrame 对象 |
| usecols | 用于筛选需要读取的列 |
| dtype | 字典,用于将指定的列的类型转换为指定的字段类型 |
| chunksize | 可以指定读取 CSV 文件的每个块中包含多少行记录 |
| encoding | 字符编码,默认为 None |
现在我们仅使用必需参数来读取上面示例中的 CSV 文件,代码如下。
data = pd.read_csv('./浙江省2021年第一批高新技术企业名单.csv')
data # 查看结果
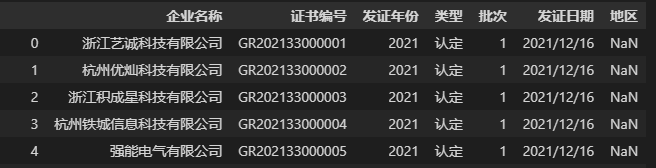
虽然上面代码中的pd.read_csv()函数只有一个文件的相对路径作为必需参数(事实上其他参数使用了默认值,比如pd.read_csv()函数的参数header默认将 CSV 文件的第一行作为表头(也称“字段名”或“列名”),参数 sep 默认以逗号作为文件的分隔符。如果 CSV 文件是以分号;作为分隔符的,那么在读取该文件时就需要指定参数sep=';',其他情况也类似。
当我们想自定义 DataFrame 的表头时,代码如下:
data = pd.read_csv('./浙江省2021年第一批高新技术企业名单.csv', header=0, names=['企业现名', '发证编号','发证年份','认定类型', '批次', '发证日期', '地区'])
data
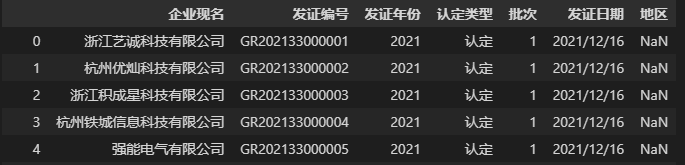
上面的代码中我们使用参数header指定第一行为表头,并且将列名列表传给参数names,这样就能够用自定义表头覆盖原文件表头。这里需要注意一点,如果原 CSV 文件有表头,那么在使用参数names自定义表头时,需要指定参数 header=0,否则原表头会作为 DataFrame 的第一行数据,如下所示:
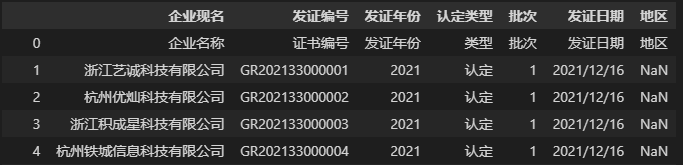
另外,我们在实际的数据处理中可能只需要一个文件中部分字段的内容,如果我们只想读取 CSV 文件的部分列要如何实现呢?代码如下:
data = pd.read_csv('./浙江省2021年第一批高新技术企业名单.csv', usecols=['企业名称', '证书编号','发证年份', '发证日期'])
data # 查看结果
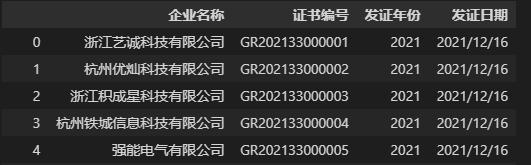
在上面的代码中我们通过参数usecols筛选需要的列,这样可以避免读取不必要的数据,从而优化读取文件的速度并且减少内存的占用。除了将需要筛选的列名的列表传入参数usecols中,还可以传入列序号(从 0 计数)的列表,但是笔者认为传入列名的列表更实用,这样不需要记忆列的顺序。
现在我们来看上面得到的data的字段类型,使用代码data.dtypes得到结果如下:
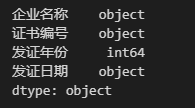
我们在上一期文章中提到 Pandas 字段类型有助于我们检查数据的异常情况,从上图结果可以看到字段“发证年份”的类型为int64,而实际该列的数据类型更适合为字符型,而不是整型,并且从“发证日期”列的字段类型应该为日期,而上图结果中该列的字段类型为 object,这是有问题的。通常在确保数据本身没有错误的情况下,这种问题往往是由于 Pandas 在读取文件时会自动对列的类型进行推断而导致的。那么如何使得字段类型正确呢?除了通过 Pandas 提供的类型转换方法来转换 DataFrame 的字段类型(后面介绍),我们在读取 CSV 文件时也可以指定字段类型,代码如下:
data = pd.read_csv('./浙江省2021年第一批高新技术企业名单.csv',
usecols=['企业名称', '证书编号', '发证年份', '发证日期'],
dtype={'发证年份':str, '发证日期':str}) # 设置 dtype=str 表示所有列均为字符型
data # 查看结果
在上面的代码中我们通过参数dtype指定各列的数据类型,传入该参数的是一个键为列名、值为数据类型的字典,我们将'发证年份'列的数据类型指定为字符型,现在再来看一下 DataFrame 的字段类型,结果如下:
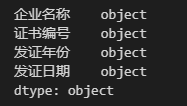
可以看到'发证年份'列的字段类型已经转换为object,但是你应该注意到在参数dtype中我们并没有指定'发证日期'列的类型为日期,这是因为read_csv()函数中不支持直接指定日期数据类型,我们可以使用 pandas 中的to_datetime()函数将日期列转换为日期类型,代码如下:
data['发证日期'] = pd.to_datetime(data['发证日期'], format='%Y-%m-%d')
data.dtypes # 查看各列字段类型
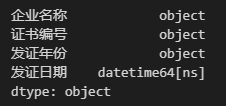
此时'发证日期'列的字段类型已经转换为日期,to_datetime()函数的参数format用来指定日期格式,需要注意的是,在使用该函数时要保证数据中的日期格式与format指定的格式一致,否则转换不成功。
下面我们来看一下read_csv()函数的参数encoding,该参数用来指定读取 CSV 文件时所使用的字符编码格式。我们在读取示例 CSV 文件时并未指定参数encoding,这是因为read_csv()函数通常会使用'utf-8'编码格式读取 CSV 文件,如果文件采用了其他的编码格式,才需要通过参数encoding来指定。read_csv()函数支持的字符编码较多,常见的如下表所示。
| 编码格式 | 说明 |
|---|---|
| utf-8 | 一种 Unicode 编码格式(自行了解),支持所有语言,是目前最常用的编码格式 |
| utf-16 | 一种 Unicode 编码格式,支持所有语言,采用 16 位编码 |
| gbk | 一种中文字符集,又称“国标码”,支持简体中文和繁体中文 |
| gb2312 | 一种中文字符集,是 GBK 字符集的前身,支持简体中文 |
| iso-8859-1 | 又称“Latin-1”编码,支持欧洲语言中的大多数字符 |
比如我们现在想要读取一个使用'gbk'编码的 CSV 文件,就可以通过指定参数encoding来实现,代码如下:
pd.read_csv('./浙江省2021年第一批高新技术企业名单.csv', encoding='gbk')
在read_csv()函数中还有一个参数chunksize,这个参数的作用是在读取较大的 CSV 文件时允许数据分块读入。chunksize参数会读入指定块的数据并返回一个可迭代的对象,其中每次迭代返回指定大小的数据集,该数据集是一个 DataFrame 类型的对象,然后我们就可以对这个 DataFrame 进行处理分析,不需要将整个数据集一次读入内存,可以节省内存空间并且提高代码运行效率。如对这个参数感兴趣的可以自行了解,我们在这里就不多说了。
Pandas 读取TXT 文本文件
除了上面介绍的 CSV 文件,我们有时还会使用 TXT 这种文本文件来存储表格,与 CSV 文件不同的是 TXT 文件不能用 Microsoft Excel 打开,在常用的 Windows 操作系统中可以使用记事本打开,并且 TXT 文件扩展名为.txt。与 CSV 文件相同的是 TXT 文件也可以使用read_csv()函数来读取,现在我们有一个 TXT 文件(示例)如下:

TXT 文件通常没有表头,且这个 TXT 文件的两列之间以' - '作为分隔符,我们现在使用read_csv()函数读取这个文件,代码如下:
Data = pd.read_csv('./ENV_PerfGovernDisclose[DES][xlsx].txt', sep=' - ', header=None)
Data # 查看结果
结果如下:
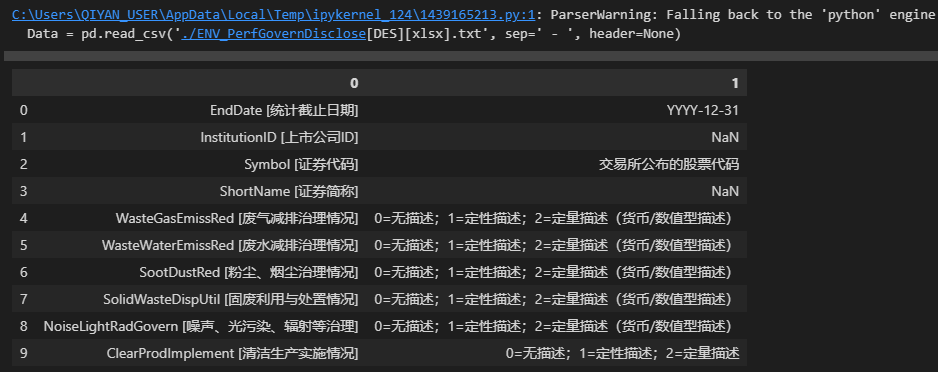
可以看到在上面代码中我们指定参数sep=' - ',-的左右两边各有一个空格,参数header=None是由于该 TXT 文件没有表头,如果不这样设置会默认将第一行数据作为表头。从上图可以看到 Python 解释器提示了警告信息:
ParserWarning: Falling back to the 'python' engine because the 'c' engine does not support regex separators (separators > 1 char and different from '\s+' are interpreted as regex); you can avoid this warning by specifying engine='python'.
这个信息告诉我们,在使用read_csv()函数读取文件时指定了一个多字符的分隔符,并且这个分隔符不是标准的空格符\s,这种情况下 Pandas 默认的 c 引擎无法处理这个字符,会转而使用 python 引擎来解析,所以出现了警告信息。想要避免这个情况,只需要明确地告诉 Pandas 你要使用的是 Python 引擎,也就是指定read_csv()函数的参数engine='python'。
Pandas 读取 Excel 表格
Excel 是一种常见的电子表格文件,与文本文件不同的是 Excel 表格可以设置数据类型(数值、文本、日期等)、公式和二进制形式存储的数据等,其由 Microsoft Excel 或其他兼容的电子表格软件创建,通常以.xlsx或.xls为扩展名。Pandas 中提供了read_excel()函数读取 Excel 文件,常见的参数如下表。
| read_excel 函数的常用参数 | 用法 |
|---|---|
| io | 必须参数,待读取的 Excel 文件路径 |
| sheet_name | 指定需要读取的工作表名或工作表序号,默认为第一个工作表 |
| header | 整数,指定作为表头的行,默认为0,即第一行为表头 |
| names | 用于将自定义的列名列表传递给 DataFrame 对象 |
| usecols | 用于筛选需要读取的列 |
| dtype | 字典,用于将指定的列的类型转换为指定的字段类型 |
可以注意到read_excel()函数的常用参数与read_csv()函数的常用参数相似,第一个参数io指定需要读取的文件路径,其他相同的参数这里就不多介绍了。不同的是读取 CSV 文件通常需要指定分隔符(默认为逗号,),而读取 Excel 文件通常需要指定读取的 sheet 表名或表序号(默认为第一个工作表)。
我们现在有一个 Excel 文件中有两个 sheet 表,Sheet1 为浙江省 2021 年的国家高新技术企业名单,Sheet2 为宁波市 2021 年的国家高新技术企业名单,现在我们使用read_excel()函数读取 Sheet2 中的内容,代码如下:
Data = pd.read_excel('./浙江省2021年第一批高新技术企业名单.xlsx', sheet_name=1, usecols=['企业名称', '证书编号','发证年份', '发证日期'])
Data # 查看结果

可以看到上面的代码中我们指定参数sheet_name=1时读取的是第二个 sheet 表,这是因为如果指定参数sheet_name时传入的是表的顺序,这时表的顺序从 0 开始计数,或者也可以直接指定表名来实现,本节示例中的 Excel 文件的表名为默认表名Sheet1和Sheet2,实现代码如下:
Data = pd.read_excel('./浙江省2021年第一批高新技术企业名单.xlsx', sheet_name='Sheet2', usecols=['企业名称', '证书编号','发证年份', '发证日期'])
需要注意一点,read_excel()函数不仅可以读取单个 sheet 表,也可以读取 Excel 文件中多个或全部 sheet 表,此时可以将需要读取的表名组成的列表传给参数sheet_name,这种情况下返回的结果是一个字典,字典的键为表名,字典的值为该表对应的 DataFrame,我们在这不过多介绍了。
Pandas 读取 Stata 文件
Stata 文件是一种二进制文件格式,它是 Stata 软件的专属数据文件格式,以.dta为扩展名。与 CSV 文件和 Excel 表格不同的是 Stata 文件中包含了大量元数据(通俗来说,元数据就是用来描述数据的数据,也称为“中介数据”)信息,比如变量标签、值标签等等。Pandas 提供了用于读取 Stata 文件的read_stata()函数,下表为该函数中常用的参数。
| read_stata 函数的常用参数 | 用法 |
|---|---|
| filepath_or_buffer | 必需参数,待读取的 Stata 文件路径 |
| convert_categoricals | 读取数据值标签,默认为 True 表示将 Stata 文件中的类别变量转换为 Pandas 中的类别变量 |
| convert_missing | 是否将缺失值转换为 Stata 中的表示,默认为 False |
| preserve_dtypes | 是否保留 Stata 数据类型,为 False 时数值型数据会转换为 float64 或 int64 |
| columns | 选择需要读取的列 |
我们使用中国学术调查数据资料库CNSDA[1]提供的中国综合社会调查(2021)项目的原始数据(Stata 文件),来看一下用 Pandas 如何读取这个 Stata 文件(该数据可自行在网站下载)。
代码如下:
data = pd.read_stata('./656354229362/CGSS2021.dta', columns=['id','provinces','community_i','type','A00','A1','A011601'], preserve_dtypes=False, convert_missing=False)
data.head(8) # 查看结果,DataFrame的head属性在第六章介绍
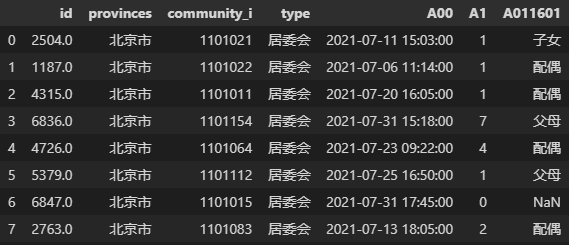
在上面的代码中我们设置参数columns选择需要读取七列数据,设置参数preserve_dtypes=False表示不保留 Stata 的数据类型,原始数据的数值类型会向上转换为 Pandas 中的float64或int64类型,设置参数convert_missing=False表示原数据的缺失值使用 Pandas 中的 NaN 表示。我们可以使用代码data.dtypes看一下data的字段类型,结果如下:
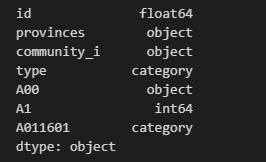
可以看到'type'和'A011601'列的字段类型为category,这是因为参数convert_categoricals默认将 Stata 中的分类变量转换为 Pandas 中的类型变量。这个示例中的参数是 Pandas 读取 Stata 文件时常用的参数,此外也有别的参数可以使用,比如想要在 Pandas 中查看原始数据的变量标签时可以使用参数iterator来实现,我们在这里不多介绍了。
DataFrame 的常用属性
在我们使用 Pandas 将数据读取为 DataFrame 后,通常需要对这个 DataFrame 做一些初步的验证,比如列名是否一致,数据量是否存在缺失等等,下面我们介绍几个 Pandas 提供的查看 DataFrame 基本信息的属性和方法,使用的数据集为上一节通过read_excel()函数读取的Data。
1查看样本
当我们读取得到的 DataFrame 样本量较大时通常需要先查看部分样本,Pandas 提供了三个常用的属性来查看 DataFrame 的样本。
DataFrame.head(n)表示查看一个 DataFrame 的前 n 行,默认参数值为 5。现在我想要查看Data的前三行数据,代码如下:
Data.head(3)
DataFrame.tail(n)表示查看一个 DataFrame 的末尾 n 行,默认参数值为 5。现在我想要查看Data的末尾五行数据,代码如下:
Data.tail()
DataFrame.sample(n)表示随机抽取一个 DataFrame 的 n 行,默认参数值为 1。现在我们想要随机抽取Data的两行数据,代码如下:
Data.sample(2)
2数据大小
如果我们想要了解读取数据集的行数和列数呢?Pandas 中使用DataFrame.shape查看数据的行、列数,执行该语句会返回一个元组,该元组的第一个元素为行数,第二个元素为列数,代码如下:
Data.shape
# 输出:(1393, 4),即该数据集共1393行4列3数据基本信息
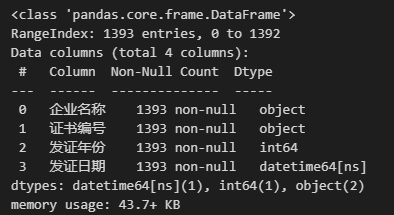
Pandas 中使用DataFrame.info()查看 DataFrame 各列的基本信息以及所占内存的大小等。现在我们想要查看Data的基本信息,代码如下:
Data.info()
观察上图,
-
第一行表示该数据是一个 DataFrame;
-
第二行中的 RangeIndex 表示该数据的行索引信息,从 0 到 1392;
-
第三行往下是该数据所有列的信息,Column 表示列名,Non-Null Count 表示该列中非空值的个数,Dtype 表示该列的字段类型;例如 Non-Null Count 下面的
1393 non-null表示这一字段共有 1393 个非缺失值,我们可以通过这个信息初步查看数据中各个字段的缺失情况。 -
最后一行的 momory usege 表示该数据在内存中所占用的空间大小。
除了上面三种信息,Pandas 中还有一个常用的函数DataFrame.describe(),其用于快速查看数值数据统计信息,函数返回的是数据各个数值列的数据分布和统计指标(最大值、最小值、中位数等等),这里我们不多介绍了。
数据导出
当我们对读入的 DataFrame 进行处理分析后,就可以通过 Pandas 中的数据导出函数将数据写入文件,为了便于展示,此处所使用的数据为本文第四章中通过read_excel()函数读取的数据 Data,下面我们介绍 Pandas 中最常用的to_csv()和to_excel()这两个数据导出函数。
1导出为CSV文件
下表列出了to_csv()函数的常用参数:
| to_csv 函数的常用参数 | 用法 |
|---|---|
| filepath_or_buffer | 保存 CSV 文件的路径 |
| sep | 指定列之间的分隔符,默认为 , |
| header | 指定是否将 DataFrame 的表头输出为文件的第一行,默认为 True |
| index | 指定是否将行索引输出到文件,默认为 True |
| columns | 指定要输出的列 |
| encoding | 指定文件编码 |
| mode | 指定文件写入模式,默认为 'w' 表示覆盖现有文件 |
上表列出的常用参数中大多数在介绍read_csv()函数时已经了解过了,这里就只说一下to_csv()函数的mode参数,该参数的常用取值是'w'和'a',当我们使用'w'模式写入时会覆盖现有文件,如果文件不存在就创建这个文件,使用'a'模式写入时会将数据追加到已存在的文件末尾,如果文件不存在就创建一个新文件。现在我们将数据Data输出为一个 CSV 文件,代码如下:
Data.to_csv('./output/NingBo_Province.csv', index=False, columns=['企业名称', '证书编号', '发证日期'])
输出得到的文件如下:

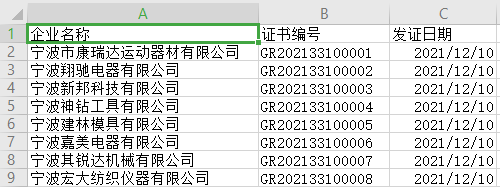
在上面代码中我们指定参数index=False来去掉索引,并且使用columns参数输出了数据Data的三列内容,其他参数使用默认值。除此以外,你也可以使用指定分隔符的参数sep等等。
2导出为EXCEL文件
与写入 CSV 文件不同的是,使用to_excel()函数可能需要依赖第三方库 openpyxl,所以在使用该函数之前需要先安装依赖的库。下表列出了to_excel()函数的常用参数:
| to_excel 函数的常用参数 | 用法 |
|---|---|
| excel_writer | 要写入数据的 Excel 文件的路径 |
| sheet_name | 要写入数据的 Excel 工作表的名称,默认为 'Sheet1' |
| header | 指定是否将 DataFrame 的表头输出为文件的第一行,默认为 True |
| index | 指定是否将行索引输出到文件,默认为 True |
| engine | 可选参数,指定写入 Excel 时使用的引擎 |
上表中的excel_writer指定了需要写入的 Excel 的文件路径或文件对象,其中的文件名必须以.xlsx或.xls为扩展名,如果参数excel_writer所指向的文件已经存在,Pandas 会删除原文件并创建新的文件。参数engine用来指定写入 Excel 文件时使用的引擎,该参数的可选值为'openpyxl'或'xlsxwriter',具体如下。
-
engine='openpyxl':使用 openpyxl 作为写入引擎,可以处理 Excel2007 或更高版本的 .xlsx 格式文件,openpyxl 库有较好的兼容性,能支持较多的 Excel 文件格式 -
engine='xlsxwrite':使用 xlsxwrite 作为写入引擎,可以处理上一条提到的 .xlsx 文件,但是不支持 .xls 格式的文件,相较于 openpyxl 有更少的依赖关系,写入的速度更快
现在我们将数据Data输出为.xlsx为扩展名的 Excel 文件,代码如下:
# 输出扩展名为 .xlsx 的 Excel 文件
Data.to_excel('./output/Ningbo_Province.xlsx', index=False)
输出得到的文件如下:

上面代码中我们指定参数index=False来去掉索引,其他参数使用默认值。
如果我们想要将Data输出为.xls为扩展名的 Excel 文件呢?代码如下:
Data.to_excel('./output/Ningbo_Province.xls', index=False)

运行上面这个代码时提示了一条警告信息,这条信息建议我们使用 openpyxl 作为写入 Excel 文件的引擎,当前正在使用的 xlwt 引擎将在未来版本移除,也就是我们需要在使用to_excel()函数时设置参数engine='openpyxl'。
当我们想要将数据导出为 Excel 文件时,笔者建议导出为.xlsx文件,这种文件格式的兼容性更强,此时不需要设置参数engine。
表格数据的索引
日常使用表格数据时,经常需要查看表格中的某处数据,这种时候不可避免地需要根据表格的字段名和行序号进行定位,例如在 Excel / WPS 这类办公软件中显示表格数据时,软件左侧和上方自带行编号和列编号,我们可以根据行编号和列编号(或字段名)来定位数据,如下图所示。
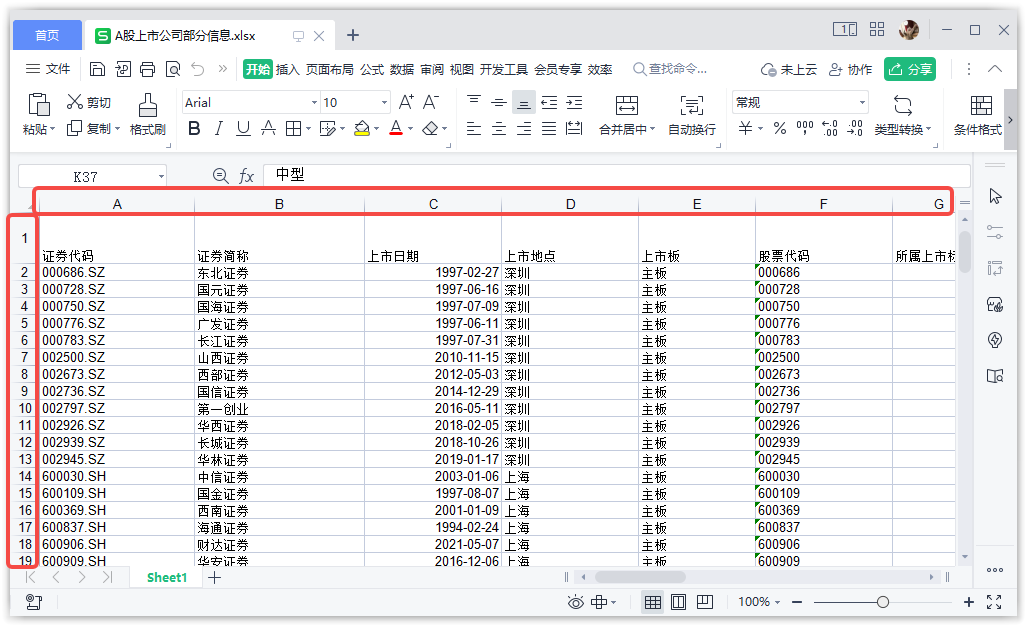
在 Python 中, Pandas 是一个专门用来处理表格数据的 Python 第三方库,在 Pandas 中,表示表格数据的数据类型是 DataFrame。为了能够像 Excel 一样方便地定位数据,DataFrame也具备行编号和列编号属性,下面我们读取一个表格数据以作演示。
#导入 pandas 库
import pandas as pd
# 读取演示用的数据
DATA = pd.read_excel('./A股上市公司部分信息.xlsx')
# 处理字段名,并做简化处理,这一步不必在意
DATA.columns = [COL.split('\n')[0] for COL in list(DATA.columns)]
# 展示数据
DATA
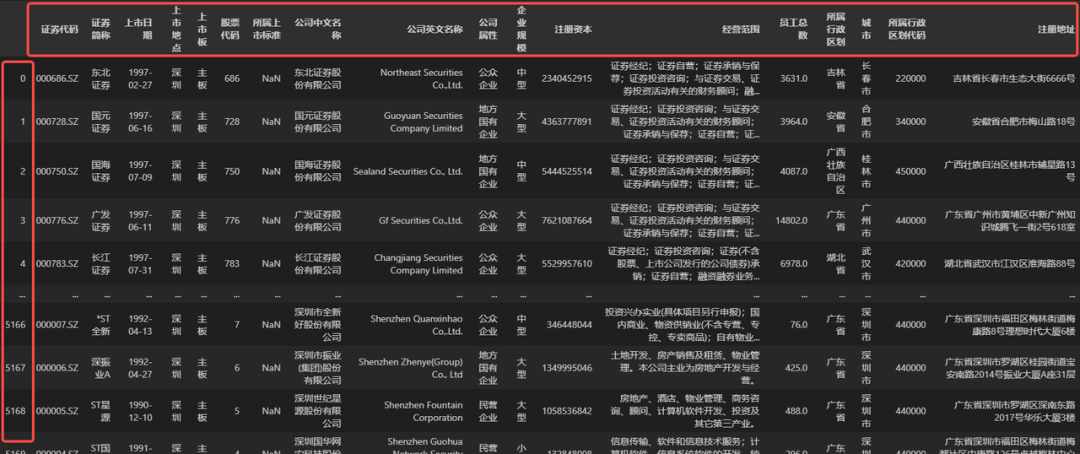
如上图所示,Pandas 中表格数据类型 DataFrame 同样具有行编号和列编号属性,DataFrame 类型行列编号和 Excel 表的行列编号看起来有几分类似,实际他们之间存在不小的差异,笔者将它们之间的主要差异罗列在下方。
-
在 Excel 表格中,表格不一定有字段名,所以才一定会有上方的列编号(A、B、C……);而在 Pandas 中,表格类型必须具有字段名,并使用字段名作为列编号(列索引或字段名:column),如果读取一份数据时发现表格没有字段名,Pandas 默认会将首行内容作为字段名,当然这可能不合理,不过我们可以在读取数据时设置参数
header=None,表示表格没有字段名,这时 Pandas 会将表格的字段名设置为自然数(从左向右依次为 0,1,2……) -
Excel 表中的行编号实际上是表格中行的序号,从上往下,从 1 开始,最多到 1048576,因为 Excel 表的数据存储上限为 1048576 (2 的 20 次方)行。且行编号是固定的,不会随着数据行的删除、隐藏而变化。而在 Pandas 中,数据行编号被称为
行索引(index),读取数据时,Pandas 会自动为表格数据赋予行索引(如上图所示),行索引默认从 0 开始,向下递增。行索引就是一行数据的编号,随着数据行的删除、添加,行索引也会跟着变化,例如索引为 1 的这一行数据被删除后,数据行索引就变为 0,2,3……所以 Pandas 中的行索引不是连续且不变的,这是为了让数据的定位更加稳定,不受数据量变化的影响。 -
Excel 表的行列编号是固定不变的,行索引是从 1 到 1048576 的正整数,列编号是由 26 个大写英文字母组成的编号。Pandas 中的表格(DataFrame)的行索引默认是递增的自然数,但可以根据编程者的需要自行定义索引值,且行索引也可以是字符串类型。在数据处理的任何阶段,使用者都可以改变某(几)行数据的索引,也可以在任何时候重置数据行索引,让其变为默认的连续自然数。
-
Excel 其实没有严格的字段名概念,只是大家习惯把字段名写在第一行,所以在 Excel 中,字段名的值是随意的,可以重复的。而在 Pandas 中,虽然也支持相同的字段名或行索引,但它不建议这么做,在读取表格数据、匹配表格数据时,如果发现至少两个字段的名称一样,Pandas 会自动做出区分,如下图所示。
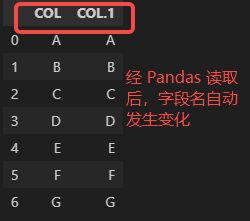
以上就是 Excel 软件中行列编号与 Pandas 中表格数据类型 DataFrame 的行索引、字段名的主要差异。相信此刻大家对 DataFrame 的索引有了一个比较全面的认识,下面我们将以默认的数据索引为例,向大家演示 Pandas 是如何进行数据选取的。
Pandas 数据选取
本节演示用的数据表为 A 股上市公司的部分信息(截至2023年5月12日),读取数据的代码和数据预览请查看上一节【表格数据的索引】。
1选取数据字段
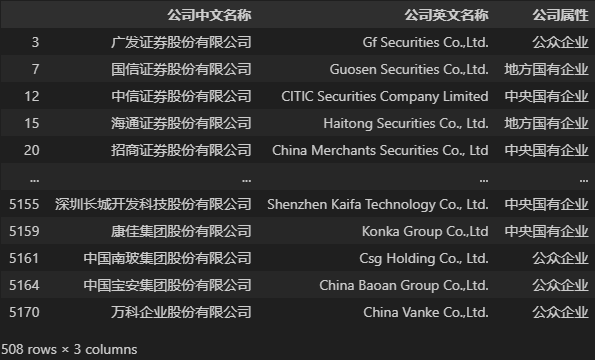
许多时候表格的字段太多,我们筛选出自己需要的即可。在 Pandas 中,我们可以根据字段名来选取需要的数据字段,示例代码如下(代码中的DATA是上一节读取数据得到的变量)。
## 如果只需要选出一个字段,可以使用这样的代码:<变量名>[<字段名>],示例如下
DATA['公司中文名称'] # 此时选取的结果是一个 Series,这里不再放图展示
## 如果需要选取若干个字段,且所得结果仍是表格
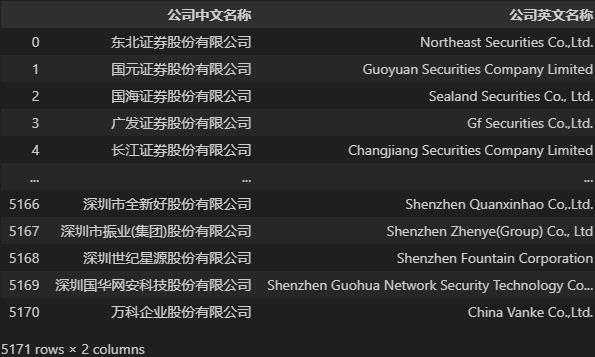
## 可以使用:<变量名>[<字段名列表>],示例如下
DATA[['公司中文名称', '公司英文名称']]
2选取数据行
Pandas 中有一种简单选取数据行的功能,可以选取某一连续范围的数据行,例如可以选取第 m 行(包含 m)到第 n 行(不包含 n)之间的所有数据。不过这里的序号 m、n 不是数据的行索引值,而是数据行的数字序号,这个行数字序号和 Excel 中的行序号几乎一样,唯一的区别是 Excel 中行序号是从 1 开始算起的,而 Pandas 中的行序号是从 0 开始算起的(如上图所示)。示例代码如下。
## 选取数据 DATA 中的第 10 到 第 15 行数据(这里所说的行序号是从 1 开始计算的)
# 由于 DataaFrame 的行序号从 0 开始,且是左闭右开区间,所以正确的代码如下
DATA[9:15] # 注意行序号
3选取单个数据值
在上文【字段选取】一小节中,我们使用了选取一个字段的代码DATA['公司中文名称'],笔者在注释中有提到,使用这样的代码选取的数据字段为一维 Series 类型,我们已经介绍过 Series 类型,这是一种具有索引的一维数据类型,如果是从 DataFrame 中得到的 Series,那么得到的 Series 还具有与 DataFrame 一样的索引值,例如:
DATA['公司中文名称']
所以选取单个数据值的常用方法就是先选取一列数据,再使用行索引取出目标值即可,例如需要取出表中公司中文名称字段中行索引值为 2 的数据值,就可以使用下面的代码。
DATA['公司中文名称'][2]
# 得到:'国海证券股份有限公司' 可以参考上图
对于初学 Pandas 的同学来说,这是一种定位具体某一数据值最常用的方式,经常在批量处理数据的循环代码中使用。
4选取任意数据
上文几个小节中,我们介绍了 Pandas 中选取行、列、值的几种方法,但是这些还无法满足更加多样的数据需求。在 Pandas 中,存在两个函数 loc 与 iloc,使用他们能够根据表格的行列索引或行列序号获取任意区域或满足某种条件的数据,下面我们来详细介绍这两个函数的用法。
(1)根据索引选取:loc 函数
Pandas 中表格数据类型 DataFrame 中存在一个loc函数,函数用法如下:
DataFrame.loc[row_label, column_label]
loc函数中共有两个参数 row_label 和 column_label ,分别对应着所选取区域的行索引和字段名。众所周知,表格数据是二维数据,我们通过表格数据的行列编号就可以找到对应的数据,loc 函数正是通过这个原理来选取数据的,即loc函数是根据数据的索引值来选取数据的。为了使用方便,loc函数内置的参数形式有很多种,下面我们根据参数的形式来介绍loc函数的用法。
① 参数为单个索引值
使用loc函数时可以将参数设置为单个行索引和列索引(列索引即字段名称),可以用这种方式来获取表中某个位置的具体值,示例代码如下。
## 目的:选取‘证券简称’字段中,行索引为 3 的数据值
DATA.loc[3, '证券简称'] # 注意行索引在前,字段名在后,中间用逗号隔开
# 得到:'广发证券'
上述代码DATA.loc[3, '证券简称']的含义就是获取数据DATA 中'证券简称'这一字段行索引为 3 的值。对应到表中便是:'广发证券'。
② 参数为索引列表
如果想要获取指定几行几列数据,我们还可以将索引参数设置为包含索引值的列表,示例代码如下。
## 选取‘公司中文名称’、‘员工总数’ 这两个字段,行索引是 1、3、4、7 的数据
DATA.loc[[1,3,4,7], ['公司中文名称', '员工总数']]

选中的数据仍是二维数据,所以选取的结果仍是一个 DataFrame。
③ 参数为索引范围
当需要选取某一个数值范围的数据时,例如需要选取行索引值从 100 到 200 (含200)的数据时,我们可以直接使用类似于字符串切片的范围参数100:200来充当loc函数的参数(字符串切片的用法。同样地,字段名称(列索引)也可以使用范围参数,示例代码如下。
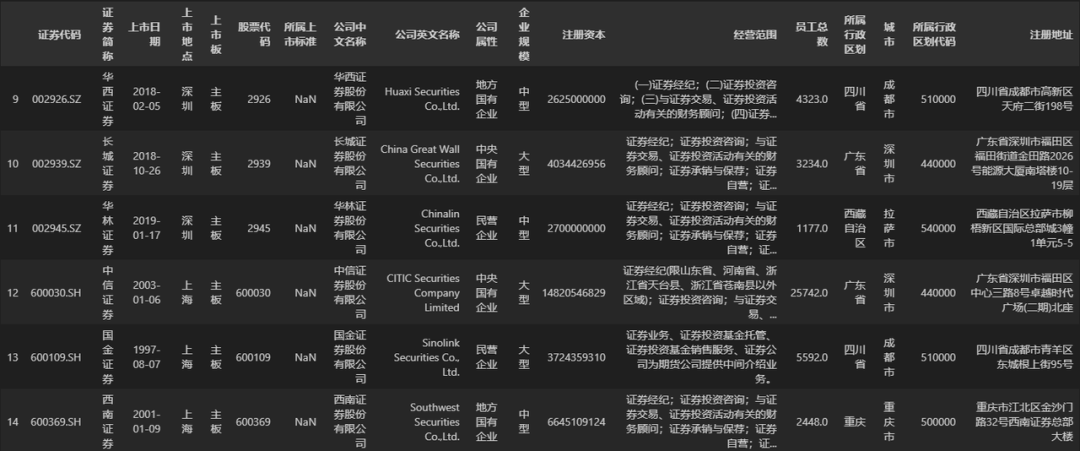
## 选取从‘证券代码’字段到‘公司属性’字段,行索引值从 100 到 200 的所有数据
DATA.loc[100:200, '证券代码':'公司属性']
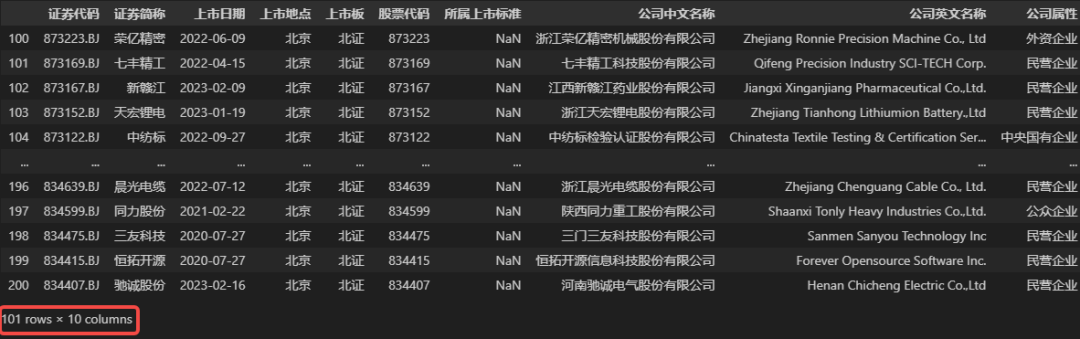
使用切片范围作为loc函数时,有以下几点需要注意。
-
使用行索引切片时,需要保证数据的行索引是连续的,且切片范围是合理的,右侧索引值须大于等于左侧索引值;
-
同样的,字段名切片是按字段顺序选取的,也需保证顺序的逻辑性;
-
在 Python 中,一般的切片都是左闭右开区间,即包含切片左侧的值,不包含切片右侧的值。但
loc函数是个例外,其内的切片参数是一个左闭右闭区间,同时包含切片两侧的索引值,例如上例中,切片100:200的选取结果实际上包含了行索引是 200 的数据行,所以选取结果的数据量才是 101 行。 -
参数为索引范围切片时,切片两侧的值可以省略,省略左侧代表从最小的行索引值(或最左侧的字段名)开始计算,省略右侧代表到最大的行索引值(或最右侧的字段名)结束,切片两侧的值虽然可以省略,但是切片中间的冒号(:)必须保留。
下面是loc函数使用范围切片作为参数时的另一个示例代码。
## 选取行索引从 0 到 5 ;字段名从‘公司中文名称’一直到最后的数据
DATA.loc[:5, '公司中文名称':] # 这里省略了切片中的部分值

④ 参数为简单条件
除了可以像以上几种情况那样直接根据索引值来选取数据之外,loc函数还可以间接地根据索引值来获取指定的数据,这里的“间接”指的是什么呢?在 Pandas 中,使用条件表达式也可以生成数据索引值,根据条件间接获取索引值的示例代码如下。
## 获取 DATA 中‘员工总数’不少于 10000 的所有数据的行索引
DATA['员工总数'] >= 10000
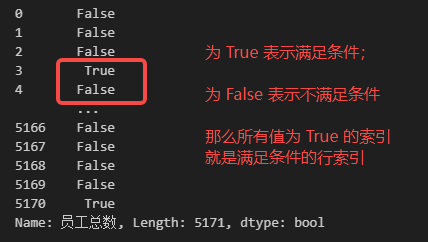
所以我们就可以根据上述条件完成相应的数据筛选。对应的选取代码如下。
## 选取数据 DATA 中员工总数不少于 10000 的所有字段数据
DATA.loc[DATA['员工总数'] >= 10000, :] # 这里的行索引参数用的是简单条件,列索引用了范围切片,
# 并省略了切片前后的值,表示所有列

上述代码中行索引参数用的是简单条件,列索引用了范围切片,实际上列索引参数也可以使用判断条件,但是在我们日常使用数据的习惯中,大多是根据数据行进行筛选数据的,根据字段名筛选字段的场景少之又少。下面笔者只介绍一个根据字段名条件表达式来筛选数据的示例。
## 选取数据 DATA 中员工总数不少于 10000 , 且字段名中包含‘公司’二字的所有数据
DATA.loc[DATA['员工总数'] >= 10000, DATA.columns.str.contains('公司')]
最后,有一点需要明确说明,在介绍loc函数的参数类型时,上文中笔者都会把行索引参数和列索引参数设置为相同的类型,这是为了方便大家学习行列索引参数的使用。实际上,loc函数是一个非常灵活的数据选取函数,其中行索引值参数和列索引值参数(即字段名参数)是相互独立的,也就是说它们的类型是随意的,没必要保持类型一致,可以随意搭配,且除了以上介绍的四种常用参数类型,还可以有其他的参数类型,其中的无穷用法需要大家自行学习探索。
(2)根据顺序选取:iloc 函数
与loc函数功能和用法十分相似的另一个数据选取函数是iloc函数,用法如下。
DataFrame.iloc[row_label, column_label]
从函数形式可以看出,iloc函数与loc函数的用法可能并无二致,事实上从用法方面来说确实如此,不过由于两个函数选取数据的依据不同,导致两者在参数类型上略有不同。上文中介绍的loc函数是根据数据的行列索引选取数据的,而下面要介绍的iloc函数则是根据数据的行列索引来选取数据的。这与我们口头上第几行第几列的说法十分相似,不同点是 Pandas 中的行列顺序都是从 0 开始,而不是从 1 开始算起的,所以使用时还需注意行列顺序值。下面我们根据不同的参数类型来介绍iloc函数。
①参数为单个序号值
在iloc函数中,行顺序值,列顺序值都是自然数,且与数据的行索引值没有任何关系。
## 选取第 2 行,第 6 列数据
DATA.iloc[1, 5]
# 得到:728
运行以上代码后,输出的值为 728,正是数据DATA中第 2 行,第 6 行的值,该数据所在位置如下图所示。
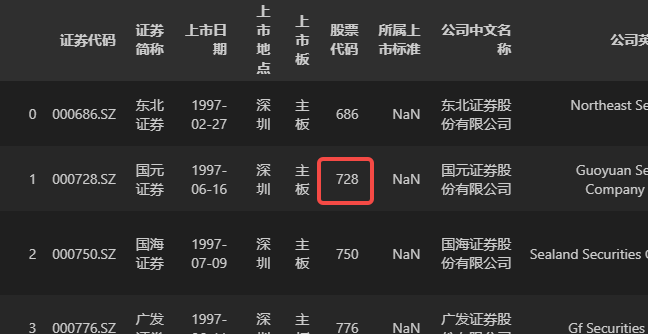
需要注意的是,由于 Pandas 的行列序号都是从 0 开始算起的,所以代码中的序号值要比描述的顺序小 1。
② 参数为序号列表
同loc函数一样,iloc函数的参数形式可以是列表。在loc函数中,列表中的值是行列索引的值,而在iloc函数中,列表中的值得是行列的序号值才行。示例代码如下。
## 选取第 3,4,6,7 行,第 2,6,8,9,10 列的数据
DATA.iloc[[2,3,5,6], [1,5,7,8,9]]

③ 参数为序号范围
iloc函数也支持传入范围切片作为数据选取的序号值,例如当需要选取第 100 到 200(含200)行数据时,可以设置行序号切片为 99:200,示例代码如下。
## 选取第 100 到 200(含200)行,全部列数据
DATA.iloc[99:200, :]
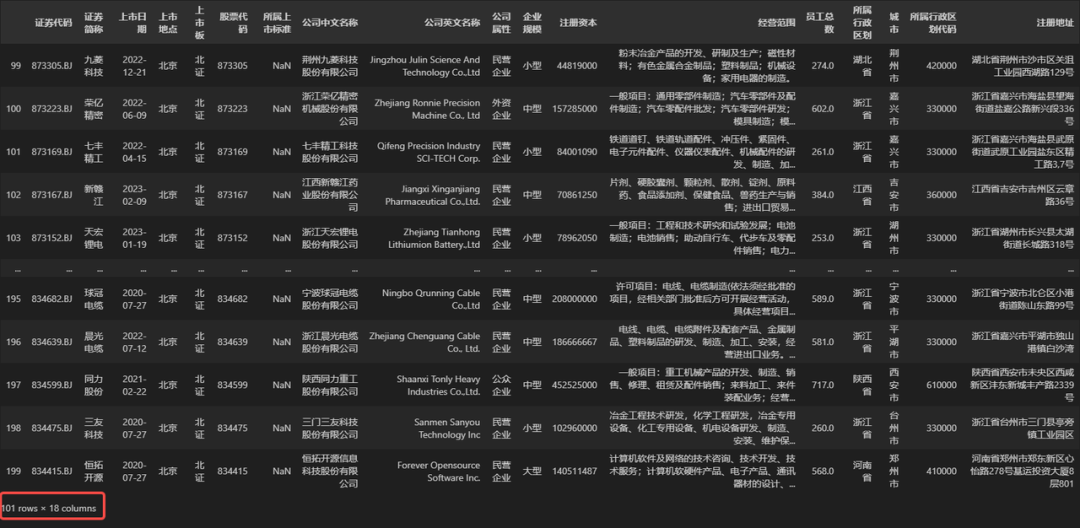
细心的同学应该已经发现了此处和loc函数不一样的地方,根据行序号的规则,第 100 到 200(含200)行的表示方法不应该是 99:199 才对吗,为什么代码中是99:200呢?这就要说到两个函数在切片规则上的不同之处了。
-
loc函数中的索引值切片对应的是一个左闭右闭的区间,而iloc函数中的序号切片则是一个左闭右开的区间,因此区间右侧的值需要多出 1 才行。 -
使用
iloc函数选取数据时,对数据的行列索引值没有任何要求,即数据的索引可以不连续。
数据选取有何用武之地?
我们已经在上文中洋洋洒洒把数据选取的两个函数扒得一干二净,那么这两个函数在数据处理中究竟有什么作用,扮演什么角色呢?下面我们来做一个简单说明。
1查看数据或生成新数据
正如介绍数据选取函数时演示的那样,数据选取可以方便我们查看选取的数据,或者当需要对数据进行裁剪操作时,也可使用数据选取函数来生成新的数据对象。例如当我们只需要表格中的某几列数据时,可以将数据选取的结果赋值给新变量,然后再对新变量进行处理分析,示例代码如下。
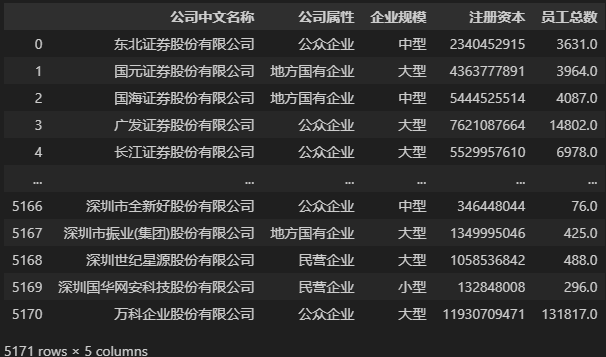
# 选取数据的公司中文名称、公司属性、企业规模、注册资本、员工总数 这几个字段,生成新数据
DATA_NEW = DATA[['公司中文名称', '公司属性', '企业规模', '注册资本', '员工总数']]
# 或:DATA_NEW = DATA.loc[:, ['公司中文名称', '公司属性', '企业规模', '注册资本', '员工总数']]
DATA_NEW
2修改数据值
在处理 Excel 表格时,如果需要修改某几处数据值,那么打开 Excel 表格文件,手动修改就可以了。但如果是在 Pandas 中,由于读取后的表格数据位于内存中,我们无法手动修改内存中表格数据的值,这时就需要使用数据选取函数来修改表中的数据值,示例代码如下。
## 假设需要手工更新数据,将前两行的员工总数分别修改为 3640 和 4000
# 方法1
DATA_NEW['员工总数'][0] = 3640
DATA_NEW['员工总数'][1] = 4000
# 方法2
DATA_NEW.loc[0, '员工总数'] = 3640
DATA_NEW.loc[1, '员工总数'] = 4000
# 方法3
DATA_NEW.loc[[0,1], '员工总数'] = (3640, 4000)
# 以上方法使用任意一种即可
修改后发现对应位置数据已经被替换为我们需要的值,如下图所示。
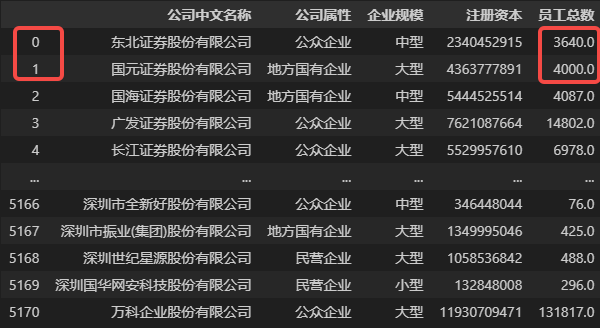
当然这只是手动修改少数几处数据值的方法,在 Pandas 中,真正需要修改数据值的场景大多在处理“大数据”的需求中,而在这些场景中,相当一部分需要借助数据选取的方式来修改数据,所以说本文介绍的内容是 Python 处理大数据的一项重要知识。
Excel 的数据筛选与分布统计
在 Excel / WPS 等办公软件中,最基本的数据筛选主要以单元格的内容为主,以 WPS 为例,选中一列内容后,点击右上方【筛选】,再点击字段名右下方按钮就会弹出按值筛选的筛选框,如下图所示。
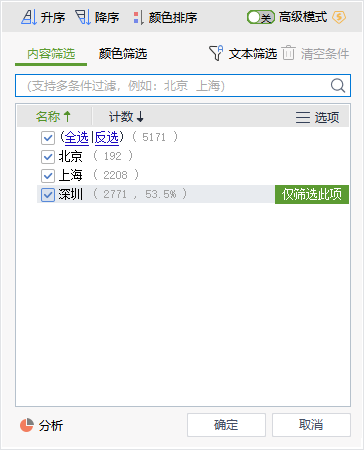
这种以字段内容作为条件的数据筛选是最基本、常用的一种,在点击【筛选】后,WPS 会立即对当前字段的所有内容做一个分布统计,显示每一种取值的数量和百分比,因此大家也习惯使用筛选的功能来做字段值的分布统计,说到这里就不得不介绍一下 Pandas 中的字段值统计操作了,下面是读取数据并统计上市地点字段值分布的代码。
读取并展示部分数据:
# 导入 pandas
import pandas as pd
# 读取演示数据
data = pd.read_excel('./A股上市公司部分信息(截至2023.5.12).xlsx')
# 处理字段名,做简化处理
data.columns = [COL.split('\n')[0] for COL in list(data.columns)]
# 展示数据前两行
data.head(2)

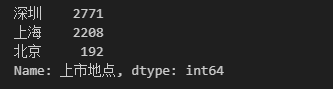
字段取值数量统计:统计上市地点字段中值的分布
# 数量统计
data['上市地点'].value_counts()
# 所得结果如下图,A股上市公司上市地点中,值为“深圳”的最多,为 2771
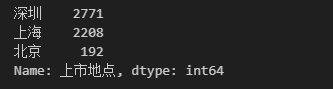
字段取值比率统计:统计上市地点字段中值的分布,以比率的形式展现
# 比率统计,在数量统计的基础上加一个参数 normalize=True
data['上市地点'].value_counts(normalize=True)
除此之外,如果需要对字段内容进行片段内容查询,还可以在上图所示的筛选框中点击右上方的【文本筛选】进行更细致的筛选。除了查找明确的字符,还可以使用通配符*和?进行模糊匹配(*代表任意多个字符,?代表任意单个字符),颇有一些正则表达式的味道。
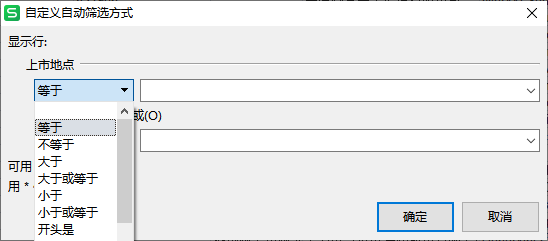
在 Pandas 中,类似的数据筛选同样存在,不仅如此,在模糊查找方面,由于 Pandas 中已经融入了正则表达式,所以在文本数据的筛选中,可以利用正则表达式进行更加自由、细致的筛选操作,除此之外,Pandas 还可以从更多的维度来进行筛选,下面我们一起来学习。
本文拿 Excel / WPS 与 Pandas 做了数据筛选方面的简单对比,本意不是踩一捧一,而是说明不同工具的差异。如果大家能在这里学到 Excel / WPS 的实用操作,这当然也是一件好事。


















 8804
8804

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











