









本文中所有的图片均来自原文。 未标注参考文献编码直接使用论文名的均为原文的参考文献。本文是我本人对原文学习研究后的理解和介绍。“当前应用与未来期待”部分以及文中对结果部分的几点“质疑”完全是我个人的观点。
在开始前,作为学习专栏,先简单介绍一下博弈论与强化学习:
- 博弈论是研究不同个体或群体在竞争或合作环境下如何做出最佳决策的数学理论。它分析在多个参与者互动的情境中,各方如何选择策略以最大化自身利益或达到某种均衡状态。
- 强化学习则是一种机器学习方法,模拟个体(智能体)在未知环境中通过试错学习获得最佳策略。智能体在与环境互动过程中,通过奖励或惩罚来调整行为,以达到预期的目标。
- 博弈论与强化学习的联系在于,强化学习中的智能体与环境的互动可以视为一种博弈。在多智能体系统中,多个智能体的行为会互相影响,这种情况与博弈论的分析场景相似。因此,博弈论可以用于分析和优化多智能体强化学习的问题,帮助智能体在多方互动中找到最优策略。
摘要
本文是对《Decentralized Task Offloading in Edge Computing: An Offline-to-Online Reinforcement Learning Approach》的综述和对其提出模型的研究报告,原论文研究了边缘计算环境中分散式任务卸载的挑战,提出了一种Offline-to-Online深度强化学习(O2O-DRL)模型来提高任务成功率并优化资源分配。原论文通过离线预训练和在线微调相结合,构建了O2O-DRL模型以解决冷启动问题,从而在边缘环境中实现高效、实时的任务调度。实验结果表明,O2O-DRL在多种负载条件下优于传统方法,展示了其在边缘计算应用中的可行性和扩展潜力。同时,本文也对原论文对实际环境地复杂程度模拟和结论是否过于乐观提出了一定的质疑。
关键词:边缘计算,任务卸载,深度强化学习,离线-在线学习,冷启动,资源分配
绪论
原论文主要探讨了在边缘计算环境中分散式任务卸载的挑战和解决方案。边缘计算作为云计算的一种延伸[1],通过将计算资源下沉到网络边缘来应对延时敏感型任务。然而,随着用户设备的增多和网络环境的复杂性,边缘计算中的任务卸载面临多重挑战:如何在有限的计算资源下高效分配任务?如何在动态环境中保持资源利用率与任务成功率的平衡?任务卸载需要在任务复杂性、计算需求和实时性等因素之间权衡,而不良的资源分配可能导致计算延迟或失败,进而影响用户体验。因此,提升任务成功率和优化资源分配成为边缘计算研究中的重要问题。
现有相关工作(三类基准方案)
当前的研究中,边缘计算的任务卸载策略分为集中式和分布式两种。在集中式方法中,云或边缘服务器通过集中式决策来分配任务,而分布式方法则更多依赖设备之间的协同。
- 边缘计算的任务卸载策略是将计算任务转移至边缘或云端,以降低延迟并优化资源分配。
当前基于启发式算法中的任务卸载机制
通常可以用于集中式和分布式两种场景,但在集中式中更常见。
多任务部分计算卸载和网络流调度的联合问题
《Spectrum-aware Multi-hop Task Routing in Vehicle-assisted Collaborative Edge Computing》的作者采用了一种基于多智能体深度确定性策略梯度(MADDPG)的启发式算法以解决多任务部分计算卸载和网络流调度的联合优化问题。
通过将每个终端用户视为独立的智能体,MADDPG算法根据网络动态和车辆移动性实时优化多跳任务卸载路径。主要实验结果表明,该方法在满足端到端延迟和资源限制的前提下显著提高了任务完成率和系统吞吐量,相比传统的单跳和贪心多跳卸载方案,该算法在动态环境中展现了更高的任务完成率和负载平衡能力。
- 网络流调度指在网络中管理和优化数据传输路径,以减少延迟并提高资源利用率。
- 多跳任务卸载路径指通过多个中间节点(如车辆或设备)将计算任务逐步传递到目标边缘服务器,扩展任务传输的范围。
移动边缘计算中的对等卸载问题
《Peer Offloading in Mobile Edge Computing with Worst-Case Response Time Guarantees》针对移动边缘计算中的对等卸载问题,提出了两种启发式算法,旨在优化时间平均吞吐量并满足能耗和最坏响应时间约束。在实验中,作者采用了两种在线算法:一种假设任务到达率已知,通过理论分析实现最优系统性能;另一种在任务到达率未知时,基于Lyapunov优化框架管理计算任务的随机到达。实验结果表明,该方法在负载动态变化的复杂网络环境中显著提升了任务完成率,并在保证低响应时间的同时,实现了更高的系统吞吐量,与其他基准方案相比表现出明显的优势。
- 对等卸载问题是指设备之间协作将计算任务卸载给邻近设备,以减少延迟并节省资源。
分散式任务卸载问题
《Computational Load Balancing on the Edge in Absence of Cloud and Fog》的实验方法基于反应性分布式算法,通过分散式调度使传感器网络设备协同工作,优化能耗和延迟表现。其核心在于通过网络中各节点共享的状态信息,根据当前负载情况分配任务,实现负载均衡。实验结果显示该算法在低带宽或连接不完整的环境下表现良好,有效增加了任务的完成率,并显著平衡了能量消耗与系统性能的关系。
《Power of Random Choices Made Efficient for Fog Computing》则提出了一种适用于雾计算的基于阈值的负载均衡协议(LL(F,T)),在负载超过阈值时,节点会随机探测邻近节点的负载状态,将任务转交给较轻负载的节点。通过模拟实验,研究显示在高动态和异构节点环境中,该协议显著降低了延迟和通信开销,同时优化了节点间资源利用效率,相比传统集中式方案更适合雾计算的去中心化场景。
- 分散式任务卸载问题涉及在边缘节点间自主决策任务的分配与执行,以最大化资源利用率和系统性能,而无需集中控制。
- 雾计算是一种将计算和存储资源分布在网络边缘附近节点上的计算模式,以降低数据传输延迟并提高本地处理效率,特别适用于实时和物联网应用。
- 异构网络环境指包含多种不同类型设备、协议或网络架构的网络环境,设备之间的互联互通需要兼容性和协调。
当前基于博弈论中的任务卸载机制
基于启发式算法的研究需要集中控制,这可能导致过高的传输开销,且不适用于大规模边缘网络。而且这些方法主要专注于贪婪优化,从长期角度来看可能产生次优解。基于博弈论的机制多用于分布式场景。设备之间通过博弈建立协作,实现自主卸载决策,适用于异构和动态的网络环境。
雾计算中的任务卸载问题
《Decentralized Algorithm for Randomized Task Allocation in Fog Computing Systems》在雾计算中研究了多用户的任务卸载问题,并将其建模为一个多用户计算卸载博弈,提出了静态混合纳什均衡(SM-NE)算法来求解该博弈的均衡解。实验方法主要是通过仿真对比SM-NE算法与全局最佳响应(MBR)算法的性能,其中MBR算法需要全局系统状态的知识,而SM-NE算法仅依赖平均系统参数。结果表明,尽管SM-NE算法的信令开销较低,但其系统性能接近于MBR算法,实现了良好的任务分配效率,并显著提升了系统吞吐量和减少了任务完成时间。
- 纳什均衡在博弈中指的是各方在给定其他参与者策略的情况下无法通过单方面改变自身策略来获得更高收益的状态。
MEC服务器的最优定价策略和用户数据卸载策略问题
《Price and Risk Awareness for Data Offloading Decision-Making in Edge Computing Systems》通过多主多从的斯塔克尔伯格博弈模型,研究了雾计算中用户任务卸载的定价和风险感知问题。作者提出的实验方法中,雾计算(MEC)服务器作为领导者制定最优的计算服务定价策略,而用户作为追随者基于前景理论的效用函数选择数据卸载策略,以平衡风险和收益,并避免过度利用服务器的资源。实验结果显示,提出的定价策略不仅有效提升了MEC服务器的收益,还显著改善了用户在风险约束下的任务完成率,相比于传统方法实现了更优的资源利用和服务质量。
- 在斯塔克尔伯格博弈模型中,一方作为领导者首先做出决策,随后追随者根据领导者的选择来制定自己的最佳策略,从而形成分层决策过程。
当前基于深度强化学习中的任务卸载机制
然而,随着边缘节点的增加,集中式方法难以应对资源调度的实时性需求,而分布式方法的任务卸载决策可能因设备资源的异构性而效率低下。深度强化学习作为一种高效的决策模型,被广泛应用于任务卸载和资源调度。这种机制在集中式下和分布式下均可有所成效,集中式深度学习方法由中心节点训练模型;而分布式方法可采用边缘设备联合训练,实现去中心化任务分配。
普适边缘计算网络中的分散式任务卸载问题
《Multi-Agent Imitation Learning for Pervasive Edge Computing: A Decentralized Computation Offloading Algorithm》提出了一种基于多智能体模仿学习的分散式任务卸载算法,用于普适边缘计算网络的任务卸载问题。该实验方法使用多智能体模仿学习,其中多个设备作为智能体,通过观察专家策略并模仿其行为,在局部观测的基础上实现近似的纳什均衡。实验结果表明,该算法在优化任务完成时间和资源利用率方面具有显著优势,并能够在去中心化环境中实现较快的收敛速度,与其他基准方法相比有效提升了卸载效率和整体系统性能。
具有多个移动设备和雾设备的雾计算网络中的任务分割和功率控制联合问
《Multiagent DDPG-Based Joint Task Partitioning and Power Control in Fog Computing Networks》研究了多个移动设备(MD)和雾设备(FD)组成的雾计算网络中的任务分割与功率控制联合优化问题。作者提出了基于多智能体深度确定性策略梯度(MADDPG)方法来实现分布式任务卸载,通过引入中心化训练与分散化执行的框架,每个MD在给定本地状态的情况下做出最优任务分割与传输功率控制决策。实验结果表明,该方法显著优化了系统效用,降低了任务执行延迟和能耗,相较传统方法在不同任务规模和设备数量的条件下均表现出更优的稳定性和收敛速度。然而,以上工作直接将DRL应用于边缘计算,这会导致冷启动问题,显著影响在DRL模型收敛之前用户的QoE。
- 冷启动问题指模型在缺乏足够的初始数据或经验时可能性能不佳或无法做出准确决策。
- QoE指用户在使用服务时的整体满意度,衡量服务性能是否满足用户期望和需求。
离线训练DRL模型及初步由离线到在线问题
《OFF-POLICY DEEP REINFORCEMENT LEARNING WITHOUT EXPLORATION》的实验方法主要是利用批量约束深度Q学习(BCQ)来解决离线DRL模型在无交互环境中的训练问题,提出通过限制动作空间来减小推断误差,从而在离线数据上实现高效学习,实验结果显示该算法在离线数据的多任务环境下性能显著提高。与此同时,《Offline-to-Online Reinforcement Learning via Balanced Replay and Pessimistic Q-Ensemble》提出了一种离线到在线的过渡方法,采用平衡重放机制和悲观Q函数集成来应对状态-动作分布偏移的问题,实验表明这种方法在减少启动误差的同时提高了样本效率,表现出良好的在线调优能力,但在一些具有复杂状态分布偏移的机器人操控任务上,该方法的性能表现出现下降,特别是在初始的在线调优阶段,未能充分抵消因分布偏移带来的启动误差。
- DRL指传统的深度强化学习模型,通过在模拟环境中不断试错和积累经验,以学习最佳决策策略来最大化累积奖励。
- 离线指在无需实时环境交互的情况下,利用预先收集的数据集来训练模型或优化策略。
- 在线指在实际环境中通过实时交互,动态调整和改进模型或策略,以适应新的数据和情况。
原论文工作
虽然现有的离线和在线深度强化学习方法在任务卸载中各有应用,但两者都存在局限性。离线学习由于无法实时更新模型,导致在环境变化时,决策可能不再有效;在线学习虽然能够适应变化,但在训练早期表现欠佳,可能会导致较低的任务成功率或资源分配效率。因此,如何结合离线与在线学习的优势,以应对复杂的动态边缘计算环境,成为一个关键问题。此外,现有研究大多关注于同步任务卸载,而忽略了边缘计算环境中异步任务的复杂性。在异步场景下,如何保持任务成功率与系统整体性能仍是一个未解难题。
原论文研究了边缘节点间的分散式任务卸载问题。与先前的工作不同,原论文进一步考虑了任务执行和传输的可靠性。此外,原论文首次在边缘计算中的DRL应用场景中有效解决了冷启动问题。
提出方法:Offline-to-Online 深度强化学习模型
假设
- 故障发生只影响当前任务
- 一个任务只由一台设备执行
- 任何失效情况都不能化为由故障率驱动的泊松分布
- 初始数据在时间间隔t内到达节点服从伯努利分布
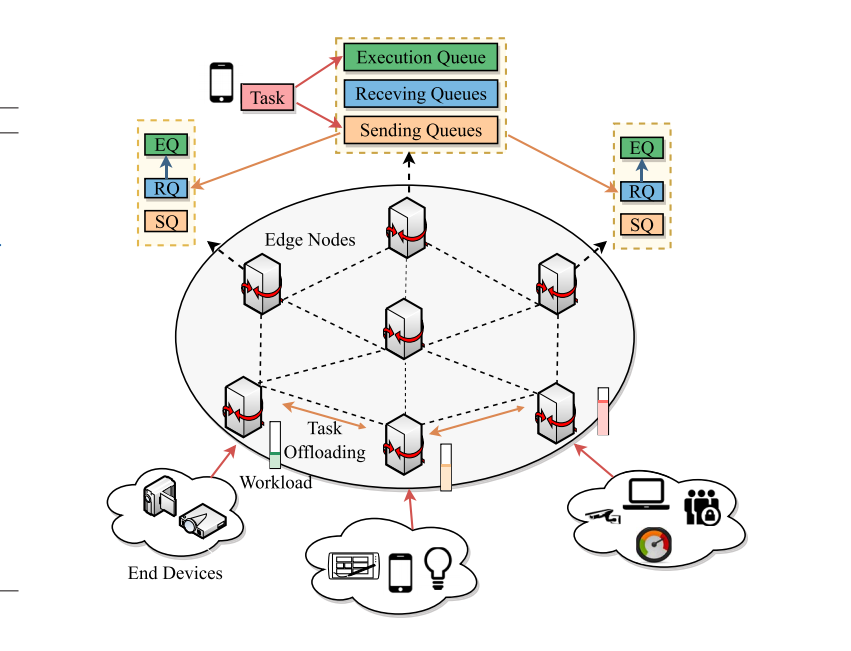
原论文提出了一种离线到在线的深度强化学习模型,其核心设计理念在于将离线学习的经验与在线学习的自适应性结合起来。在模型优化任务卸载与资源分配的过程中实现了两个核心目标:既提高了任务的成功率,也优化了资源利用效率。O2O-DRL 模型在离线阶段利用历史任务日志数据进行初步训练,以加速模型收敛并减少冷启动期间的性能损失;在在线阶段,通过实时环境反馈对模型参数进行微调,以适应动态边缘计算环境。
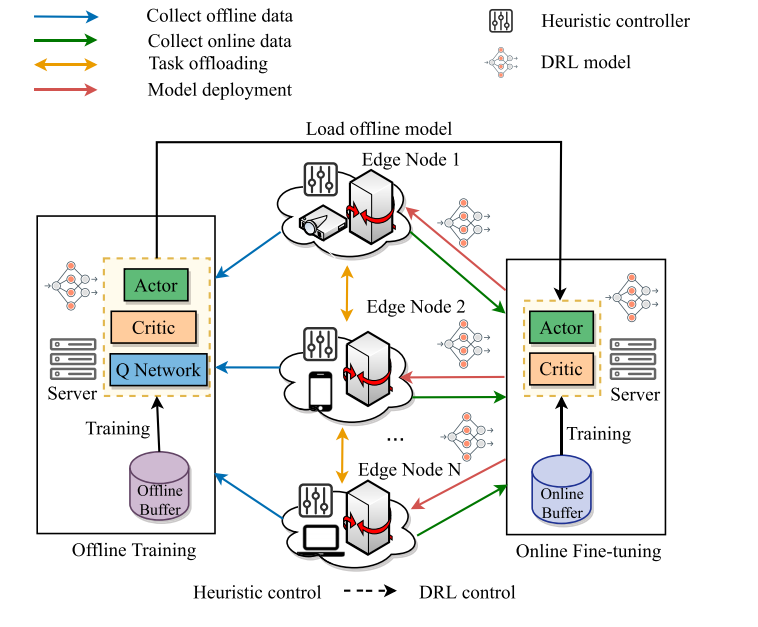
实施过程
离线阶段
在离线阶段,模型主要利用边缘节点生成的历史任务运行日志数据进行训练。该阶段主要任务是积累经验和优化决策策略,使得模型能够适应典型的任务负载和边缘计算环境。通过离线训练,模型在部署初期就具备初步的优化能力,避免了冷启动阶段的性能下降。该过程可以分为以下步骤,本文根据原文的伪代码进行了主要部分的代码复现:
数据收集与预处理
首先收集由启发式方法(如 RATC 算法)生成的任务运行日志数据,并将其存储为一组离散状态-动作-奖励的集合。每条记录包含以下元素:
- 状态 s_t:节点的观测信息,包括任务到达率、任务大小、CPU 需求、计算失败率等。
- 动作 a_t:当前节点选择的任务卸载决策,可能是本地处理或发送到特定的边缘节点。
- 奖励 r_t:任务成功处理的反馈(如成功则 +1,失败或超时则 -1)。
这些数据经过归一化处理,以确保特征值处于相同的量级范围,从而有利于模型的收敛。
离线训练架构

离线训练使用一种基于策略的离线强化学习方法(如离散软演员-评论家算法,Discrete Soft Actor-Critic,DSAC)。在这种架构下,训练过程分为以下几个主要模块:
- Actor 网络:负责策略的学习和改进,生成动作的概率分布。
- Critic 网络:估计动作的价值,帮助评估当前策略的优劣。
- Q 网络:两个独立的 Q 网络用于避免价值过高估计,计算动作的 Q 值。
训练时,通过经验回放池随机采样 mini-batch 数据,以减少样本间的相关性和训练偏差。以 Q 网络为例,目标值的计算方式如下:
# 目标 Q 值计算
def target_q_value(rewards, next_states, discount, q_network, target_network):
next_actions = actor_network(next_states)
min_q_value = torch.min(
q_network[0](next_states, next_actions),
q_network[1](next_states, next_actions)
)
return rewards + discount * min_q_value
- 通过 Q 值的计算,模型使用梯度下降法优化 Q 网络,使 Q 网络的估计误差最小化,通过使用正则项更新。
- Actor 网络更新通过最大化 soft Q 值(在强化学习中结合了熵正则化的Q值,鼓励策略探索更多的动作选择,从而在长期内更稳定地优化收益)完成:
# Actor 网络更新
def update_actor(states, actor_network, q_network):
actions = actor_network(states)
min_q_value = torch.min(
q_network[0](states, actions),
q_network[1](states, actions)
)
actor_loss = -min_q_value.mean() # 反向传播更新策略
return actor_loss
# Critic 网络更新(正则化损失)
def update_critic(states, actions, rewards, discount, q_network, target_network, lambda_c):
target_values = target_q_value(rewards, states, discount, actor_network, q_network, target_network)
loss_q1 = torch.mean((q_network[0](states, actions) - target_values) ** 2)
loss_q2 = torch.mean((q_network[1](states, actions) - target_values) ** 2)
# 正则项处理
reg_q1 = torch.logsumexp(q_network[0](states, actions), dim=1).mean() - q_network[0](states, actions).mean()
reg_q2 = torch.logsumexp(q_network[1](states, actions), dim=1).mean() - q_network[1](states, actions).mean()
critic_loss = loss_q1 + loss_q2 + lambda_c * (reg_q1 + reg_q2)
return critic_lossCQL 正则化处理
考虑到离线数据和模型策略存在分布不一致性,采用 Conservative Q-Learning正则化项,使 Q 值对未见过的动作降低,从而避免策略过度估计。
在线阶段

在部署至实际环境后,模型会进入在线微调阶段,在此阶段利用新生成的实时数据进行动态调整,以适应不断变化的任务负载和边缘资源。
策略微调
在线阶段的核心是基于策略的 on-policy 学习方法。在微调过程中,首先收集足够的在线数据,将它们存储到新的经验回放池中。接下来,利用通用优势估计(GAE)来减少偏差,同时平衡估值偏差和方差,更新 Actor 和 Critic 网络:
# 优势估计计算
def calculate_advantage(rewards, values, next_values, discount, gae_lambda):
deltas = rewards + discount * next_values – values
advantages = torch.zeros_like(rewards)
gae = 0 for t in reversed(range(len(rewards))):
gae = deltas[t] + discount * gae_lambda * gae
advantages[t] = gae return advantages目标值更新:每个时间步的目标值可以通过优势估计加上当前值来计算:
# 计算目标值
def target_value(advantages, values):
return advantages + values
策略优化
在策略优化中,采用 PPO 算法的 clip-trick 更新 Actor 网络,以确保在线更新的稳定性和效率。clip-trick 的目标是保持新旧策略变化在一定范围内:
# PPO 策略优化
def ppo_update(actor_network, critic_network, states, actions, advantages, clip_param):
old_probs = actor_network(states).gather(1, actions)
new_probs = actor_network(states).gather(1, actions)
ratio = new_probs / old_probs
clipped_ratio = torch.clamp(ratio, 1 - clip_param, 1 + clip_param)
olicy_loss =- torch.min(ratio * advantages, clipped_ratio * advantages).mean()
return policy_loss
# Critic 网络更新
def update_critic_online(critic_network, states, target_values):
critic_loss=torch.mean((critic_network(states) - target_values) ** 2)
return critic_loss
实时更新与模型推理
每一轮更新后,将 Actor 网络更新至边缘节点,从而实现分布式的去中心化推理。在实际推理中,边缘节点根据当前观测信息选择动作,将任务卸载至资源可用、可靠性较高的节点上,实现高效的边缘协作。
O2O-DRL 模型的训练与推理过程
O2O-DRL 模型采用双阶段强化学习架构来解决离线和在线数据分布不一致的问题。首先进行离线训练,以减少冷启动问题;然后通过在线训练进一步更新策略,确保模型能够迅速适应动态环境。模型使用离线数据进行策略的初步学习,通过基于策略的在线训练机制来避免策略过度估计,从而平衡离线和在线阶段的策略稳定性。
实验结果
环境设置
实验设置在 Python 模拟器中进行,模拟边缘计算环境以验证 O2O-DRL 模型的有效性。边缘节点的数量为 20,总时间段为 100 个单位时间,每个任务的到达概率、任务大小、计算复杂度、节点的 CPU 频率等参数按照特定的范围分布设置,以模拟不同任务负载的边缘计算场景。
实验还有在工作平台的测试,工作平台论文原作者开源在github上了,本文不对其做评述和解释。
影响因素
启发式方法的影响
O2O-DRL 模型通过使用启发式算法生成的任务运行日志数据进行离线学习,结果表明,选择不同的启发式方法对 O2O-DRL 的性能有显著影响。相比其他启发式算法,RATC 能更好地指导模型学习优化策略,以提升任务成功率。
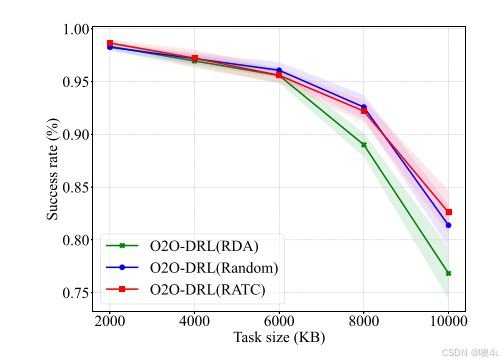
任务大小的影响
随着任务大小的增加,所有方法的任务成功率均有所下降。O2O-DRL 在较大任务情况下表现尤为优越,表明该方法能够在高负载条件下有效分配资源并提高成功率。
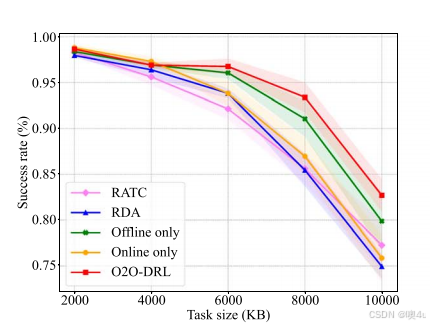
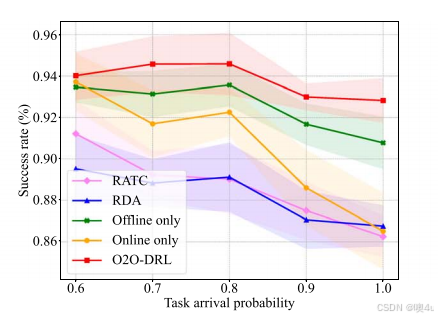
任务到达概率的影响
实验显示,任务到达概率的增大导致任务成功率的下降。O2O-DRL 模型在各个任务到达概率下都表现优于其他方法,并能够有效平衡高负载时的任务调度需求。
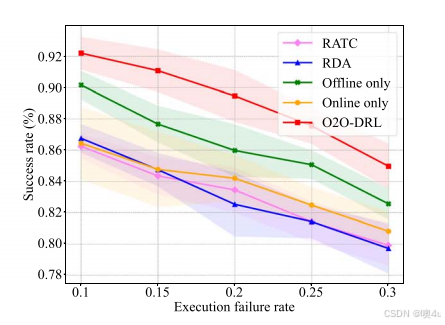
失败率的影响
随着边缘节点执行失败率的增加,任务成功率逐渐降低。O2O-DRL在所有失败率设置下表现优于其他基准方法,说明其可以在考虑任务可靠性的前提下提升成功率。
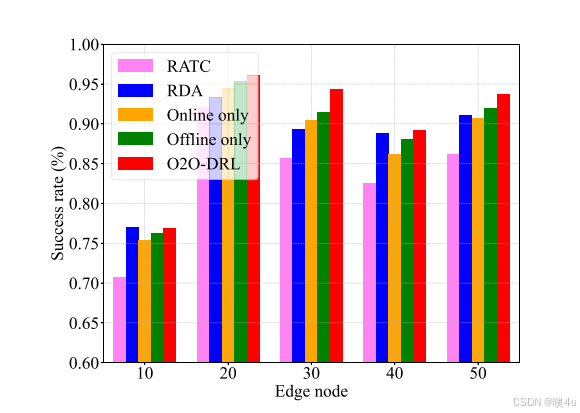
边缘节点数量的影响
实验结果表明,随着系统中边缘节点数量的增加,O2O-DRL方法在性能上优于其他方法,展示出良好的扩展性。具体而言,O2O-DRL通过在线微调在性能上进一步优化,超过了仅使用历史运行日志进行训练的离线方法和直接在网络中进行在线学习的在线方法,后者往往因缺乏启发式指导而容易陷入次优解。
模型效果
提出方法的收敛性
实验结果表明,O2O-DRL 模型能够在离线阶段和在线微调阶段快速收敛,并在训练结束时收敛到优于其他方法的解决方案。该模型在离线阶段的策略指导下,能够更快达到稳定状态,且相比直接在线学习能够避免次优解。 从图中我们也能直观的看出本篇论文提出的模型确实在当前实验环境下极大地解决了冷启动问题。
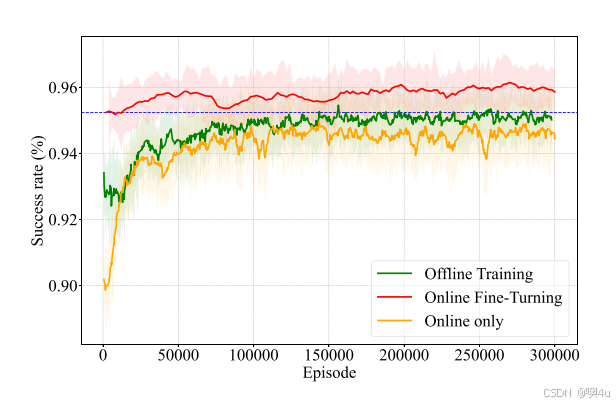
任务成功率
O2O-DRL 方法在任务成功率上显著优于传统方法和基于在线学习的 DRL 方法,特别是在动态环境下表现突出。
任务执行延迟
通过在任务执行延迟方面的测试,O2O-DRL 表现出比基准方法更低的延迟。这表明 O2O-DRL 模型在任务调度过程中能够更有效地平衡延迟与成功率。
资源利用率
O2O-DRL 模型通过在线微调策略进一步提升了资源利用率。在同等条件下,O2O-DRL 能更高效地利用边缘计算资源,从而在高负载场景中确保更高的任务完成率。
本文对原论文结果的质疑
在本文之前对模型和实验过程的分析的过程中已经提到本文是建立在四个假设上的,即“故障发生只影响当前任务”、“一个任务只由一台设备执行”、“任何失效情况都不能化为由故障率驱动的泊松分布”和“初始数据在时间间隔t内到达节点服从伯努利分布”。此外,对边缘节点数量的限制、任务负载的多样性的模拟、实验指标的选择和评价这四点因素都对实验环境的模拟精度产生了“美化原论文结果”的影响:
假设的合理性
- 故障影响的范围:假设“故障发生只影响当前任务”似乎将系统的复杂性简化了。实际边缘计算环境中,硬件或软件故障可能会对整个系统或其他任务产生连锁反应,因此这一假设是否合理值得质疑。
- 单设备执行假设:假设“一个任务只由一台设备执行”,忽略了分布式计算的潜在优势。在边缘计算中,任务分片或并行处理可以提高效率和容错能力,这一假设的合理性可以进一步探讨。
- 泊松分布的排除:假设任何失效情况都不能化为由故障率驱动的泊松分布,这在传统的系统可靠性建模中是不常见的。通常故障模型会采用泊松分布,因此完全排除泊松分布的应用是否适合需要更多依据。
- 初始数据的伯努利分布:该假设对一些场景可能过于简单化,现实中的数据流入情况可能受网络波动、用户行为等多种因素影响,未必完全符合伯努利分布。
边缘节点数量的限制
- 节点数量的代表性:该实验仅在10至50个边缘节点的范围内进行测试,可能不足以充分验证模型的可扩展性。实际应用中边缘计算网络通常规模更大,节点数量多样,因此测试节点数量过少可能导致实验结果缺乏广泛适用性。
- 负载均衡和可靠性影响:在较小的节点数下,系统的负载均衡和容错能力会受到限制,因此实验结果可能无法体现模型在大规模、多节点环境下的实际表现,这点可能会影响实验结果的泛化性。
任务负载的多样性
- 负载变化:原论文诚然考虑到了任务到达率和负载的动态变化,但限制任务的输入大小在 [1000, 8000] KB 之间、任务的复杂性在 [800, 2400] CPU周期/位的范围内变化、任务到达率遵循 [0, 1] 范围内的均匀分布是否真的能充分模拟实际边缘计算环境的多样性和复杂性仍然是一个值得讨论的问题。
实验指标的选择和评价
- 不同方法的基准对比:虽然文章中对比了多种基准方法,但这些方法是否具有代表性且合理?例如,如果某些基准方法本身在实际应用中已被证明效果不佳,则对比结果的实际意义可能受到质疑。,如原论文正是因为单一离线训练或单一在线训练存在问题才提出的该模型,那论文的实验结果优于这两者是一个更优模型的必要条件,但未能引入其他最新方法作为对比,可能导致实验结果不够全面。
综合以上四点我们可以合理的质疑原论文的仿真实验环境为仿真环境在计算资源、网络延迟和节点失效频率等方面可能与真实边缘计算环境存在差异,是否充分验证了仿真结果与真实环境的可转移性?边缘节点间的通信延迟和可靠性在实验中是否有真实地反映?如果实验结果未能考虑实际环境的复杂性,可能导致实验结果过于乐观,从而影响模型的实际应用效果。
当前应用与未来期待
当前应用
当前,在大数据推荐系统,如微博、小红书等平台,正使用了O2O-DRL 模型。在初次使用时、进入首页之前,会有交互式问卷让用户提前选择若干个感兴趣的领域或话题。这正是避免了在线训练的冷启动的问题,让用户在一开始刷新页面时就有良好的体验。
有些用户可能会反感使用交互式问卷的方式,那离线训练的数据也可以是使用热门内容推荐或利用用户的社交数据推荐,当然,在这个过程中也要注意脱敏问题。
更大规模和复杂网络环境中的应用前景
随着边缘计算网络规模的扩展和网络拓扑结构的复杂化,O2O-DRL 模型在这些环境中的应用前景更加广阔。例如,在智能电网和物联网 (IoT) 的大规模异构网络中,模型需要面对不同节点之间的任务协作和资源共享的需求。利用 OBAC 模型中的离线最优策略作为在线策略的基准,可以提高模型在大规模网络中的任务处理效率[2]。此外,通过分布式的深度强化学习技术[3],可以有效地解决资源和计算任务在大规模网络中的分配问题。因此,未来研究可以考虑如何通过分布式训练和节点协同优化,以进一步提升模型在复杂网络中的计算效率。
可能的优化方向与进一步研究的潜力
硬件加速与资源利用优化
随着边缘计算节点的硬件性能提升,通过硬件如GPU 和 TPU加速来优化 O2O-DRL 模型成为可能[4]。在未来,研究可以探索如何基于边缘节点的硬件特性设计更高效的任务分配策略,以实现实时响应和高资源利用率。
离线-在线策略的自适应融合
O2O-DRL 模型当前的离线与在线策略融合可以进一步优化。通过自适应权重调整机制,使模型能在不同负载条件下更灵活地切换策略。OBAC 框架[2]在这方面提出了可行的方法,通过对离线最优策略和在线策略的状态值比较,确保在线策略在必要时受到离线最优策略的引导,从而避免策略的过度偏差。
联邦学习的集成
在分布式边缘计算场景中,利用联邦学习技术在节点间共享模型更新可以进一步提升系统性能。联邦学习可以在保护隐私的前提下实现分布式学习[5],尤其适用于多节点任务协作的环境。未来研究可以探索如何在边缘计算环境中集成联邦学习技术,以实现节点间的协同优化,提升任务成功率和资源分配效率。
- 联邦学习技术是一种分布式机器学习方法,允许多个设备在不共享原始数据的情况下协同训练模型,从而保护数据隐私。
基于模仿学习的自适应探索
考虑到边缘计算环境的多样性和动态性,可以在模型中引入模仿学习模块,用于从经验中学习最佳任务卸载策略。模仿学习的优势在于可以加速模型的策略学习过程。模仿学习在任务协同与策略传递上具有显著优势[6],尤其适用于跨场景的策略适应和调整。因此,在边缘计算的跨场景应用中,模仿学习的引入可以有效提高策略迁移的效率。
- 模仿学习是指通过观察专家示范数据,训练模型模仿专家的决策行为,以快速学习复杂任务的有效策略。
总结
原论文通过深入分析边缘计算环境的任务卸载需求,提出O2O-DRL模型以应对动态网络中的高效资源分配难题。与传统集中或分散方法不同,O2O-DRL结合了离线经验和在线自适应调优,克服了冷启动问题并提高了任务成功率。实验验证了该模型在处理大规模、复杂任务时的有效性,特别是在资源有限的边缘节点中更能体现出其高效的调度与分配能力。本文通过对原论文工作的研究和复现,以及对相关工作的普及学习,认为未来工作可探索硬件加速、联邦学习等新技术的集成,以提升模型在复杂异构环境中的适应性。
参考文献
[1] Firdose Saeik, Marios Avgeris, Dimitrios Spatharakis, Nina Santi, Dimitrios Dechouniotis, et al.. Task Offloading in Edge and Cloud Computing: A Survey on Mathematical, Artificial Intelligence and Control Theory Solutions. Computer Networks, 2021, 195, 10.1016/j.comnet.2021.108177.hal03243071
[2] Luo, Y., Ji, T., Sun, F., et al. (2024). Offline-Boosted Actor-Critic: Adaptively Blending Optimal Historical Behaviors in Deep Off-Policy RL. Proceedings of the 41st International Conference on Machine Learning.
[3] Zhu, X., Zhao, Y., and Li, J. (2022). Distributed Deep Reinforcement Learning for Large-Scale Network Resource Allocation. IEEE Transactions on Network and Service Management.
[4] Gao, T., Chen, X., and Wu, H. (2023). Accelerated Task Scheduling in Edge Computing with Hardware-Assisted Reinforcement Learning. Journal of Parallel and Distributed Computing.
[5] Kairouz, P., McMahan, H. B., et al. (2021). Advances and Open Problems in Federated Learning. Foundations and Trends® in Machine Learning.
[6] Ho, J., and Ermon, S. (2016). Generative Adversarial Imitation Learning. Advances in Neural Information Processing Systems. https://blog.csdn.net/weixin_43336281/article/details/125243019


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









