










原文链接:Seeing the Unseen: A Frequency Prompt Guided Transformer for Image Restoration
原文翻译部分所有图片均截图自原文。研讨报告部分数据集图片来源于原文参考文献;其余来源于学校老师PPT及网络资料整理。
本文在arxiv中类属于“Computer Vision and Pattern Recognition”(计算机视觉与模式识别)
原文翻译
标题:看见未见之物:一种频率提示引导的变换器用于图像修复
Shihao Zhou1.2、Jinshan Pan3、Jinglei Shi1、Duosheng Chen1、Lishen Qu1、Jufeng Yang1.2
- 南开大学计算机科学学院(VCIP & TMCC & DISSec),天津,中国
{zhoushihao96, duoshengchen, lishenqu}@mail.nankai.edu.cn - 南开国际高级研究院(深圳福田),天津,中国
{jinglei.shi, yangjufeng}@nankai.edu.cn - 南京理工大学计算机科学与工程学院,南京,中国
摘要:如何从图像中提取有用特征作为提示来引导深度图像修复模型是解决图像修复问题的有效方法。与挖掘图像内的空间关系作为提示不同,后者往往忽略了不同频率的特征,从而导致恢复图像中出现微妙或无法察觉的伪影。为了克服这一问题,我们提出了一种频率提示引导的图像修复方法,称为FPro,能够有效地从频率的角度为修复模型提供提示组件,帮助其处理这些差异。具体而言,我们首先通过动态学习的滤波器将输入特征分解为不同的频率部分,并在此过程中引入了一个门控机制,用于抑制内核中不太有信息的元素。为了将有用的频率信息作为提示传播,我们提出了一个双提示块,其中包含低频提示调制器(LPM)和高频提示调制器(HPM),分别处理来自不同频段的信号。每个调制器都包含一个生成过程,将提示组件融入提取的频率图中,并且有一个调制部分,用解码器特征的指导来修改提示特征。我们在多个流行数据集上的实验结果表明,在包括去雨、去水滴、去摩尔纹、去模糊和去雾等五个图像修复任务上,FPro方法在与现有最先进方法的比较中表现优异。源代码可在https://github.com/joshyZhou/FPro获取。
关键词:图像修复、频率提示、变换器
1 引言
在恶劣环境下拍摄图像,例如雨天或雾霾,通常会导致低质量图像,进而影响下游任务在实际中的应用。因此,开发一种有效的图像修复方法,将退化的图像恢复为清晰图像,是一项重要的任务。
由于各种深度学习模型的出现,已经取得了显著的进展 [4,5,81],这些基于深度学习的方法已经成为主流,因为它们在性能上超过了传统的基于手工设计先验的方法 [3,21,31,44,84]。
现有的方法,例如 [33,72,81],在多种图像修复任务中取得了令人鼓舞的成果。然而,这些基于学习的方法通常致力于学习退化图像与清晰图像之间的映射函数,而对特定退化的特征考虑较少。例如,雨丝通常会部分遮挡背景,而水滴则通常会导致更明显的局部遮挡。因此,这些模型的表现受限,无法生成更好的修复结果。
最近,基于提示学习的方法 [50,67,68] 为编码特定退化的有用内容提供了另一种方法,能够调节网络,并显著提升图像修复的性能。然而,我们注意到,这些方法 [50,68] 主要关注于挖掘空间相关性来提供退化信息,而对任务特定的频率提示研究较少。实际上,由于各种形式的退化对图像内容的影响各不相同,它们影响来自不同频率带的信息。因此,开发一个高效的提示机制,能够从频率的角度探索有用的提示,以识别不同退化的特定特征,至关重要,这将有助于模型更好地恢复图像的细节和场景的非局部结构。
本文提出了一种频率提示图像修复方法,称为 FPro,通过编码特定退化频率提示来调节网络。如上所述,现有的提示策略 [50,68] 主要关注挖掘空间关系作为有用提示。采用这种方法时,修复图像与真实图像在频率域 [25] 的差异被忽略,从而在空间域留下微妙或无法察觉的伪影。相反,我们的 FPro 旨在利用多尺度分辨率下不同频率带的提示学习能力,从而恢复清晰图像。
我们提出了两种设计来增强 FPro 以实现通用的图像修复:
- 我们首先使用一个门控动态解耦器将输入特征解耦成低频和高频部分,因为不同频带的信号在编码图像模式时代表了不同的视角,即局部细节和全局结构。为此,引入了一个门控机制,通过抑制内核中不太有信息的元素来帮助学习增强的低通滤波器,之后这些滤波器用于生成低频图。与此同时,通过从单位核中减去低通滤波器,获得相应的高通滤波器,从而生成高频图。
- 我们提出了一个双提示块(Dual Prompt Block,DPB),它由两个调制器组成,即低频提示调制器(LPM)和高频提示调制器(HPM),分别处理低频和高频信息。每个调制器包含:(a)一个生成部分,将提示组件融入提取的频率图中,帮助区分特征中的不同元素,例如在去雨任务中区分雨滴模式;(b)一个调制部分,在恢复过程中,通过解码器特征的指导来修改提示特征。在功能上,LPM通过在傅里叶域中的门控机制增强低频特性,然后将提示组件注入,这在计算上高效,且相当于在空间域中的动态大内核深度卷积,然后通过全局交叉注意力编码低频交互。作为补充,HPM应用局部增强的门控机制来获得有用的高频信号,并通过局部交叉注意力编码高频交互。
我们总结了本文的主要贡献如下:
- 我们提出了 FPro,它通过频率分量的提示学习来实现通用的图像修复。与之前的方法不同,我们探索频率图来编码特定的退化信息,作为提示引导图像修复模型,帮助恢复图像的细节和场景的全局结构。
- 我们使用可学习的低通滤波器将输入特征解耦成不同的频率带,并提出了一个双提示块,由低频提示调制器(LPM)和高频提示调制器(HPM)组成,探索细节和结构,从而实现更好的修复效果。
- 在五个修复任务上(去雨、去水滴、去摩尔纹、去模糊和去雾),实验结果表明,FPro 在与现有最先进方法的比较中表现优异。
2 相关工作
图像修复
图像修复任务的目标是从退化的图像中恢复高质量的图像。超越传统的基于先验的方法 [3,21],该领域已经见证了基于学习的多种方法 [34,48,79] 的巨大成功。尽管各种基于卷积神经网络(CNN)架构的方法 [9,35,58] 取得了良好的效果,但这些方法的主要问题在于它们面临基本卷积操作的有限感受野问题。这意味着特征图包含较少的全局上下文(对应图像中的低频特征),最终的预测结果可能会受到这一限制的困扰。这个缺点促使了对能够捕获所需全局线索的组件进行探索,例如注意力机制 [10,45,60],从而可以获得更好的修复性能。例如,MIRNet [82] 提出了一个双重注意力单元,用于在双维度上捕捉上下文信息;NLSN [41] 则采用自注意力机制来收集用于超分辨率的全局相关信息。
基于变换器的修复
近年来,使用变换器架构 [64] 来解决各种计算机视觉任务的理念变得流行。得益于其出色的特征表示能力,变换器不仅在解决高层次视觉任务 [13,14,71] 中获得优势,而且也被扩展到低层次的图像修复任务中 [27,85,88]。不幸的是,由于原始自注意力的复杂度与图像大小呈二次关系,这种机制在处理高分辨率输入时会遭遇相当大的计算成本。为了应对这一问题,一些研究尝试探索更高效的变换器架构 [4,72,87]。例如,SwinIR [33] 引入了基于窗口的自注意力机制以提高效率;Restormer [81] 采用通道级自注意力来降低计算成本。这些工作大多为恢复清晰图像提供了可靠的解决方案,然而,一些研究 [11,49] 意识到自注意力的低通滤波性质,可能会丢失高频信息,如纹理和边缘。尽管这些模型取得了优越的性能,但能够利用的高频细节较少,从而限制了图像修复的更好恢复。
视觉提示学习
提示学习(Prompt Learning),最初出现在自然语言处理(NLP)领域 [1],在其向计算机视觉任务的适配过程中取得了快速的进展 [17,24,26]。与高层次视觉问题不同,部分工作也考虑为低层次管道寻求合适的提示 [40,74,78],以提高效果。
本文的目标并不是为解决“ALL-in-One”问题提供提示(事实上,[32,40,50] 等先前的工作已经通过设计各种退化提示模块很好地解决了这一问题)。然而,我们的方法与近期研究 [67,68] 探索特定退化信息以获得更好的图像修复效果相关。与这些通过预训练模型生成原始退化特征的尝试不同,我们从频率角度为修复模型提供提示。
3 提出的方法
3.1 总体框架
如图 1 所示,本文提出的 FPro 的总体框架包括上层的修复分支,与现有工作 [33,81] 类似,以及下层的提示分支,用于提取有用的频率图并将其调制为提示。
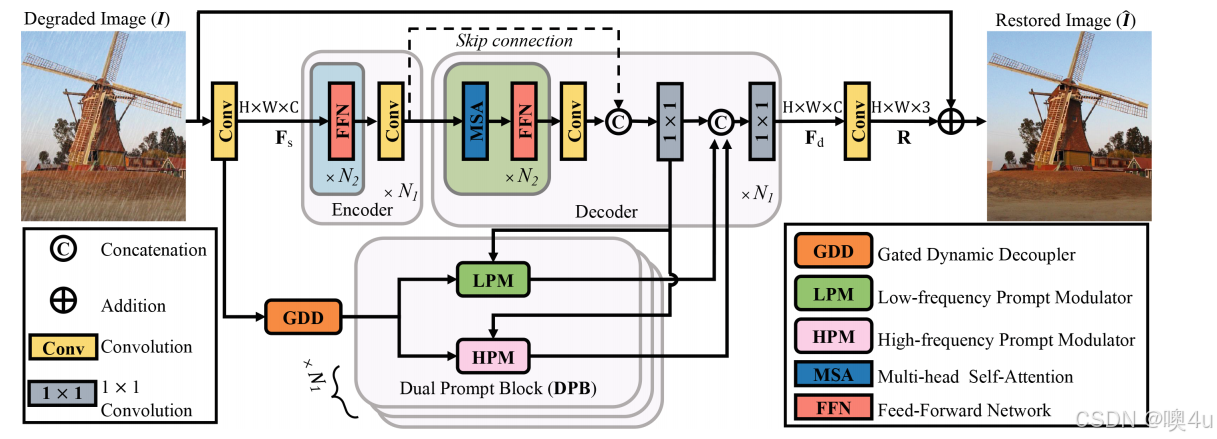
图1. 提出方法 FPro 的概述
除了与现有方法 [33,81] 相似的常见上层修复分支外,FPro 还包含了一个下层提示分支,用于从频率角度提取有用的特征。具体而言,该框架中提示分支的主要组件是门控动态解耦器(GDD)和双重提示模块(DPB)。GDD 用于将输入特征中的低频成分和相应的高频特征解耦。然后,这些特定频率的特征在 DPB 中进一步处理,即高频提示调制器(HPM)和低频提示调制器(LPM),它们生成代表性的频率提示,帮助清晰图像的重建。
修复分支
给定一个退化的图像作为输入,FPro 首先通过卷积层提取浅层特征
,其中
表示空间维度,C 是通道数。接着,浅层特征通过上层的 N1 级编码器-解码器修复分支提取深层特征
。变换器(Transformer)模型中的早期层主要聚焦于聚合局部模式 [76],而自注意力模块(self-attention)作为低通滤波器,容易稀释高频局部细节 [49]。
为了缓解这两个矛盾因素,我们去除了修复分支编码器中的注意力机制。具体而言,编码器的每一层包括 N2 个前馈网络(FFN)[81] 和配对的卷积层进行下采样。编码器提取的特征通过跳跃连接与解码器的特征进行融合,采用 1×1 卷积。对于解码器部分,每一层由 N2 对 FFN 和多头自注意力机制(MSA)[81] 组成,同时还有卷积层用于上采样。最后,使用一个 3×3 的卷积层对深层特征 进行处理,以生成残差图像
。恢复图像
通过以下公式估计:
提示分支
在提示分支中,我们以浅层特征为输入,生成有用的频率提示,这些提示进一步被用来促进潜在清晰图像的重建。为实现这一目标,我们首先使用门控动态解耦(GDD)[见 3.2 节] 将输入特征解耦为不同的频率带。之后,低频和高频图被注入提示组件,以区分根据特定任务所需的有用元素,然后通过 1×1 卷积将其调制为不同的提示(即
和
,与解码器特征进行交互(见 3.3 节)。接下来,我们介绍提示分支的各个模块。
3.2 门控动态解耦器
每种退化类型以不同的方式影响图像内容。例如,雨条部分遮挡背景,而雨滴则通常造成更大的遮挡,分别对应触及高频/低频带。为了解决这些差异,如图 2 所示,我们基于门控和动态学习的滤波器将输入特征解耦为独立的频率部分。关键在于引入门控机制来帮助生成可学习的低通滤波器和相应的高通滤波器,然后分别用于获得低频和高频图。这些滤波器在每个空间位置和通道组上动态学习,以平衡计算负担和特征多样性。
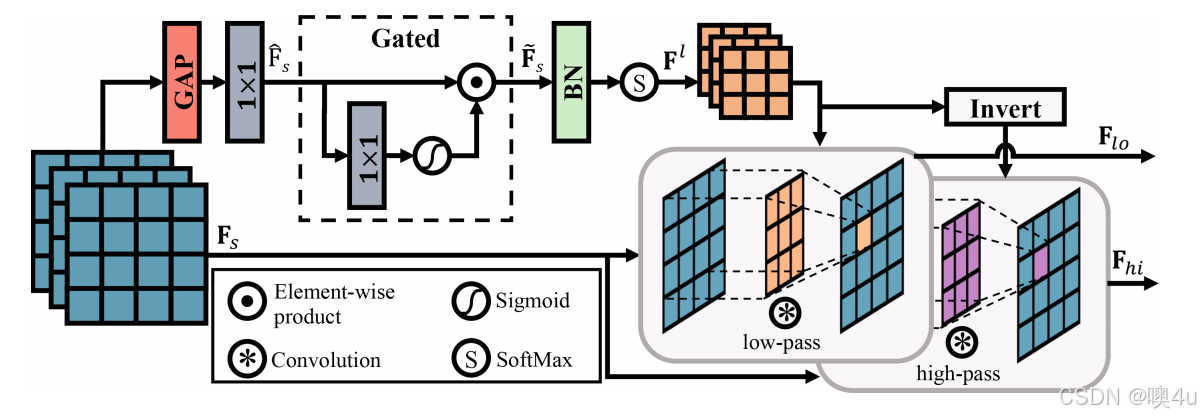
图2. 门控动态解耦器的示意图(此图展示了门控动态解耦器 (GDD) 的工作原理。GDD 将输入特征分解为低频和高频部分,以便更好地捕捉图像中的不同退化特征。在图中,我们可以看到 GDD 通过门控机制生成可学习的低通和高通滤波器,这些滤波器分别用于提取低频和高频成分,从而有助于图像的恢复。)
具体来说,给定输入的浅层特征图 ,我们首先预测每个特征通道组的低通滤波器,可以表示为:
其中,,g 是通道组的数量,
对应学习滤波器的卷积核大小;GAP(·) 和 Conv1×1(·) 分别是全局平均池化层和 1×1 卷积操作;ϕ(⋅) 表示 sigmoid 激活函数,⊙代表逐元素相乘,B(⋅)表示批归一化操作。特别地,Softmax(·) 是 softmax 层,用于确保生成的滤波器为低通滤波器 [89]。
然后,我们将这些学习到的滤波器应用于每个组的输入特征,以获得低频成分:
其中,是重塑后的滤波器,iii 表示组索引,
是组内通道数,c 是通道索引,h 和 w 是空间坐标,p,q∈{−1,0,1} 指示周围的位置。
与此同时,我们通过从单位核中减去低通滤波器来反转这个过程,得到高通滤波器,进而用于生成相应的高频成分 。
3.3 双重提示模块 (Dual Prompt Block)
考虑到提取的特征(即低频/高频特征图)从不同的视角(图像的局部细节和主要结构)编码了图像模式,我们设计了双重提示模块(Dual Prompt Block),该模块包括两个组件:高频提示调制器(HPM)和低频提示调制器(LPM),分别用于处理这些特征图(图3)。
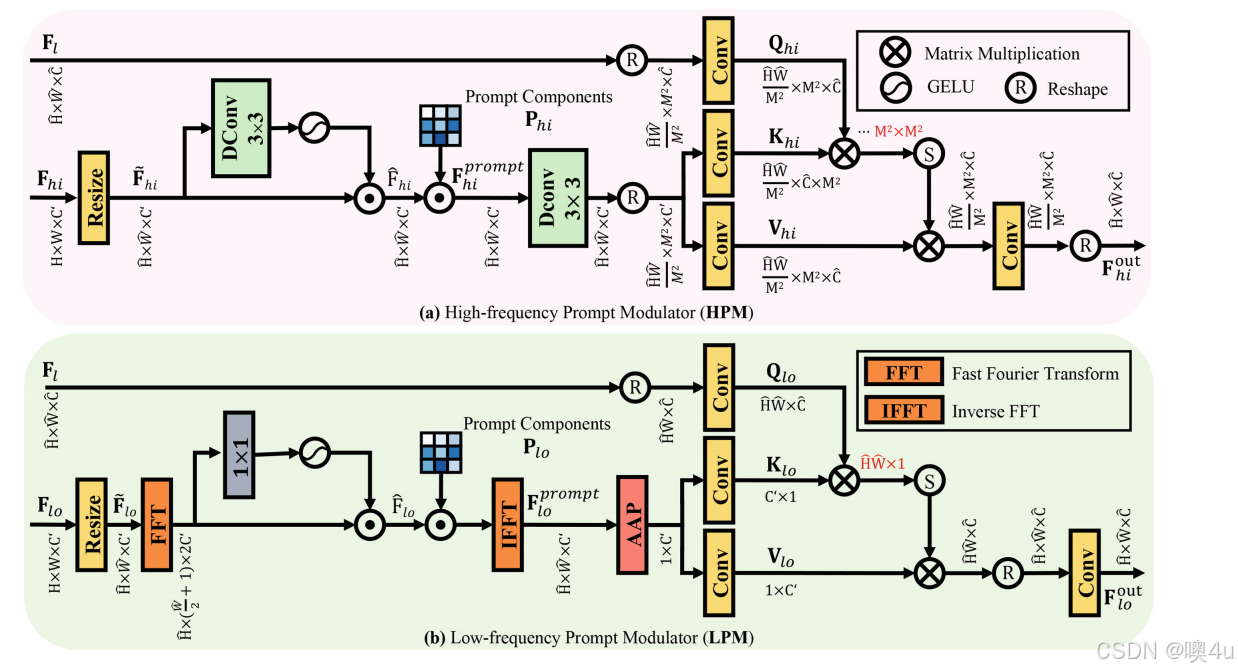
高频提示调制器 (High-Frequency Prompt Modulator)
给定两个输入特征图,包括 l-级特征 和高频特征
,我们首先对
进行尺寸调整,得到
。为了突出高频特征,我们采用门控机制来自适应地确定有用的频率信息:
其中 是处理后的特征,DConv3×3(⋅)表示3×3卷积操作,σ(⋅)\sigma(\cdot)σ(⋅) 是GELU激活函数 [22]。然后,我们利用可学习的高频提示组件
来调整输入特征,这旨在帮助区分不同的元素,例如在去雨任务中的雨纹和不同方向、强度的雨滴:
其中 是获得的高频特征提示。
接下来,我们根据输入特征 对高频提示
进行修改。具体来说,我们利用深度卷积操作,它作为高通滤波器 [49],来增强输入
中的高频信息。然后,我们分别从
生成查询(
)投影、从处理后的特征图
生成键(
)和值(
)投影。同时,由于高频信息通常对应于图像的细节并且是局部特征,计算全局注意力可能是冗余的。因此,在利用线性层获得
、
和
矩阵之前,采用局部窗口自注意力机制,以减少计算复杂度并捕获细粒度的高频信息,得出:
其中表示投影矩阵,R(⋅)表示窗口分割策略 [39]。通常,我们有:
其中 是分割窗口的大小。然后,计算注意力矩阵来调节高频提示:
其中 是高频提示调制分支的输出特征图;d 是查询/键维度 [33]。
低频提示调制器 (Low-Frequency Prompt Modulator)
给定两个输入特征图,包括 l-级特征和低频特征
,我们首先调整
的尺寸,得到
。为了有效处理低频信号,我们通过快速傅里叶变换(FFT)将
投影到频域。然后,采用门控机制来控制有用的低频成分向前传播:
其中 是处理后的特征,F(⋅) 表示傅里叶变换。
接下来,我们通过注入可学习的低频提示组件 来校准输入特征,并将其转换回空间域:
其中 是生成的低频特征提示,
表示逆傅里叶变换。
值得注意的是,我们在傅里叶域内进行特征变换,以便高效地进行全局信息交互。卷积定理 [46, 55] 表明,傅里叶域中两个信号的Hadamard积等于它们在原始空间域中的卷积的傅里叶变换。基于这一原理,我们可以将式 (6) 和式 (7) 结合起来:
其中,“”表示卷积操作。由于
是一个与
形状相同的张量,因此它可以作为一个动态深度卷积核,大小与
相同,同时引入较少的模型复杂度。
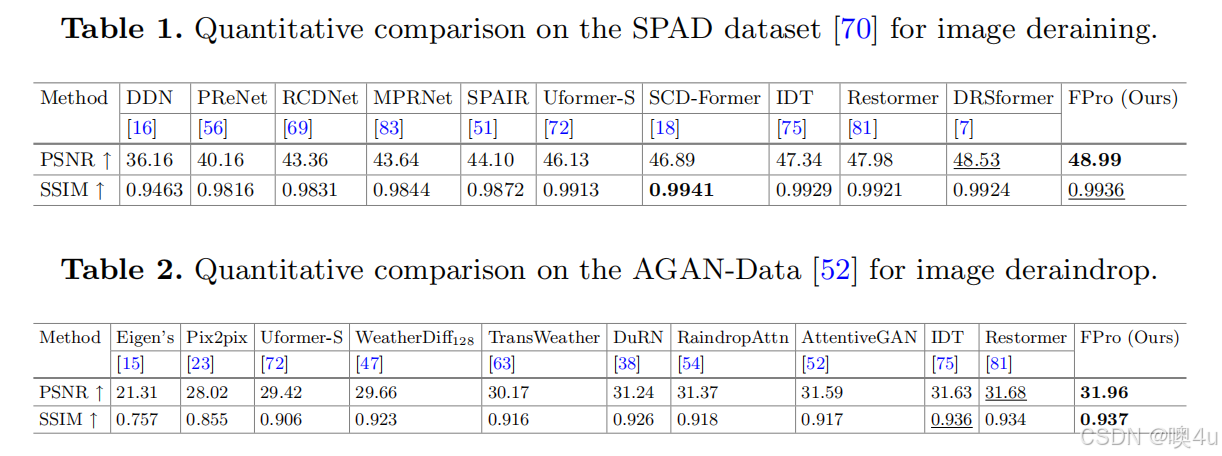
- 表1:在SPAD数据集 [70] 上的图像去雨定量比较。
- 表2:在AGAN-Data [52] 上的图像去雨滴定量比较。
接下来,我们进一步通过输入特征的指导来调节低频视觉提示
。具体而言,我们采用自适应平均池化算子,该算子作为低通滤波器 [65],用来增强输入
中的低频内容。之后,我们从重塑后的
生成查询(
)投影,从经过平均池化的特征
生成键(
)和值(
)投影。这里,AAP(·) 表示自适应平均池化操作。接着,我们使用 1×1 卷积来生成
,以及
。其中,
表示 1×1 卷积。接下来,我们计算查询和键投影的点积,从而生成转置注意力矩阵
。
总体而言,调节低频提示的过程定义为:
其中,是低频提示调节分支的输出特征图;
,和
是输入矩阵;α 是可学习的缩放参数。
对于低频和高频调节器,我们并行计算注意力图,并将这些结果进行拼接,最终用于多头自注意力(MSA)[64]。
4 实验
4.1 实验设置
评估指标。我们采用常用的峰值信噪比(PSNR)[73]和结构相似度(SSIM)指标来评估恢复后的图像。同时,采用感知指标 NIQE [42] 作为无参考指标。根据之前的工作 [69,72],对于图像去雨任务,PSNR/SSIM 的计算是在 YCbCr 空间的 Y 通道上进行的,而对于其他恢复任务,则在 RGB 颜色空间中计算。在报告的表格中,最佳和第二佳的得分分别用粗体和下划线标记。
实现细节。FPro 包含 层的编码器-解码器结构,其中编码器和解码器共享相同的
个块。我们将嵌入维度 C 设置为 48,注意力头的数量为 [2, 4, 8]。FFN 中的扩展通道容量因子为 3。HPM 中的默认分割窗口大小设置为M=8。在下采样和上采样中使用了像素反混合(pixel-unshuffle)和像素混合(pixel-shuffle)。我们使用 AdamW 优化器,初始学习率为
,并通过余弦退火将学习率逐步降低至
,来训练 FPro。此外,我们采用广泛使用的损失函数 [68] 来约束网络训练。
4.2 主要结果
雨滴条纹去除
我们将所提出的 FPro 与一般的图像恢复方法 [51,72,81,83] 以及任务特定的方法 [7,16,18,56,69,75] 进行了比较。表1 显示了 FPro 在 SPAD 数据集 [70] 上的真实图像去雨效果超越了现有的方法。与之前最好的方法 DRSformer [7] 相比,FPro 提高了 0.46 dB 的性能。此外,FPro 相比于最近的模型 SCDFormer [18] 提高了 2.1 dB 的 PSNR。图4 提供了一个视觉去雨的示例,其中 FPro 成功地去除了雨水的影响,同时保持了图像的结构信息。
- 图4. 在 SPAD 数据集 [70] 上进行的真实图像去雨的定性比较。
雨滴去除
对于图像去雨滴任务,我们将 FPro 与一些现有的去雨滴方法进行比较,包括 Eigen’s [15]、Pix2pix [23]、TransWeather [63]、Uformer [72]、WeatherDiff128 [47]、DuRN [38]、RaindropAttn [54]、AttentiveGAN [52]、IDT [75] 和 Restormer [81]。我们在 AGAN-Data [52] 数据集上报告了定量结果,如表2 所示。FPro 在所有考虑的方法中,在 PSNR 和 SSIM 分数上都取得了最佳表现。FPro 相较于 Restormer [81] 提高了 0.28 dB 的 PSNR,相较于最近的方法 WeatherDiff128 [47] 提高了 2.3 dB。图5 展示了视觉比较,FPro 生成了一个更加细致的结果。
- 图5. 在 AGAN-Data 数据集 [52] 上进行的图像去雨滴的定性比较。
摩尔纹去除
我们在 TIP-2018 [61] 数据集上进行了图像去摩尔纹的实验,并将 FPro 与十种去摩尔纹的方法进行比较,包括 AMNet [80]、DMCNN [61]、UNet [59]、WDNet [36]、MopNet [19]、TAPE-Net [37]、FHD2eNet [20]、MBCNN [86]、Uformer-S [72] 和 Wang 等人 [66]。在表3中,FPro 比之前最好的方法 Wang 等人 [66] 提高了 0.38 dB 的性能,相较于最近的模型 TAPE-Net [37] 提高了 1.73 dB。
去雾
我们在 SOTS [29] 基准数据集上进行了图像去雾实验,并将 FPro 与八种代表性方法进行比较,包括 AOD-Net [28]、MSCNN [57]、DehazeNet [2]、EPDN [53]、FDGAN [12]、AirNet [30]、Restormer [81] 和 PromptIR [50]。如表4所示,FPro 在所有考虑的方法中取得了最佳分数。与最近的基于提示的方法 PromptIR [50] 相比,FPro 提高了 1.54 dB 的性能。
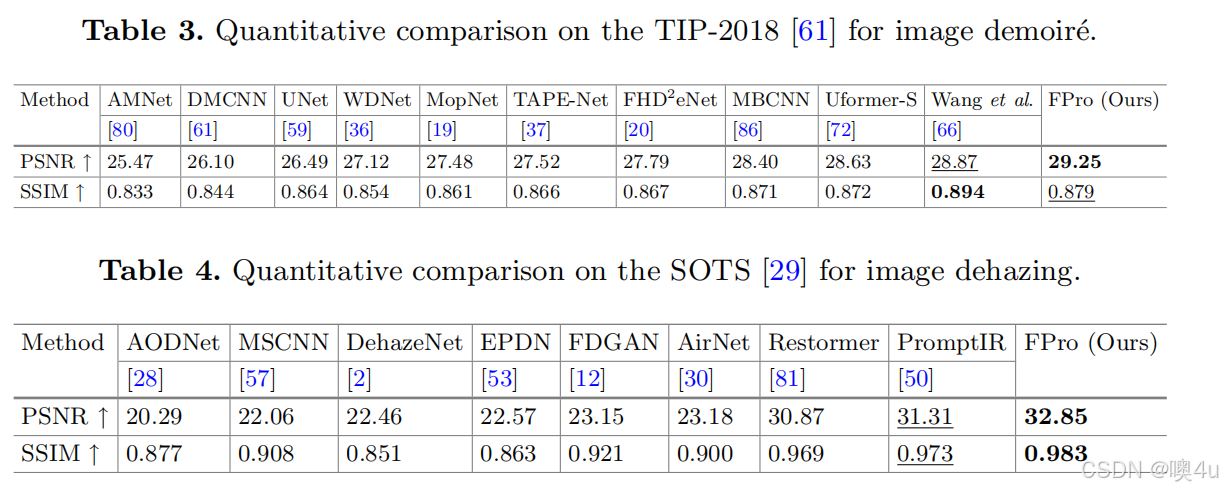
- 表3. 在 TIP-2018 数据集 [61] 上进行的图像去摩尔纹的定量比较。
- 表4. 在 SOTS 数据集 [29] 上进行的图像去雾的定量比较。
运动模糊去除
我们在 GoPro 数据集 [43] 上评估了图像去模糊的性能。对于合成去模糊,我们将 FPro 与八种代表性模型进行了比较:CODE [85]、IPT [4]、MPRNet [83]、MIMO [9]、HINet [6]、MAXIM [62]、Restormer [81] 和 PromptRestorer [68]。表5 显示,我们的 FPro 相较于最近的基于提示的方法 PromptRestorer [68] 实现了具有竞争力的性能,并且计算量只有其一半。与此同时,与最近的方法 CODE [85] 相比,FPro 在 PSNR 上提高了 1.11 dB,并且使用了更少的 FLOP。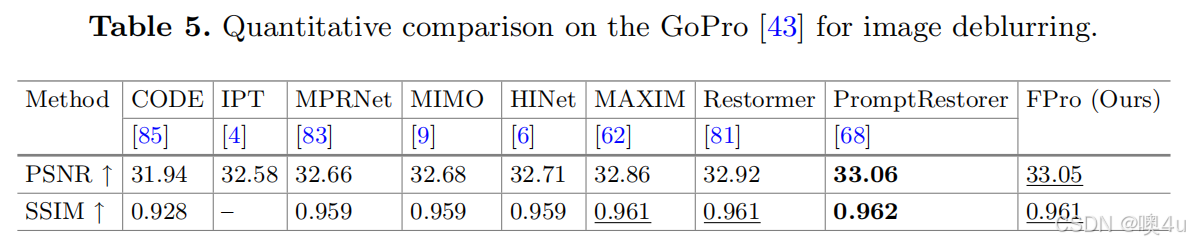
- 表5. 在 GoPro 数据集 [43] 上进行的图像去模糊的定量比较。
4.3 分析与讨论
在消融研究中,我们研究了在 SPAD [70] 上进行雨条去除的不同模型,使用 256×256 的图像块进行 300K 次迭代。测试在 SPAD 测试数据集 [70] 上进行。
Gated Dynamic Decoupler 的有效性
为了验证 Gated Dynamic Decoupler(GDD)的有效性,我们在表 6 中进行不同模型变体的实验。与使用多重动态卷积 [8](DC)来分离不同频率部分的模型(b)相比,直接用 GDD 替换它(c)在 PSNR 方面带来了 0.39 dB 的性能提升。同时,我们尝试用共享一个 GDD 模块来分离低频和高频信息(d),这样稍微降低了整体框架的复杂性(0.02 M),并带来了 0.08 dB 的性能提升。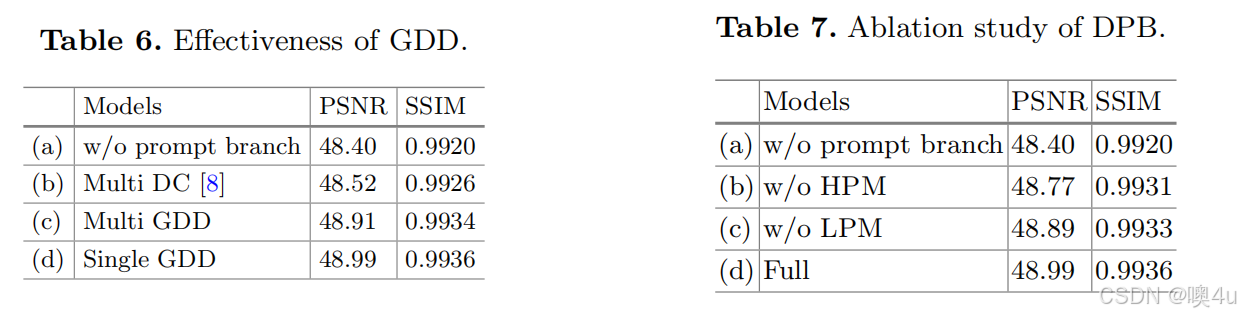
- 表 6. GDD 的有效性
- 表 7. DPB 的消融研究
Dual Prompt Block 的有效性
为了研究开发的 DPB,在表 7 中进行了消融研究。禁用 HPM 或 LPM 分别导致 0.22 dB 和 0.1 dB 的明显下降。这些实验结果表明,HPM 和 LPM 都在恢复高质量图像中发挥了积极作用。此外,我们通过可视化展示了 DPB 的效果。如图 7 所示,我们可视化了来自每个分支的低频/高频特征图,并进行傅里叶域分析,其中低频提示特征编码了诸如结构之类的信息,而高频提示特征则专注于边缘和纹理等信息。同时,我们在图 8 中提供了可视化比较,以展示所提出的 HPM/LPM 的有效性。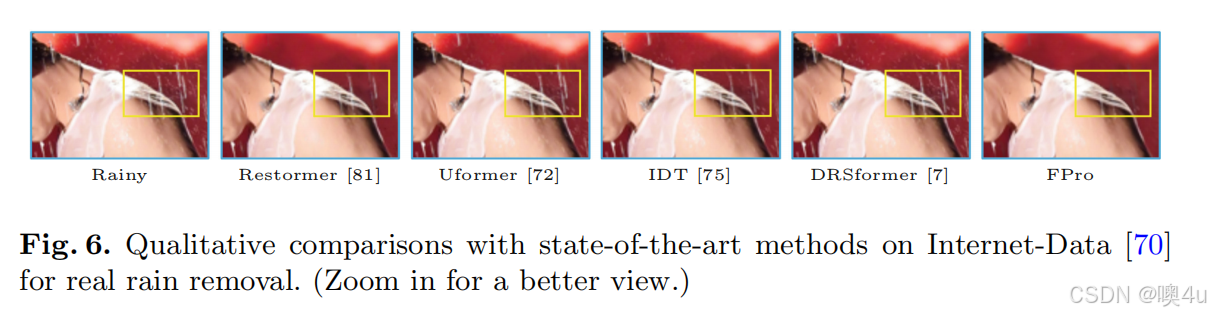

- 图 6. 与最先进方法的定性比较,基于 Internet-Data [70] 进行真实雨水去除。(放大以获得更清晰的视图。)
- 图 7. 特征分析。 我们可视化了来自 LPM 分支的特征(a),以及来自 HPM 分支的特征(b)。在右下角,我们展示了在傅里叶域中沿通道维度平均特征的结果。(放大以获得更清晰的视图。)
- 图 8. DPB 的效果。 第 1 列和第 3 列显示了低通和高通滤波后的结果,而第 2 列和第 4 列显示了经过处理结果与相应滤波后的真实标签之间的差异(Diff.)。与(a)相比,FPro w/ LPM(e)在捕捉诸如结构等信息方面表现更好,从而减少了错误预测(f)。与(c)相比,FPro w/ HPM(g)恢复了清晰的边缘和形状,这表明它受益于高频信息提示。(放大以获得更清晰的视图。)
感知质量评估
为了测试所提出的 FPro 的感知质量,按照 [7] 的方法,我们随机选择了 20 张来自 Internet-Data [70] 的真实场景下的雨天图像进行评估。如表 10 所示,与其他考虑的方法相比,FPro 获得了更低的 NIQE 分数,这意味着生成的结果包含更清晰的内容和更好的感知质量。通过图 6 中的定性比较,FPro 在视觉上优于其他模型,表明它能够很好地处理未见过的退化情况。
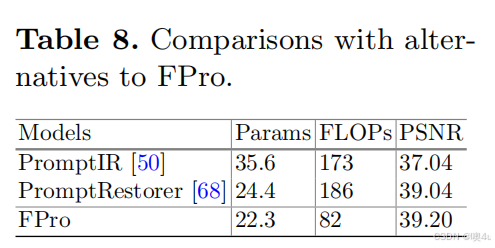
- 表 8. 与 FPro 替代方法的比较
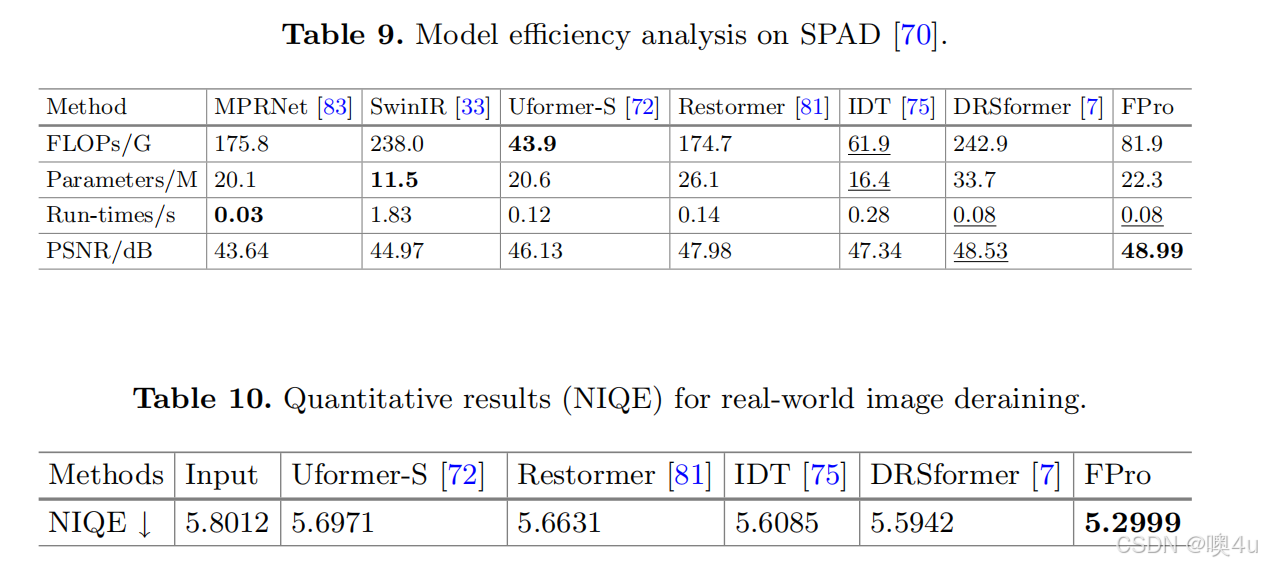
- 表 9. 在 SPAD [70] 上的模型效率分析
- 表 10. 真实世界图像去雨的定量结果(NIQE)
模型效率
我们提供了图像去雨任务中性能(PSNR)、复杂度(FLOPs 和参数量)以及延迟(运行时间)的比较。FLOPs 和运行时间是在输入图像大小为 256×256 时测量的,PSNR 分数是在 SPAD [70] 上测试的。如表 9 所示,尽管 FPro 在 PSNR 指标上取得了更好的性能,但其模型复杂度比 Restormer [81] 和 DRSformer [7] 更低。与其他 CNN-/Transformer 基础的方法相比,FPro 的模型复杂度仍然较低或相当。
与 FPro 的替代方法比较
为了进一步证明 FPro 的优越性,我们将其与最近的基于提示的方法进行比较,这些方法通过挖掘空间关系作为提示,包括 PromptIR [50] 和 PromptRestorer [68]。如表 8 所示,按照 PromptIR [50] 的方法,我们在 Rain100L [77] 数据集上训练并验证了 FPro。我们相较于 PromptIR 提高了 2.16 dB 的性能,并且比 PromptRestorer 提高了 0.16 dB 的性能。
5 结论
在这项工作中,我们从频率角度探索了提示学习在图像恢复任务中的优势。首先,通过使用门控机制对输入特征进行动态解耦以选择代表性元素,我们获得了与特定退化去除任务相关的频率成分。然后,我们提出通过独立分支对低频/高频信号进行调制,关注来自不同频带的特征图的内在特性。通过这些模块,我们提出的 FPro 在多个图像恢复任务中超越了之前的最先进方法,同时在计算成本方面也表现得具有竞争力。
- 图 9. 显示了错误重建的示例,其中夜间真实场景中的严重退化导致 FPro 的典型失败。
局限性
仍然有许多改进的方向。例如,通过解决图 9 所示的失败案例,FPro 在处理夜间真实场景中的严重退化时遇到了挑战。从直觉上讲,收集大规模的真实世界数据集是改进的潜在方向。
致谢
本工作得到了中国天津市自然科学基金(项目号:20JCJQJC00020)、中国国家自然科学基金(项目号:U22B2049,62302240)、中央高校基础研究基金以及南开大学超级计算中心(NKSC)的支持。
References
- Brown, T.B., et al.: Language models are few-shot learners. In: NeurIPS (2020)
- Cai, B., Xu, X., Jia, K., Qing, C., Tao, D.: Dehazenet: an end-to-end system for single image haze removal. TIP 25, 5187–5198 (2016)
- Chantas, G., Galatsanos, N.P., Molina, R., Katsaggelos, A.K.: Variational bayesian image restoration with a product of spatially weighted total variation image priors. TIP 19, 351–362 (2009)
- Chen, H., et al.: Pre-trained image processing transformer. In: CVPR (2021)
- Chen, L., Chu, X., Zhang, X., Sun, J.: Simple baselines for image restoration. In: ECCV 2022, pp. 17–33. Springer, Heidelberg (2022). https://doi.org/10.1007/978-3-031-20071-7_2
- Chen, L., Lu, X., Zhang, J., Chu, X., Chen, C.: Hinet: half instance normalization network for image restoration. In: CVPR Workshops (2021)
- Chen, X., Li, H., Li, M., Pan, J.: Learning a sparse transformer network for effective image deraining. In: CVPR (2023)
- Chen, Y., Dai, X., Liu, M., Chen, D., Yuan, L., Liu, Z.: Dynamic convolution: attention over convolution kernels. In: CVPR (2020)
- Cho, S.J., Ji, S.W., Hong, J.P., Jung, S.W., Ko, S.J.: Rethinking coarse-to-fine approach in single image deblurring. In: ICCV (2021)
- Deng, X., Dragotti, P.L.: Deep convolutional neural network for multi-modal image restoration and fusion. TPAMI 43, 3333–3348 (2021)
- Dong, J., Pan, J., Yang, Z., Tang, J.: Multi-scale residual low-pass filter network for image deblurring. In: ICCV (2023)
- Dong, Y., Liu, Y., Zhang, H., Chen, S., Qiao, Y.: Fd-gan: generative adversarial networks with fusion-discriminator for single image dehazing. In: AAAI (2020)
- Dosovitskiy, A., et al.: An image is worth 16×16 words: transformers for image recognition at scale. In: ICLR (2021)
- d’Ascoli, S., Touvron, H., Leavitt, M.L., Morcos, A.S., Biroli, G., Sagun, L.: Convit: improving vision transformers with soft convolutional inductive biases. In: ICML (2021)
- Eigen, D., Krishnan, D., Fergus, R.: Restoring an image taken through a window covered with dirt or rain. In: ICCV (2013)
- Fu, X., Huang, J., Zeng, D., Huang, Y., Ding, X., Paisley, J.: Removing rain from single images via a deep detail network. In: CVPR (2017)
- Gan, Y., et al.: Decorate the newcomers: visual domain prompt for continual test time adaptation. In: AAAI (2023)
- Guo, Y., Xiao, X., Chang, Y., Deng, S., Yan, L.: From sky to the ground: a large-scale benchmark and simple baseline towards real rain removal. In: ICCV (2023)
- He, B., Wang, C., Shi, B., Duan, L.: Mop moiré patterns using mopnet. In: ICCV (2019)
- He, B., Wang, C., Shi, B., Duan, L.-Y.: Fhde2net: full high definition demoireing network. In: Vedaldi, A., Bischof, H., Brox, T., Frahm, J.-M. (eds.) ECCV 2020. LNCS, vol. 12367, pp. 713–729. Springer, Cham (2020). https://doi.org/10.1007/978-3-030-58542-6_43
- He, K., Sun, J., Tang, X.: Single image haze removal using dark channel prior. TPAMI 33, 2341–2353 (2010)
- Hendrycks, D., Gimpel, K.: Gaussian error linear units (gelus). arXiv preprint arXiv:1606.08415 (2016)
- Isola, P., Zhu, J.Y., Zhou, T., Efros, A.A.: Image-to-image translation with conditional adversarial networks. In: CVPR (2017)
- Jia, M., et al.: Visual prompt tuning. In: ECCV 2022, pp. 709–727. Springer, Heidelberg (2022). Computer Vision – ECCV 2022: 17th European Conference, Tel Aviv, Israel, October 23–27, 2022, Proceedings, Part XXXIII | SpringerLink
- Jiang, L., Dai, B., Wu, W., Loy, C.C.: Focal frequency loss for image reconstruction and synthesis. In: CVPR (2021)
- Khattak, M.U., Rasheed, H., Maaz, M., Khan, S., Khan, F.S.: Maple: multi-modal prompt learning. In: CVPR (2023)
- Kong, L., Dong, J., Ge, J., Li, M., Pan, J.: Efficient frequency domain-based transformers for high-quality image deblurring. In: CVPR (2023)
- Li, B., Peng, X., Wang, Z., Xu, J., Feng, D.: Aod-net: all-in-one dehazing network. In: ICCV (2017)
- Li, B., et al.: Benchmarking single-image dehazing and beyond. TIP 28, 492–505 (2018)
- Li, B., Liu, X., Hu, P., Wu, Z., Lv, J., Peng, X.: All-in-one image restoration for unknown corruption. In: CVPR (2022)
- Li, Y., Tan, R.T., Guo, X., Lu, J., Brown, M.S.: Rain streak removal using layer priors. In: CVPR (2016)
- Li, Z., Lei, Y., Ma, C., Zhang, J., Shan, H.: Prompt-in-prompt learning for universal image restoration. arXiv preprint arXiv:2312.05038 (2023)
- Liang, J., Cao, J., Sun, G., Zhang, K., Van Gool, L., Timofte, R.: Swinir: image restoration using swin transformer. In: ICCV Workshops (2021)
- Liu, D., Wen, B., Fan, Y., Loy, C.C., Huang, T.S.: Non-local recurrent network for image restoration. In: NeurIPS (2018)
- Liu, J., Yan, M., Zeng, T.: Surface-aware blind image deblurring. TPAMI 43, 1041–1055 (2021)
- Liu, L., et al.: Wavelet-based dual-branch network for image demoiréing. In: Vedaldi, A., Bischof, H., Brox, T., Frahm, J.-M. (eds.) ECCV 2020. LNCS, vol. 12358, pp. 86–102. Springer, Cham (2020). https://doi.org/10.1007/978-3-030-58601-0_6
- Liu, L., et al.: Tape: task-agnostic prior embedding for image restoration. In: ECCV 2022, pp. 447–464. Springer, Heidelberg (2022). https://doi.org/10.1007/978-3-031-19797-0_26
- Liu, X., Suganuma, M., Sun, Z., Okatani, T.: Dual residual networks leveraging the potential of paired operations for image restoration. In: CVPR (2019)
- Liu, Z., et al.: Swin transformer: hierarchical vision transformer using shifted windows. In: ICCV (2021)
- Ma, J., Cheng, T., Wang, G., Zhang, Q., Wang, X., Zhang, L.: Prores: exploring degradation-aware visual prompt for universal image restoration. arXiv preprint arXiv:2306.13653 (2023)
- Mei, Y., Fan, Y., Zhou, Y.: Image super-resolution with non-local sparse attention. In: CVPR (2021)
- Mittal, A., Soundararajan, R., Bovik, A.C.: Making a “completely blind” image quality analyzer. IEEE SPL 20, 209–212 (2012)
- Nah, S., Hyun Kim, T., Mu Lee, K.: Deep multi-scale convolutional neural network for dynamic scene deblurring. In: CVPR (2017)
- Narasimhan, S.G., Nayar, S.K.: Contrast restoration of weather degraded images. TPAMI 25, 713–724 (2003)
- Niu, B., et al.: Single image super-resolution via a holistic attention network. In: Vedaldi, A., Bischof, H., Brox, T., Frahm, J.-M. (eds.) ECCV 2020. LNCS, vol. 12357, pp. 191–207. Springer, Cham (2020). https://link.springer.com/chapter/10.1007/978-3-030-58610-2_12
- Oppenheim, A.: Discrete-Time Signal Processing. Prentice-Hall, Upper Saddle River (1999)
- Ozdenizci, O., Legenstein, R.: Restoring vision in adverse weather conditions with patch-based denoising diffusion models. TPAMI 45, 10346–10357 (2023)
- Pan, X., Zhan, X., Dai, B., Lin, D., Loy, C.C., Luo, P.: Exploiting deep generative prior for versatile image restoration and manipulation. TPAMI 44, 7474–7489 (2022)
- Park, N., Kim, S.: How do vision transformers work? In: ICLR (2022)
- Potlapalli, V., Zamir, S.W., Khan, S., Khan, F.S.: Promptir: prompting for all-in-one blind image restoration. In: NeurIPS (2023)
- Purohit, K., Suin, M., Rajagopalan, A., Boddeti, V.N.: Spatially-adaptive image restoration using distortion-guided networks. In: ICCV (2021)
- Qian, R., Tan, R.T., Yang, W., Su, J., Liu, J.: Attentive generative adversarial network for raindrop removal from a single image. In: CVPR (2018)
- Qu, Y., Chen, Y., Huang, J., Xie, Y.: Enhanced pix2pix dehazing network. In: CVPR (2019)
- Quan, Y., Deng, S., Chen, Y., Ji, H.: Deep learning for seeing through window with raindrops. In: ICCV (2019)
- Rabiner, L.R., Gold, B.: Theory and Application of Digital Signal Processing. Prentice-Hall, Englewood Cliffs (1975)
- Ren, D., Zuo, W., Hu, Q., Zhu, P., Meng, D.: Progressive image deraining networks: a better and simpler baseline. In: CVPR (2019)
- Ren, W., et al.: Single image dehazing via multi-scale convolutional neural networks. In: Leibe, B., Matas, J., Sebe, N., Welling, M. (eds.) ECCV 2016. LNCS, vol. 9906, pp. 154–169. Springer, Cham (2016). https://link.springer.com/chapter/10.1007/978-3-319-46475-6_10
- Ren, W., et al.: Deblurring dynamic scenes via spatially varying recurrent neural networks. TPAMI 44, 3974–3987 (2022)
- Ronneberger, O., Fischer, P., Brox, T.: U-net: convolutional networks for biomedical image segmentation. In: Navab, N., Hornegger, J., Wells, W.M., Frangi, A.F. (eds.) MICCAI 2015. LNCS, vol. 9351, pp. 234–241. Springer, Cham (2015).https://doi.org/10.1007/978-3-319-24574-4_28
- Song, X., et al.: Tusr-net: triple unfolding single image dehazing with self-regularization and dual feature to pixel attention. TIP 32, 1231–1244 (2023)
- Sun, Y., Yu, Y., Wang, W.: Moiré photo restoration using multiresolution convolutional neural networks. TIP 27, 4160–4178 (2018)
- Tu, Z., et al.: Maxim: multi-axis mlp for image processing. In: CVPR (2022)
- Valanarasu, J.M.J., Yasarla, R., Patel, V.M.: Transweather: transformer-based restoration of images degraded by adverse weather conditions. In: CVPR (2022)
- Vaswani, A., et al.: Attention is all you need. In: NeurIPS (2017)
- Voigtman, E., Winefordner, J.D.: Low-pass filters for signal averaging. Rev. Sci. Inst. 57, 957–966 (1986)
- Wang, C., He, B., Wu, S., Wan, R., Shi, B., Duan, L.Y.: Coarse-to-fine disentangling demoiréing framework for recaptured screen images. TPAMI 45, 9439–9453 (2023)
- Wang, C., Pan, J., Lin, W., Dong, J., Wu, X.M.: Selfpromer: self-prompt dehazing transformers with depth-consistency. arXiv preprint arXiv:2303.07033 (2023)
- Wang, C., et al.: Promptrestorer: a prompting image restoration method with degradation perception. In: NeurIPS (2023)
- Wang, H., Xie, Q., Zhao, Q., Meng, D.: A model-driven deep neural network for single image rain removal. In: CVPR (2020)
- Wang, T., Yang, X., Xu, K., Chen, S., Zhang, Q., Lau, R.W.: Spatial attentive single-image deraining with a high quality real rain dataset. In: CVPR (2019)
- Wang, W., et al.: Pyramid vision transformer: a versatile backbone for dense prediction without convolutions. In: ICCV (2021)
- Wang, Z., Cun, X., Bao, J., Zhou, W., Liu, J., Li, H.: Uformer: a general u-shaped transformer for image restoration. In: CVPR (2022)
- Wang, Z., Bovik, A.C., Sheikh, H.R., Simoncelli, E.P.: Image quality assessment: from error visibility to structural similarity. TIP 13, 600–612 (2004)
- Wu, R., Yang, T., Sun, L., Zhang, Z., Li, S., Zhang, L.: Seesr: towards semantics-aware real-world image super-resolution. arXiv preprint arXiv:2311.16518 (2023)
- Xiao, J., Fu, X., Liu, A., Wu, F., Zha, Z.J.: Image de-raining transformer. TPAMI 45, 12978–12995 (2022)
- Xiao, T., Singh, M., Mintun, E., Darrell, T., Dollar, P., Girshick, R.: Early convolutions help transformers see better. In: NeurIPS (2021)
- Yang, W., Tan, R.T., Feng, J., Guo, Z., Yan, S., Liu, J.: Joint rain detection and removal from a single image with contextualized deep networks. TPAMI 42, 1377–1393 (2019)
- Yu, F., et al.: Scaling up to excellence: practicing model scaling for photo-realistic image restoration in the wild. arXiv preprint arXiv:2401.13627 (2024)
- Yu, K., Wang, X., Dong, C., Tang, X., Loy, C.C.: Path-restore: learning network path selection for image restoration. TPAMI 44, 7078–7092 (2022)
- Yue, H., Mao, Y., Liang, L., Xu, H., Hou, C., Yang, J.: Recaptured screen image demoiréing. TCSVT (2021)
- Zamir, S.W., Arora, A., Khan, S., Hayat, M., Khan, F.S., Yang, M.H.: Restormer: efficient transformer for high-resolution image restoration. In: CVPR (2022)
- Zamir, S.W., Arora, A., Khan, S., Hayat, M., Khan, F.S., Yang, M.-H., Shao, L.: Learning enriched features for real image restoration and enhancement. In: Vedaldi, A., Bischof, H., Brox, T., Frahm, J.-M. (eds.) ECCV 2020. LNCS, vol. 12370, pp. 492–511. Springer, Cham (2020).https://doi.org/10.1007/978-3-030-58595-2_30
- Zamir, S.W., et al.: Multi-stage progressive image restoration. In: CVPR (2021)
- Zhang, K., Li, Y., Zuo, W., Zhang, L., Van Gool, L., Timofte, R.: Plug-and-play image restoration with deep denoiser prior. TPAMI 44, 6360–6376 (2021)
- Zhao, H., Gou, Y., Li, B., Peng, D., Lv, J., Peng, X.: Comprehensive and delicate: an efficient transformer for image restoration. In: CVPR (2023)
- Zheng, B., Yuan, S., Slabaugh, G., Leonardis, A.: Image demoireing with learnable bandpass filters. In: CVPR (2020)
- Zheng, C., Zhang, Y., Gu, J., Zhang, Y., Kong, L., Yuan, X.: Cross aggregation transformer for image restoration. In: NeurIPS (2022)
- Zhou, S., Chen, D., Pan, J., Shi, J., Yang, J.: Adapt or perish: adaptive sparse transformer with attentive feature refinement for image restoration. In: CVPR (2024)
- Zou, X., Xiao, F., Yu, Z., Li, Y., Lee, Y.J.: Delving deeper into anti-aliasing in convnets. IJCV 131, 67–81 (2023)
研讨报告
1. 绪论
问题概述:
图像修复是计算机视觉中的一个重要任务,特别是在恶劣环境下拍摄的图像修复,如雨天、雾霾或水滴等干扰条件下拍摄的图像。这些图像通常会严重失真,导致图像的质量较低,影响后续图像处理和分析的效果。图像修复的目标是从退化的图像中恢复出清晰的图像,特别是在图像质量受到多种因素影响时(例如雨水、雾霾等),修复过程往往面临巨大的挑战。
研究意义:
随着深度学习特别是卷积神经网络(CNN)和变换器(Transformer)模型的兴起,图像修复技术已经取得了显著的进展。然而,现有的图像修复方法通常依赖于空间上的关系(如像素邻域信息),而忽视了不同频率特征的重要性。不同频率成分对图像的局部细节和全局结构有不同的影响,忽略频率成分的处理可能导致图像修复中细节丢失,或者产生伪影。因此,开发一种新的图像修复方法,能够从频率域提供额外的信息引导,是提升图像修复效果的一个关键方向。
邻域是在一定意义下,在空间域中,与该像素相邻的像素的集合。将图像信息转换为频率信息,使得在频率域中可以更方便地进行滤波、降噪、压缩等操作。因此,频率域修改图像能够在保持或增强图像质量的同时,降低处理难度和计算量。
- 频域中的信息描述了图像的变化模式,而不是图像的具体像素值。通过傅里叶变换,图像被分解成不同频率的“波”,每个频率成分的强度(幅度)和位置(相位)可以表示图像的细节和整体特征。
- 幅度信息:表示频率分量的强度。幅度较大的频率分量对图像的整体外观贡献较大。通过修改幅度,可以影响图像的对比度和亮度。在空间域中,振幅可以理解为像素的亮度或强度。
- 相位信息:表示频率分量的位置。相位信息对于图像的结构和位置非常重要。如果只保留图像的相位信息而忽略幅度信息,仍然可以看出图像的结构轮廓,这表明相位在图像重构中具有重要作用。空间域的相位决定了图像的结构和布局。
- 低频信息:表示图像的主要轮廓、背景或大面积的色调变化,通常对图像的整体结构贡献最大。
- 高频信息:表示图像的细节、纹理、边缘等,这些部分通常在图像中变化较快,是图像的细节信息来源。
- 在频率域中,高频低频分量被分开展示:如,通过傅里叶变换,低频成分靠近频谱中心,高频成分分布在边缘,能够很容易地对不同频率成分进行处理。
- 图像滤波的卷积运算在空间域中计算量较大,但根据卷积定理,卷积在频率域可以转化为简单的乘法。傅里叶变换将卷积操作简化为频率域中的乘法,再通过反傅里叶变换返回空间域。
- 这些滤波器在频率域中具有明确的频率范围,可以更精确地控制图像的某些频率分量,而不影响其他部分。这种精确的控制在空间域较难实现。
论文的贡献:
本文提出了一种频率提示引导的图像修复方法——FPro。通过引入频率分量的提示,FPro能够更有效地恢复图像的细节和全局结构。该方法通过动态学习的低通和高通滤波器解耦图像的低频和高频特征,并使用频率提示调制器(LPM和HPM)来增强图像修复的效果。实验结果表明,FPro在多个图像修复任务中表现优异,优于现有的主流方法。
2. 现有相关工作
图像修复任务的目标是从退化的图像中恢复高质量的图像,该领域已有大量研究,主要可以分为两类方法:传统基于先验的方法和基于深度学习的方法。
一.传统图像修复方法:
早期的图像修复方法主要依赖于传统的图像处理技术,如插值、边缘扩展和纹理合成等。这些方法往往依赖于对图像退化过程的假设和手工设计的先验模型(在没有具体图像数据的情况下,基于对图像的一些假设或经验规律构建的数学模型。通常基于图像的统计特性、物理规律或几何结构等信息来推测图像的缺失部分或修复过程。例如,假设图像中的纹理是平滑变化的,或者图像中的边缘是连贯的)。尽管它们在一些简单的图像修复任务中表现良好(如小范围的划痕或污点、简单的噪声去除等不会大幅改变图像的整体结构的“损坏”),但对于复杂的退化(如雨水、雾霾、摩尔纹等),这些方法无法有效地恢复图像细节,且修复效果往往较为粗糙。
- 摩尔纹是一种在数码照相机或者扫描仪等设备上,感光元件出现的高频干扰的条纹,是一种会在图片上出现的彩色的高频率不规则条纹。摩尔纹因为是不规则的,所以并没有明显的形状规律。
二.基于深度学习的图像修复方法:
近年来,深度学习方法在图像修复中取得了显著进展,特别是卷积神经网络(CNN)和变换器(Transformer)模型的应用。传统的深度学习方法(如使用CNN进行图像修复)通常通过学习输入图像与目标图像之间的映射关系来进行修复。然而,CNN方法面临一个问题,即其感受野较小,难以捕捉到图像中的全局信息,因此可能无法恢复图像中的低频部分和全局结构。
随着变换器模型的引入,图像修复任务得到了进一步的改进。变换器通过自注意力机制能够有效捕获图像中的全局上下文信息,从而提高修复效果。然而,现有的变换器方法通常会忽视高频细节,导致图像中的纹理和边缘信息损失,且在处理高分辨率图像是计算成本是超高的。
注意力机制(Attention Mechanism)通过自适应地分配“注意力”来帮助网络关注图像中的关键信息,尤其是在图像修复任务中,能够显著提高修复的效果和性能。其核心思想是,网络在处理图像时,不是平均地对所有像素或区域进行处理,而是根据特定任务需要,重点关注图像中最重要的部分。在图像修复中,注意力机制通过以下几种方式提升修复性能:
-
自适应的局部信息聚焦: 图像中的修复任务通常要求网络重点关注损坏区域的上下文信息(比如损坏区域的周围像素)。注意力机制可以帮助网络动态地对修复区域的相关上下文赋予更高的权重,从而提高修复的准确性和细节恢复能力。
- 例如,使用自注意力(Self-Attention)机制,网络会根据图像各部分之间的相似度来调整每个部分的权重,确保修复时充分利用周围的有效信息。
-
提高信息传播能力: 修复任务往往需要图像各部分之间的信息相互传播。例如,图像的远距离像素(比如角落的像素)可能对修复区域有重要影响。注意力机制可以通过计算全局依赖关系,有效地将这些远距离信息传递到目标区域,改善修复效果。
- 例如,使用多头自注意力(Multi-head Attention)来捕捉不同的特征信息,从而改善图像的修复细节。
-
去除无关信息的干扰: 在图像修复任务中,一些图像区域可能包含不相关的信息,干扰修复过程。注意力机制能够帮助网络自动忽略这些无关部分,集中精力修复重要区域,从而提高修复的质量。
- 比如,图像中某些背景区域的细节可能与当前修复区域无关,注意力机制可以降低这些区域对修复结果的影响。
-
细节恢复: 对于复杂的图像修复任务,尤其是涉及到纹理或边缘恢复时,注意力机制能够在不同尺度上捕捉到重要的图像特征,尤其在细节恢复方面表现优异。
变换器架构(Transformer)最初被设计用于自然语言处理任务,但其在图像处理中的表现也非常强大,特别是在图像修复、生成和超分辨率等任务中,取得了显著的进展。以下是变换器架构在图像修复中的优势和表现:
-
全局依赖关系建模: 与传统卷积神经网络(CNN)不同,CNN通常只关注局部区域的特征,而变换器架构能够建模图像中全局的依赖关系。对于图像修复任务,尤其是需要恢复较大区域细节时,变换器能够有效地利用图像的全局上下文信息,从而提高修复结果的连贯性和细节恢复能力。
- 例如,在修复大范围缺失区域时,变换器能够通过自注意力机制将图像的远程区域与缺失区域关联起来,从而更准确地推断出缺失部分的内容。
-
非局部特征提取: 变换器架构通过自注意力机制能够有效地捕捉图像中不相邻的特征信息,这对于修复任务非常重要。图像中的一些细节和纹理可能分布在较远的区域,变换器能够有效地连接这些信息并利用它们进行修复。
- 例如,通过在变换器中引入多头自注意力,网络能够在多个尺度和不同的特征维度上提取图像信息,进一步提升修复的精度。
-
处理不同尺度信息: 变换器结构通常可以通过层次化的处理,在不同的层次上获取不同尺度的图像特征。对于图像修复任务,特别是在复杂退化任务中,图像的局部细节和全局结构可能需要同时考虑。变换器能够通过多层次、多尺度的特征提取,处理图像中的细节和大范围的上下文信息,从而提高修复的效果。
- 比如,变换器在处理缺失的细节(如纹理、边缘等)时能够更精确地恢复,而在处理整体结构(如背景、场景等)时也能保持连贯性。
-
并行计算与效率: 变换器架构在计算上具有较好的并行性,相较于传统的RNN或CNN,它能够在训练时更高效地处理大规模数据。这使得变换器能够更快速地处理复杂的图像修复任务,尤其是在高分辨率图像修复中能够保持较好的效率和质量。
- 由于自注意力机制计算的并行性,变换器在处理高分辨率图像时能够显著减少计算时间,提升训练和推理效率。
-
灵活的结构和易于扩展: 变换器架构的灵活性使得它能够轻松与其他网络结构(如卷积神经网络、生成对抗网络等)结合,进一步提升图像修复的性能。例如,Vision Transformer (ViT)、Swin Transformer等变换器模型已经被证明在图像任务中非常有效,它们能够结合图像的局部特征和全局信息,提升修复精度。
三.提示学习的引入:
近年来,一些研究开始探索通过提示学习(Prompt Learning)来辅助图像修复任务。提示学习最早应用于自然语言处理(NLP),并迅速扩展到计算机视觉领域。提示学习方法通过为模型提供额外的指引(如特定的退化信息或任务相关特征)来提升模型性能。这些方法通常注重空间相关性,而忽略了频率特征的使用。
四.频率域处理的引入:
在本论文之前,就有论文提出频率域处理图像会有较大的进步和成效,但它们都或多或少有“提高高频信息在模型中的权重”等先验假设或只做了粗略修复,具体有:
- 《"Learning to Restore a Single Image from a Single Measurement" (CVPR 2021)》:提出了频率损失函数,结合深度卷积神经网络(CNN)来恢复图像。在损失函数中加入频率损失,优化频率域上的高频信息。
- 《"Deep Image Prior for Image Restoration: Frequency-Localized Training" (ICCV 2021)》:在深度图像先验(DIP)模型的基础上,提出了频率局部化训练,即在训练过程中强调频率域特征,尤其是高频部分的训练。假设图像的高频信息(如纹理、细节)在图像恢复中非常重要,因此对高频部分进行更高权重的优化。
- 《"Frequency Guided Generative Networks for Image Restoration" (ICCV 2023)》:提出了Frequency Guided Generative Network (FG-GAN),通过频率引导机制在生成对抗网络(GAN)中引导图像恢复过程,特别是在细节恢复中使用频率信息。假设高频信息对于图像质量的贡献至关重要,并且生成对抗网络能够有效利用频率引导来改善图像修复的细节。
- 等
简单代码验证
本研讨对现有工作的传统修复方式、注意力机制修复方式和频率域中修复方式做了简单的验证,对于上文出现过的那张具有摩尔纹的图片,本研讨关注这三种修复(去噪)方式的效果与效率。
import cv2
import numpy as np
import torch
import torch.nn as nn
import matplotlib.pyplot as plt
import time
# 载入包含摩尔纹的图像
img = cv2.imread(r"D:\Microsoft VS Code\vs work\codeworkvs\py\1.png")
img_gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 传统图像修复(去除摩尔纹):使用高斯模糊
def traditional_moire_repair(img):
return cv2.GaussianBlur(img, (5, 5), 0)
# 注意力机制修复:使用一个简单的卷积层模拟注意力机制修复
class SimpleAttentionModel(nn.Module):
def __init__(self):
super(SimpleAttentionModel, self).__init__()
# 定义一个简单的卷积层
self.conv1 = nn.Conv2d(1, 64, kernel_size=3, padding=1)
self.conv2 = nn.Conv2d(64, 1, kernel_size=3, padding=1)
self.relu = nn.ReLU()
def forward(self, x):
x = self.relu(self.conv1(x))
x = self.conv2(x)
return x
# 频率域修复(去除摩尔纹):通过傅里叶变换处理图像
def frequency_domain_filter(img):
# 执行傅里叶变换
f = np.fft.fft2(img)
fshift = np.fft.fftshift(f)
# 创建低通滤波器(去噪)
rows, cols = img.shape
crow, ccol = rows // 2, cols // 2
fshift[crow-30:crow+30, ccol-30:ccol+30] = 0 # 阻断高频部分
# 逆傅里叶变换得到修复后的图像
f_ishift = np.fft.ifftshift(fshift)
img_back = np.fft.ifft2(f_ishift)
img_back = np.abs(img_back)
return img_back
# 开始计时并执行各个修复过程
# 传统图像修复
start_time = time.time()
mean_filtered = traditional_moire_repair(img_gray)
traditional_repair_time = time.time() - start_time
print(f"Traditional Repair Time: {traditional_repair_time:.4f} seconds")
# 注意力机制修复
start_time = time.time()
def attention_based_repair(img):
model = SimpleAttentionModel()
model.eval() # 设置为评估模式
img_tensor = torch.tensor(img, dtype=torch.float32).unsqueeze(0).unsqueeze(0) # 转换为Tensor并添加批次和通道维度
img_tensor = img_tensor / 255.0 # 归一化
with torch.no_grad(): # 禁用梯度计算
restored_img_tensor = model(img_tensor)
restored_img = restored_img_tensor.squeeze().cpu().numpy() * 255 # 转回Numpy,并恢复为原始范围
return restored_img.astype(np.uint8)
restored_attention = attention_based_repair(img_gray)
attention_repair_time = time.time() - start_time
print(f"Attention-based Repair Time: {attention_repair_time:.4f} seconds")
# 频率域修复
start_time = time.time()
restored_frequency = frequency_domain_filter(img_gray)
frequency_repair_time = time.time() - start_time
print(f"Frequency Domain Repair Time: {frequency_repair_time:.4f} seconds")
# 绘制修复结果
fig, axes = plt.subplots(1, 3, figsize=(18, 5))
# 显示传统修复结果
axes[0].imshow(mean_filtered, cmap='gray')
axes[0].set_title(f"Traditional Repair (Gaussian Blur)\nTime: {traditional_repair_time:.4f}s")
axes[0].axis('off')
# 显示注意力机制修复结果
axes[1].imshow(restored_attention, cmap='gray')
axes[1].set_title(f"Attention-based Repair\nTime: {attention_repair_time:.4f}s")
axes[1].axis('off')
# 显示频率域修复结果
axes[2].imshow(restored_frequency, cmap='gray')
axes[2].set_title(f"Frequency Domain Repair\nTime: {frequency_repair_time:.4f}s")
axes[2].axis('off')
plt.tight_layout()
plt.show()

本文的创新:
本文的创新之处在于引入频率域的提示学习,采用频率分量作为额外的输入信息来指导图像修复过程。通过将图像特征分解为低频和高频成分,FPro能够针对不同频率特征进行处理,从而有效恢复图像的细节和全局结构。与现有方法相比,FPro能够更好地处理图像中的退化特征,如雨滴、水雾和摩尔纹等。
3. 本文工作
研究目标:
本文的主要目标是提出一种基于频率提示引导的图像修复方法——FPro,旨在提升图像修复效果,尤其是对于处理复杂退化问题(如雨滴、雾霾等)的场景。传统的图像修复方法往往只能处理图像中的空间细节信息,难以有效应对这些复杂的退化情况。FPro通过引入频率提示机制,将图像的低频与高频信息解耦,从而能够针对不同退化类型采取不同的修复策略。具体而言,FPro的设计目标是通过频率分解和频率提示调制,精确恢复图像的细节和结构信息。
研究方法简述:
FPro的核心思想是通过引入频率提示引导图像修复过程。通过引入这种“提示”信息,修复模型能够专注于特定的图像特征,使修复结果更加精准,特别是在图像退化复杂时。具体方法包括以下几个步骤:
- 输入特征提取: 通过卷积层提取输入图像的浅层特征,为后续的修复和频率分解做准备。浅层特征能够提供图像的基本信息,包括图像的纹理、边缘等内容。
- 频率分解: FPro通过使用动态学习的低通和高通滤波器将图像特征解耦成低频和高频部分。低频部分主要包含图像的全局结构信息,而高频部分则保留了图像的细节信息。不同类型的图像退化(例如雨滴、雾霾、摩尔纹等)可能对高频或低频部分产生不同程度的影响,FPro正是利用这种特点来优化修复过程。
- 频率提示调制器: 在频率提示调制阶段,FPro设计了双重提示模块(LPM和HPM),分别对低频和高频特征进行处理。通过高频提示调制器(HPM)和低频提示调制器(LPM),FPro注入了特定频率的提示信息,使得图像修复过程中能够更加精细地调整图像的恢复细节。例如,在去雨任务中,HPM有助于处理图像中的细节部分,如雨滴的边缘和雨条的纹理,而LPM则帮助保持图像的全局结构,避免失去背景信息。
- 低频提示负责引导模型恢复图像的全局结构。在图像退化时,低频部分通常受影响较小,但保留了物体的主要形态。FPro通过低频提示(LPM)模块引导修复过程中的低频信息恢复,确保修复后的图像能够保留自然的结构和形状。例如,在雨滴去除任务中,低频信息对于恢复背景和整体物体形状尤为重要。
- 高频提示则负责帮助模型恢复细节和纹理,如边缘和表面纹理等。由于高频部分往往容易受到退化(例如,雨滴、运动模糊等)的影响,恢复高频信息对于修复图像的细节至关重要。FPro通过高频提示(HPM)模块来强调修复过程中的高频部分,以增强图像的清晰度和细节。例如,在去雨或去雾任务中,恢复高频信息有助于去除图像中的模糊部分,恢复图像的清晰度和真实感。
- 门控机制: FPro通过门控机制(门控机制是指在深度学习模型中通过引入“门”(gate)来控制信息流的流动和处理方式的机制,核心思想是能够“选择性地”控制哪些信息传递或保留,从而优化网络的学习过程)来抑制无用的频率成分,聚焦于有用的频率信息。在图像修复过程中,一些无关的频率成分(例如噪声或不相关的干扰)可能会对图像恢复造成负面影响。通过门控机制,FPro能够动态学习并生成低通和高通滤波器,从而有效地筛选出对修复有帮助的频率信息。
- 图像修复分支: 图像修复分支负责将频率提示信息结合到修复过程中,利用变换器模型中的解码器部分对图像进行恢复。在这一过程中,频率提示被用作修复的引导,确保修复结果更加细致和准确。特别是在处理复杂退化情况时,FPro能够通过频率提示引导更好地恢复细节和结构信息。
假设:
本文的假设并未明确提出额外的先验假设,而是基于图像的频率特性来进行修复。具体来说,FPro假设图像的退化影响在频率域内表现为不同的低频和高频信息,而这些信息的提取与调制能够有效提升图像的修复效果。通过频率分解和频率提示调制,模型能够适应各种退化类型,并恢复图像的清晰度。
实验架构:
GDD(Global Domain Decoder)、DPB(Deformable Prompt Branch)、常规修复分支(即编码-解码器结构)共同协作,以频率提示为核心,优化图像恢复过程。以下是这些模块之间的数据流、作用和相互协同工作的详细总结:
1. GDD、DPB中的数据信息来源与作用
GDD(Global Domain Decoder)
- 数据来源:GDD接收来自编码器的特征输出。这些特征通常是图像的高层次表达,包含了空间和频率信息。编码器处理图像后,会得到一个表示图像全局信息的潜在空间特征图。
- 框架:先对浅层特征Fs进行全局平均池化,得到该特征图的全局特征,比如对于尺寸为 h×w×d的特征图,GAP层将其转换为 1×1×d 的尺寸,其中 d是特征图的深度或通道数。 通过 1×1 卷积 + Sigmoid 激活 学习到一个通道权重向量(Gate),并与输入特征进行逐元素乘积,实现对输入特征的动态筛选。BN用于批归一化操作,对删选后的元素进行批归一化,加速训练过程,提高模型的稳定性,并减少对初始化的敏感性。Softmax 层会将输入的特征(如通道权重或某些特征响应)转换为概率分布,使得每个类别的输出值代表该类别的概率。
- 作用:GDD的主要功能是提取全局频率信息,尤其是图像中的高频部分(如纹理和细节)。它通过分析全局频率信息帮助恢复图像的细节部分,特别是在去噪、去模糊、超分辨率等任务中提供关键的高频细节。
DPB(Deformable Prompt Branch)
-
数据来源:DPB的输入数据来自两个部分:
- 来自GDD的频率信息:GDD输出的频率信息(特别是高频)为DPB提供了全局频率提示。
- 来自常规修复分支的解码器的数据:常规修复分支的解码器输出经过1x1卷积处理的特征,这些特征包含了图像的低级别空间信息,如边缘、轮廓等。这些空间信息为DPB提供了图像恢复的粗略框架和结构信息。
-
作用:DPB的任务是生成频率提示,以引导图像恢复过程。DPB根据全局频率信息(来自GDD)和空间特征(来自解码器1x1卷积)生成低频和高频的频率提示。DPB通过这种方式为图像恢复过程提供了更加细致、动态的频率提示,尤其是在恢复局部细节方面发挥重要作用。
2. DPB输出的数据信息去向与作用
DPB的输出是低频和高频的频率提示。通过LPM(Low-frequency Prompt Module)和HPM(High-frequency Prompt Module),DPB生成的频率提示分别关注图像中的低频结构(如背景和边缘)和高频细节(如纹理和细小结构)。
- 输出去向:DPB生成的频率提示将传递给解码器或后续的恢复模块。这些频率提示会与解码器的输出结果进行融合,进一步优化图像恢复过程,提升图像的质量,尤其是在去噪、去模糊、超分辨率等任务中。
- 低频提示(来自LPM):帮助恢复图像中的大尺度结构和背景,确保图像的整体框架和结构完整。
- 高频提示(来自HPM):帮助恢复图像中的细节和纹理,特别是在细节恢复和噪声去除方面起到关键作用。
3. 常规修复分支与GDD、DPB的协同工作
-
常规修复分支(即编码-解码器结构)首先通过编码器对输入图像进行特征提取,将图像转换为潜在空间表示。接着,通过解码器恢复图像的空间信息(如边缘、颜色、结构等)。在解码器中,输出的特征会经过1x1卷积处理,提供图像的低级空间特征。这些特征在图像恢复的早期阶段起到基础修复的作用。
-
GDD和DPB作为辅助模块,通过频率信息引导常规修复分支的图像恢复过程:
- GDD从编码器的输出中提取全局频率信息,特别是高频信息(如纹理和细节),并将这些信息传递给DPB,帮助生成全局频率提示。GDD为图像恢复提供了高频细节的指导。
- DPB根据来自GDD的频率信息和来自解码器的空间信息生成低频和高频提示。DPB为解码器提供了更加精细和动态的恢复指导,特别是在恢复图像的局部细节时发挥重要作用。
-
融合机制:常规修复分支(解码器)生成的基础恢复结果与来自GDD和DPB的频率提示共同作用,通过融合策略(低频和高频图被注入提示组件,以区分根据特定任务所需的有用元素,然后通过 1×1 卷积将其调制为不同的提示),得到最终的图像恢复结果。频率提示帮助模型在恢复过程中同时关注图像的低频结构和高频细节,从而提高恢复的效果。
4. 整体工作流程
- 编码器:对输入图像进行特征提取,输出包含空间和频率信息的特征图。
- 常规修复分支(解码器):解码器利用编码器输出的特征恢复图像的空间信息,生成初步的恢复结果,并通过1x1卷积提取低级空间特征。(先通过卷积层得到浅层特征Fs,再通过N1级编码解码器提取深度特征Fd。由于Transformer模型早期层主要聚焦于聚合局部模式,自注意力模块作为低通滤波器,容易稀释高频局部细节。 故在编码器中去除了注意力机制,更改为N2个FFN和配套的卷积层进行下采样,解码器中通过N2对MSA和FFN以及卷积层进行上采样。)
- GDD:从编码器输出的特征中提取全局频率信息,特别是高频细节,为DPB提供全局频率提示。
- DPB:结合来自GDD的频率信息和解码器输出的空间特征,动态生成低频和高频的频率提示,并将其传递给解码器或后续恢复模块。
- 解码器与频率提示融合:解码器与频率提示融合,生成最终恢复结果。低频提示帮助恢复图像结构,高频提示帮助恢复图像细节。
实验结果:
实验结果表明,FPro在多个图像修复任务(如去雨、去水滴、去摩尔纹、去模糊和去雾)中展现了优异的性能,超越了现有的最先进方法。
评估指标:
- 峰值信噪比(PSNR):PSNR(Peak Signal-to-Noise Ratio)是一种常用于衡量图像去噪、压缩质量等效果的指标,表示原始图像与恢复图像之间的信噪比。

- PSNR值越大,表示恢复图像与原图越接近,去噪或压缩效果越好。
- PSNR通常用于低失真(即恢复图像与原图差异很小)的情况,但它并未考虑图像的结构和内容。
-
结构相似度(SSIM):SSIM(Structural Similarity Index)是一种更符合人眼视觉感知的图像质量评价标准,考虑了亮度、对比度和结构等因素。它比PSNR更能反映视觉上的相似性。

- SSIM的值范围在[0, 1]之间,值越接近1表示两幅图像越相似,质量越好。
- SSIM能够有效地捕捉到图像的结构信息,因此比PSNR更符合人眼视觉的感知。
-
感知质量指标(NIQE):NIQE(Natural Image Quality Evaluator)是一种无参考的图像质量评估方法,主要用于评估图像的自然性和感知质量。与PSNR和SSIM不同,NIQE不需要参考图像,而是基于自然图像统计学模型来评估图像质量。
- 特征提取:首先,NIQE会提取图像的多个统计特征(如纹理、对比度、结构等),这些特征基于自然图像的统计分布。
- 高斯模型:然后,这些特征会与一个通过大量自然图像学习到的高斯模型进行比较。该模型能够描述自然图像的统计分布。
- 计算距离:最后,使用这些特征与自然图像模型之间的距离来衡量图像的质量。NIQE评分越低,表示图像质量越好。
- NIQE是无参考指标,因此不需要原始图像作为对比,适用于图像质量的自动评估。
- 它特别适合用于评估图像恢复、去噪等任务中的图像质量,尤其在没有原图的情况下。
- FLOP指标
- 计算依据:FLOP(浮点运算)表示模型的运算量,通常用于衡量模型计算复杂度。
- 意义:数值越小,表示模型效率越高,适合实际部署。
雨滴条纹去除
SPAD 数据集:包括降雨和无雨场景中的高清图像,用于研究去雨任务。数据集通过合成的方式生成,涵盖多种降雨强度和场景。
与之前最好的方法 DRSformer 相比,FPro 提高了 0.46 dB 的性能。此外,FPro 相比于最近的模型 SCDFormer 提高了 2.1 dB 的 PSNR。
- DRSformer模型:DRSformer(Deep Rain Streaks Removal Transformer)基于自注意力机制的深度学习模型,旨在去除雨滴对图像质量的影响,通过特征自适应方式生成高质量的去雨图像。
- SCDFormer模型:通过将自注意力机制与卷积神经网络结合,旨在有效去除图像中的降雨噪声,提高去雨效果。
雨滴去除
AGAN-Data数据集:包含大量具有不同天气状况(如雨、雾、雪)的图像,供去噪和图像恢复研究使用。
优于Eigen’s、Pix2pix、TransWeather、Uformer、WeatherDiff128、DuRN、RaindropAttn、AttentiveGAN、IDT 和 Restormer。FPro 相较于 Restormer 提高了 0.28 dB 的 PSNR,相较于最近的方法 WeatherDiff128 提高了 2.3 dB。
- Pix2pix模型:基于生成对抗网络(GAN)的图像到图像的转换模型,特别擅长从某种图像到另一种图像的映射,如去雨、图像修复等任务。
- TransWeather模型:使用Transformer架构来处理图像的天气影响,如去雨、去雪等,利用自注意力机制有效捕捉图像的全局特征。
- Uformer模型:采用U-Net结构与Transformer相结合,专注于图像恢复任务,通过跨层特征整合提升图像质量。
- WeatherDiff128模型:基于深度卷积神经网络和扩散模型,针对复杂天气条件下的图像恢复任务,适应不同天气场景。
- DuRN模型:(Deep Uncertainty Rain Removal Network)专门为去雨任务设计的深度学习模型,结合了深度残差网络,能够有效从降雨图像中提取有用特征。
- RaindropAttn模型:利用自注意力机制专注于雨滴的恢复过程,通过捕捉局部与全局信息,实现优越的去雨效果。
- AttentiveGAN模型:使用生成对抗网络(GAN)结合注意力机制,通过提升对雨滴区域的关注,从而改善去雨效果。
- IDT模型:(Image Denoising Transformer)基于图像深度学习技术,适用于去除图像中的雨滴和雪等噪声。
- Restormer模型:采用Transformer架构与卷积神经网络结合,专注于图像恢复任务,尤其在去噪、去雾方面表现良好。
摩尔纹去除
TIP-2018数据集:用于图像去摩尔纹任务。
优于 AMNet、DMCNN、UNet、WDNet、MopNet、TAPE-Net、FHD2eNet、MBCNN、Uformer-S。FPro 比之前最好的方法 Wang 等人提出的框架(粗到细的解耦去摩尔纹框架(Coarse-to-Fine Disentangling Demoiréing Framework))提高了 0.38 dB 的性能,相较于最近的模型 TAPE-Net提高了 1.73 dB。
- AMNet模型:(Attention Mechanism Network)利用自注意力机制处理图像去噪任务。
- DMCNN模型:(Deep Multi-scale Convolutional Neural Network)基于卷积神经网络,通过多尺度学习提高恢复效果。
- UNet模型:一种常见的卷积神经网络结构,广泛用于图像分割、恢复等任务,通过编码器-解码器架构进行图像处理。
- WDNet模型:(Weather Dehazing Network)专门用于图像去雨的深度学习网络,通过多尺度卷积和去噪模块恢复图像细节。
- MopNet模型:(Multi-scale Optical Priors Network)采用多尺度学习和深度神经网络提高图像去雨质量。
- TAPE-Net模型:(Texture-Aware Photo Enhancement Network)利用卷积神经网络对图像进行去雨处理,采用特定的深度学习架构提升去雨效果。
- FHD2eNet模型:(Full High Definition to Enhanced Network)一个基于深度学习的图像恢复网络,专门用于去雨和图像清晰度恢复。
- MBCNN模型:(Multi-Branch Convolutional Neural Network)基于深度卷积神经网络,用于图像去噪、去雨等恢复任务。
- Uformer-S模型:是Uformer模型的简化版,适用于图像恢复,特别是去雨任务。
去雾
SOTS基准数据集:去雾数据集(真实单图像去雾RESIDE)的一部分。REalistic Single Image DEhazing (RESIDE),这是一个大规模数据集,用于公平地评估和比较单图像去雾算法。 RESIDE的一个显着特征在于其评估标准的多样性,从传统的完整参考指标到更实用的无参考指标,再到所需的人类主观评估和任务驱动评估。RESIDE 根据不同的数据源和图像内容,分为五个子集,每个子集有不同的目的(训练或评估)或来源(室内或室外)。各子集图片示例:
- ITS (Indoor Training Set)
- OTS (Outdoor Training Set)
- SOTS (Synthetic Objective Testing Set)
- RTTS (Real-world Task-Driven Testing Set)
- HSTS (Hybrid Subjective Testing Set)
- Unannotated Real-world Hazy Images(不包含在上述子集中)

优于AOD-Net、MSCNN、DehazeNet、EPDN、FDGAN、AirNet、Restormer和 PromptIR。与最近的基于提示的方法 PromptIR相比,FPro 提高了 1.54 dB 的性能。
- AOD-Net模型:(All-in-One Dehazing Network)专为去雾设计,通过深度卷积网络恢复被雾霾遮挡的图像细节。
- MSCNN模型:(Multi-Scale Convolutional Neural Network)一个多尺度卷积神经网络,适用于图像恢复和去雾任务,能够从不同尺度的图像信息中恢复细节。
- DehazeNet模型:用于图像去雾,通过卷积神经网络恢复图像中的真实场景。
- EPDN模型:(Edge-Preserving Dehazing Network)专门设计用于去雾任务,通过深度网络恢复雾霾影响下的图像质量。
- FDGAN模型:(Feature Decomposition Generative Adversarial Network)基于生成对抗网络,用于图像去雾,能够生成去雾后的清晰图像。
- AirNet模型:基于深度学习的图像恢复网络,特别用于去除空气污染造成的图像失真。
- Restormer模型:采用Transformer架构与卷积神经网络结合,专注于图像恢复任务,尤其在去噪、去雾方面表现良好。
- PromptIR模型:基于提示方法的图像恢复模型,特别适用于低光和恶劣天气条件下的图像清晰度恢复。
运动模糊去除
GoPro 数据集:用于去模糊任务的数据集。包括 3,214 张大小为 1,280×720 的模糊图像,其中 2,103 张是训练图像, 1,111 张是测试图像。该数据集由一一对应的真实模糊图像与 ground truth 图像组成,均由高速摄像机拍摄。
优于或持平于除PromptRestorer之外的所有方法,相较于最近的基于提示的方法 PromptRestorer实现了具有竞争力的性能(PSNR略略低),并且计算量只有其一半。与此同时,与最近的方法 CODE相比,FPro 在 PSNR 上提高了 1.11 dB,并且使用了更少的 FLOP。
- CODE:(Coordinate Descent Method for Image Denoising)是一种针对图像去噪的优化方法,旨在通过协同优化策略精细处理图像中的噪声和细节。该方法使用了特定的降噪策略,并在图像的空间特征上进行优化,取得了优秀的去噪效果。
- IPT:(Image Processing Transformer)是基于变换器(Transformer)结构的图像处理模型,旨在通过强大的自注意力机制来捕捉图像的全局信息。IPT能够有效地处理图像的各种变换任务,如去噪、超分辨率等,并通过适应性学习图像的结构和内容来优化处理效果。
- MPRNet:(Multi-Path Residual Network)是一种多路径残差网络,专门用于图像恢复任务(如去噪、去模糊等)。MPRNet通过多个路径来处理不同层次的特征,从而更好地恢复图像细节。它通过残差连接在多尺度上进行信息流动,提高了恢复质量。
- MIMO:(Multi-Input Multi-Output Network)是一种多输入多输出的神经网络结构,通常用于图像去模糊任务。MIMO通过多个输入通道处理不同的图像信息,并使用输出通道生成去模糊的图像。该模型能够有效地处理图像中的各种复杂模糊。
- HINet:(High-order Information Network)是用于图像去噪的一种深度网络结构。HINet通过高阶信息的融合来提升去噪性能,特别是在处理复杂噪声时能够更好地恢复细节。该模型强调高阶信息的学习,使得噪声与图像内容之间的关系得以更加精确的建模。
- MAXIM:(Maximum Image Matching Network)是一种图像匹配网络,旨在解决图像恢复中的失真问题。MAXIM通过最大匹配原则在图像恢复过程中找到最佳的匹配特征,从而有效地去除图像中的模糊和噪声,提高图像质量。
- Restormer:Restormer是一种基于变换器结构的图像恢复模型,专注于去噪、去模糊等任务。Restormer采用了自注意力机制和局部变换器(Local Transformer)来捕捉图像中的长期和局部依赖关系,极大地改善了图像恢复的精度和效率。
- PromptRestorer:PromptRestorer是一种结合了提示学习(Prompt Learning)的图像恢复模型。通过引入提示信息,PromptRestorer能够更好地指导图像恢复过程,特别是在处理不同类型的恢复任务(如去噪、去模糊等)时,能够快速适应并提升效果。
感知质量评估
与其他考虑的方法相比,FPro 获得了更低的 NIQE 分数,这意味着生成的结果包含更清晰的内容和更好的感知质量。通过定性比较,FPro 在视觉上优于其他模型,表明它能够很好地处理未见过的退化情况。
模型效率
FLOPs 和运行时间是在输入图像大小为 256×256 时测量的,PSNR 分数是在 SPAD上测试的。尽管 FPro 在 PSNR 指标上取得了更好的性能,但其模型复杂度(FLOPs 和参数量)比 Restormer 和 DRSformer 更低。与其他 CNN-/Transformer 基础的方法相比,FPro 的模型复杂度仍然较低或相当。
并通过消融研究证明了GDD和DPB的有效性。
总的来说,FPro在多个任务中表现优异,能够在确保图像质量的同时,优化计算效率,具有广泛的实际应用潜力。
4. 研讨评价
优缺点:
本文提出的FPro方法在图像修复领域具有重要的创新意义。其优点在于通过频率提示引导修复过程,能够更好地恢复图像的细节,尤其在面对复杂退化时表现突出。同时FPro采用了Dual Prompt Block (DPB) 模块,可以灵活地从低频和高频特征中提取信息,这种模块化的设计使得方法的应用更加灵活,能够针对不同任务定制优化策略。并且原论文评估了模型在多个数据集下的性能,验证了来自不同传感器或不同环境的图像下对频率提示的响应性能均较好。
然而,FPro也存在计算复杂度较高的问题,尤其是在高分辨率图像的修复任务中,需要强大的计算资源。且在频率域中的一系列操作和门控机制等可能使得模型的可解释性和透明度较差。
存在质疑:
尽管FPro在多个任务中表现优异,但在研讨中仍有以下质疑:
- 频率域操作的普适性:尽管FPro在处理具有强结构信息的退化类型(如雨滴、雾霾等)时表现出色,但其是否适用于所有类型的图像退化仍然存在疑问。在原文的“相关工作”部分提到:“我们的方法与近期研究探索特定退化信息以获得更好的图像修复效果相关”。对于一些“非特定”的、简单的退化(如运动模糊),频率域操作可能未必能提供明显的性能提升,因为简单模糊的退化往往不涉及频域中复杂的结构或纹理信息。因此,在这类任务中,频率域的优势可能不如直接在像素空间中进行修复。为了更好的泛化效果,提出以下可能的解决方案:
- 解决方向:可以结合FPro的频率提示模块与现有的其他方法(如基于卷积神经网络的模糊修复方法)进行集成,探索混合模式。对于简单退化,可能采用直接的像素空间修复,而对于复杂退化,则依赖于频率提示模块。
- 频率域特征的选择性处理: 在使用门控动态解耦器(GDD)进行低频和高频成分的分离时,虽然引入了门控机制来优化滤波器,但仍可能存在某些频率成分被过度抑制或忽略的情况。具体而言,某些频率带可能在某些修复任务中比其他频率带更重要,但该方法通过门控机制统一处理不同频率带,可能没有针对性地优化重要频率带的特征提取。
- 计算复杂度问题: 频率域操作可能会显著增加计算开销,尤其是在大规模图像修复任务中。
- 解决方向:为了解决这一问题,可以通过优化算法(如自适应计算方法、低秩矩阵近似等),减少频率域的计算复杂度。例如,采用快速傅里叶变换(FFT)加速频域操作,或者通过网络剪枝、量化等技术减小网络的计算需求。此外,硬件加速(如使用GPU或专用AI芯片)也可以显著提升FPro的计算效率,减轻计算资源的负担。此外,分布式计算和并行处理也可能是降低复杂度的有效途径,尤其是在处理超高分辨率图像时。
对生活的应用:
FPro方法能够广泛应用于需要修复退化图像的实际场景,如自动驾驶中的雨天修复、视频监控中的模糊修复、医疗影像中的噪声去除等。
- 自动驾驶:在雨天或雾霾天气条件下,自动驾驶系统依赖于图像修复技术提高视觉感知的准确性。FPro可以用于去除雨水、水滴、雾霾等影响,恢复清晰的道路视图,从而提高自动驾驶系统在恶劣天气中的安全性和准确性。
- 视频监控:视频监控中的图像经常受到低光、运动模糊、雨水等退化因素的影响。FPro可用于去除图像中的噪声或模糊,恢复图像的细节,提升监控视频的清晰度和识别性能。这对于安防领域,尤其是在夜间或恶劣天气条件下的监控场景尤为重要。
- 医疗影像:在医疗影像领域,FPro能够应用于去噪、去模糊、去伪影等图像修复任务,提升医学影像的质量,帮助医生进行更准确的诊断。例如,FPro可以用于修复CT、MRI图像中的噪声,恢复更加清晰的组织细节。
- 遥感影像处理:遥感图像往往会受到云雾、雨滴等天气因素的影响,导致图像退化。FPro能够在遥感影像的修复中发挥重要作用,恢复高质量的地表信息,助力环境监测、灾害预警等领域。
发展前景:
随着硬件性能的提高和算法的进一步优化,FPro有望在实际应用中发挥更大的作用。尤其是随着提示学习和频率域分析方法的进一步研究,FPro有潜力应用于更多复杂的图像修复任务中。
- 多任务学习:FPro目前主要专注于单一类型的图像修复任务,但未来可以将其扩展到多任务学习中,通过一个统一的框架处理不同类型的图像退化问题。这样,FPro不仅能够针对不同退化类型进行优化,还可以跨任务共享学习的知识,提升整体修复性能。
- 频率域与其他技术的结合:未来,频率域的操作可以与其他先进技术(如生成对抗网络(GAN)、自监督学习等)结合,进一步提高图像修复效果。例如,生成对抗网络可以在修复过程中引导图像更接近自然图像,减少伪影和修复痕迹。
- 大规模数据集与实时应用:随着大规模图像数据集的不断增多,FPro有潜力扩展到大规模数据集的训练与应用。随着实时计算和边缘计算技术的进步,FPro有望成为许多实时图像修复任务(如自动驾驶、视频监控等)的主流技术。
5. 研讨结论
本文提出的FPro方法通过引入频率提示引导图像修复,能够有效恢复图像的低频和高频成分,改善修复效果。实验结果表明,FPro在多个图像修复任务中表现优异,尤其在复杂退化的修复上具有显著优势。尽管存在计算复杂度较高的问题,但FPro为图像修复领域提供了一个新的思路,具有广泛的应用前景。

















 1386
1386

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









