









写在前面
正好最近在准备数学建模竞赛,加上专业课程需求,就花时间整理了一下目前我会用到的python各种数据图的方法,也正好作为我的“入门机器学习”专栏的一个补充篇章。数据可视化也是数据分析、机器学习领域的一大议题;模型可视化也是提高模型可解释性的一大手段。为演示需要,本文均采用经典数据集如iris或简单的伪数据为例。使用了各种常用、合适的制图库,包含seaborn、matplotlib、plotly库。
目录
散点图 + 回归线(Scatter Plot with Regression Line)
编辑训练集与测试集分布对比图(Train vs Test Distribution)
数据分析可视化类
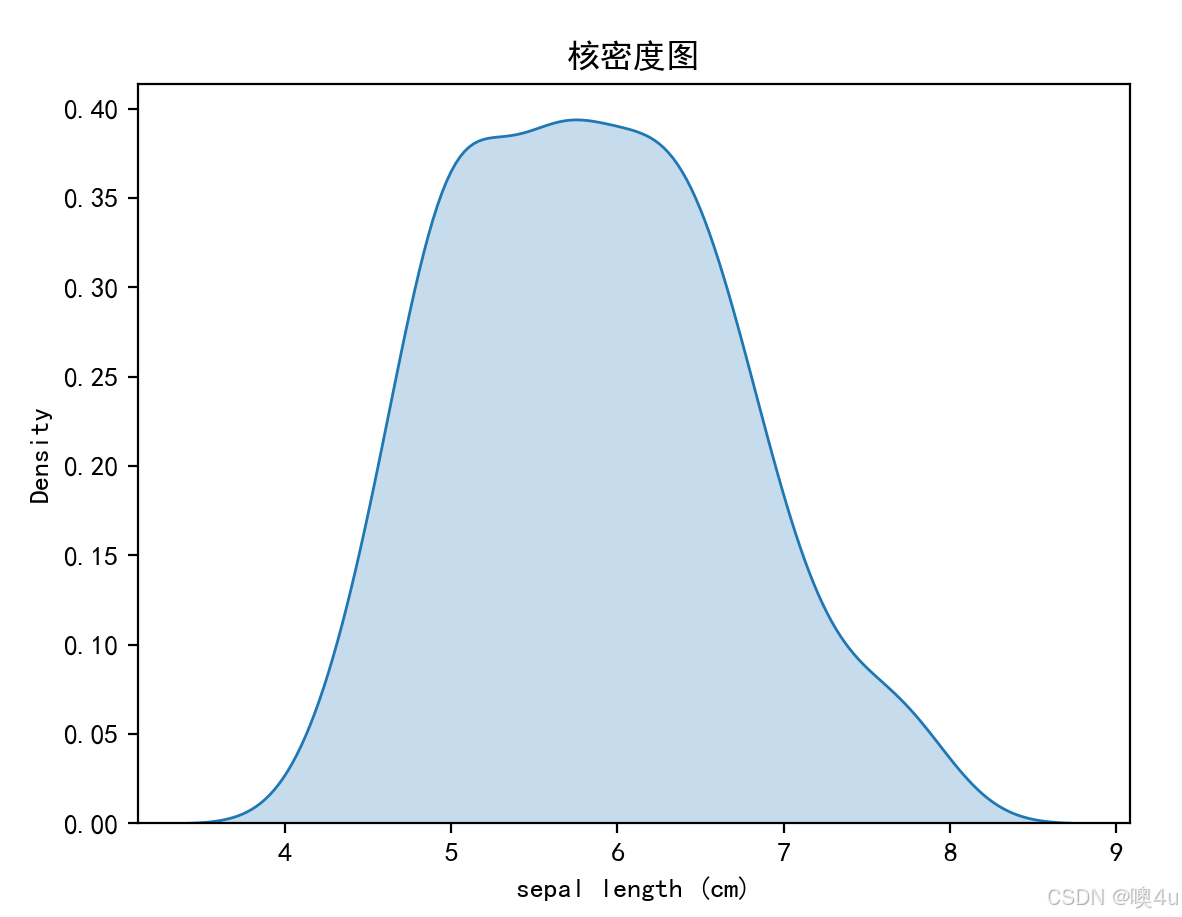
核密度图(Kernel Density Plot)
核密度图用于估计数据的概率密度,展示数据分布的平滑曲线。
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
import pandas as pd
# 设置中文字体和负号显示
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 加载数据集
iris = load_iris()
df = pd.DataFrame(iris.data, columns=iris.feature_names)
# 核密度图
sns.kdeplot(df['sepal length (cm)'], shade=True)
plt.title('核密度图')
plt.show()
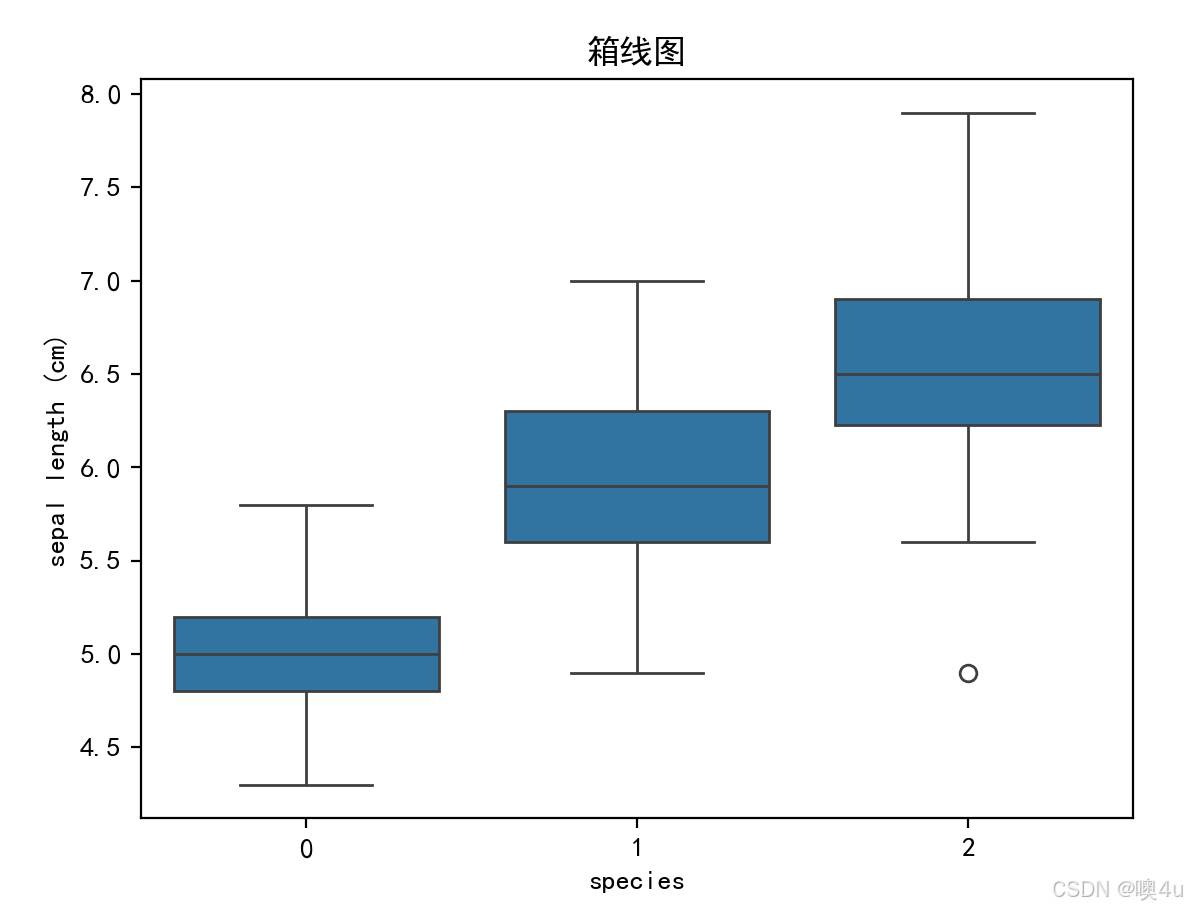
 箱线图(Box Plot)
箱线图(Box Plot)
箱线图显示了数据的中位数、四分位数和异常值,适用于比较多个类别的数据分布。
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
import pandas as pd
# 设置中文字体和负号显示
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 加载数据集
iris = load_iris()
df = pd.DataFrame(iris.data, columns=iris.feature_names)
df['species'] = iris.target
# 箱线图
sns.boxplot(x='species', y='sepal length (cm)', data=df)
plt.title('箱线图')
plt.show()
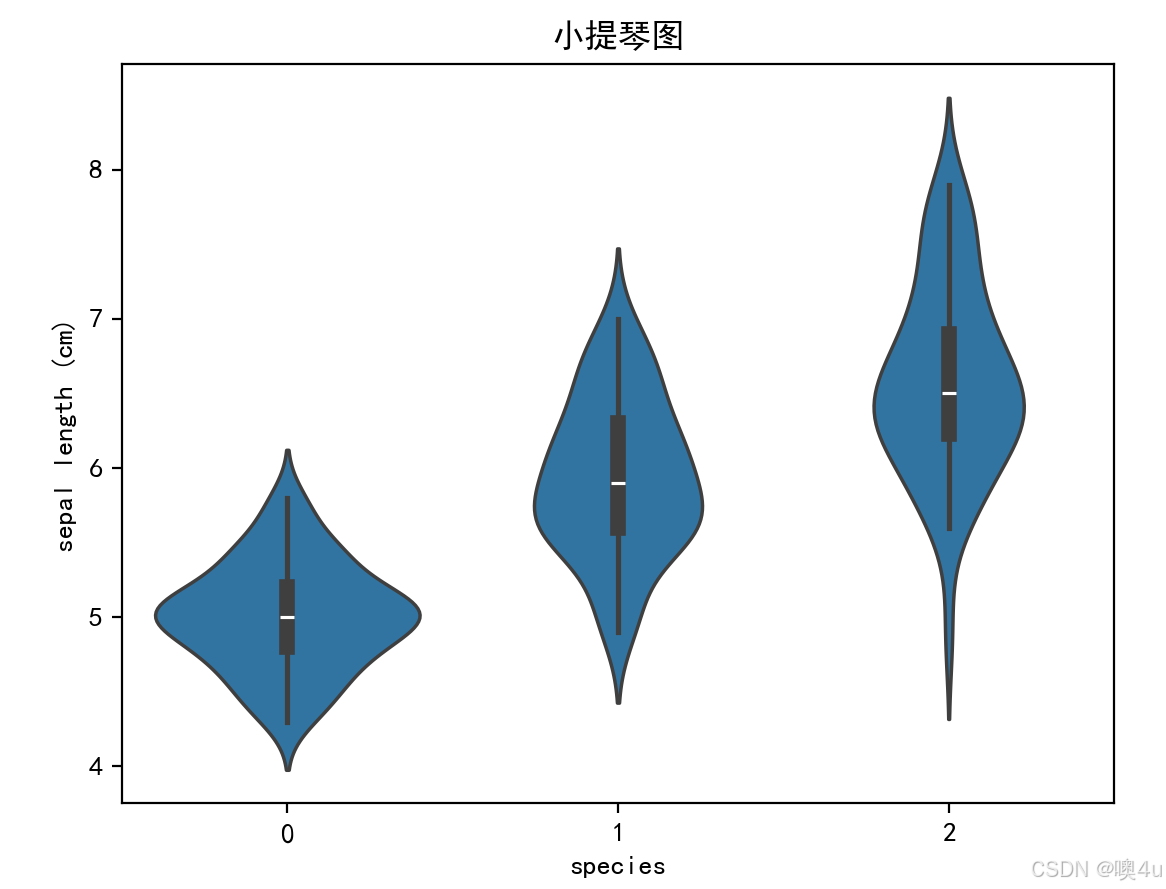
小提琴图(Violin Plot)
小提琴图结合了箱线图和核密度图,可以显示数据的分布情况和集中趋势。
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
import pandas as pd
# 设置中文字体和负号显示
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 加载数据集
iris = load_iris()
df = pd.DataFrame(iris.data, columns=iris.feature_names)
df['species'] = iris.target
# 小提琴图
sns.violinplot(x='species', y='sepal length (cm)', data=df)
plt.title('小提琴图')
plt.show()
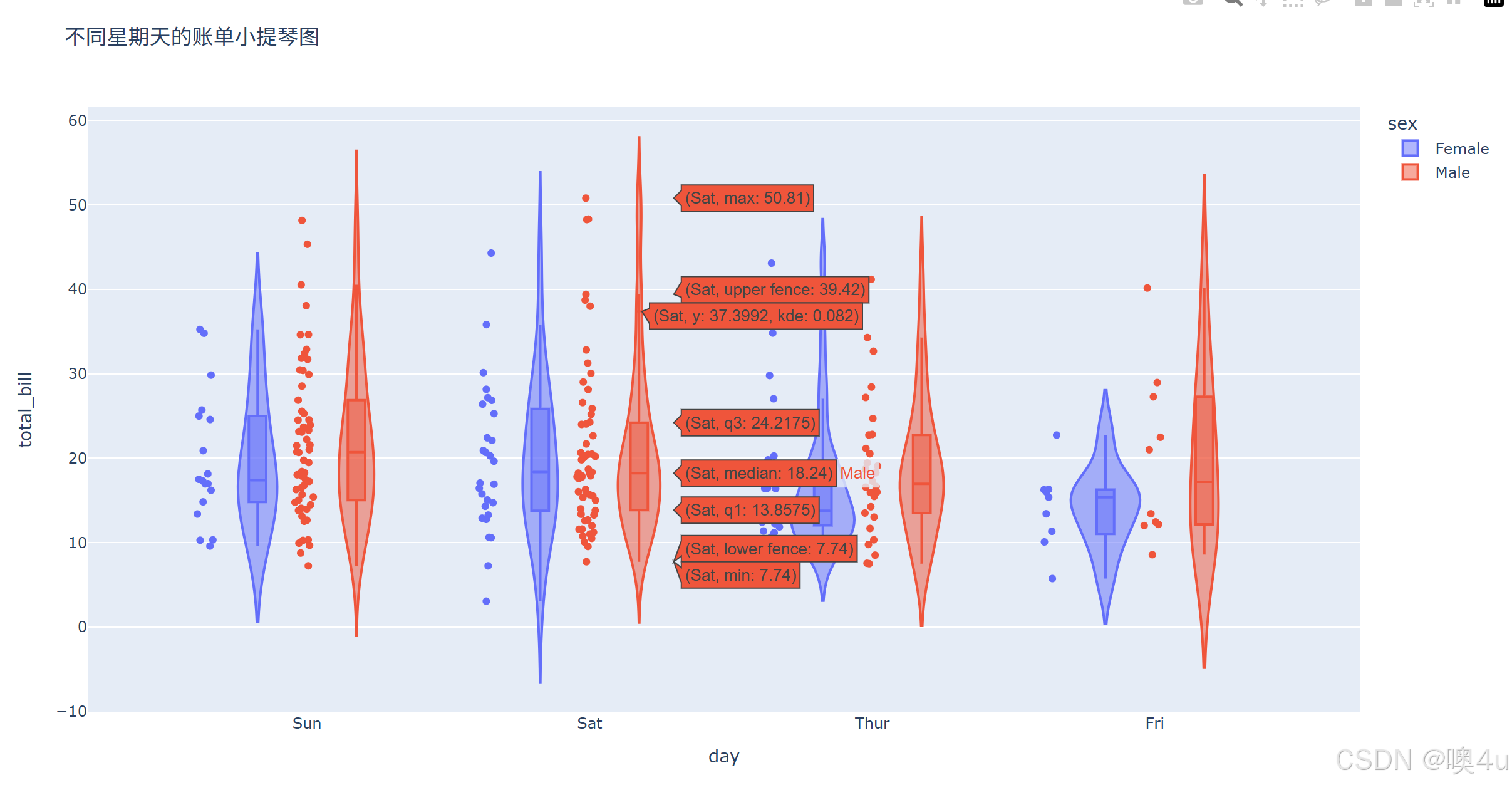
import plotly.express as px
df = px.data.tips()
fig = px.violin(df, y='total_bill', x='day', color='sex', box=True, points='all', title='不同星期天的账单小提琴图')
fig.show()
散点图(Scatter Plot)
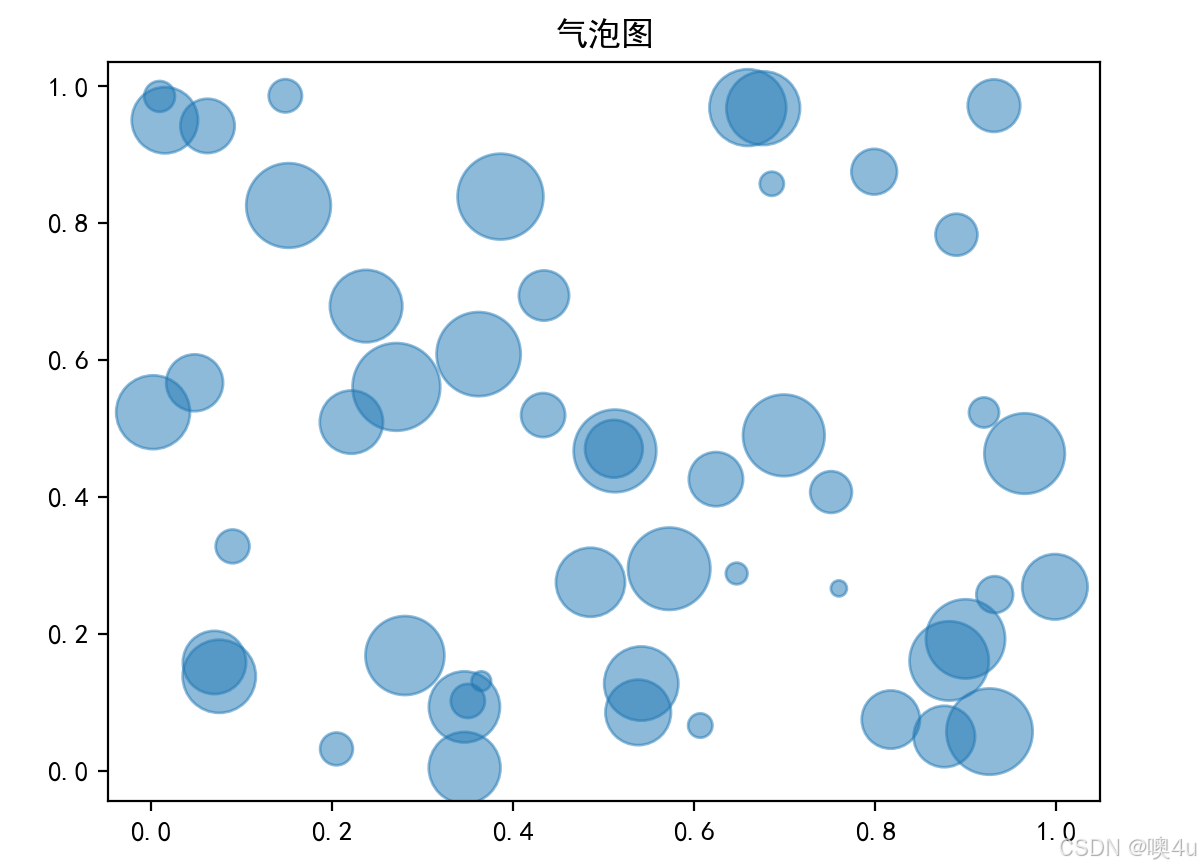
气泡图(Bubble Plot)
气泡图是散点图的扩展,除了显示数据点的位置外,还通过气泡大小来显示额外的信息(如权重)。
import matplotlib.pyplot as plt
import numpy as np
# 设置中文字体和负号显示
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 伪数据
x = np.random.rand(50)
y = np.random.rand(50)
size = np.random.rand(50) * 1000 # 气泡大小
# 气泡图
plt.scatter(x, y, s=size, alpha=0.5)
plt.title('气泡图')
plt.show()
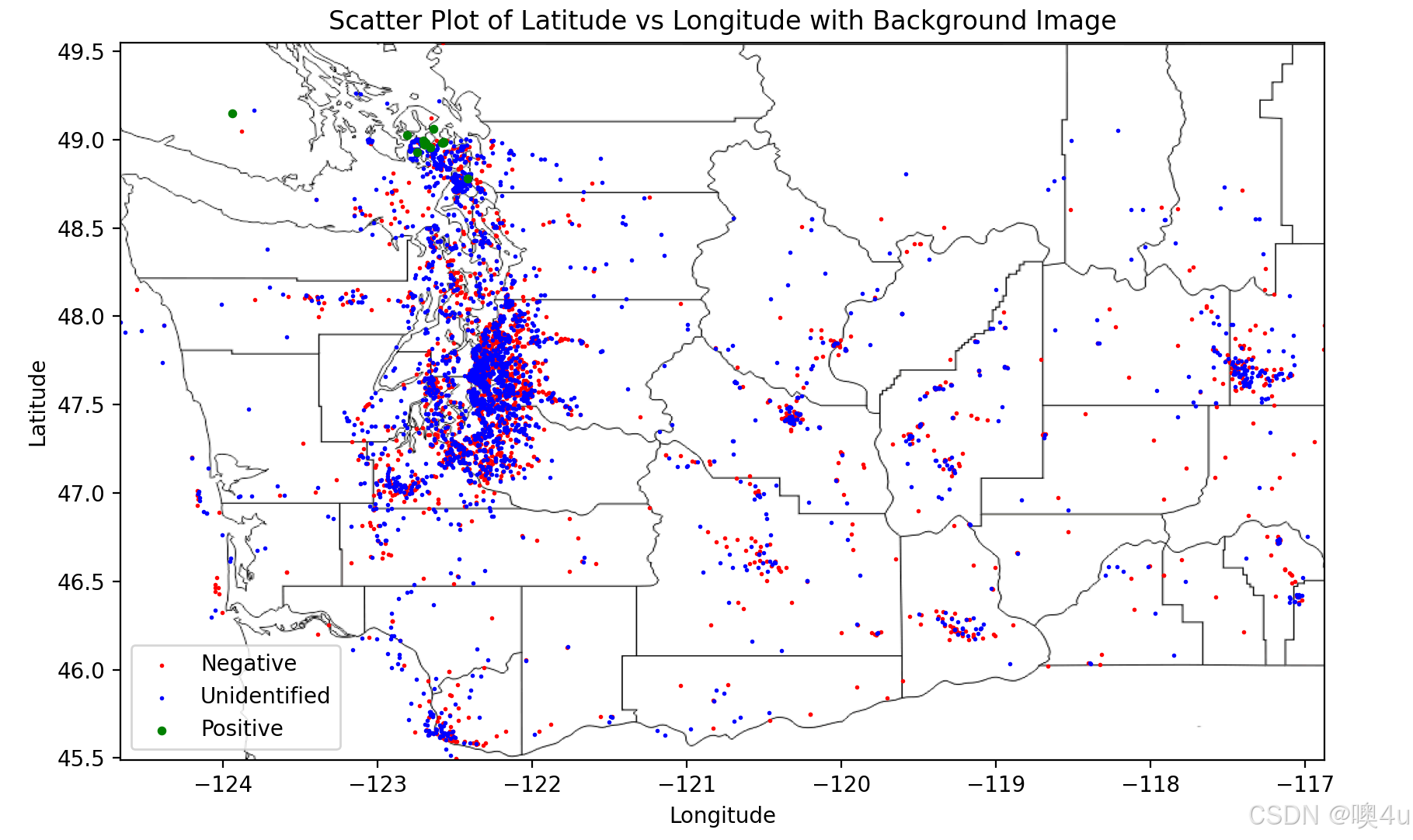
在图片中加入背景,并绘制散点图
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib.image as mpimg
# 1. 读取数据
file_path = r".\data.xlsx"
data = pd.read_excel(file_path)
# 2. 提取"Latitude"和"Longitude"列数据
latitude = data["Latitude"]
longitude = data["Longitude"]
# 3. 根据"Lab Status"分组
positive_data = data[data['Lab Status'] == "Positive ID"]
print(positive_data.info())
negative_data = data[data['Lab Status'] == "Negative ID"]
unidentified_data = data[data['Lab Status'] != "Positive ID"]
unidentified_data = unidentified_data[unidentified_data['Lab Status'] != "Negative ID"]
# 4. 加载背景图片
img_path = r'.\1.png'
img = mpimg.imread(img_path)
# 5. 创建一个新的Figure对象
plt.figure(figsize=(10, 6))
# 6. 显示背景图片
plt.imshow(img, extent=[min(longitude), max(longitude), min(latitude), max(latitude)], aspect='auto')
# 7. 绘制不同颜色的散点
plt.scatter(negative_data["Longitude"], negative_data["Latitude"], color='red', label='Negative', s=1) # Negative ID用红色
plt.scatter(unidentified_data["Longitude"], unidentified_data["Latitude"], color='blue', label='Unidentified', s=1) # 其他用蓝色
plt.scatter(positive_data["Longitude"], positive_data["Latitude"], color='green', label='Positive', s=10) # Positive ID用绿色
# 8. 设置图表标题和标签
plt.title('Scatter Plot of Latitude vs Longitude with Background Image')
plt.xlabel('Longitude')
plt.ylabel('Latitude')
# # 9. 调整散点图的坐标轴范围(缩小散点图分布空间)
# # 例如将坐标轴范围稍微收缩一点
# plt.xlim(min(longitude) + 0.8, max(longitude) - 0.8) # 左右范围缩小
# plt.ylim(min(latitude) + 0.8, max(latitude) - 0.8) # 上下范围缩小
# 10. 显示图例
plt.legend()
# 11. 显示图表
plt.show()
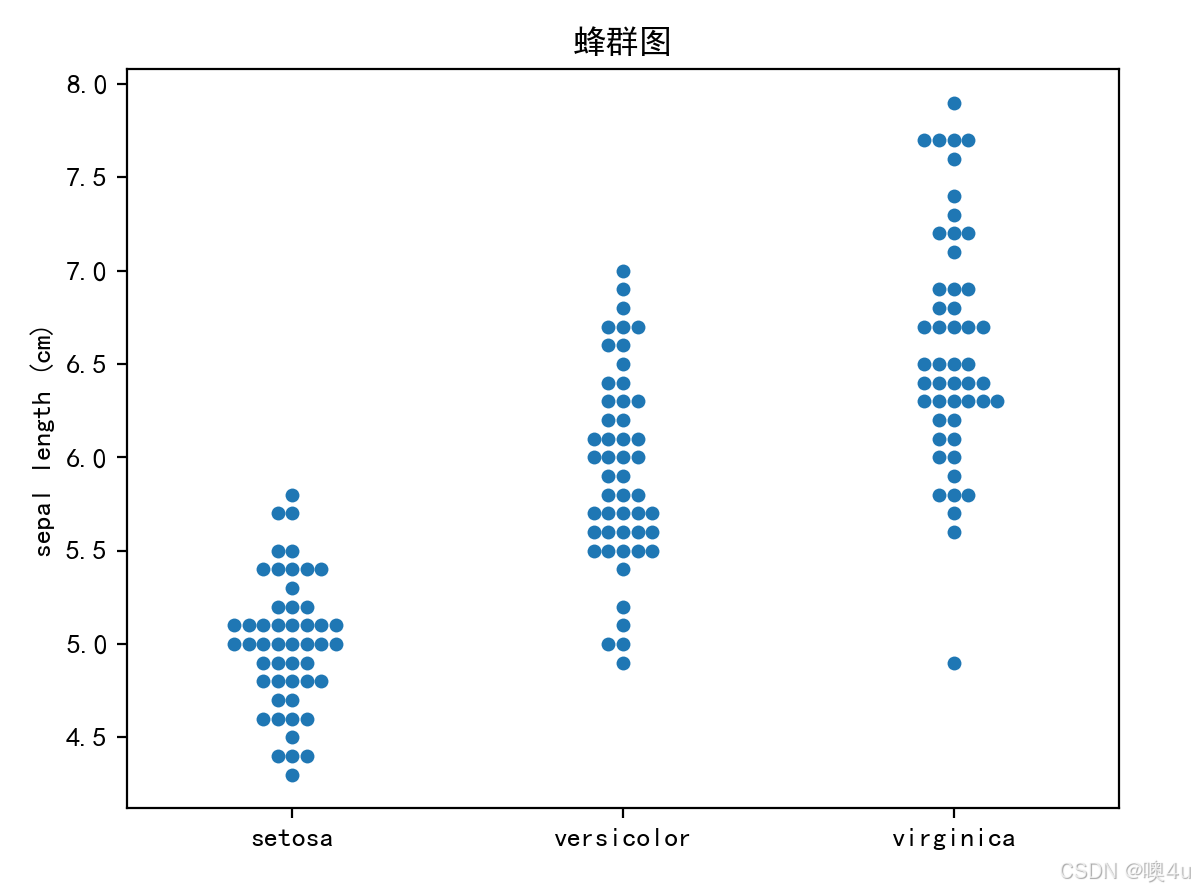
蜂群图(Swarm Plot)
蜂群图用于展示数据点的分布,避免了散点图的重叠问题,适合分类数据的可视化。
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
import pandas as pd
# 设置中文字体和负号显示
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 加载数据集
iris = load_iris()
df = pd.DataFrame(iris.data, columns=iris.feature_names)
# 蜂群图
sns.swarmplot(x=iris.target_names[iris.target], y='sepal length (cm)', data=df)
plt.title('蜂群图')
plt.show()
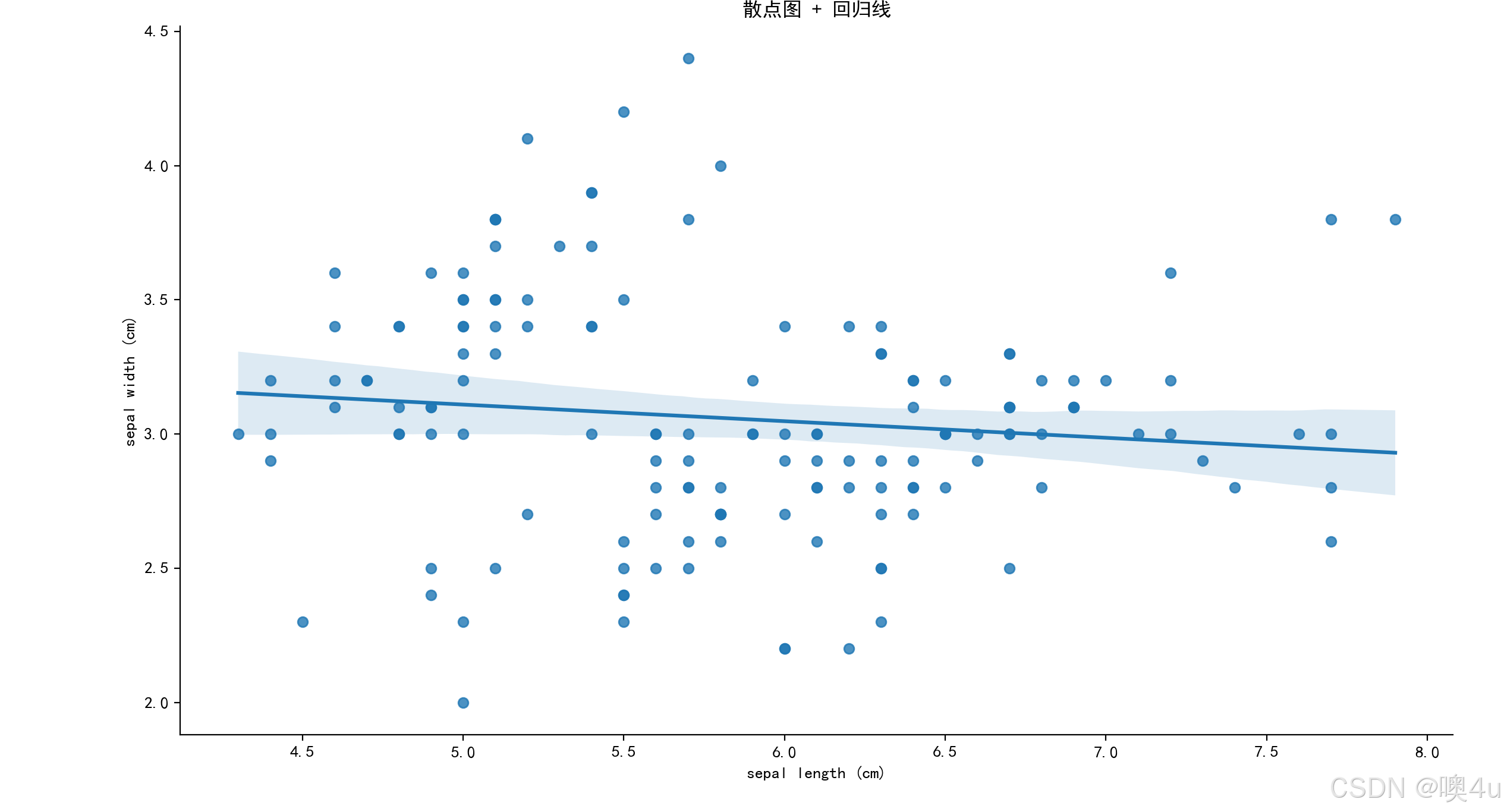
散点图 + 回归线(Scatter Plot with Regression Line)
散点图展示数据点之间的关系,回归线用于表示数据之间的线性关系。
- 置信区间阴影区域:回归线周围的浅色阴影表示拟合线的置信区间,默认是 95%。 置信区间表示回归线的可靠性,即在多次采样的情况下,线性拟合结果的可能范围。区域越大,代表预测的不确定性较高。
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
import pandas as pd
# 设置中文字体和负号显示
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 加载数据集
iris = load_iris()
df = pd.DataFrame(iris.data, columns=iris.feature_names)
# 散点图 + 回归线
sns.lmplot(x='sepal length (cm)', y='sepal width (cm)', data=df)
plt.title('散点图 + 回归线')
plt.show()
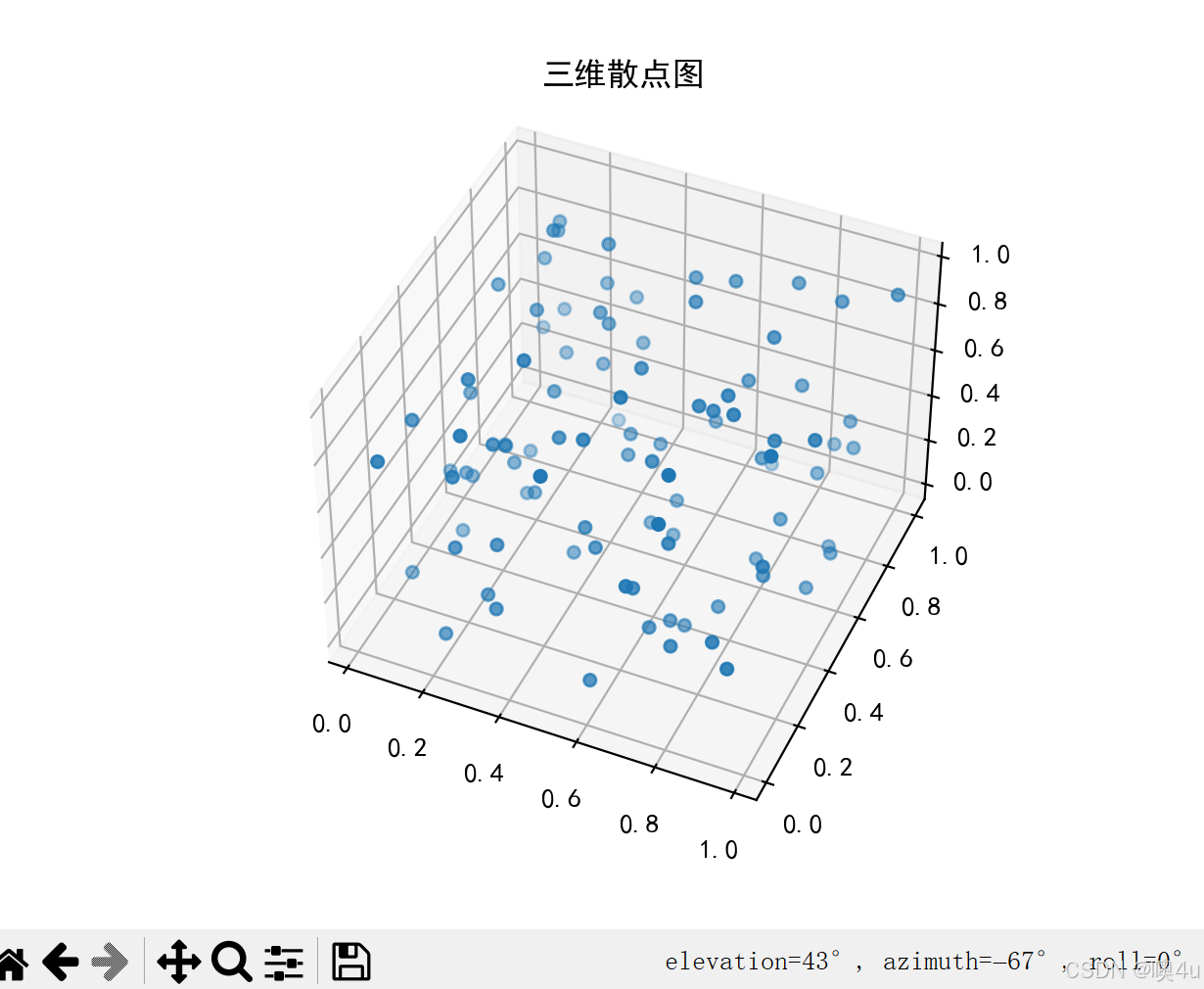
三维散点图(3D Scatter Plot)
三维散点图用于展示三维空间中数据点的分布,适用于三维数据的可视化。
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
import numpy as np
# 设置中文字体和负号显示
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 生成伪数据
x = np.random.rand(100)
y = np.random.rand(100)
z = np.random.rand(100)
# 三维散点图
fig = plt.figure()
ax = fig.add_subplot(111, projection='3d')
ax.scatter(x, y, z)
plt.title('三维散点图')
plt.show()
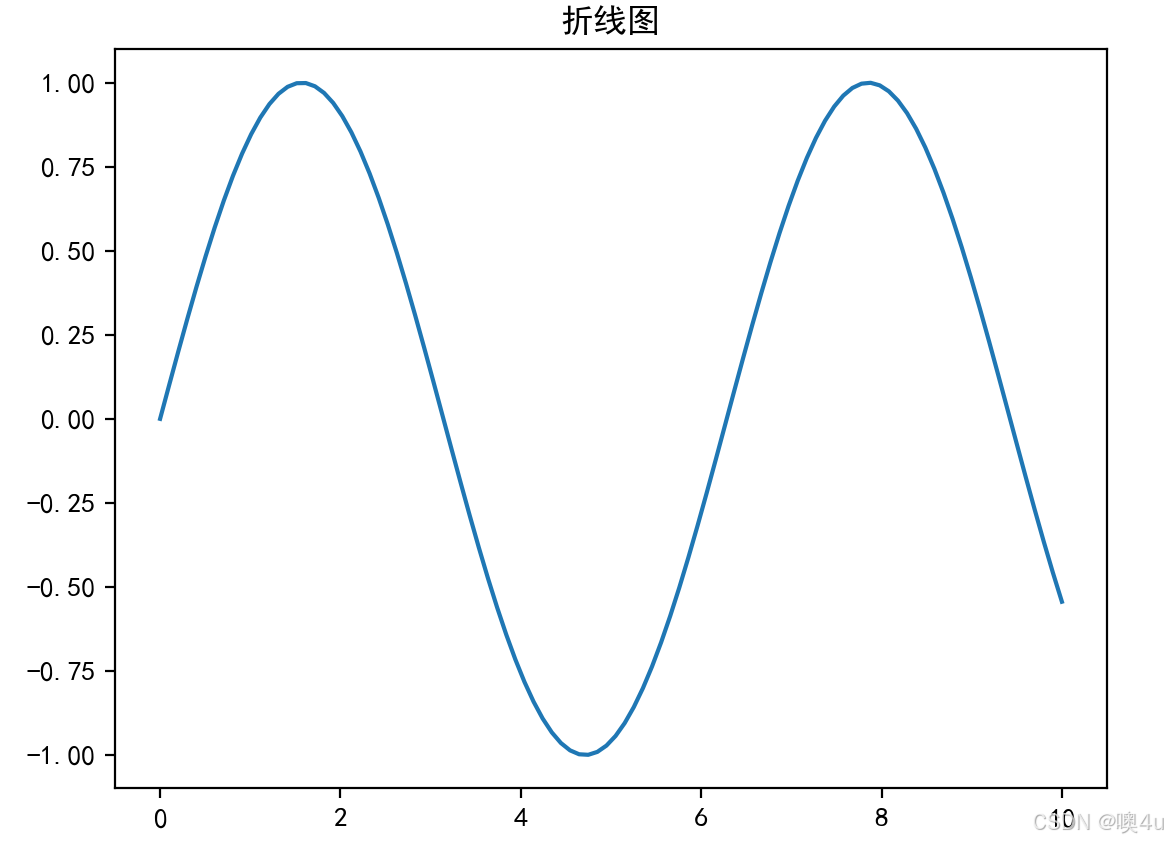
折线图(Line Plot)
折线图用于展示数据随时间或其他连续变量的变化趋势。
matplotlib库的折线图
import seaborn as sns
import matplotlib.pyplot as plt
import numpy as np
# 设置中文字体和负号显示
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 生成伪数据
time = np.linspace(0, 10, 100)
value = np.sin(time)
# 折线图
sns.lineplot(x=time, y=value)
plt.title('折线图')
plt.show()
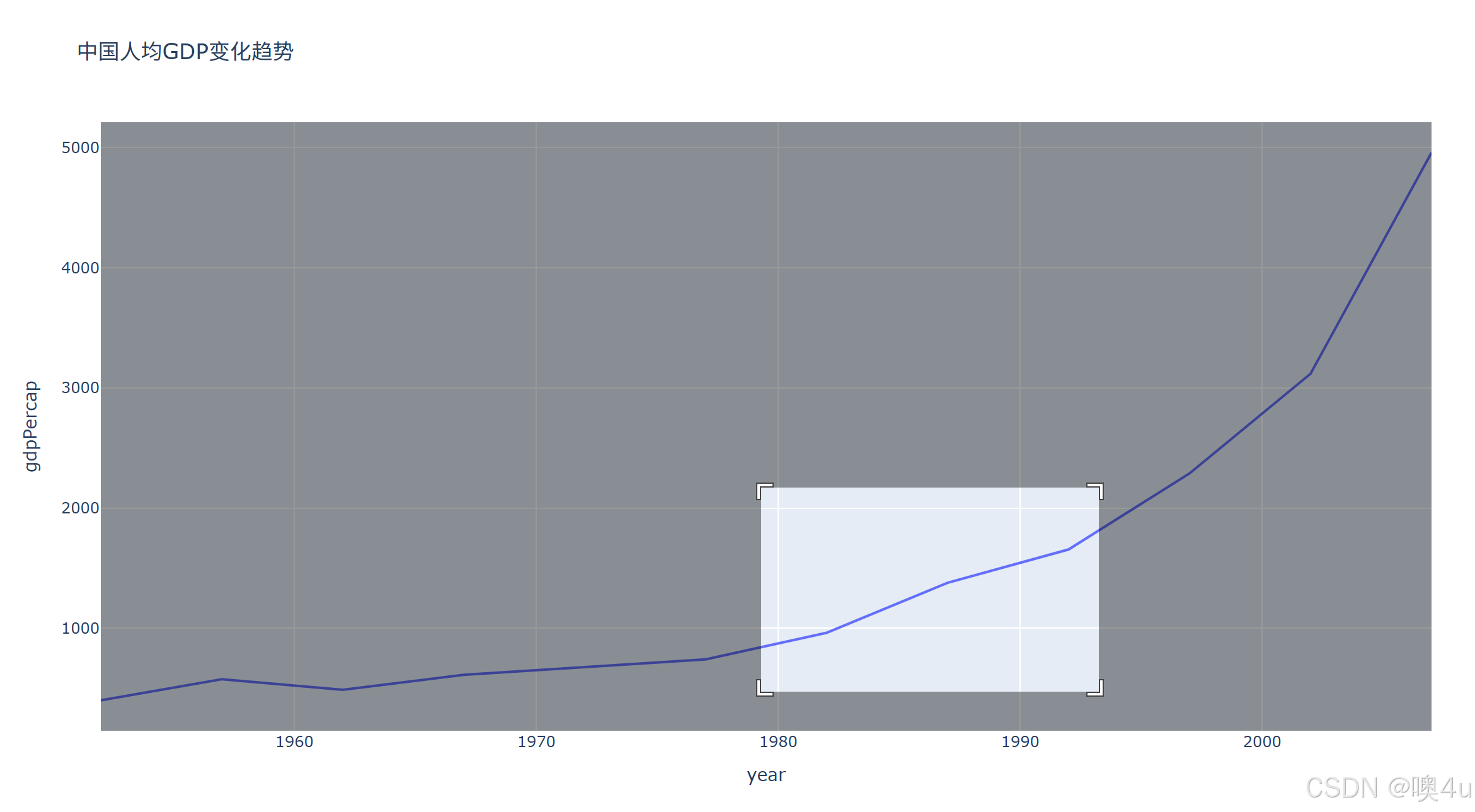
plotly库的折线图
支持选择区域放大分析:
import plotly.express as px
df = px.data.gapminder().query("country=='China'")
fig = px.line(df, x='year', y='gdpPercap', title='中国人均GDP变化趋势')
fig.show()
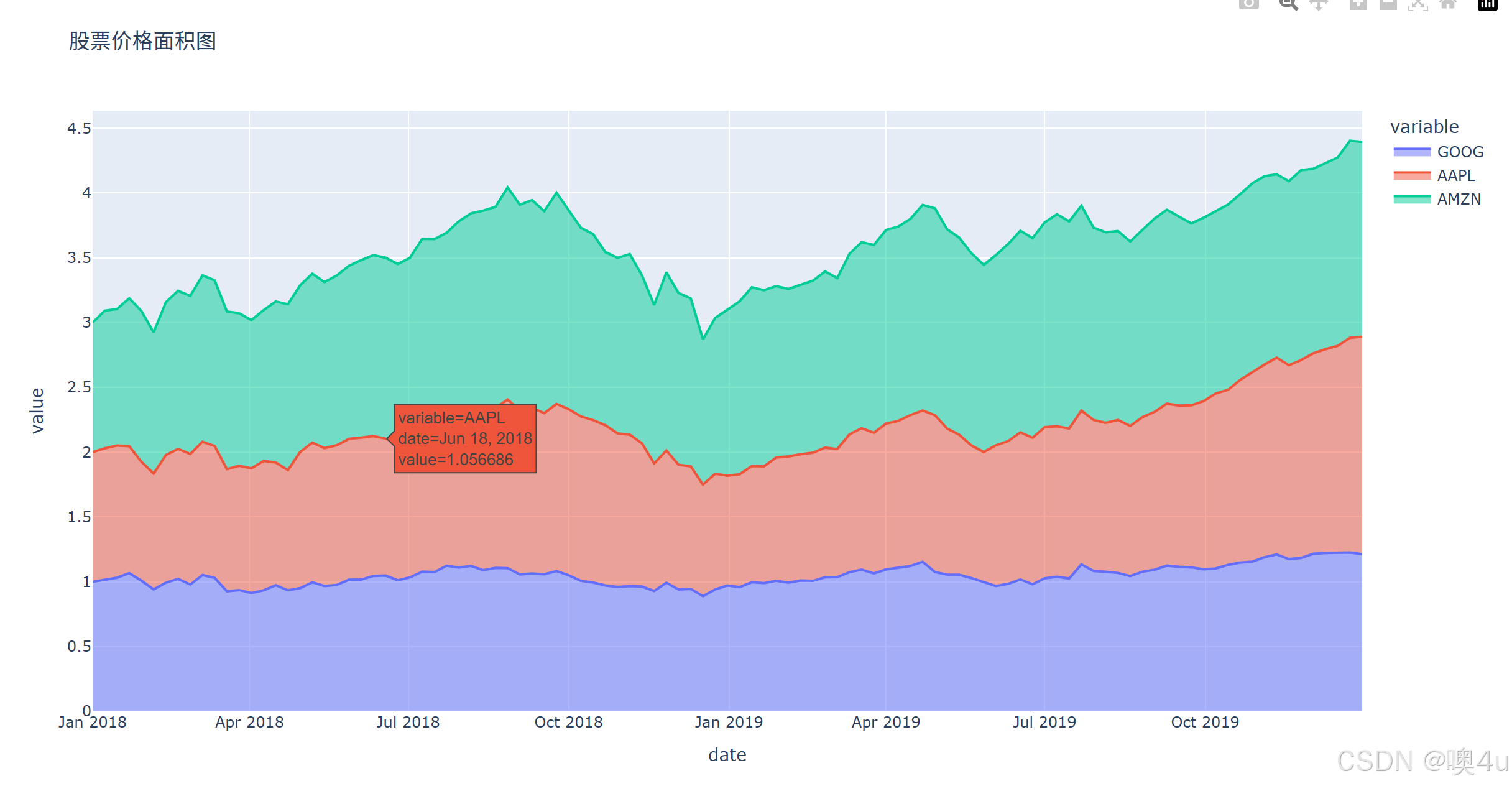
除此之外,还有plotly库几种更美观的时间序列图:
面积图(Area Chart)
import plotly.express as px
df = px.data.stocks()
fig = px.area(df, x='date', y=['GOOG', 'AAPL', 'AMZN'], title='股票价格面积图')
fig.show()
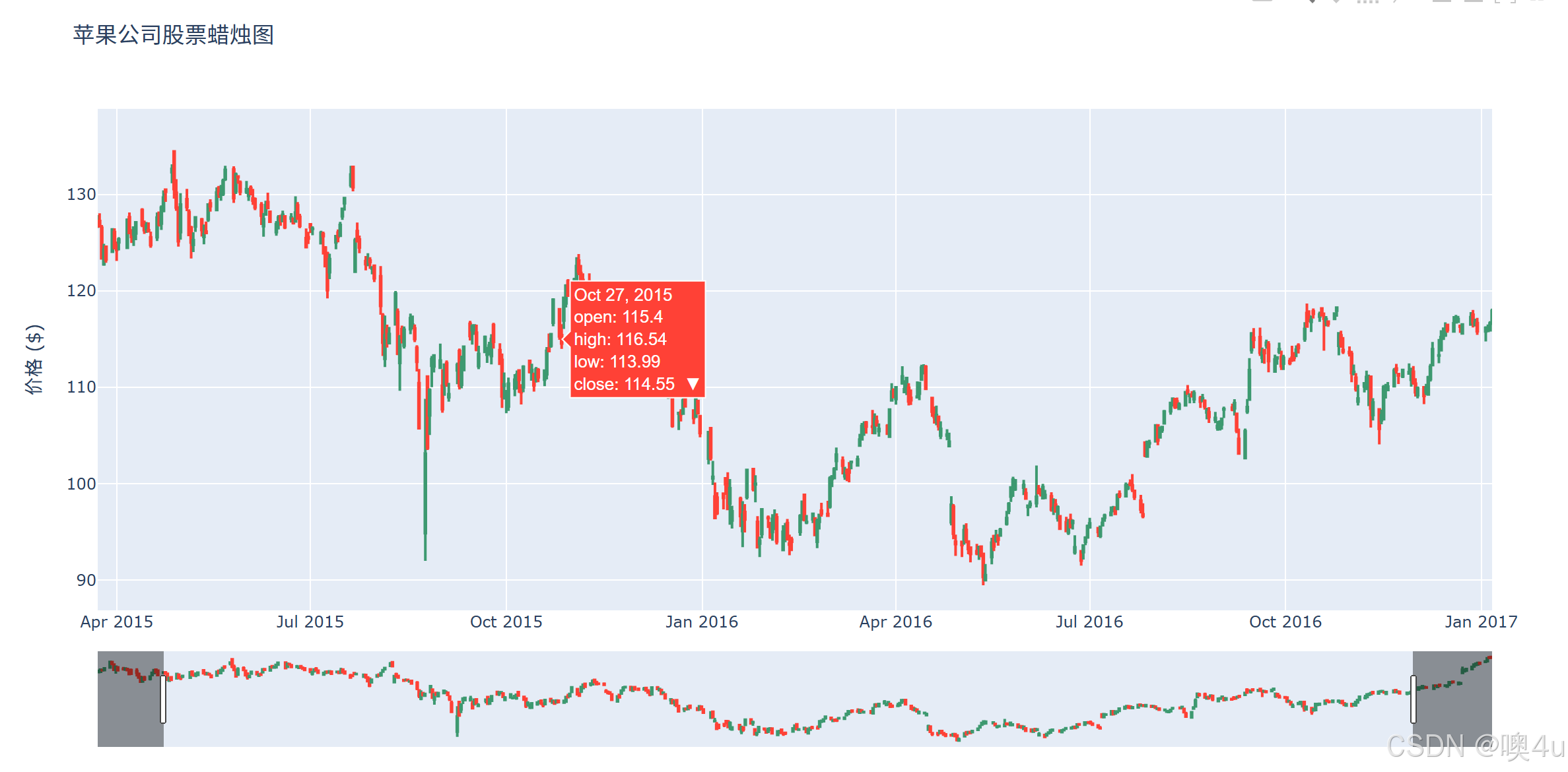
 蜡烛图(Candlestick Chart)
蜡烛图(Candlestick Chart)
金融领域,用于展示股票或其他资产的开盘、收盘、最高和最低价格。
plotly绘制的图支持滑动选择窗口期:
import plotly.graph_objects as go
import pandas as pd
df = pd.read_csv('https://raw.githubusercontent.com/plotly/datasets/master/finance-charts-apple.csv')
fig = go.Figure(data=[go.Candlestick(
x=df['Date'],
open=df['AAPL.Open'],
high=df['AAPL.High'],
low=df['AAPL.Low'],
close=df['AAPL.Close'],
name='苹果股票'
)])
fig.update_layout(title='苹果公司股票蜡烛图', yaxis_title='价格 ($)')
fig.show()
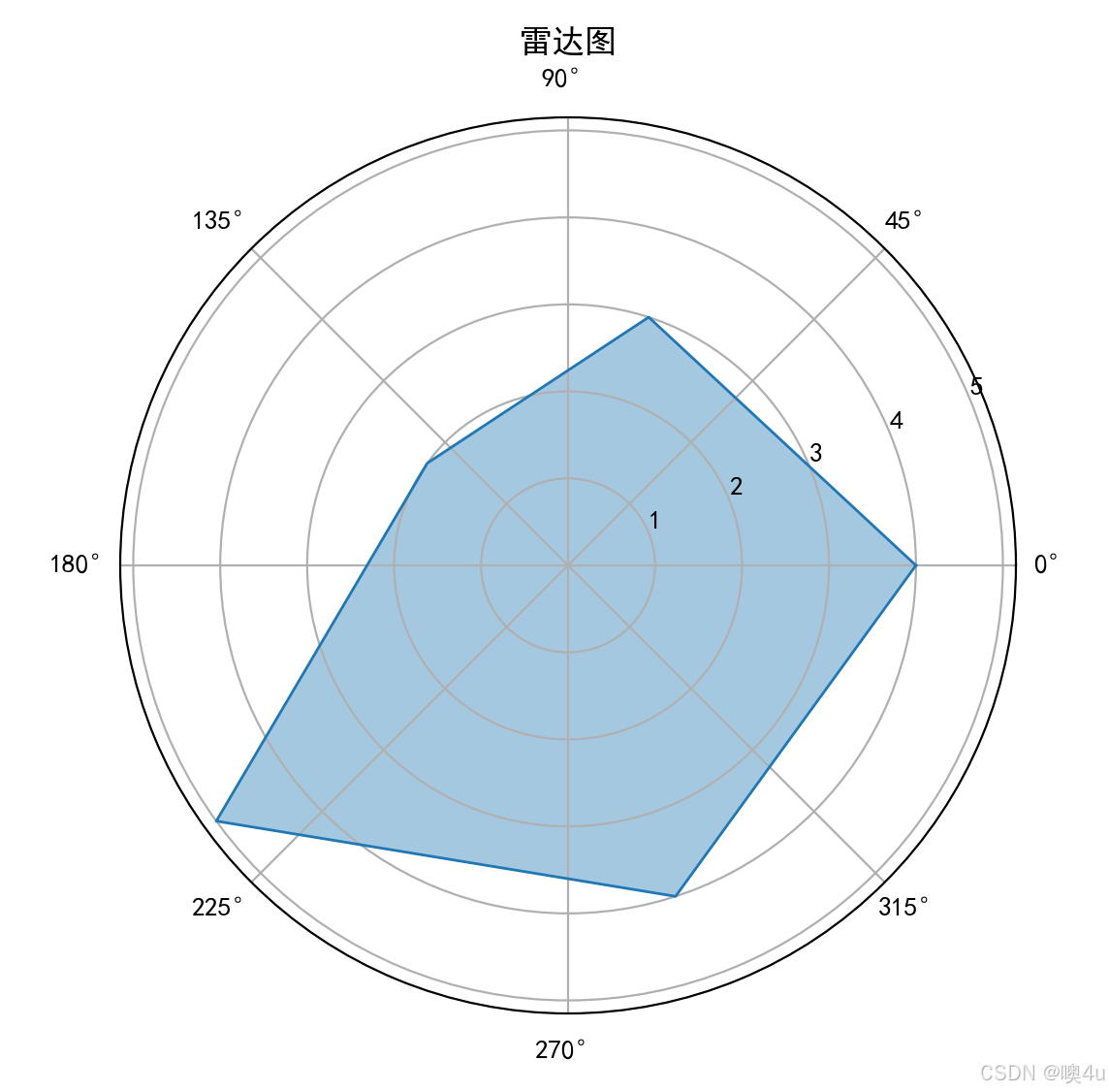
雷达图(Radar Chart)
雷达图适用于展示多个变量之间的比较,通常用于显示各项指标的表现。
import numpy as np
import matplotlib.pyplot as plt
# 设置中文字体和负号显示
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 伪数据
labels = ['A', 'B', 'C', 'D', 'E']
values = [4, 3, 2, 5, 4]
# 雷达图
angles = np.linspace(0, 2 * np.pi, len(labels), endpoint=False).tolist()
values += values[:1]
angles += angles[:1]
fig, ax = plt.subplots(figsize=(6, 6), subplot_kw=dict(polar=True))
ax.plot(angles, values, linewidth=1, linestyle='solid')
ax.fill(angles, values, alpha=0.4)
plt.title('雷达图')
plt.show()
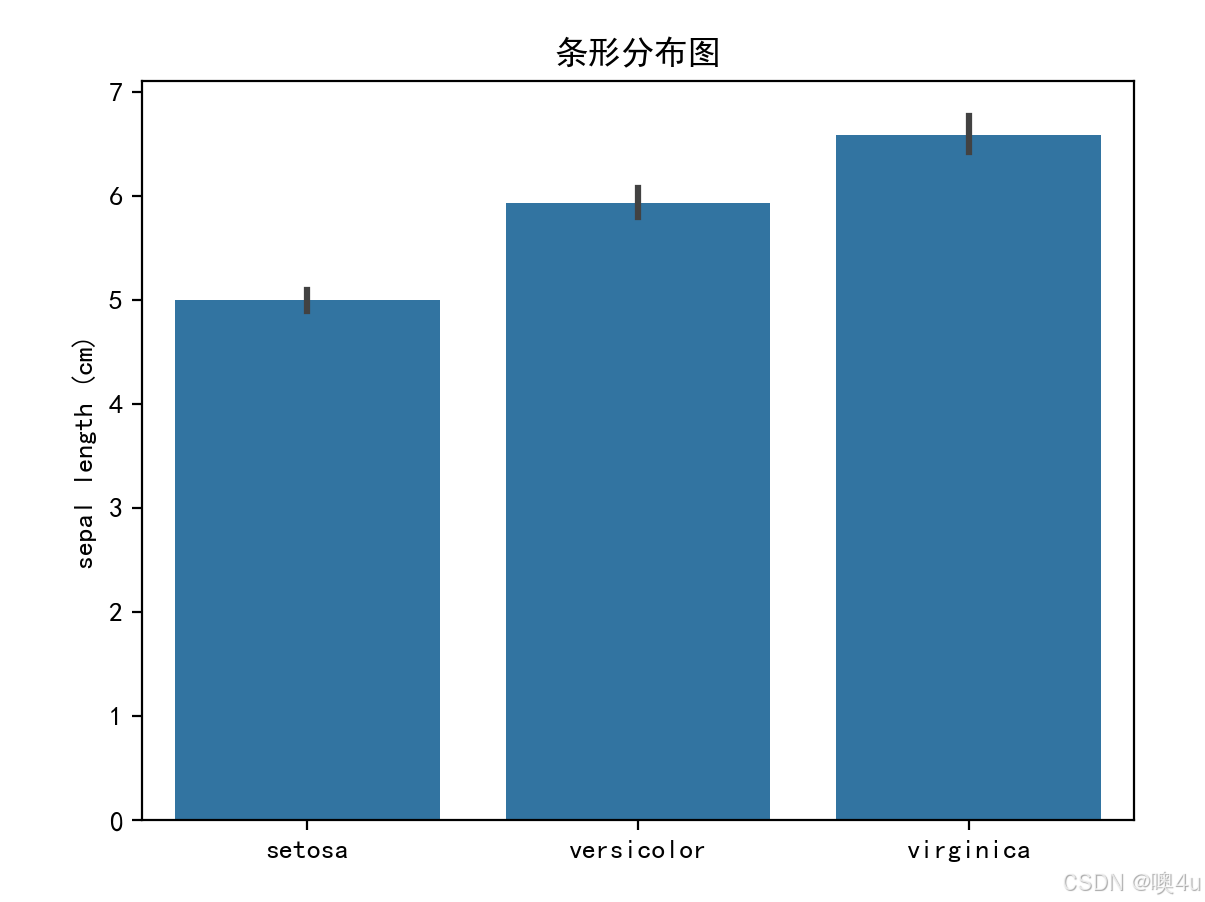
柱状图(Bar Chart)
条形分布图(Bar Plot)
条形图显示各类别之间的数量或平均值,适用于类别数据的可视化。
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
import pandas as pd
# 设置中文字体和负号显示
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 加载数据集
iris = load_iris()
df = pd.DataFrame(iris.data, columns=iris.feature_names)
# 条形图
sns.barplot(x=iris.target_names[iris.target], y='sepal length (cm)', data=df)
plt.title('条形分布图')
plt.show()
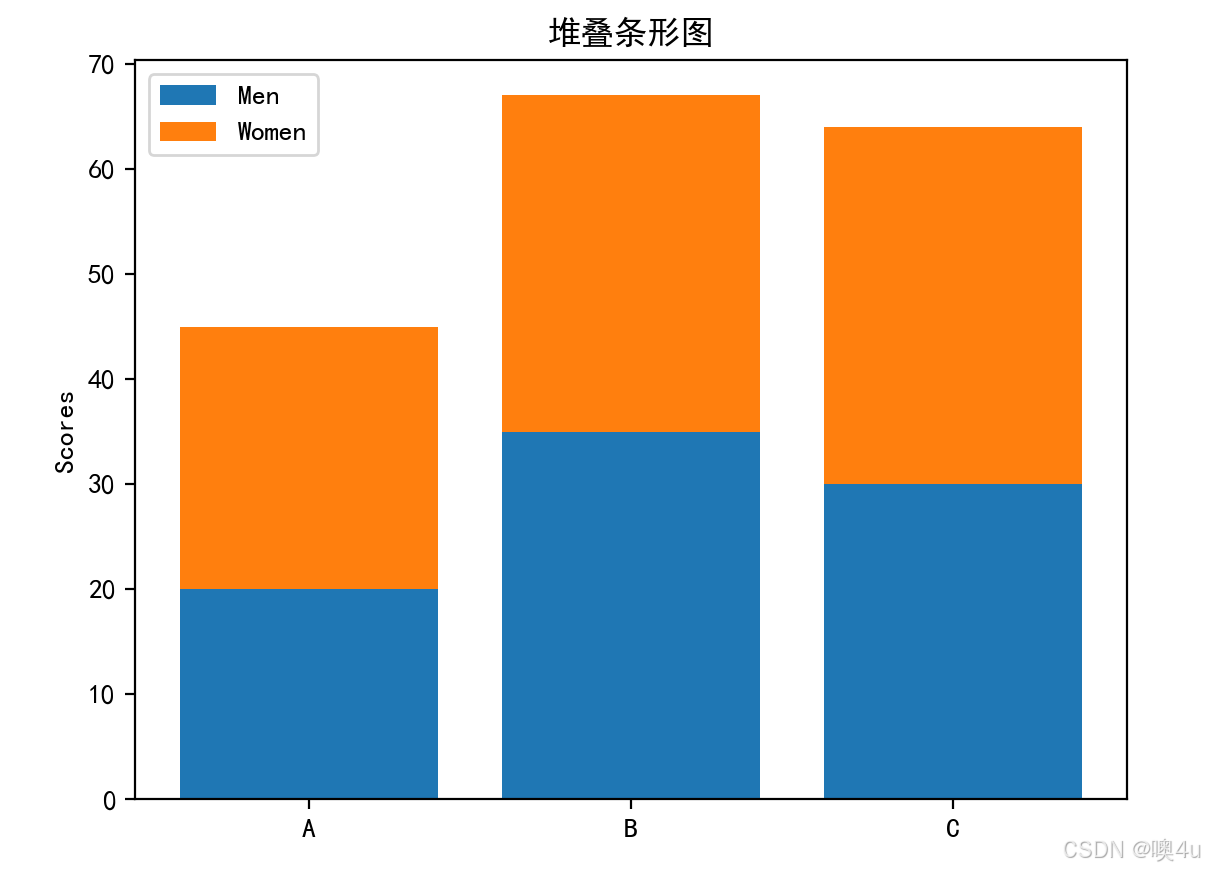
堆叠条形图(Stacked Bar Chart)
显示每一类别中各部分的叠加效果,适用于多个类别数据的对比。
import matplotlib.pyplot as plt
import numpy as np
# 设置中文字体和负号显示
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 伪数据
labels = ['A', 'B', 'C']
men_means = [20, 35, 30]
women_means = [25, 32, 34]
# 堆叠条形图
x = np.arange(len(labels)) # 标签位置
fig, ax = plt.subplots()
ax.bar(x, men_means, label='Men')
ax.bar(x, women_means, bottom=men_means, label='Women')
ax.set_ylabel('Scores')
ax.set_title('堆叠条形图')
ax.set_xticks(x)
ax.set_xticklabels(labels)
ax.legend()
plt.show()
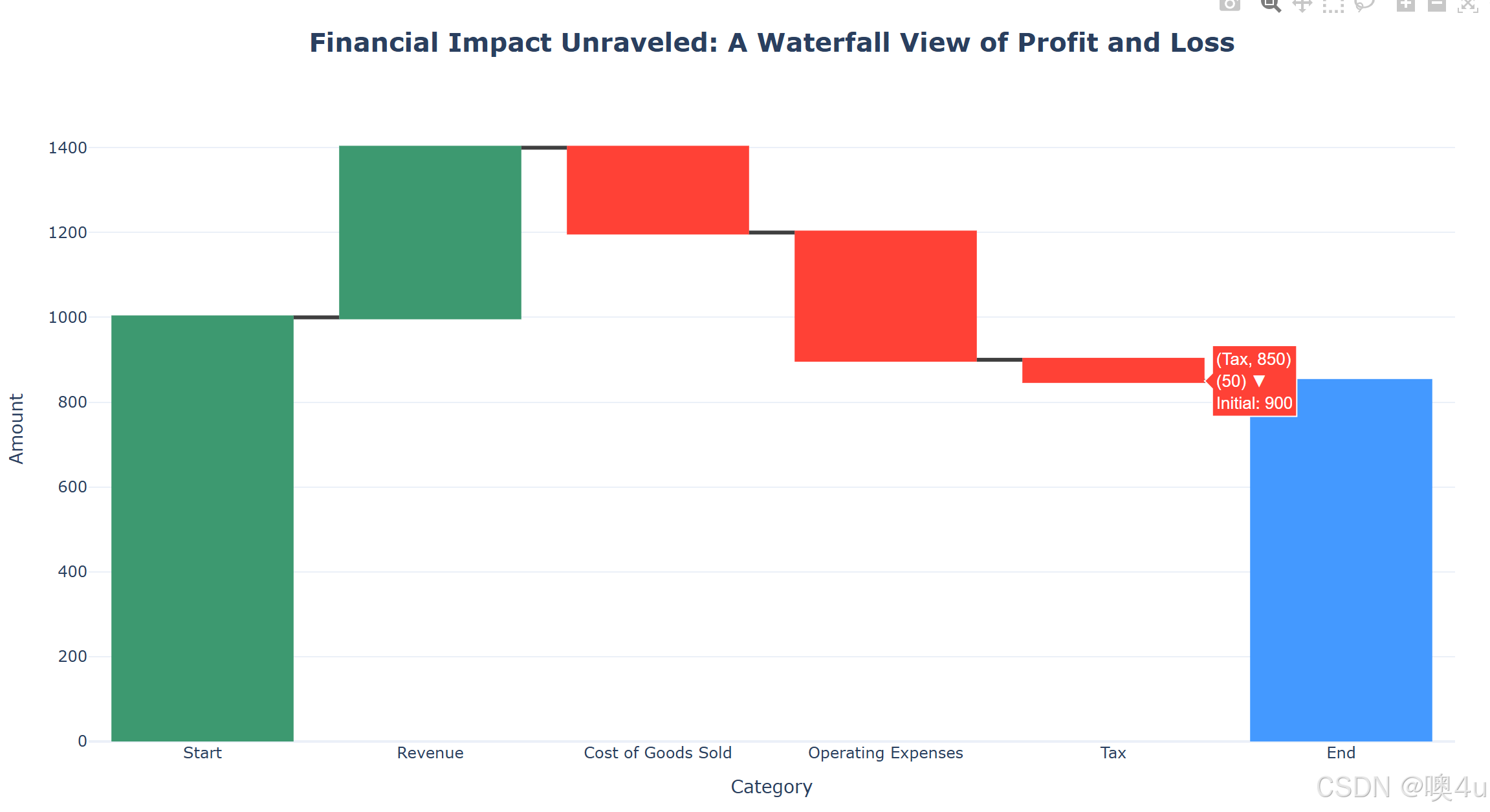
瀑布图(Waterfall Chart)
可以直观地了解数据从初始到最终的变化过程,并分析变化原因并对预测提供帮助
import pandas as pd
import plotly.graph_objects as go
# 示例数据
sample_data = {
'Category': ['Start', 'Revenue', 'Cost of Goods Sold', 'Operating Expenses', 'Tax', 'End'],
'Value': [1000, 400, -200, -300, -50, 850],
'Measure': ['relative', 'relative', 'relative', 'relative', 'relative', 'total']
}
df_chart = pd.DataFrame(sample_data)
# 创建瀑布图
fig = go.Figure(go.Waterfall(
name="Financials",
orientation="v",
measure=df_chart['Measure'],
x=df_chart['Category'],
y=df_chart['Value'],
connector={"line": {"color": "rgb(63, 63, 63)", "width": 3}}
))
# 自定义布局
fig.update_layout(
title_text='<b>Financial Impact Unraveled: A Waterfall View of Profit and Loss</b>',
title_font_size=20,
title_x=0.5, # 标题水平居中
template="plotly_white",
xaxis_title="Category",
yaxis_title="Amount"
)
# 显示图表
fig.show()
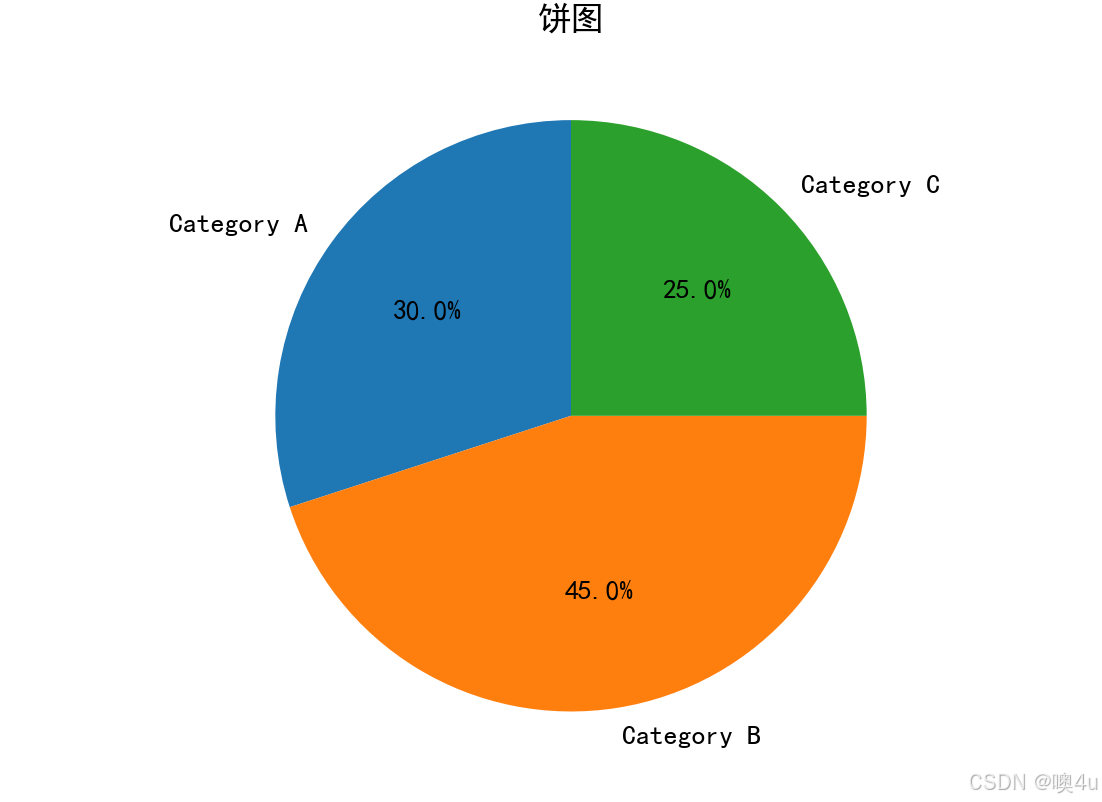
饼图(Pie Chart)
饼图显示数据各部分所占的比例,适用于类别数据的比例分析。
import matplotlib.pyplot as plt
# 设置中文字体和负号显示
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 伪数据:各类别的比例
labels = ['Category A', 'Category B', 'Category C']
sizes = [30, 45, 25]
# 饼图
plt.pie(sizes, labels=labels, autopct='%1.1f%%', startangle=90)
plt.title('饼图')
plt.show()
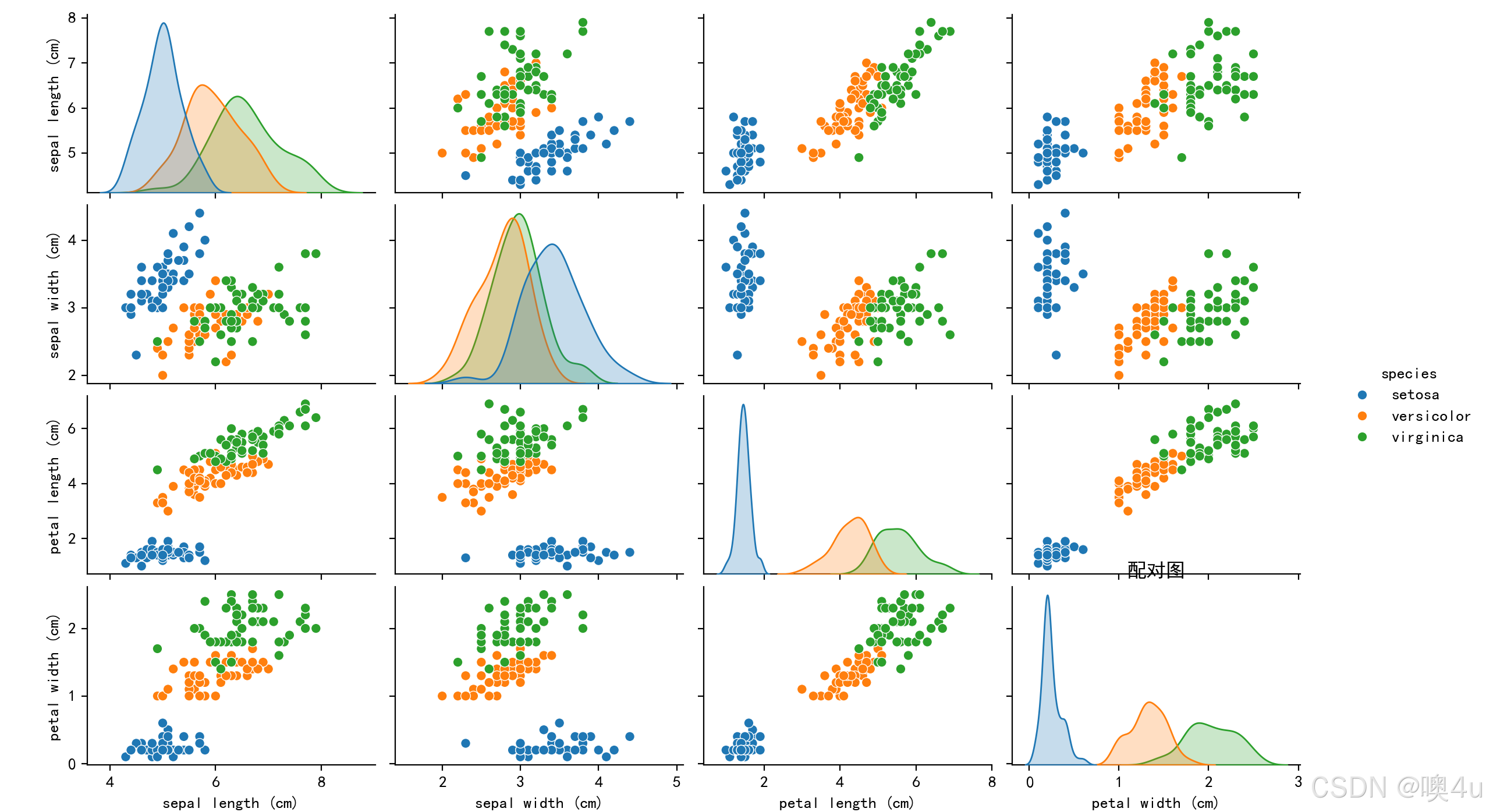
配对图(Pair Plot)
配对图展示了各特征之间的散点图以及分布情况,适合进行多变量数据的探索性分析。
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
import pandas as pd
# 设置中文字体和负号显示
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 加载数据集
iris = load_iris()
df = pd.DataFrame(iris.data, columns=iris.feature_names)
df['species'] = iris.target_names[iris.target]
# 配对图
sns.pairplot(df, hue='species')
plt.title('配对图')
plt.show()
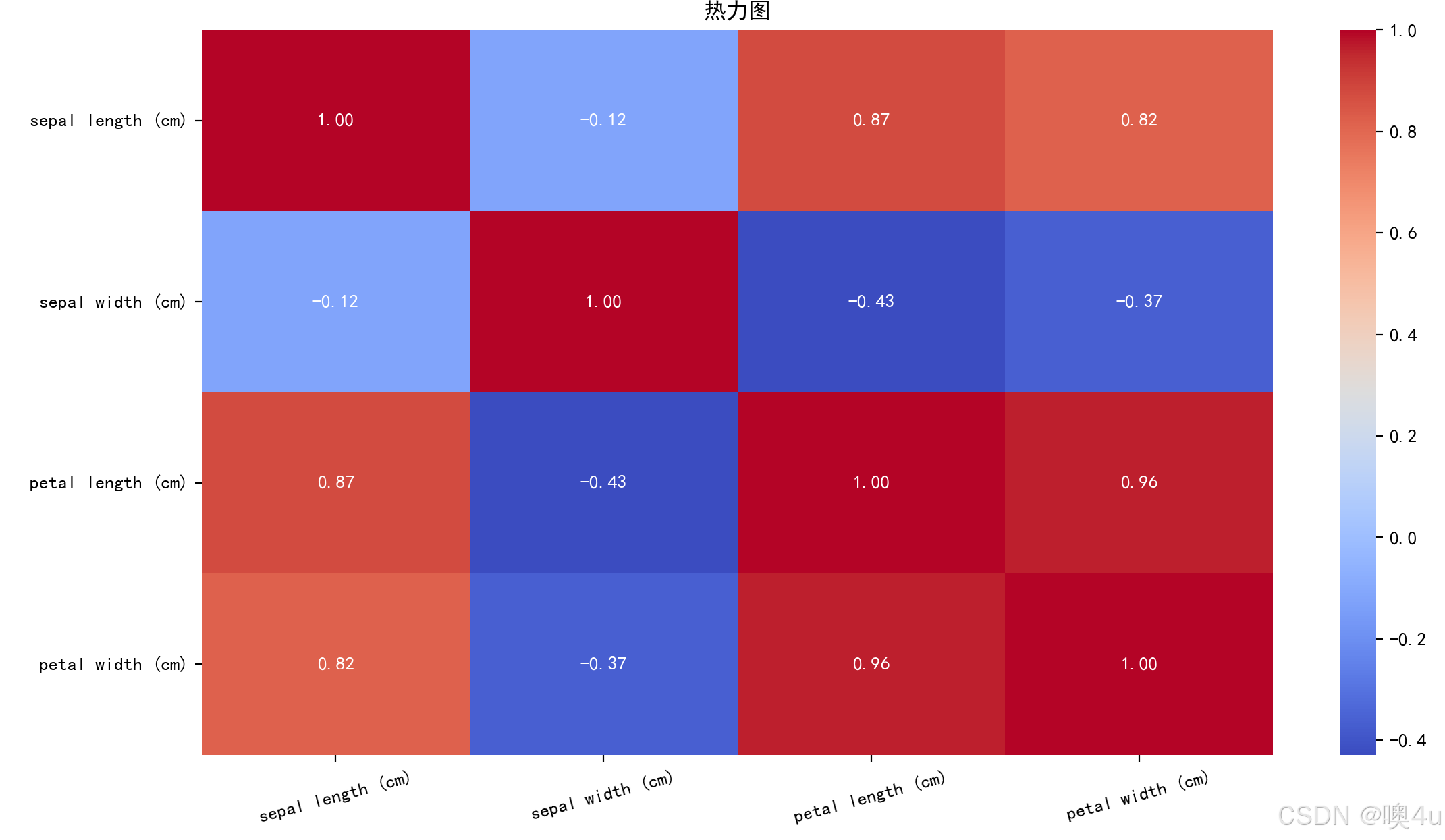
热力图(Heatmap)
热力图通过颜色展示数据的强度,常用于相关性矩阵、表格数据等。
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
import pandas as pd
# 设置中文字体和负号显示
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 生成伪数据:相关性矩阵
iris = load_iris()
df = pd.DataFrame(iris.data, columns=iris.feature_names)
corr = df.corr()
# 热力图
sns.heatmap(corr, annot=True, cmap='coolwarm', fmt='.2f')
plt.title('热力图')
plt.xticks(rotation=15)
plt.show()
对于数据较多的情况,可以设置“annot=False”去除图中的数字,仅展示每个方格的颜色: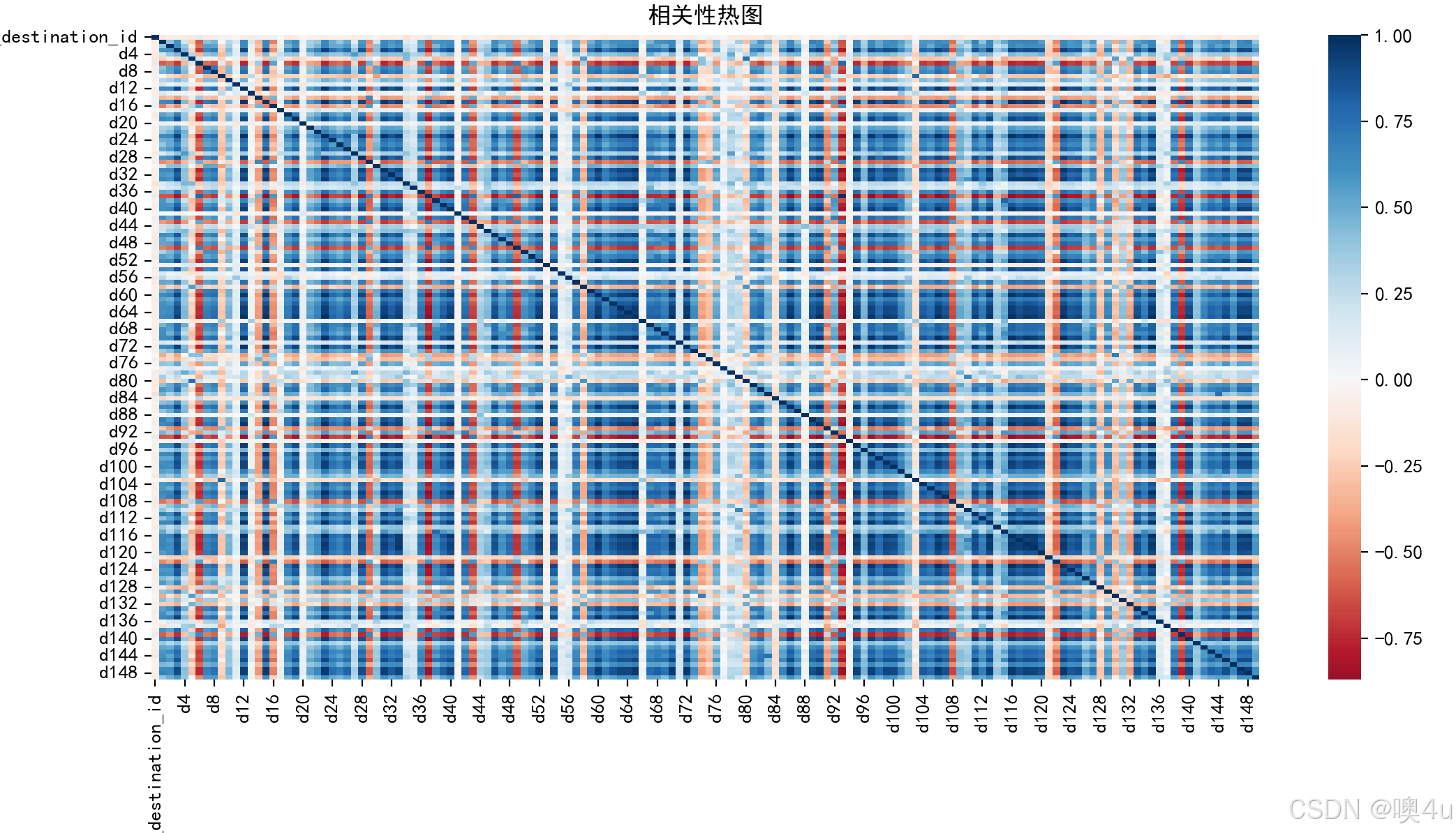
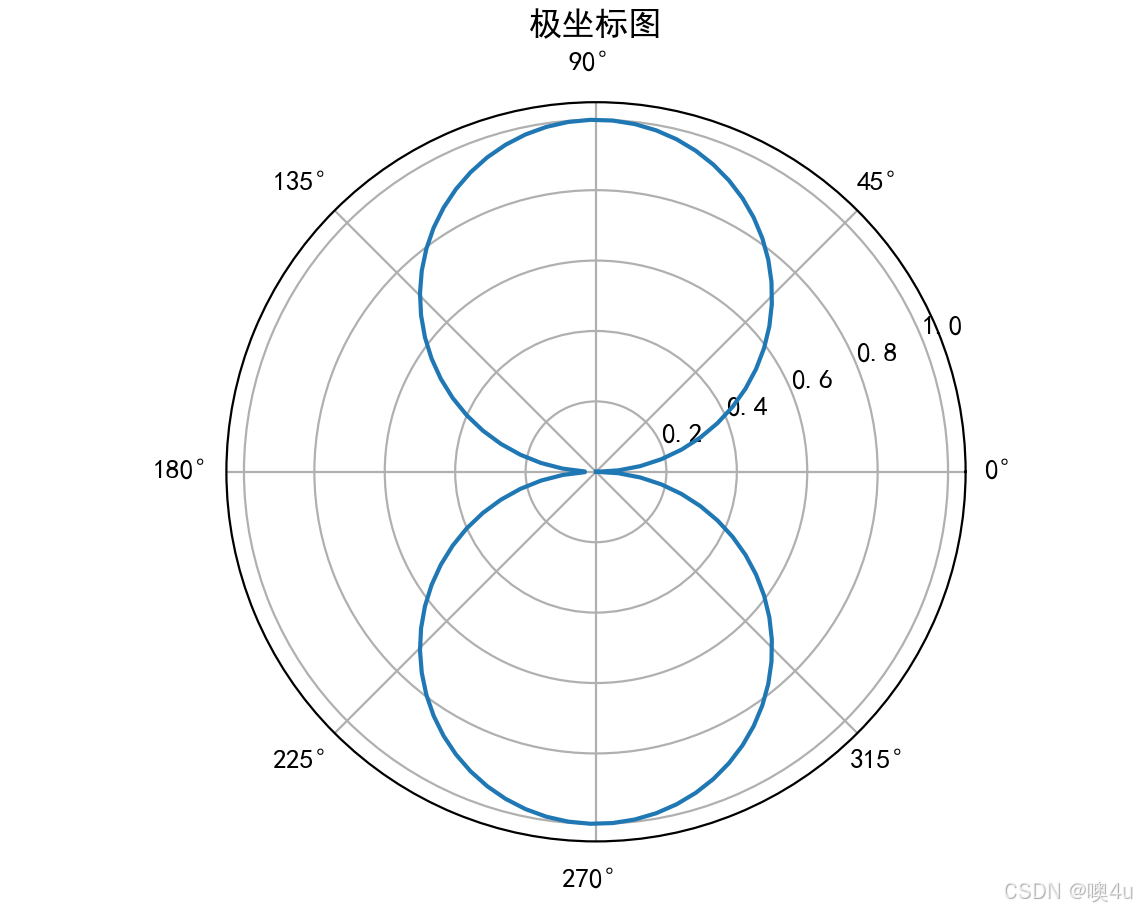
极坐标图(Polar Plot)
在极坐标系中展示数据,常用于周期性数据的可视化,如风速、方向等。
import matplotlib.pyplot as plt
import numpy as np
# 设置中文字体和负号显示
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 伪数据
theta = np.linspace(0, 2*np.pi, 100)
r = np.abs(np.sin(theta))
# 极坐标图
plt.subplot(111, projection='polar')
plt.plot(theta, r)
plt.title('极坐标图')
plt.show()
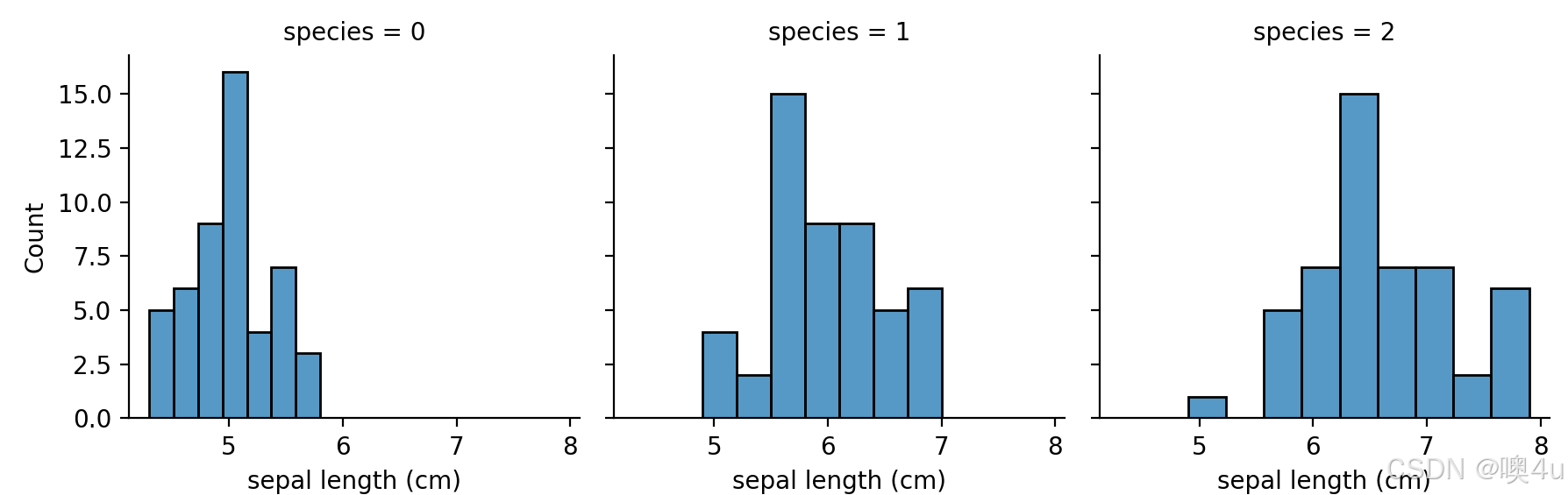
分面图(Facet Grid)
将不同的子图展示在一个网格中,适合展示不同条件下的多个子图(subplot)。
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
import pandas as pd
# 加载数据集
iris = load_iris()
df = pd.DataFrame(iris.data, columns=iris.feature_names)
df['species'] = iris.target
# 分面图
g = sns.FacetGrid(df, col="species")
g.map(sns.histplot, "sepal length (cm)")
plt.show()
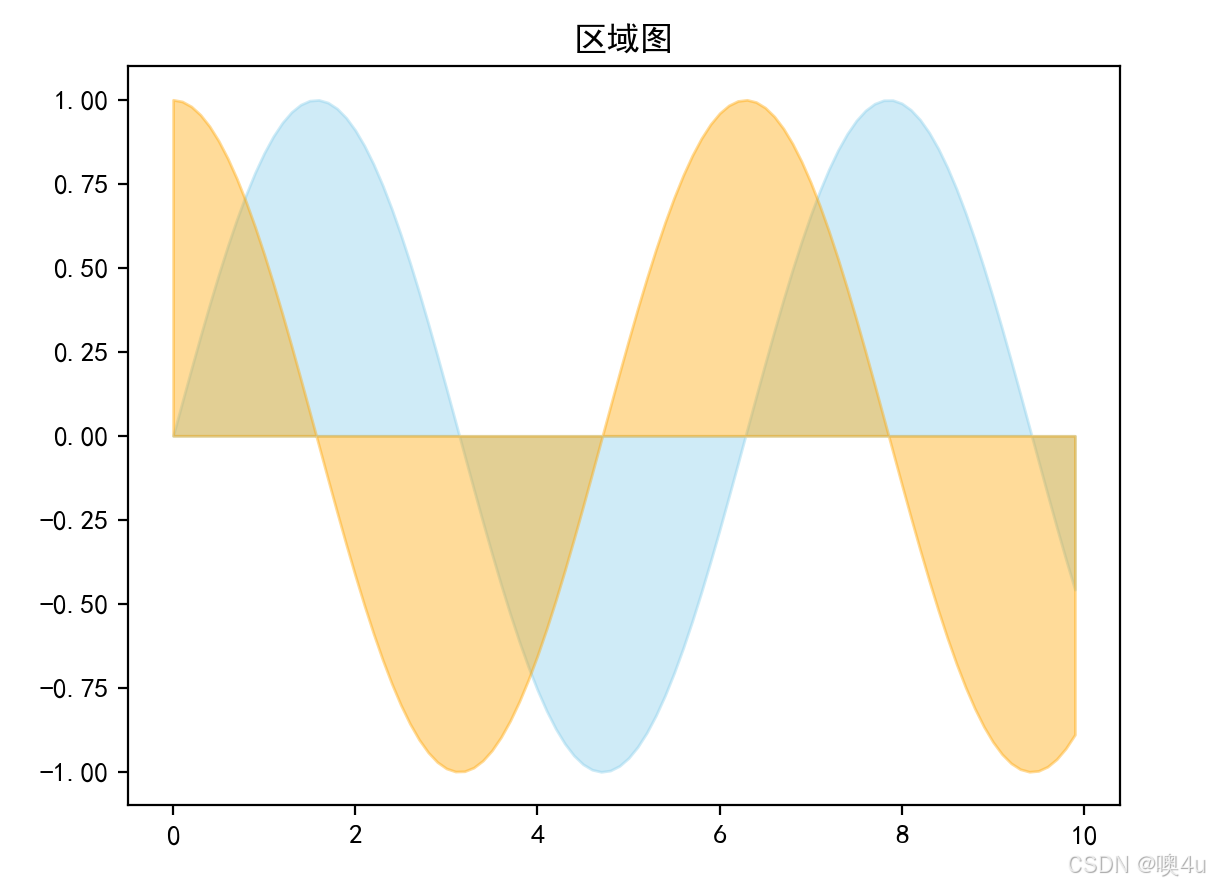
区域图(Area Chart)
展示两条(或多条)曲线围出的区域。
import matplotlib.pyplot as plt
import numpy as np
# 设置中文字体和负号显示
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 伪数据
x = np.arange(0, 10, 0.1)
y1 = np.sin(x)
y2 = np.cos(x)
# 区域图
plt.fill_between(x, y1, color="skyblue", alpha=0.4)
plt.fill_between(x, y2, color="orange", alpha=0.4)
plt.title('区域图')
plt.show()
地图可视化(Choropleth Map)
以下仅提供几种绘制真实地图(世界范围、七大州范围、地区范围)的方法,可以直接修改代码在这些图上绘制散点图、等高线图等等,但数据和位置信息需自行寻找合适的使用。或者不使用plotly库的这种绘制地图方法,直接将图片作为背景,使用上文提到的“在图片中加入背景图”的方式。
import plotly.express as px
df = px.data.gapminder().query("year==2007")
fig = px.scatter_geo(df, locations='iso_alpha', color='continent',
hover_name='country', size='pop',
projection='natural earth', title='2007年全球人口分布')
fig.show()
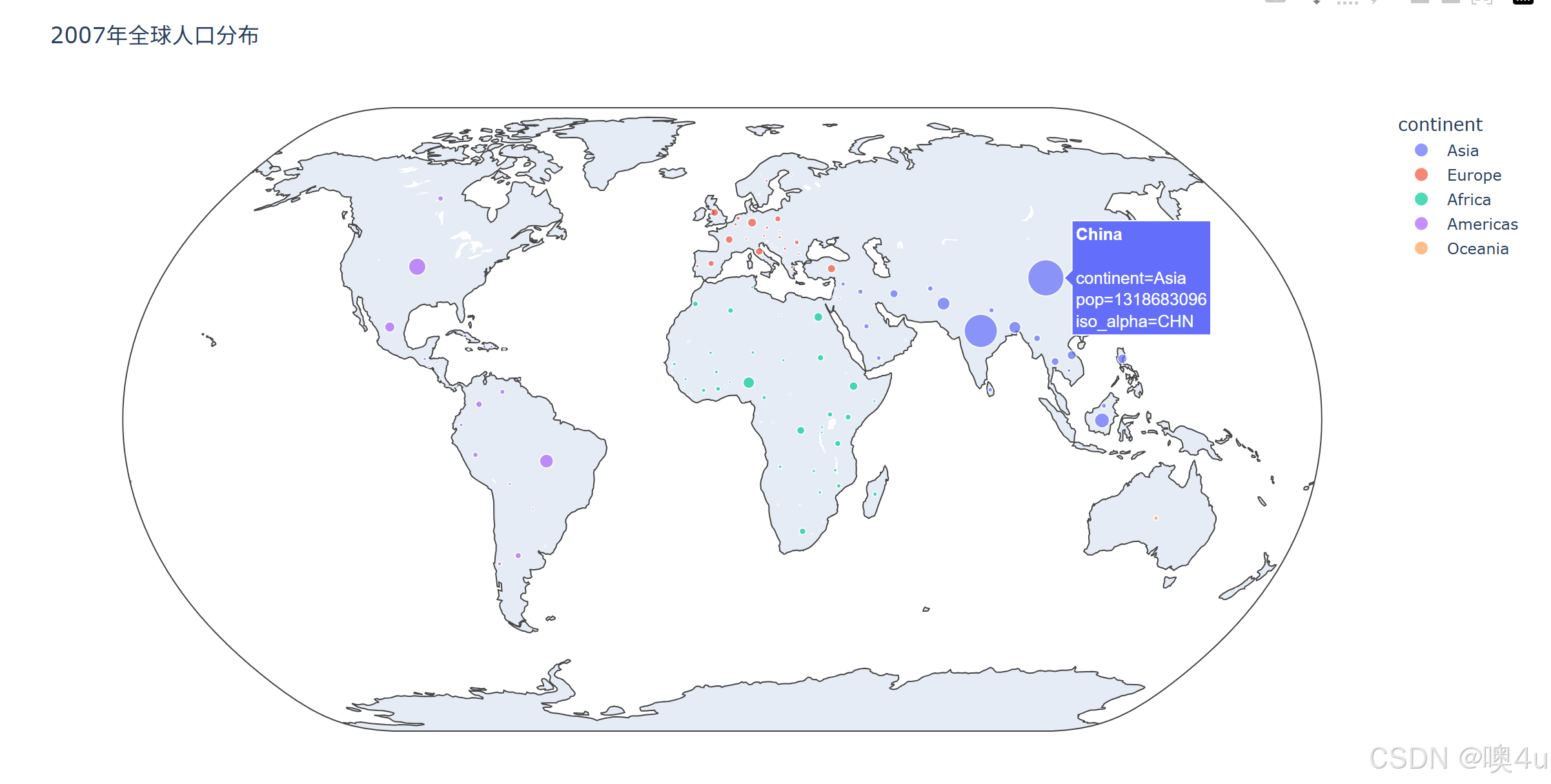
当然还有不同的projection投影方式:
-
Mercator(墨卡托投影)
- 描述:广泛用于网络地图服务(如 Google Maps)。在赤道附近保持形状和角度的准确性,但极地区域会被夸大。
- 用途:导航和在线地图。
-
Natural Earth(自然地球投影)
- 描述:旨在展示全球的整体形状,减少面积和形状的失真。适用于世界地图展示。
- 用途:全球概览、学术和教育用途。
-
Orthographic(正投影)
- 描述:类似于从太空观察地球的视角,只显示地球的一半,具有三维效果。
- 用途:视觉效果展示、地球仪效果。
-
Miller(米勒投影)
- 描述:介于墨卡托投影和自然地球投影之间,减少了极地区域的失真。
- 用途:世界地图展示,替代墨卡托投影。
-
Equirectangular(等距矩形投影)
- 描述:将纬度和经度以等距比例映射到矩形平面上,保持纬度和经度的比例,但形状和面积失真。
- 用途:简单的地图展示,基础地图绘制。
-
Robinson(罗宾逊投影)
- 描述:一种伪圆形投影,平衡形状和面积的失真,常用于教育和出版物。
- 用途:世界地图展示,教育用途。
-
Albers Conic(阿尔伯斯圆锥投影)
- 描述:适用于展示中纬度地区,保持形状和面积的准确性。
- 用途:国家或区域级别的地图展示,特别是中纬度国家如美国。
-
Azimuthal Equidistant(方位等距投影)
- 描述:从一个点出发,保持距离的准确性,适用于无线电广播和飞行路线。
- 用途:特定点的距离测量,航空航天。
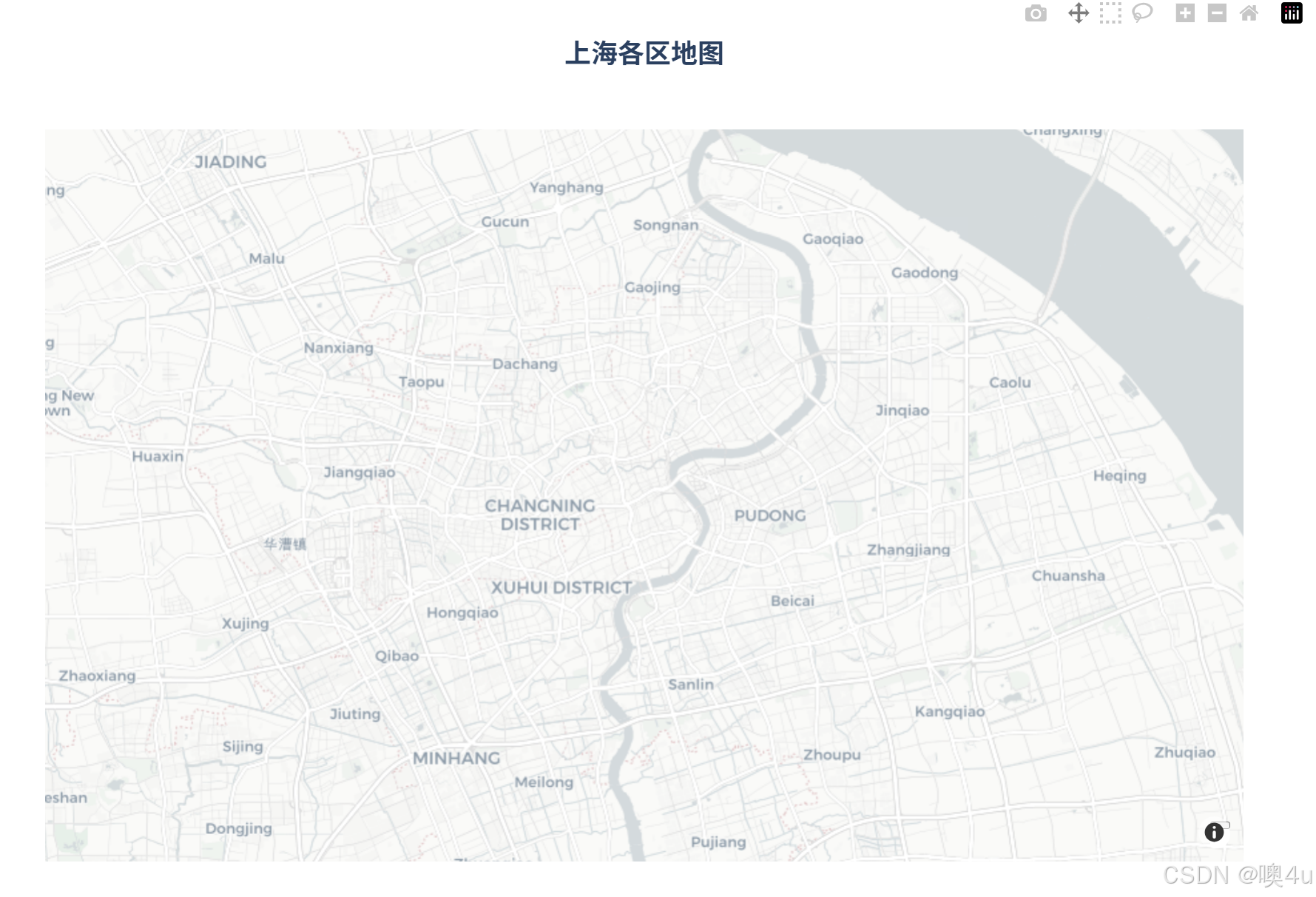
使用px.choropleth.mapbox
地区范围:mapbox,需指定展示的中心的经纬度坐标值。
import plotly.express as px
import pandas as pd
import json
# 1. 创建 Choropleth Mapbox 图表
fig = px.choropleth_mapbox(
mapbox_style="carto-positron", # 地图样式
zoom=10, # 缩放级别
center={"lat": 31.2304, "lon": 121.4737}, # 地图中心点(上海坐标)
opacity=0.6, # 颜色填充透明度
labels={'population':'人口数量'}, # 标签
title='上海地图' # 图表标题
)
# 2. 自定义布局
fig.update_layout(
title_text='<b>上海各区地图</b>',
title_font_size=20,
title_x=0.5, # 标题水平居中
template="plotly_white", # 使用白色背景模板
margin=dict(t=100, l=50, r=50, b=50), # 调整边距
height=700, # 图表高度
width=1000 # 图表宽度
)
# 3. 显示图表
fig.show()
使用plotly.go.Scattergeo
七大洲范围:可选择展示陆地、海洋、投影方式等等
import pandas as pd
import plotly.graph_objects as go
from geopy.geocoders import Nominatim
import time
# # 初始化地理编码器
# geolocator = Nominatim(user_agent="geoapiExercises")
# # 亚洲国家及其首都列表
# capital_data = {
# '国家': [
# '日本', '中国', '印度', '韩国', '泰国',
# '印度尼西亚', '马来西亚', '新加坡', '越南', '巴基斯坦',
# '阿联酋', '伊朗', '土耳其', '阿曼', '科威特',
# '伊拉克', '菲律宾', '伊朗', '阿富汗', '孟加拉国'
# ],
# '首都': [
# '东京', '北京', '新德里', '首尔', '曼谷',
# '雅加达', '吉隆坡', '新加坡', '河内', '伊斯兰堡',
# '迪拜', '德黑兰', '安卡拉', '马斯喀特', '科威特城',
# '巴格达', '马尼拉', '德黑兰', '喀布尔', '达卡'
# ]
# }
# df_capitals = pd.DataFrame(capital_data)
# # 获取经纬度
# def get_coordinates(city, country):
# try:
# location = geolocator.geocode(f"{city}, {country}", timeout=10)
# if location:
# return location.longitude, location.latitude
# else:
# return None, None
# except:
# return None, None
# # 添加经度和纬度列
# df_capitals['经度'] = None
# df_capitals['纬度'] = None
# for index, row in df_capitals.iterrows():
# lon, lat = get_coordinates(row['首都'], row['国家'])
# df_capitals.at[index, '经度'] = lon
# df_capitals.at[index, '纬度'] = lat
# print(f"获取 {row['国家']} 的首都 {row['首都']} 坐标: 经度={lon}, 纬度={lat}")
# time.sleep(1) # 延时以遵守服务条款
# # 删除无法获取坐标的行
# df_capitals.dropna(subset=['经度', '纬度'], inplace=True)
# # 示例数值(这里使用人口数据,实际应用中请使用真实数据)
# # 这里我们假设每个首都有一个示例数值,可以根据需要替换
# df_capitals['数值'] = [
# 37400068, 21540000, 30236350, 9776000, 8281000,
# 10770487, 8083000, 5704000, 8000000, 12460688,
# 3331420, 8846782, 5503985, 1650000, 2735000,
# 3109076, 1780148, 8846782, 4273156, 2061542
# ]
data = {
'地点': [
'东京', '北京', '新德里', '首尔', '曼谷',
'雅加达', '吉隆坡', '新加坡', '河内', '卡拉奇',
'迪拜', '德里', '伊斯兰堡', '喀布尔', '马尼拉',
'伊斯坦布尔', '阿曼', '科威特城', '巴格达', '德黑兰'
],
'经度': [
139.6917, 116.4074, 77.2090, 126.9780, 100.5018,
106.8456, 101.6869, 103.8198, 105.8342, 67.0099,
55.2708, 77.1025, 73.0479, 69.2075, 120.9842,
28.9784, 58.3816, 47.4818, 44.3615, 51.3890
],
'纬度': [
35.6895, 39.9042, 28.6139, 37.5665, 13.7563,
-6.2088, 3.1390, 1.3521, 21.0285, 24.8607,
25.2048, 28.7041, 33.6844, 34.5553, 14.5995,
41.0082, 23.8859, 29.3759, 33.3152, 35.6892
],
'数值': [
37400068, 21540000, 30236350, 9776000, 8281000,
10770487, 8083000, 5704000, 8000000, 15741000,
3331420, 30236350, 12460688, 4273156, 1780148,
15462452, 789000, 4270000, 3500000, 8846782
]
}
df_capitals = pd.DataFrame(data)
# 创建 Scattergeo 图
fig = go.Figure(go.Scattergeo(
lon = df_capitals['经度'],
lat = df_capitals['纬度'],
text = df_capitals['地点'] + '<br>人口: ' + df_capitals['数值'].astype(str),
marker = dict(
size = df_capitals['数值'] / 1000000, # 调整大小比例,例如每100万人一个单位
color = df_capitals['数值'],
colorscale = 'YlOrRd',
showscale = True,
colorbar_title = "人口数量",
line = dict(width=0.5, color='black') # 为散点添加边框
)
))
# 更新布局
fig.update_layout(
title_text='<b>亚洲各国首都人口分布</b>',
title_font_size=20,
title_x=0.5, # 标题水平居中
template="plotly_white", # 使用白色背景模板
geo = dict(
scope='asia',
# geo_center=dict(lon=121.4737, lat=31.2304), # 展示中心的经纬度
projection_type='natural earth', # 自然地球投影
showland = True,
landcolor = "LightGray",
countrycolor = "Gray",
coastlinecolor = "Black",
showocean = True,
oceancolor = "LightBlue",
),
height=700,
width=1000
)
# 显示图表
fig.show()
The 'scope' property is an enumeration that may be specified as:
- One of the following enumeration values:
['africa', 'asia', 'europe', 'north america', 'south
america', 'usa', 'world']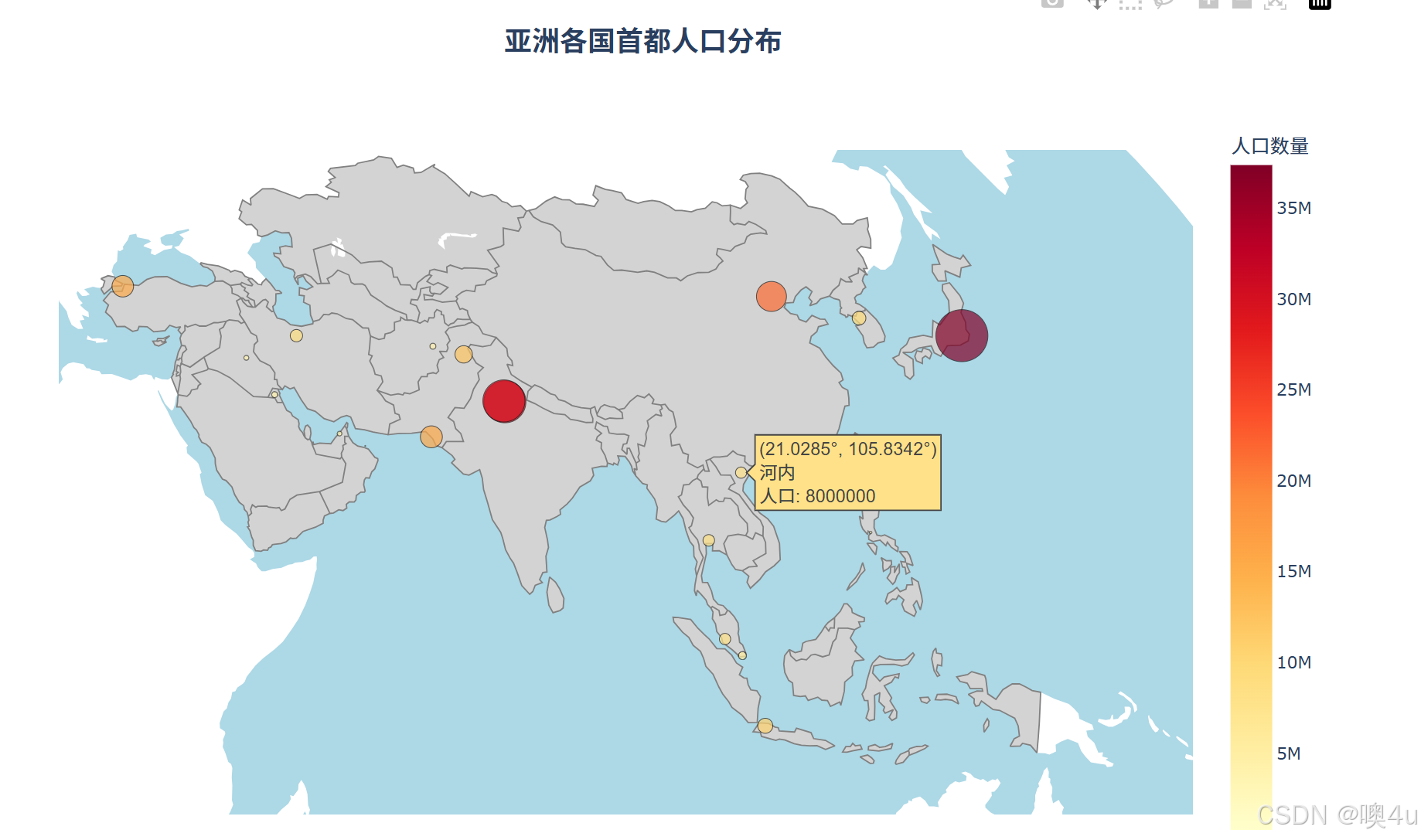
使用Shapefile
import pandas as pd
import geopandas as gpd
import matplotlib.pyplot as plt
from matplotlib.colors import ListedColormap
from matplotlib.patches import Patch
# 加载数据
df = pd.read_csv(r"奥运会奖牌数量.csv")
# 分段上色条件
bins = [0, 10, 50, 100, 200, 500, 1000, float('inf')]
labels = ['1-10', '10-50', '50-100', '100-200', '200-500', '500-1000', '1000+']
colors = ['#f7fbff', '#deebf7', '#c6dbef', '#9ecae1', '#6baed6', '#4292c6', '#2171b5']
medal_totals['Color_Category'] = pd.cut(medal_totals['Total'], bins=bins, labels=labels, right=False)
cmap = ListedColormap(colors)
# 指定你下载并解压的Shapefile路径
path_to_shapefile = r".\ne_110m_admin_0_countries\ne_110m_admin_0_countries.shp"
world = gpd.read_file(path_to_shapefile)
# 确保你的国家名匹配地图数据中的国家名
world = world.merge(medal_totals, how="left", left_on="NAME", right_on="NOC")
# 绘制地图
fig, ax = plt.subplots(1, 1, figsize=(15, 10))
world.boundary.plot(ax=ax)
world_map = world.plot(column='Color_Category', ax=ax, cmap=cmap, legend=False)
# 创建图例
legend_labels = [Patch(facecolor=color, label=label) for color, label in zip(colors, labels)]
ax.legend(handles=legend_labels, title="Medal Count Ranges", loc='lower left')
plt.axis('off') # 隐藏坐标轴
plt.show()
 Shapefile中包含的176个国家名Natural Earth - Free vector and raster map data at 1:10m, 1:50m, and 1:110m scales
Shapefile中包含的176个国家名Natural Earth - Free vector and raster map data at 1:10m, 1:50m, and 1:110m scales
0 Fiji
1 Tanzania
2 W. Sahara
3 Canada
4 United States of America
5 Kazakhstan
6 Uzbekistan
7 Papua New Guinea
8 Indonesia
9 Argentina
10 Chile
11 Dem. Rep. Congo
12 Somalia
13 Kenya
14 Sudan
15 Chad
16 Haiti
17 Dominican Rep.
18 Russia
19 Bahamas
20 Falkland Is.
21 Norway
22 Greenland
23 Fr. S. Antarctic Lands
24 Timor-Leste
25 South Africa
26 Lesotho
27 Mexico
28 Uruguay
29 Brazil
30 Bolivia
31 Peru
32 Colombia
33 Panama
34 Costa Rica
35 Nicaragua
36 Honduras
37 El Salvador
38 Guatemala
39 Belize
40 Venezuela
41 Guyana
42 Suriname
43 France
44 Ecuador
45 Puerto Rico
46 Jamaica
47 Cuba
48 Zimbabwe
49 Botswana
50 Namibia
51 Senegal
52 Mali
53 Mauritania
54 Benin
55 Niger
56 Nigeria
57 Cameroon
58 Togo
59 Ghana
60 Côte d'Ivoire
61 Guinea
62 Guinea-Bissau
63 Liberia
64 Sierra Leone
65 Burkina Faso
66 Central African Rep.
67 Congo
68 Gabon
69 Eq. Guinea
70 Zambia
71 Malawi
72 Mozambique
73 eSwatini
74 Angola
75 Burundi
76 Israel
77 Lebanon
78 Madagascar
79 Palestine
80 Gambia
81 Tunisia
82 Algeria
83 Jordan
84 United Arab Emirates
85 Qatar
86 Kuwait
87 Iraq
88 Oman
89 Vanuatu
90 Cambodia
91 Thailand
92 Laos
93 Myanmar
94 Vietnam
95 North Korea
96 South Korea
97 Mongolia
98 India
99 Bangladesh
100 Bhutan
101 Nepal
102 Pakistan
103 Afghanistan
104 Tajikistan
105 Kyrgyzstan
106 Turkmenistan
107 Iran
108 Syria
109 Armenia
110 Sweden
111 Belarus
112 Ukraine
113 Poland
114 Austria
115 Hungary
116 Moldova
117 Romania
118 Lithuania
119 Latvia
120 Estonia
121 Germany
122 Bulgaria
123 Greece
124 Turkey
125 Albania
126 Croatia
127 Switzerland
128 Luxembourg
129 Belgium
130 Netherlands
131 Portugal
132 Spain
133 Ireland
134 New Caledonia
135 Solomon Is.
136 New Zealand
137 Australia
138 Sri Lanka
139 China
140 Taiwan
141 Italy
142 Denmark
143 United Kingdom
144 Iceland
145 Azerbaijan
146 Georgia
147 Philippines
148 Malaysia
149 Brunei
150 Slovenia
151 Finland
152 Slovakia
153 Czechia
154 Eritrea
155 Japan
156 Paraguay
157 Yemen
158 Saudi Arabia
159 Antarctica
160 N. Cyprus
161 Cyprus
162 Morocco
163 Egypt
164 Libya
165 Ethiopia
166 Djibouti
167 Somaliland
168 Uganda
169 Rwanda
170 Bosnia and Herz.
171 North Macedonia
172 Serbia
173 Montenegro
174 Kosovo
175 Trinidad and Tobago
176 S. Sudan
Name: NAME, dtype: object平行坐标图(Parallel Coordinates)
用于多变量的可视化,适合于展示每个样本在多个变量维度下的分布情况。
import pandas as pd
import numpy as np
from pandas.plotting import parallel_coordinates
import matplotlib.pyplot as plt
# 生成伪数据
df = pd.DataFrame({
'feature1': np.random.rand(10),
'feature2': np.random.rand(10),
'feature3': np.random.rand(10),
'class': np.random.choice(['A', 'B'], 10)
})
# 平行坐标图
parallel_coordinates(df, 'class', color=('#556270', '#4ECDC4'))
plt.title('Parallel Coordinates')
plt.show()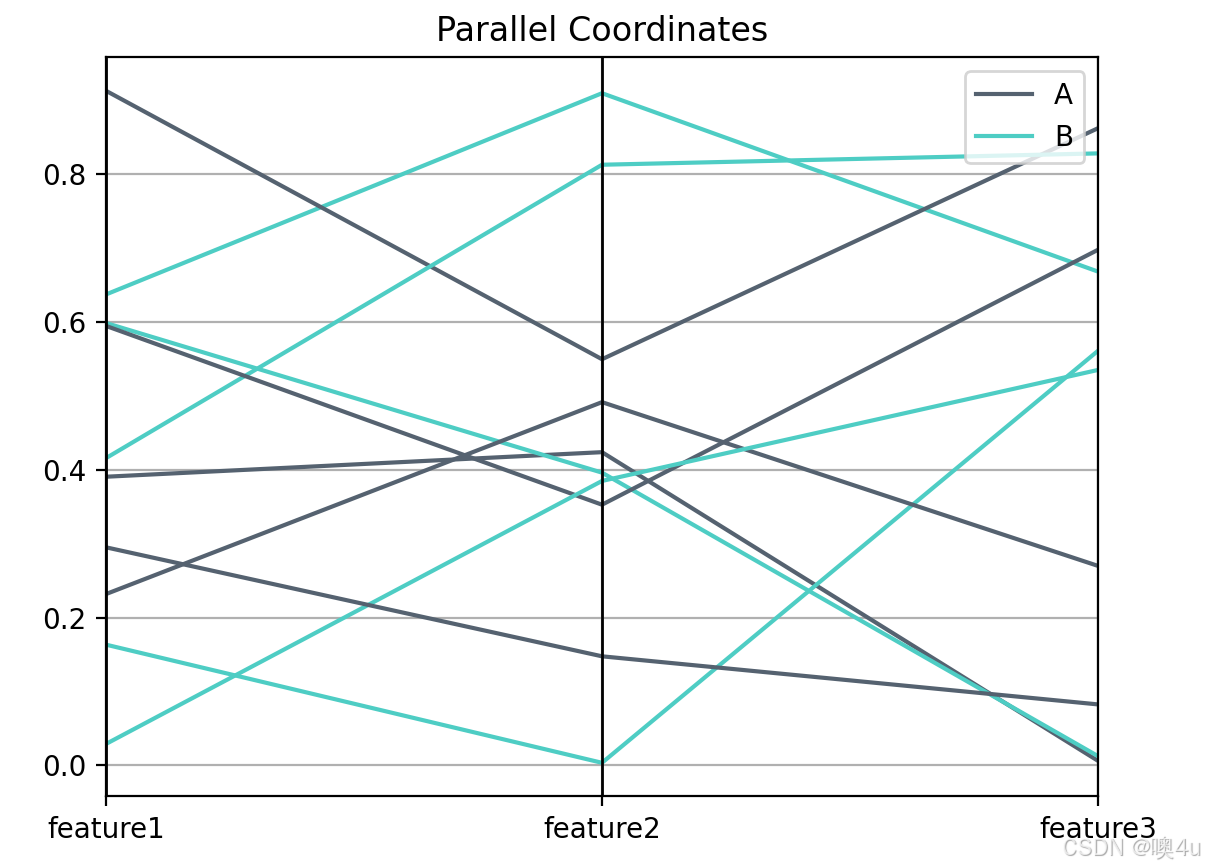
漏斗图(Funnel Chart)
主要用于展示一个流程中的各阶段数据,适用于转换率的分析,常用于营销、销售等领域。具体实现用横的条形图模拟。
import matplotlib.pyplot as plt
# 伪数据:每个阶段的数量
stages = ['Stage 1', 'Stage 2', 'Stage 3', 'Stage 4']
values = [100, 80, 60, 40]
# 漏斗图(通过条形图模拟)
plt.barh(stages, values, color='skyblue')
plt.title('Funnel Chart')
plt.xlabel('Number of Users')
plt.show()
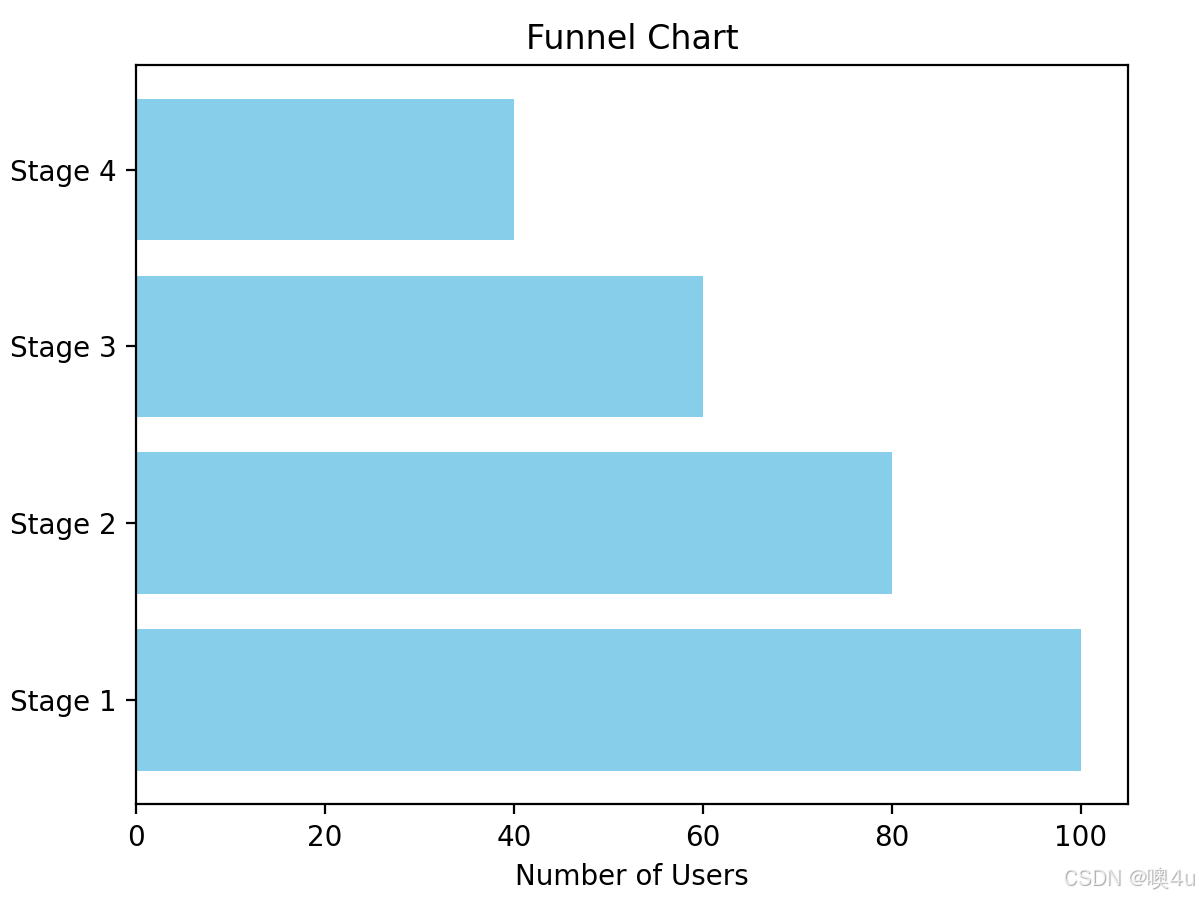
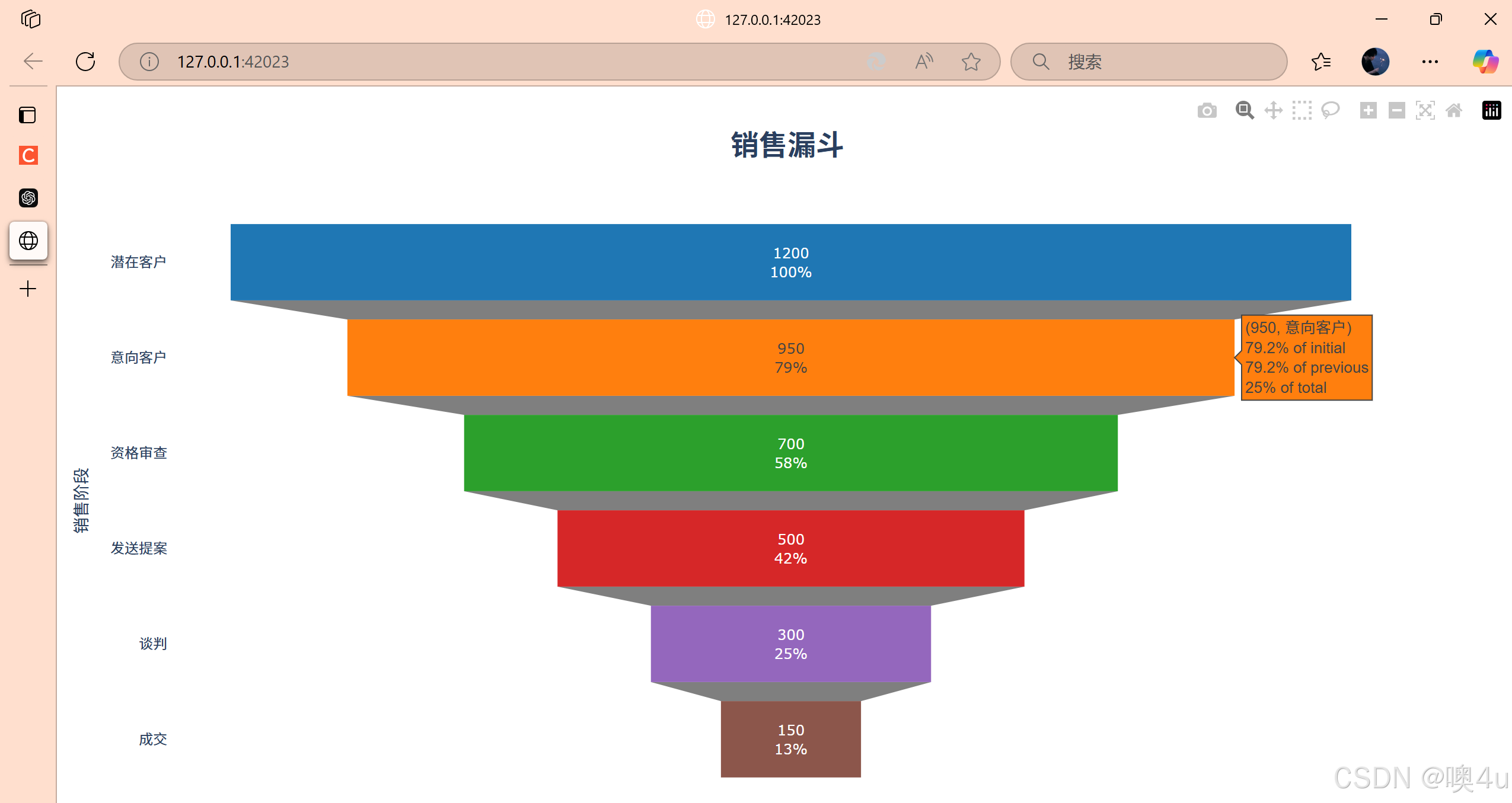
此外,还有Plotly库,会在默认浏览器中显示交互式漏斗图:
import plotly.graph_objects as go
# 定义流程的各个阶段及其对应的值
stages = ['潜在客户', '意向客户', '资格审查', '发送提案', '谈判', '成交']
values = [1200, 950, 700, 500, 300, 150]
# 为每个阶段定义自定义颜色
colors = ['#1f77b4', '#ff7f0e', '#2ca02c', '#d62728', '#9467bd', '#8c564b']
# 使用Plotly创建漏斗图,并应用自定义颜色
fig = go.Figure(go.Funnel(
y=stages,
x=values,
textinfo="value+percent initial",
textposition="inside",
marker=dict(color=colors) # 设置自定义颜色
))
# 自定义布局
fig.update_layout(
title_text='<b>销售漏斗</b>',
title_font_size=24,
title_x=0.5,
xaxis_title="客户数量",
yaxis_title="销售阶段",
template="plotly_white" # 使用白色背景模板
)
# 显示图表
fig.show()
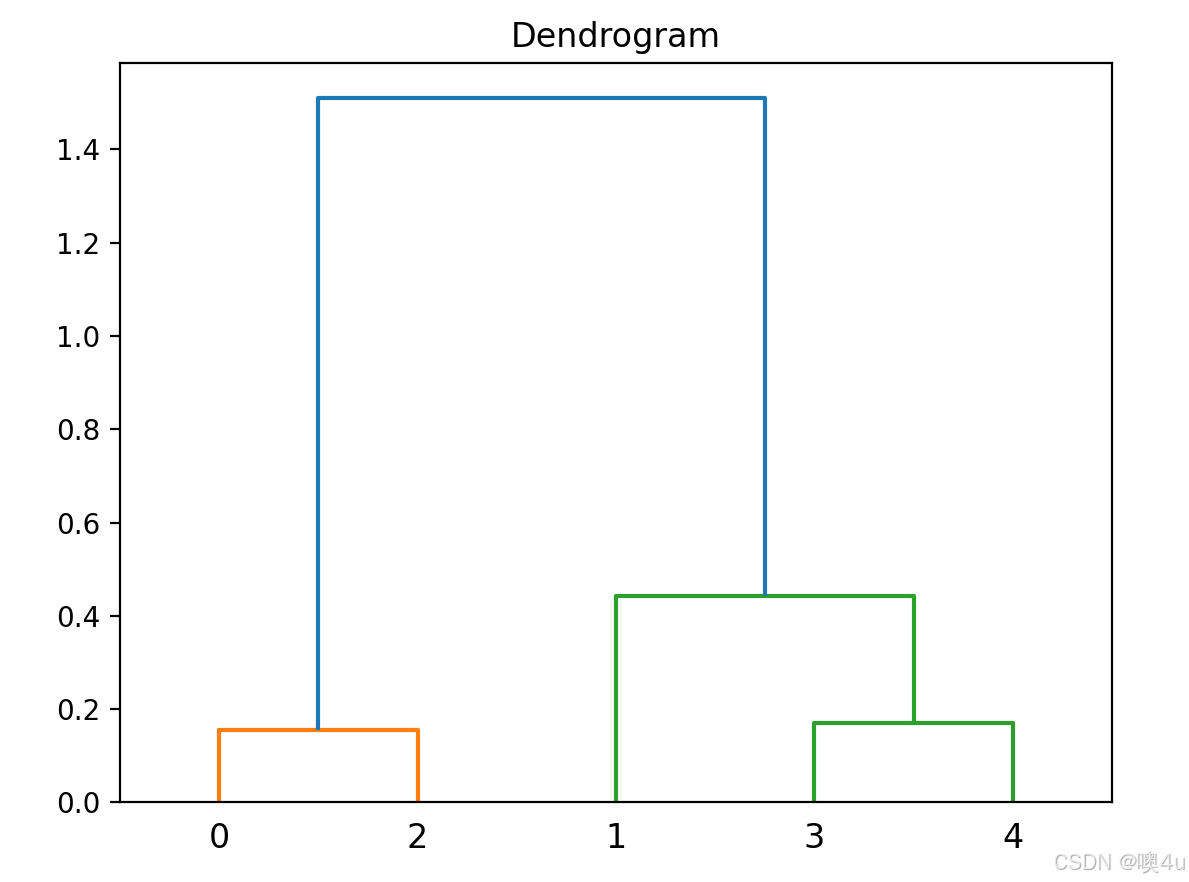
树状图(Dendrogram)
展示数据层级关系,常用于聚类分析。
import scipy.cluster.hierarchy as sch
import numpy as np
import matplotlib.pyplot as plt
# 伪数据
data = np.random.rand(5, 3)
# 树状图
sch.dendrogram(sch.linkage(data, method='ward'))
plt.title('Dendrogram')
plt.show()
此外,还有使用 plotly 库的树状图,以下这段代码中数据都是伪数据,仅作参考无实际意义:
import pandas as pd
import plotly.express as px
import numpy as np
# 设置随机种子以确保结果可重复
np.random.seed(42)
# 生成伪数据
# 定义一些示例国家和年份
countries = ['美国', '印度', '德国', '英国', '加拿大', '澳大利亚', '法国', '中国', '巴西', '日本']
years = list(range(2015, 2023)) # 2015年至2022年
# 生成每个国家每年的员工数量
data = []
for country in countries:
for year in years:
# 随机生成员工数量,范围从50到500
total_personnel = np.random.randint(50, 500)
data.append({
'employee_residence': country,
'work_year': year,
'total_personnel': total_personnel
})
# 创建 DataFrame
df_salaries = pd.DataFrame(data)
# 数据处理:按员工居住地和工作年份分组,计算每组的人员总数
data_chart = df_salaries.groupby(['employee_residence', 'work_year']).sum().reset_index()
# 按人员总数降序排序,并选择前100条数据(在这个示例中数据量较小,可以省略)
data_chart = data_chart.sort_values(['total_personnel'], ascending=False).head(100)
# 创建树状图
fig = px.treemap(
data_chart,
path=['employee_residence', 'work_year'], # 定义层级结构
values='total_personnel', # 定义每个矩形的大小
color='total_personnel', # 根据人员总数进行颜色映射
color_continuous_scale=["#BB3E00", "#F7AD45", '#5F8D37'], # 自定义颜色渐变
)
# 自定义布局
fig.update_layout(
title={
"text": "<b>各国人力资源市场份额(按年份)</b>",
"x": 0.5,
"xanchor": "center",
"font": {
'size': 25,
'family': 'Proxima Nova',
'color': '#BB3E00',
}
},
template='simple_white', # 使用简单白色模板
paper_bgcolor='#F2EAC5', # 设置纸张背景色
plot_bgcolor='#FFF1D7', # 设置绘图背景色
treemapcolorway=["#BB3E00", "#F7AD45", '#5F8D37'], # 设置树状图颜色方案
height=600, # 设置图表高度
width=900, # 设置图表宽度
margin=dict(t=130), # 设置图表上边距
)
# 显示图表
fig.show()

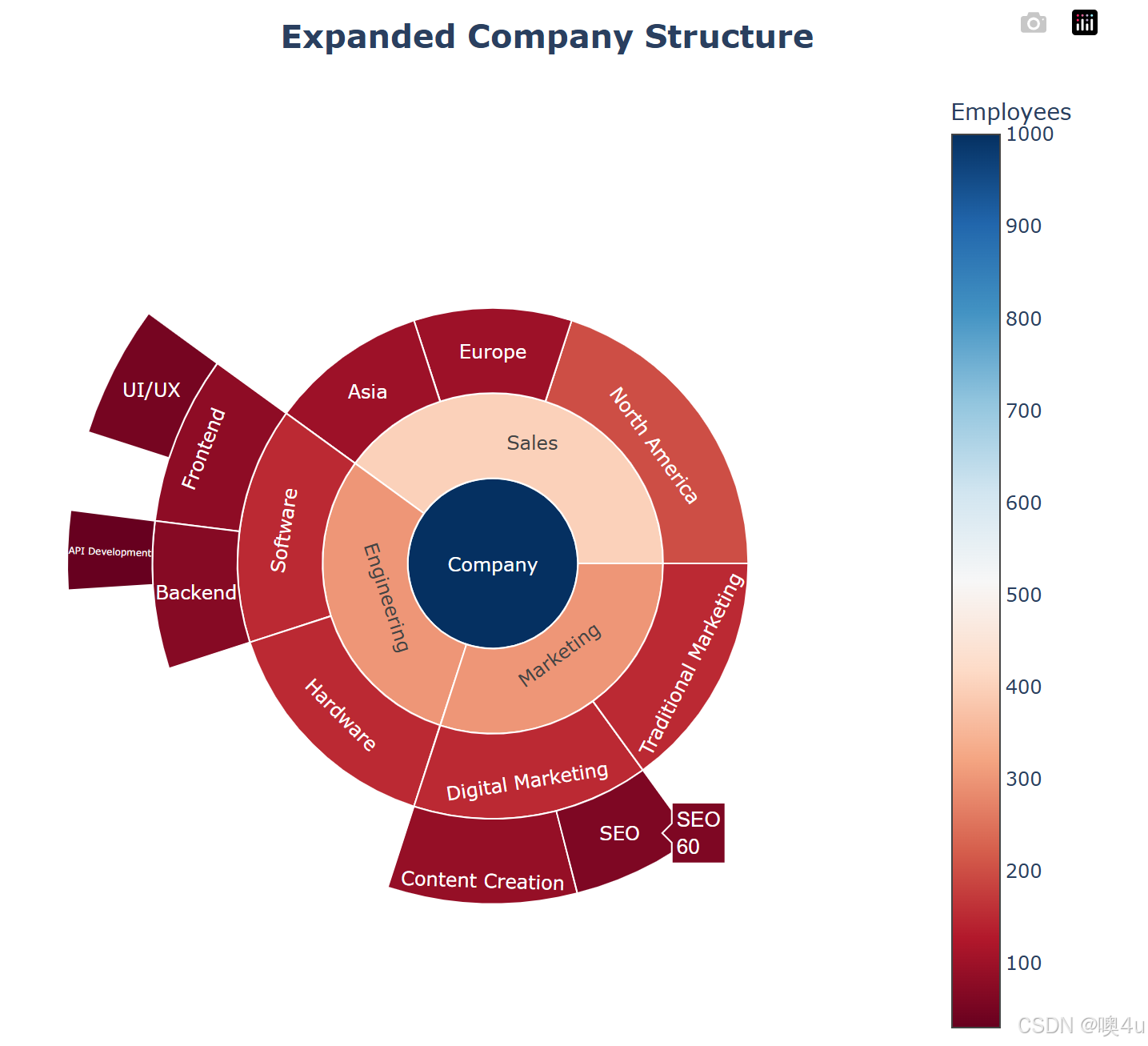
旭日图(Sunburst Chart)
旭日图(Sunburst Chart) 是一种用于展示层级数据的可视化工具。它通过同心圆的方式,直观地展示数据的层级结构和各部分之间的关系。旭日图特别适用于显示树状结构的数据,如公司组织结构、分类系统、文件目录等。
旭日图的组成部分:
-
根节点(Root Node):位于最中心,代表整个数据集的起点。例如,公司的总部门。
-
子节点(Child Nodes):位于根节点周围的同心圆上,代表根节点的下一级分类或部门。例如,公司的各个部门如销售、工程、市场等。
-
孙节点(Grandchild Nodes):位于子节点外侧的同心圆上,代表更细分的分类或子部门。例如,销售部门下的北美、欧洲、亚洲等区域。
-
颜色和大小:
- 颜色可以用于区分不同的类别或表示某种度量(如销售额、员工数量等)。
- 部分旭日图还可以通过扇形的角度或面积来表示数量或比例。
如何阅读旭日图?
-
从中心开始:识别根节点,理解整个图表所代表的整体。
-
沿着同心圆向外查看:分析每一层级的子节点,了解其与上一级节点的关系。
-
观察颜色和大小:
- 通过颜色区分不同的类别或部门。
- 通过扇形的大小或角度比较各部分的相对重要性或数量。
-
识别关键部分:找出哪些部分在整体中占据重要地位,哪些部分相对较小。
旭日图的用途
- 公司组织结构:展示公司各部门及其子部门的层级关系。
- 分类系统:如产品分类、书籍分类等,展示各类别及其子类别。
- 财务分析:展示不同收入来源和支出项目对总体财务状况的影响。
- 项目管理:展示项目的各个阶段及其子任务。
以下代码中使用的数据仅作示例,没有实际意义:
import pandas as pd
import plotly.graph_objects as go
# 定义标签和父节点
labels = [
'Company', # 根节点
'Sales', 'Engineering', 'Marketing', # 第一层级
'North America', 'Europe', 'Asia', # 第二层级(Sales 的子部门)
'Software', 'Hardware', # 第二层级(Engineering 的子部门)
'Digital Marketing', 'Traditional Marketing', # 第二层级(Marketing 的子部门)
'Frontend', 'Backend', # 第三层级(Software 的子部门)
'UI/UX', 'API Development', # 第四层级(Frontend 和 Backend 的子部门)
'SEO', 'Content Creation' # 第三层级(Digital Marketing 的子部门)
]
parents = [
'', # 根节点无父节点
'Company', 'Company', 'Company', # 第一层级的父节点是公司
'Sales', 'Sales', 'Sales', # Sales 的子部门
'Engineering', 'Engineering', # Engineering 的子部门
'Marketing', 'Marketing', # Marketing 的子部门
'Software', 'Software', # Software 的子部门
'Frontend', 'Backend', # Frontend 和 Backend 的子部门
'Digital Marketing', 'Digital Marketing' # Digital Marketing 的子部门
]
# 定义每个节点的值(例如,员工数量或销售额)
values = [
1000, # Company
400, # Sales
300, # Engineering
300, # Marketing
200, # North America
100, # Europe
100, # Asia
150, # Software
150, # Hardware
150, # Digital Marketing
150, # Traditional Marketing
80, # Frontend
70, # Backend
50, # UI/UX
30, # API Development
60, # SEO
90 # Content Creation
]
# 创建旭日图
fig = go.Figure(go.Sunburst(
labels=labels,
parents=parents,
values=values,
branchvalues='total', # 每个父节点的值等于其子节点的总和
marker=dict(
colors=values, # 根据值着色
colorscale='RdBu', # 选择颜色渐变
showscale=True, # 显示颜色条
colorbar=dict(title="Employees") # 颜色条标题
)
))
# 自定义布局
fig.update_layout(
title_text='<b>Expanded Company Structure</b>',
title_font_size=20,
title_x=0.5, # 标题水平居中
title_y=0.98, # 标题垂直位置
showlegend=False, # 隐藏图例
template="plotly_white", # 使用白色背景模板
margin=dict(t=50, l=50, r=50, b=50), # 调整边距
height=700, # 图表高度
width=700 # 图表宽度
)
# 显示图表
fig.show()
 也可以自定义每个节点的颜色,并且中心可以使用“图像”,但图像的形状美化(方形、圆形等形状需要自行匹配处理,旭日图中无直接支持的代码)
也可以自定义每个节点的颜色,并且中心可以使用“图像”,但图像的形状美化(方形、圆形等形状需要自行匹配处理,旭日图中无直接支持的代码)
import pandas as pd
import plotly.graph_objects as go
import base64
from PIL import Image, ImageDraw
def make_circle(image_path, output_path):
# 打开原始图片并确保为 RGBA 模式
img = Image.open(image_path).convert("RGBA")
# 创建一个相同尺寸的透明图像
size = img.size
mask = Image.new('L', size, 0)
# 在蒙版上绘制一个白色圆形区域
draw = ImageDraw.Draw(mask)
draw.ellipse((0, 0) + size, fill=255)
# 将蒙版应用于图片的 alpha 通道
img.putalpha(mask)
# 保存裁剪后的圆形图片
img.save(output_path, format="PNG")
# 使用函数裁剪图片
image_path = r".\1.png"
output_path = r".\2.png"
make_circle(image_path, output_path)
# 定义标签和父节点
labels = [
'', # 根节点(不显示了,便于图片的美观)
'Sales', 'Engineering', 'Marketing', # 第一层级
'North America', 'Europe', 'Asia', # 第二层级(Sales 的子部门)
'Software', 'Hardware', # 第二层级(Engineering 的子部门)
'Digital Marketing', 'Traditional Marketing', # 第二层级(Marketing 的子部门)
'Frontend', 'Backend', # 第三层级(Software 的子部门)
'UI/UX', 'API Development', # 第四层级(Frontend 和 Backend 的子部门)
'SEO', 'Content Creation' # 第三层级(Digital Marketing 的子部门)
]
parents = [
'', # 根节点无父节点
'', '', '', # 第一层级的父节点
'Sales', 'Sales', 'Sales', # Sales 的子部门
'Engineering', 'Engineering', # Engineering 的子部门
'Marketing', 'Marketing', # Marketing 的子部门
'Software', 'Software', # Software 的子部门
'Frontend', 'Backend', # Frontend 和 Backend 的子部门
'Digital Marketing', 'Digital Marketing' # Digital Marketing 的子部门
]
# 定义每个节点的值(例如,员工数量或销售额)
values = [
1000, #
400, # Sales
300, # Engineering
300, # Marketing
200, # North America
100, # Europe
100, # Asia
150, # Software
150, # Hardware
150, # Digital Marketing
150, # Traditional Marketing
80, # Frontend
70, # Backend
50, # UI/UX
30, # API Development
60, # SEO
90 # Content Creation
]
# 定义每个节点的颜色
custom_colors = [
'#FFD700', # 应为根节点 - 金色(但其实颜色已经无所谓了,会被图片压住)
'#1f77b4', # Sales - 蓝色
'#ff7f0e', # Engineering - 橙色
'#2ca02c', # Marketing - 绿色
'#aec7e8', # North America - 浅蓝色
'#ffbb78', # Europe - 浅橙色
'#98df8a', # Asia - 浅绿色
'#c5b0d5', # Software - 浅紫色
'#c49c94', # Hardware - 淡棕色
'#ff9896', # Digital Marketing - 淡红色
'#c7c7c7', # Traditional Marketing - 灰色
'#c7c7c7', # Frontend - 灰色
'#c7c7c7', # Backend - 灰色
'#c7c7c7', # UI/UX - 灰色
'#c7c7c7', # API Development - 灰色
'#c7c7c7', # SEO - 灰色
'#c7c7c7' # Content Creation - 灰色
]
# 创建旭日图
fig = go.Figure(go.Sunburst(
labels=labels,
parents=parents,
values=values,
branchvalues='total', # 每个父节点的值等于其子节点的总和
marker=dict(
colors=custom_colors,
showscale=False,
)
))
# 添加中心图片
# 首先,将图片转换为 base64 编码
# 示例图片URL
# image_url = "https://i.imgur.com/6IUbEME.png"
# # 直接使用图片URL
# fig.add_layout_image(
# dict(
# source=image_url,
# xref="paper", yref="paper",
# x=0.5, y=0.5, # 位置在图表中心
# sizex=0.2, sizey=0.2, # 调整图片大小
# xanchor="center", yanchor="middle",
# opacity=1.0,
# layer="above" # 确保图片在图表之上
# )
# )
# 本地图片,可以使用以下方法将其转换为base64:
image_path = r"D:\Microsoft VS Code\vs work\codeworkvs\py\py\shu\mathmodel\25meisai\21\2_word_circle.png"
with open(image_path, "rb") as image_file:
encoded_image = base64.b64encode(image_file.read()).decode()
# 添加图片到布局
fig.add_layout_image(
dict(
source="data:image/png;base64,{}".format(encoded_image),
xref="paper", yref="paper",
x=0.5, y=0.5, # 位置在图表中心
sizex=0.08, sizey=0.08, # 调整图片大小
xanchor="center", yanchor="middle",
opacity=1.0, #图片透明度
layer="above" # 确保图片在图表之上
)
)
# 自定义布局
fig.update_layout(
title_text='<b> Structure with Central Image</b>',
title_font_size=20,
title_x=0.5, # 标题水平居中
title_y=0.95, # 标题垂直位置
showlegend=False, # 隐藏图例
template="plotly_white", # 使用白色背景模板
margin=dict(t=100, l=50, r=50, b=50), # 调整边距
height=700, # 图表高度
width=700 # 图表宽度
)
# 显示图表
fig.show()
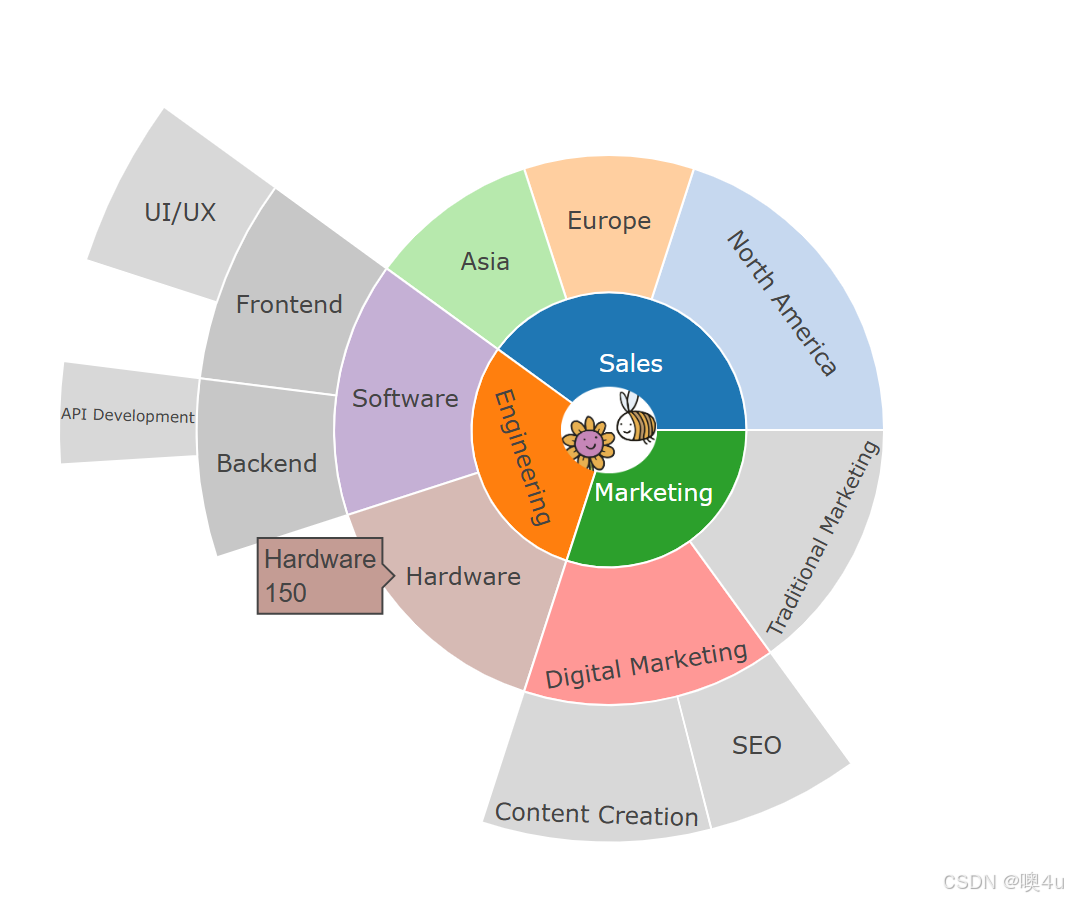
甘特图(Gantt Chart)
展示任务或事件的时间安排,常用于项目管理。
import matplotlib.pyplot as plt
import matplotlib.dates as mdates
import pandas as pd
# 创建数据
tasks = {
'Task': ['Task 1', 'Task 2', 'Task 3'],
'Start': ['2024-12-01', '2024-12-03', '2024-12-05'],
'End': ['2024-12-04', '2024-12-07', '2024-12-10']
}
df = pd.DataFrame(tasks)
df['Start'] = pd.to_datetime(df['Start'])
df['End'] = pd.to_datetime(df['End'])
# 绘制甘特图
fig, ax = plt.subplots(figsize=(10, 5))
for i, task in df.iterrows():
ax.barh(task['Task'], (task['End'] - task['Start']).days, left=task['Start'])
ax.xaxis.set_major_locator(mdates.WeekdayLocator())
ax.xaxis.set_major_formatter(mdates.DateFormatter('%Y-%m-%d'))
plt.title('Gantt Chart')
plt.show()
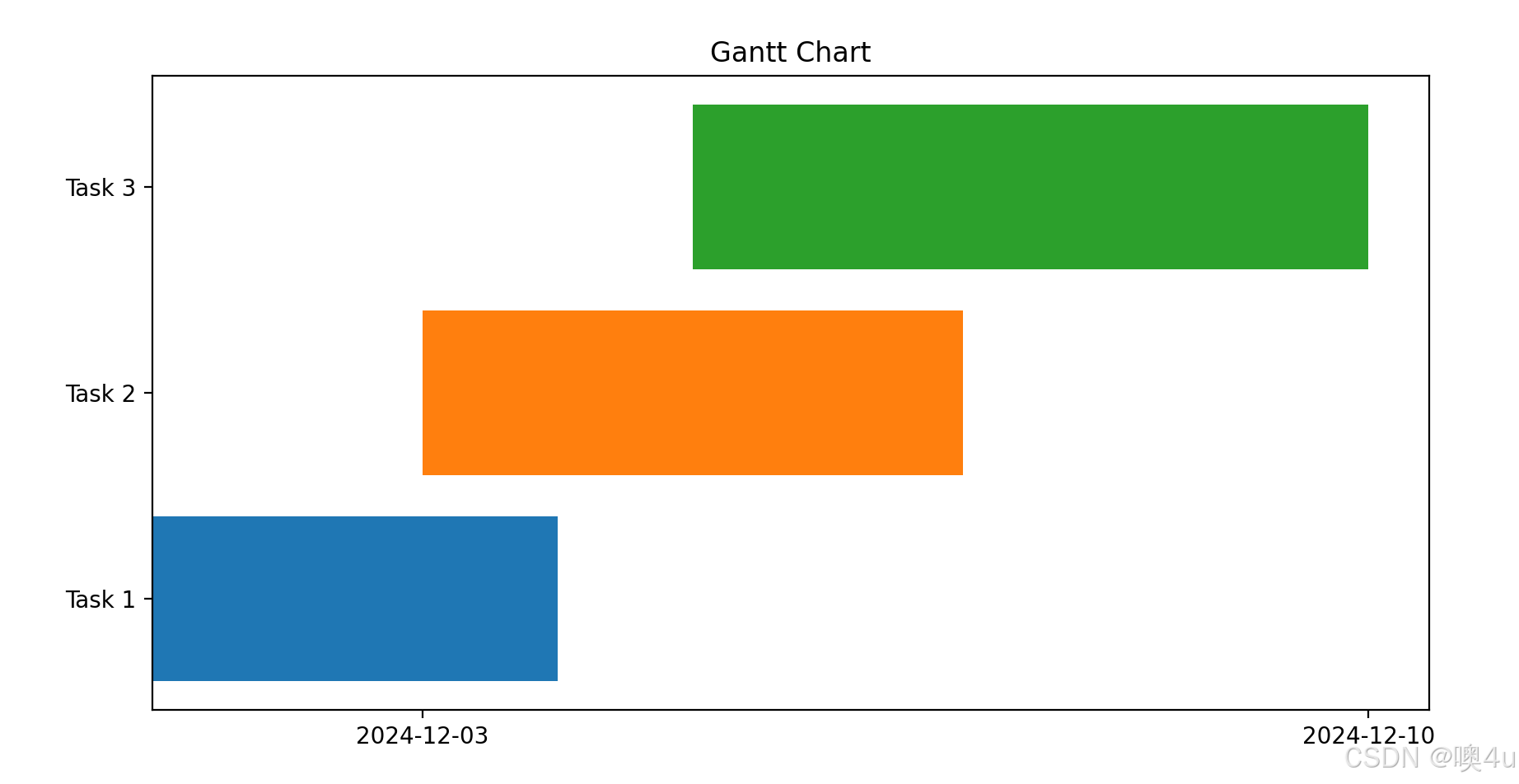
桑基图(Sankey Diagram)
展示流量或能量在不同阶段的分配和转移。
import plotly.graph_objects as go
fig = go.Figure(data=[go.Sankey(
node=dict(
pad=15,
thickness=20,
line=dict(color="black", width=0.5),
label=["A", "B", "C", "D", "E"],
color=["blue", "green", "red", "orange", "purple"]
),
link=dict(
source=[0, 1, 0, 2, 3, 3],
target=[2, 3, 3, 4, 4, 1],
value=[8, 4, 2, 8, 4, 2]
)
)])
fig.update_layout(title_text="桑基图示例", font_size=10)
fig.show()
词云图(Word Cloud)
import matplotlib.pyplot as plt
from wordcloud import WordCloud
# 设置中文字体和负号显示
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# # 读取自定义形状的图像(mask_image.png)
# mask = np.array(Image.open('mask_image.png'))
#伪数据
text = """
人工智能(AI)是计算机科学的一个分支,旨在通过模拟人的思维过程来开发智能机器。随着大数据、云计算和深度学习的快速发展,AI的应用范围不断扩大,涵盖了自然语言处理、计算机视觉、自动驾驶、机器人、语音识别等领域。机器学习是AI的重要组成部分,它通过分析大量数据来训练模型,使得计算机能够在没有明确编程指令的情况下进行自我学习和改进。深度学习则是机器学习中的一个分支,主要通过神经网络模型来处理复杂的数据结构和模式识别问题。
在数据科学的背景下,AI被广泛应用于图像识别、语音识别、数据分析、推荐系统等各个行业,极大地提高了效率和精度。人工智能在医疗健康、金融风控、教育、智能制造等多个行业领域都有着广泛的前景,尤其是在解决复杂问题和提高生产力方面表现出色。随着技术的不断进步,未来的人工智能将更加智能化、个性化和自动化。
"""
# 创建词云对象,指定掩模图像,背景颜色和其他参数
# wordcloud = WordCloud(mask=mask, background_color='white', contour_color='black', contour_width=1, width=800, height=800).generate(text)
# 创建词云对象
wordcloud = WordCloud(font_path='simhei.ttf', width=800, height=400, background_color='white').generate(text)
# 显示词云图
plt.figure(figsize=(10, 10))
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis("off") # 不显示坐标轴
plt.show()

给词云图规定形状
import pandas as pd
import re
from collections import Counter
from wordcloud import WordCloud
import matplotlib.pyplot as plt
import numpy as np
from PIL import Image
# 1. 读取Excel文件
file_path = r"./data.xlsx"
data = pd.read_excel(file_path)
# 2. 提取“Notes”和“Lab Comments”列
text_data = data[['Notes', 'Lab Comments']].fillna('') # 将空值填充为空字符串
# 3. 合并所有文本内容为一个大字符串
all_text = ' '.join(text_data['Notes'].astype(str)) + ' ' + ' '.join(text_data['Lab Comments'].astype(str))
# 4. 清洗文本数据:去除标点符号和特殊字符,转换为小写
all_text = re.sub(r'[^\w\s]', '', all_text.lower()) # 保留字母和数字
# 5. 分词并去除停用词
stopwords = set([
'i', 'me', 'my', 'myself', 'we', 'our', 'ours', 'ourselves', 'you', 'your', 'yours', 'yourself', 'yourselves',
'he', 'him', 'his', 'himself', 'she', 'her', 'hers', 'herself', 'it', 'its', 'itself', 'they', 'them', 'their',
'theirs', 'themselves', 'what', 'which', 'who', 'whom', 'this', 'that', 'these', 'those', 'am', 'is', 'are', 'was',
'were', 'be', 'been', 'being', 'have', 'has', 'had', 'having', 'do', 'does', 'did', 'doing', '1', 'a', 'an', 'the',
'and', 'but', 'if', 'or', 'because', 'as', 'until', 'while', 'of', 'at', 'by', 'for', 'with', 'about', 'against',
'between', 'into', 'through', 'during', 'before', 'after', 'above', 'below', 'to', 'from', 'up', 'down', 'in',
'out', 'on', 'off', 'over', 'under', 'again', 'further', 'then', 'once', 'here', 'there', 'when', 'where', 'why',
'how', 'all', 'any', 'both', 'each', 'few', 'more', 'most', 'other', 'some', 'such', 'no', 'nor', 'not', 'only',
'own', 'same', 'so', 'than', 'too', 'very', 's', 't', 'can', 'will', 'just', 'don', 'should', 'now', 'd', 'll',
'm', 'o', 're', 've', 'y', 'im', 'ain', 'aren', 'couldn', 'didn', 'doesn', 'dont', 'hadn', 'hasn', 'haven', 'isn', 'ma', 'mightn',
'mustn', 'needn', 'shan', 'shouldn', 'wasn', 'weren', 'won', 'wouldn', 'submission', 'thanks', 'hornet', 'saw', 'seen',
'didnt', 'thats', 'never', 'like', 'asian', 'think', 'tried', 'pictures', 'area', 'bug', 'take'
])
words = all_text.split()
filtered_words = [word for word in words if word not in stopwords]
# 6. 加载背景图片并创建词云图的形状
background_image_path = r".\2.png"
background_image = np.array(Image.open(background_image_path))
# 7. 生成词云图
wordcloud = WordCloud(
width=800,
height=400,
background_color='white',
stopwords=stopwords,
mask=background_image, # 使用背景图片的形状
contour_color='black', # 边缘颜色
contour_width=5 # 边缘宽度
).generate_from_frequencies(word_counts)
# 8. 显示词云图
plt.figure(figsize=(10, 5))
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis('off') # 关闭坐标轴
plt.show()
 原图:原理是根据对比度找到原图的边界线。
原图:原理是根据对比度找到原图的边界线。 
网络图(Network Chart)
可以指定每个点的相对坐标:
import networkx as nx
import matplotlib.pyplot as plt
# 创建一个空的无向图
G = nx.Graph()
# 添加节点
nodes = ['A', 'B', 'C', 'D', 'E']
G.add_nodes_from(nodes)
# 添加带有标签的边
# 边的格式为 (节点1, 节点2, 标签)
edges = [
('A', 'B', 'connect AB'),
('A', 'C', 'connect AC'),
('B', 'D', 'connect BD'),
('C', 'D', 'connect CD'),
('D', 'E', 'connect DE')
]
G.add_edges_from([(u, v, {'label': label}) for u, v, label in edges])
# 指定每个节点的坐标
pos = {
'A': (0, 0),
'B': (1, 2),
'C': (1, -2),
'D': (2, 0),
'E': (3, 0)
}
# 创建图形和轴
plt.figure(figsize=(8, 6))
ax = plt.gca()
ax.set_title('Network Chart', fontsize=16)
# 绘制节点
nx.draw_networkx_nodes(G, pos, node_size=700, node_color='#1f77b4', ax=ax)
# 绘制边
nx.draw_networkx_edges(G, pos, width=2, edge_color='#888888', ax=ax)
# 绘制节点标签
nx.draw_networkx_labels(G, pos, font_size=12, font_color='white', font_weight='bold', ax=ax)
# 绘制边标签
edge_labels = nx.get_edge_attributes(G, 'label')
nx.draw_networkx_edge_labels(G, pos, edge_labels=edge_labels, font_color='red', font_size=10, ax=ax)
# 移除坐标轴
plt.axis('off')
# 显示图表
plt.show()
模型解释性可视化类
TensorBoard
除以下自主绘制图表方式外,还可在训练过程中,在终端中使用命令“tensorboard --logdir=./logs”。
TensorBoard 最初是为了深度学习(尤其是神经网络)训练过程的可视化而设计的,
- 训练过程:在神经网络训练过程中,
TensorBoard可以用来可视化损失函数、精度(accuracy)、梯度和权重的变化,帮助你分析模型训练的效果和优化过程。 - 模型结构:
TensorBoard还可以展示神经网络的结构,显示每一层的输入和输出,帮助你理解模型的架构。
但它的功能不仅限于此。对于其他类型的机器学习模型,也可以通过 TensorBoard 来监控训练过程,尤其是在使用 TensorFlow 或其他与 TensorBoard 兼容的库时。以下是几种常见场景:
-
传统机器学习模型:
- 可以使用
TensorBoard可视化例如线性回归、支持向量机(SVM)或决策树等传统机器学习模型的训练过程。这通常通过手动记录和标记(如记录训练误差或其他指标)来实现。
- 可以使用
-
模型训练曲线:
- 对于任何模型,只要有训练过程中的统计数据(如训练损失、验证损失、学习率等),都可以通过
TensorBoard来绘制这些指标的曲线图,查看训练过程中的变化。
- 对于任何模型,只要有训练过程中的统计数据(如训练损失、验证损失、学习率等),都可以通过
-
自定义指标:
- 可以在任何类型的模型训练中使用
TensorBoard来监控自定义的训练过程指标,例如训练数据的特征分布、模型的混淆矩阵、特征重要性等。
- 可以在任何类型的模型训练中使用
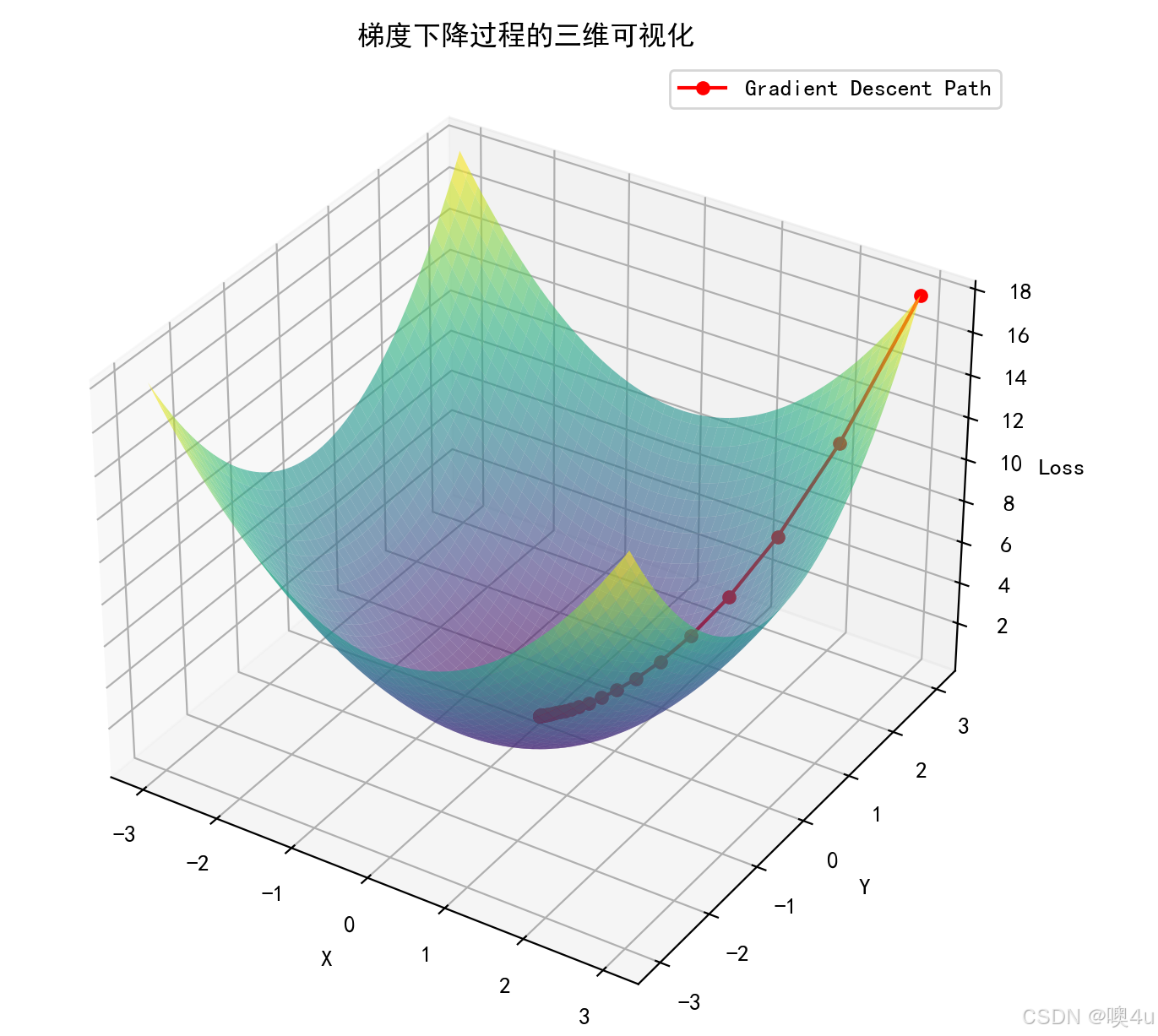
梯度下降过程的三维可视化
在神经网络模型或其他机器学习模型中,梯度下降法用于通过不断调整参数来减小损失函数(误差)的值。可以通过三维图形来直观展示这个过程,展示损失函数的表面,以及梯度下降在不同迭代步骤中的路径。
import numpy as np
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
# 设置中文字体和负号显示
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 定义损失函数:f(x, y) = x^2 + y^2
def loss_function(x, y):
return x**2 + y**2
# 计算梯度
def gradient(x, y):
return np.array([2*x, 2*y])
# 梯度下降
def gradient_descent(learning_rate=0.1, num_iterations=50):
x, y = 3.0, 3.0 # 初始化起点
path = [(x, y)] # 记录路径
for _ in range(num_iterations):
grad = gradient(x, y) # 计算梯度
x -= learning_rate * grad[0] # 更新 x
y -= learning_rate * grad[1] # 更新 y
path.append((x, y)) # 记录新的位置
return np.array(path)
# 生成网格数据
x = np.linspace(-3, 3, 100)
y = np.linspace(-3, 3, 100)
X, Y = np.meshgrid(x, y)
Z = loss_function(X, Y)
# 梯度下降路径
path = gradient_descent(learning_rate=0.1, num_iterations=50)
# 绘制三维损失函数和梯度下降路径
fig = plt.figure(figsize=(10, 8))
ax = fig.add_subplot(111, projection='3d')
# 绘制损失函数表面
ax.plot_surface(X, Y, Z, cmap='viridis', alpha=0.6)
# 绘制梯度下降路径
ax.plot(path[:, 0], path[:, 1], loss_function(path[:, 0], path[:, 1]), color='r', marker='o', markersize=5, label='Gradient Descent Path')
# 设置标题和标签
ax.set_title('梯度下降过程的三维可视化')
ax.set_xlabel('X')
ax.set_ylabel('Y')
ax.set_zlabel('Loss')
ax.legend()
plt.show()
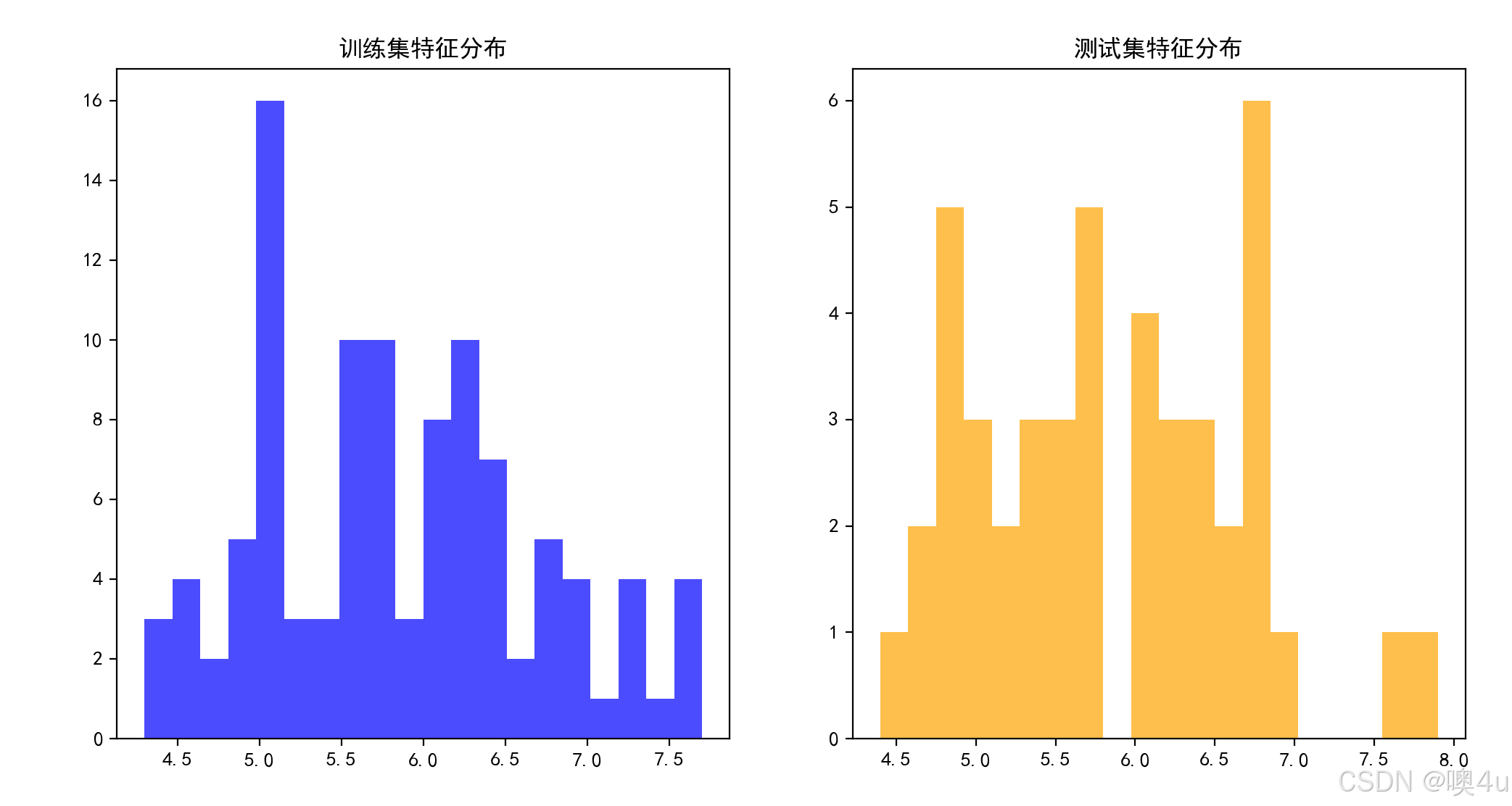
 训练集与测试集分布对比图(Train vs Test Distribution)
训练集与测试集分布对比图(Train vs Test Distribution)
通过对比训练集和测试集的分布,可以检查数据是否存在过拟合或者是否存在数据泄露问题。通常通过可视化特征的分布或目标值的分布来实现。用柱状图实现。
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
# 设置中文字体和负号显示
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 加载数据集
iris = load_iris()
X = iris.data
y = iris.target
# 切分数据集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 绘制训练集与测试集分布对比
plt.figure(figsize=(12, 6))
# 训练集
plt.subplot(1, 2, 1)
plt.hist(X_train[:, 0], bins=20, alpha=0.7, label='Train', color='blue')
plt.title('训练集特征分布')
# 测试集
plt.subplot(1, 2, 2)
plt.hist(X_test[:, 0], bins=20, alpha=0.7, label='Test', color='orange')
plt.title('测试集特征分布')
plt.show()
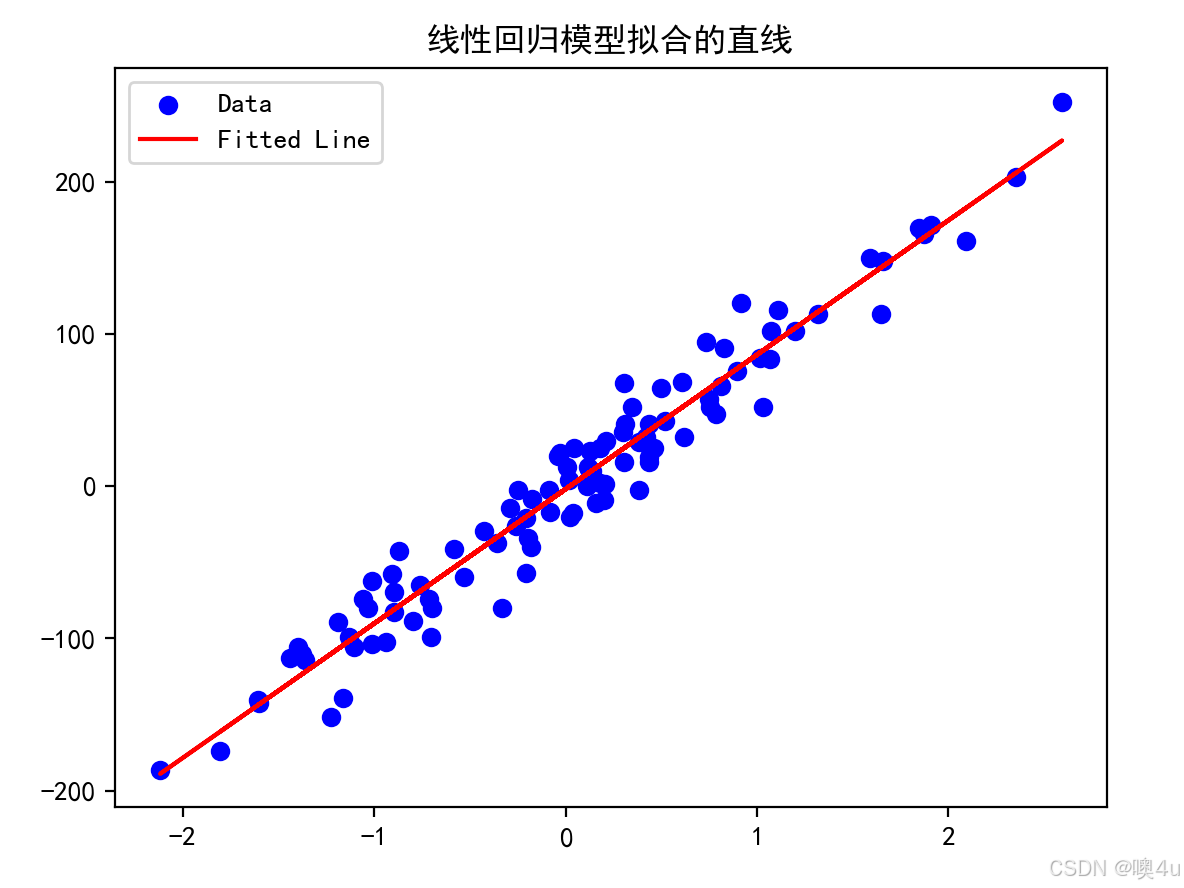
线性回归模型拟合的直线
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
from sklearn.datasets import make_regression
# 设置中文字体和负号显示
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 生成伪数据
X, y = make_regression(n_samples=100, n_features=1, noise=20)
# 线性回归模型
model = LinearRegression()
model.fit(X, y)
# 绘制数据点和拟合直线
plt.scatter(X, y, color='blue', label='Data')
plt.plot(X, model.predict(X), color='red', label='Fitted Line')
plt.title('线性回归模型拟合的直线')
plt.legend()
plt.show()
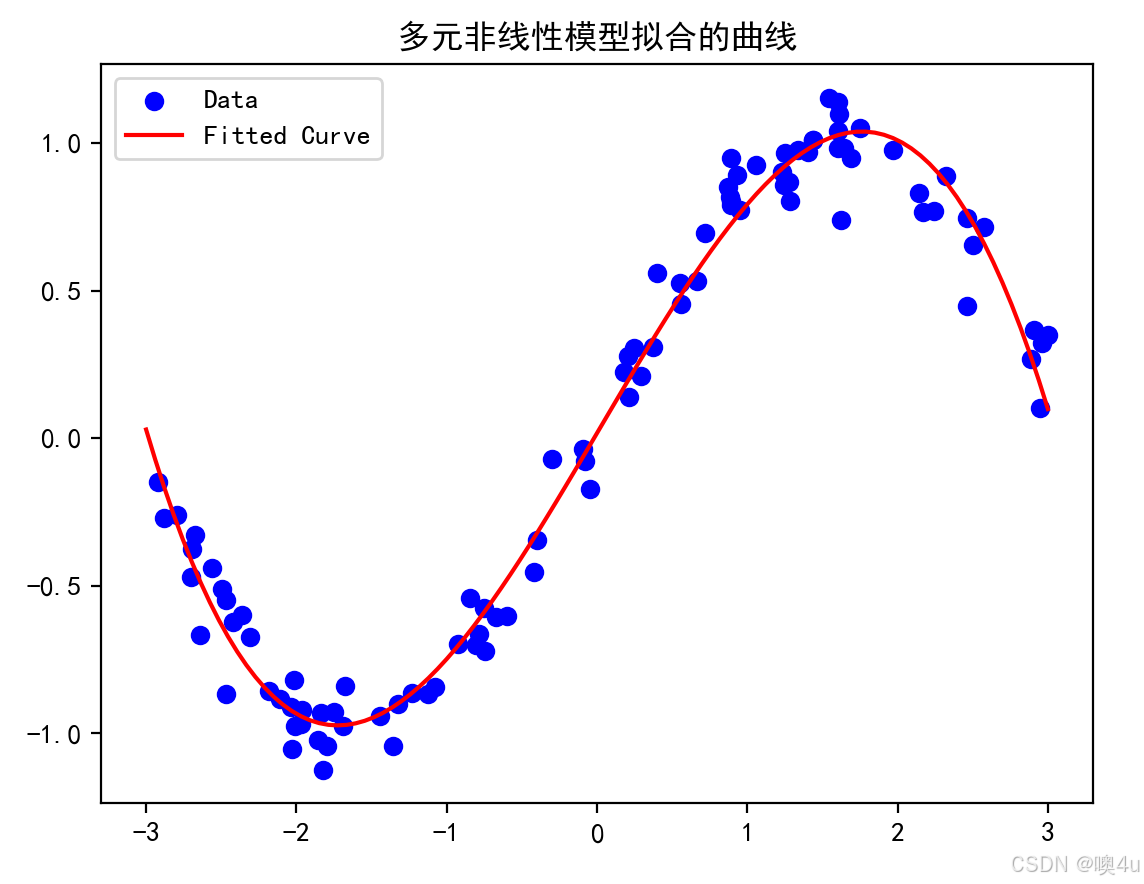
 多元非线性模型拟合的曲线
多元非线性模型拟合的曲线
多项式模型:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.preprocessing import PolynomialFeatures
from sklearn.linear_model import LinearRegression
# 设置中文字体和负号显示
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 生成伪数据(非线性)
X = np.random.rand(100, 1) * 6 - 3 # 随机生成数据
y = np.sin(X).ravel() + 0.1 * np.random.randn(100)
# 多项式回归模型
poly = PolynomialFeatures(degree=3)
X_poly = poly.fit_transform(X)
model = LinearRegression()
model.fit(X_poly, y)
# 绘制拟合曲线
X_grid = np.linspace(-3, 3, 100).reshape(-1, 1)
X_grid_poly = poly.transform(X_grid)
plt.scatter(X, y, color='blue', label='Data')
plt.plot(X_grid, model.predict(X_grid_poly), color='red', label='Fitted Curve')
plt.title('多元非线性模型拟合的曲线')
plt.legend()
plt.show()
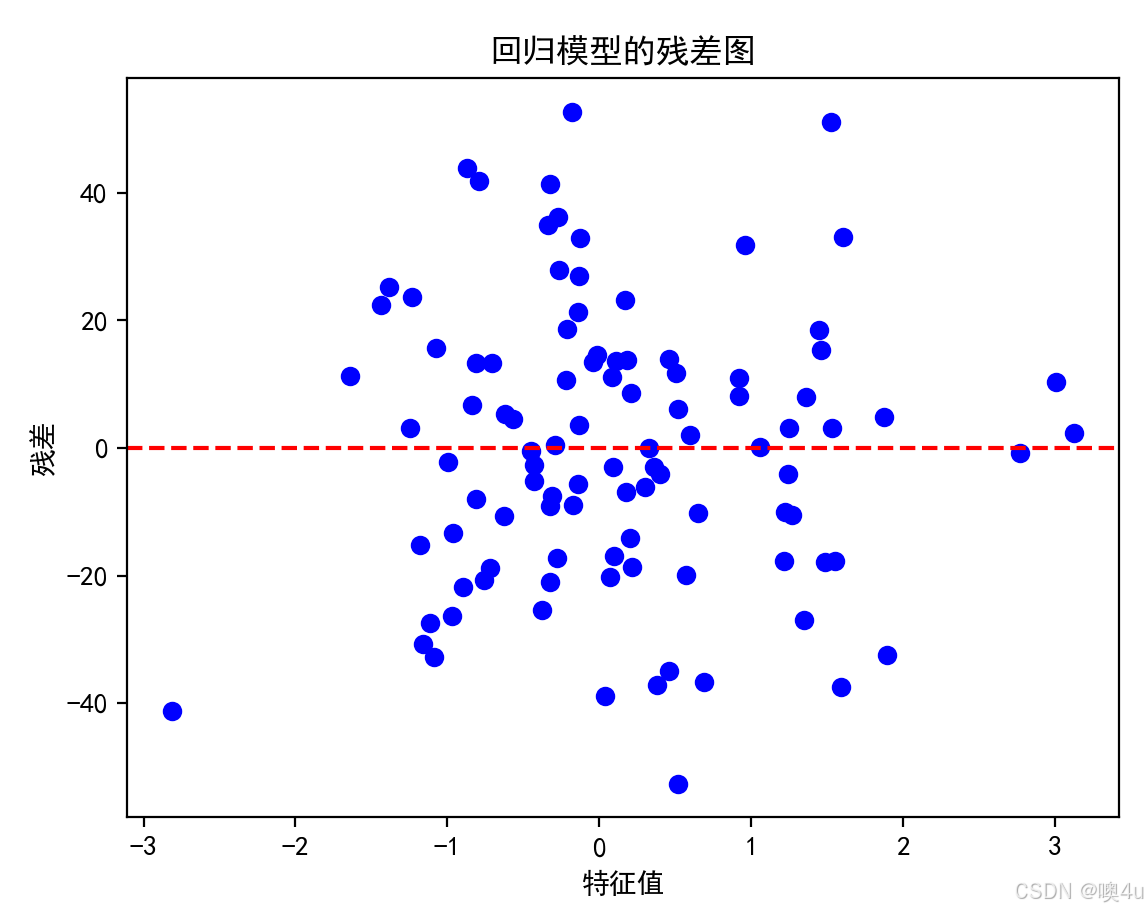
回归模型参差图
残差图用于评估回归模型的拟合效果。通过查看残差的分布,可以检查模型是否存在系统性的误差。
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
from sklearn.datasets import make_regression
# 设置中文字体和负号显示
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 生成伪数据
X, y = make_regression(n_samples=100, n_features=1, noise=20)
# 训练回归模型
model = LinearRegression()
model.fit(X, y)
# 计算预测值和残差
y_pred = model.predict(X)
residuals = y - y_pred
# 绘制残差图
plt.scatter(X, residuals, color='blue')
plt.axhline(0, color='red', linestyle='--')
plt.title('回归模型的残差图')
plt.xlabel('特征值')
plt.ylabel('残差')
plt.show()
训练过程中的损失曲线
损失函数曲线用于观察模型训练过程中的损失变化,帮助评估模型是否在收敛,是否出现过拟合或欠拟合。
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import log_loss
# 设置中文字体和负号显示
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 生成伪数据
X, y = make_classification(n_samples=1000, n_features=20, n_classes=2, random_state=42)
# 切分数据集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 训练模型并记录损失
model = LogisticRegression(max_iter=500)
train_losses = []
for i in range(1, 500):
model.max_iter = i
model.fit(X_train, y_train)
y_pred_prob = model.predict_proba(X_test)
loss = log_loss(y_test, y_pred_prob)
train_losses.append(loss)
# 绘制损失函数曲线
plt.plot(range(1, 500), train_losses, color='blue', label='Loss')
plt.title('训练过程的损失函数曲线')
plt.xlabel('迭代次数')
plt.ylabel('损失值')
plt.legend()
plt.show()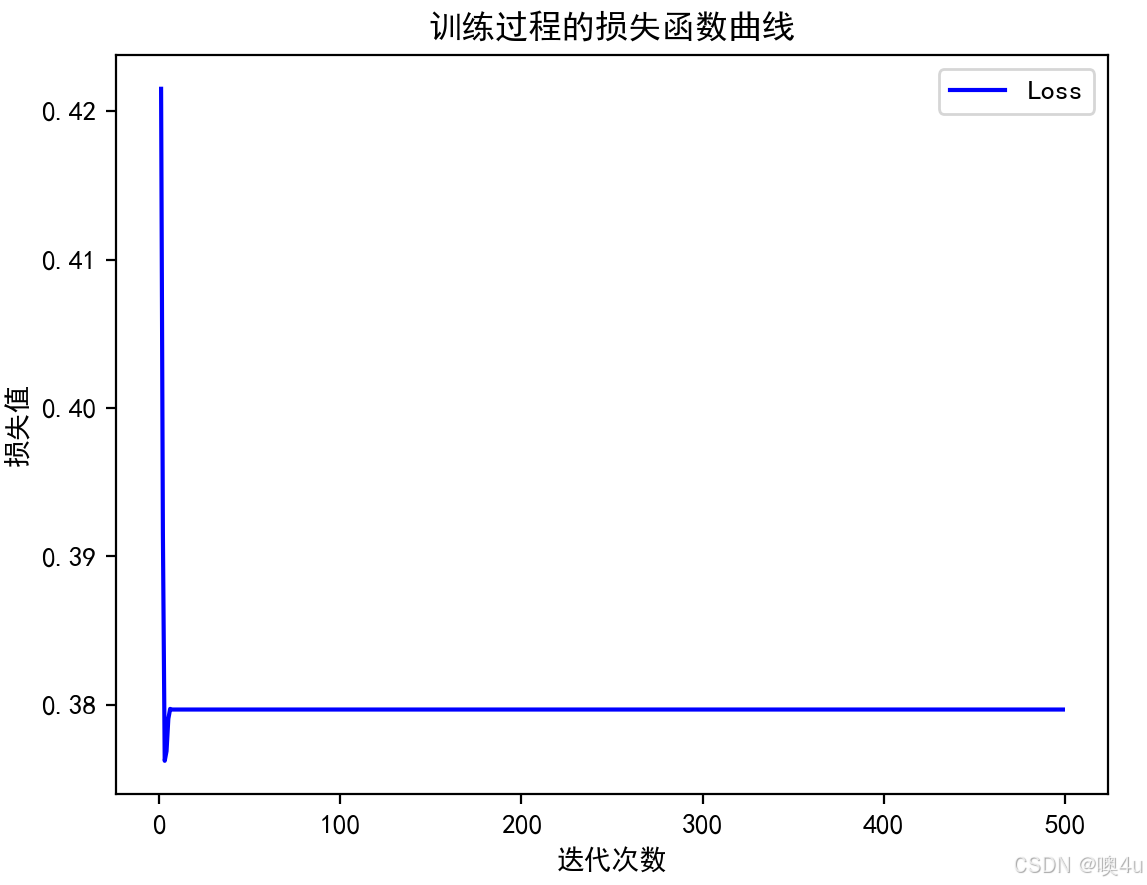
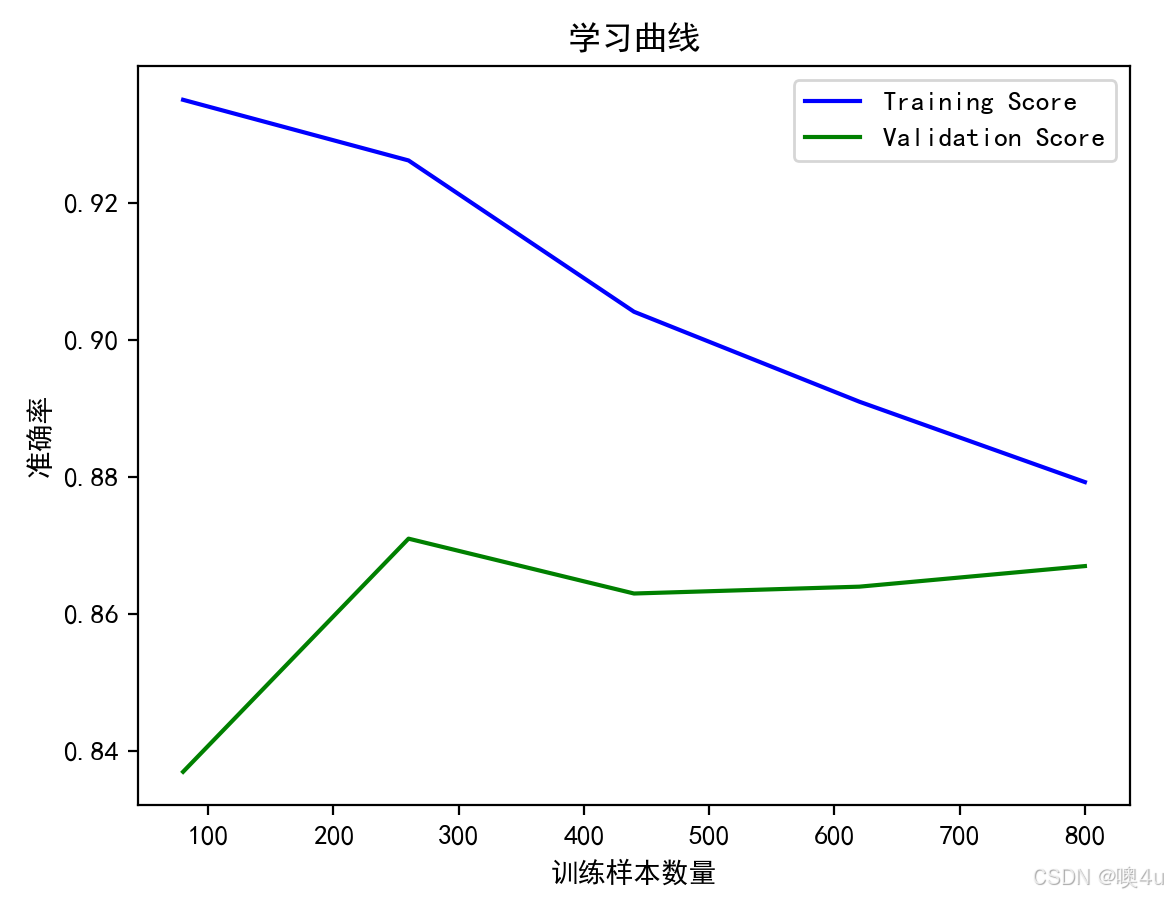
训练过程中的学习曲线
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_classification
from sklearn.model_selection import learning_curve
from sklearn.linear_model import LogisticRegression
# 设置中文字体和负号显示
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 生成伪数据
X, y = make_classification(n_samples=1000, n_features=20, n_classes=2, random_state=42)
# 训练模型并计算学习曲线
model = LogisticRegression(max_iter=200)
train_sizes, train_scores, test_scores = learning_curve(model, X, y, cv=5, n_jobs=-1)
# 计算平均值
train_mean = np.mean(train_scores, axis=1)
test_mean = np.mean(test_scores, axis=1)
# 绘制学习曲线
plt.plot(train_sizes, train_mean, label='Training Score', color='blue')
plt.plot(train_sizes, test_mean, label='Validation Score', color='green')
plt.title('学习曲线')
plt.xlabel('训练样本数量')
plt.ylabel('准确率')
plt.legend()
plt.show()
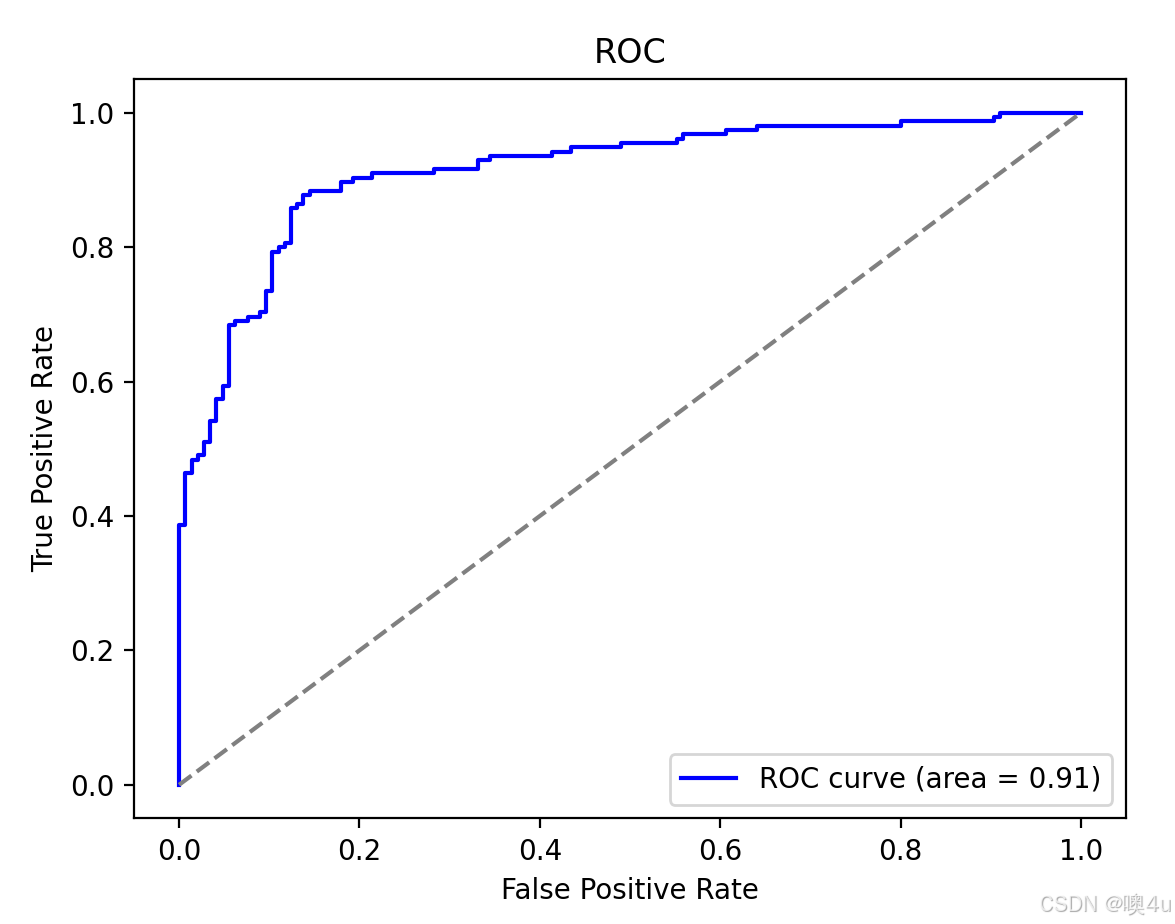
ROC曲线
解释和计算及意义具体见“机器学习”专栏,分类模型评估。
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import roc_curve, auc
# 生成伪数据
X, y = make_classification(n_samples=1000, n_features=20, n_informative=2, n_classes=2, random_state=42)
# 切分数据集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 训练逻辑回归模型
model = LogisticRegression()
model.fit(X_train, y_train)
# 计算预测概率
y_pred_prob = model.predict_proba(X_test)[:, 1]
# 计算ROC曲线数据
fpr, tpr, thresholds = roc_curve(y_test, y_pred_prob)
roc_auc = auc(fpr, tpr)
# 绘制ROC曲线
plt.plot(fpr, tpr, color='blue', label=f'ROC curve (area = {roc_auc:.2f})')
plt.plot([0, 1], [0, 1], color='gray', linestyle='--')
plt.title('ROC')
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.legend(loc='lower right')
plt.show()
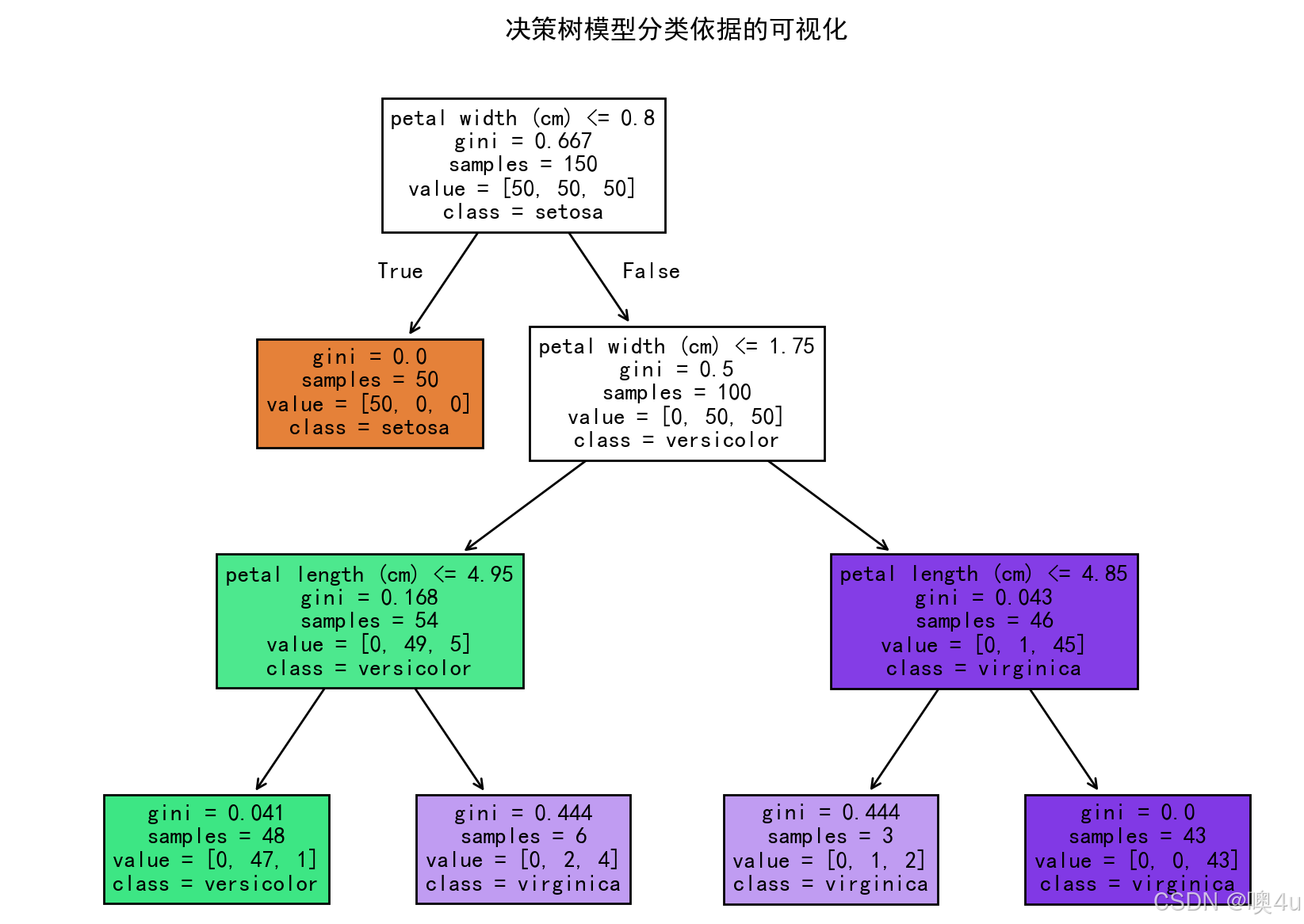
决策树模型分类依据可视化
分类依据概念和计算具体见“机器学习”专栏《4.4分类》。
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier
from sklearn.tree import plot_tree
# 设置中文字体和负号显示
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 加载数据集
iris = load_iris()
X = iris.data
y = iris.target
# 训练决策树模型
clf = DecisionTreeClassifier(max_depth=3)
clf.fit(X, y)
# 可视化决策树
plt.figure(figsize=(10, 8))
plot_tree(clf, filled=True, feature_names=iris.feature_names, class_names=iris.target_names)
plt.title('决策树模型分类依据的可视化')
plt.show()
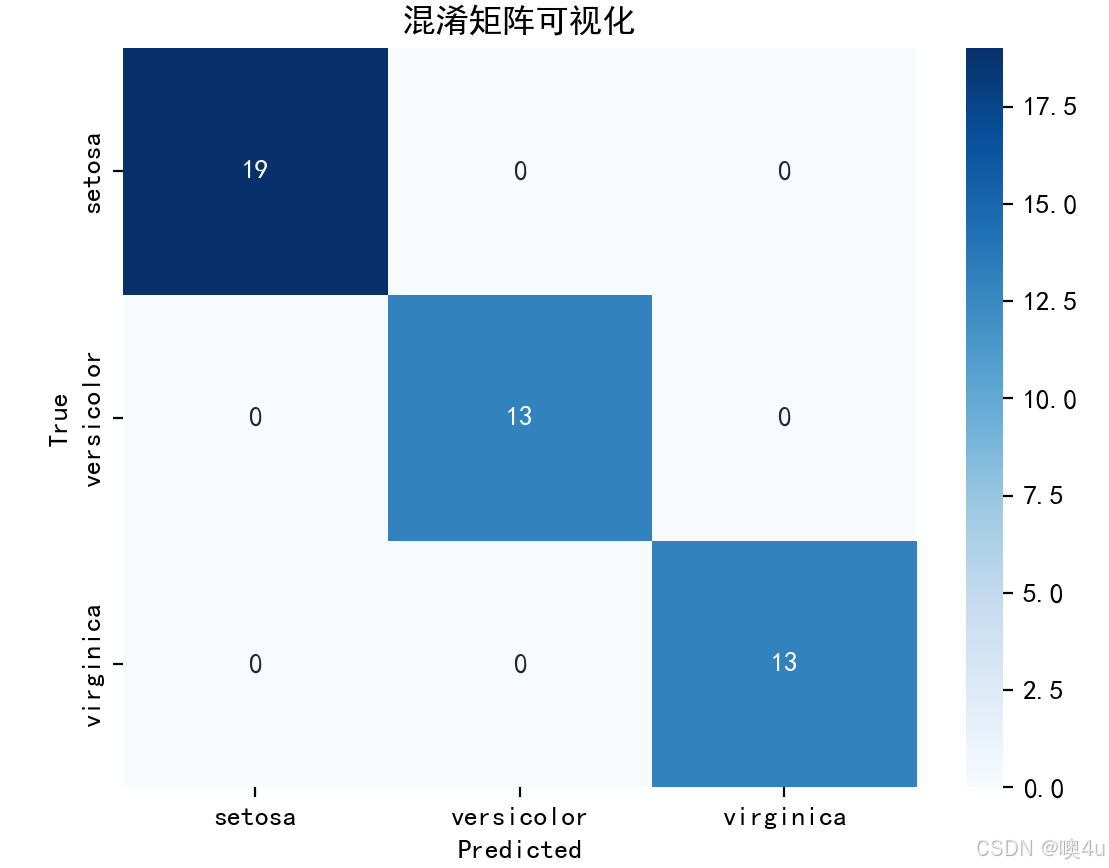
混淆矩阵可视化
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import confusion_matrix
# 设置中文字体和负号显示
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 加载数据集
iris = load_iris()
X = iris.data
y = iris.target
# 切分数据集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 训练模型
model = LogisticRegression(max_iter=200)
model.fit(X_train, y_train)
# 预测并计算混淆矩阵
y_pred = model.predict(X_test)
cm = confusion_matrix(y_test, y_pred)
# 可视化混淆矩阵
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues', xticklabels=iris.target_names, yticklabels=iris.target_names)
plt.title('混淆矩阵可视化')
plt.xlabel('Predicted')
plt.ylabel('True')
plt.show()
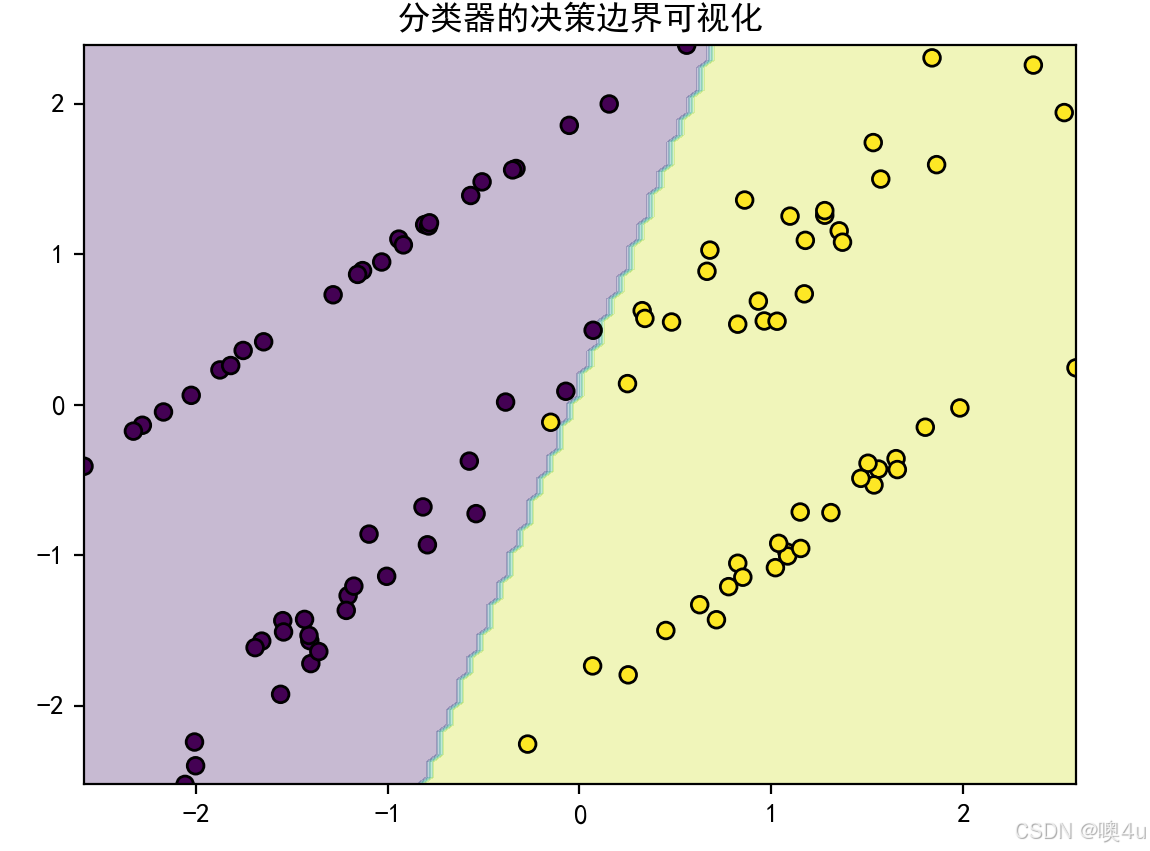
分类器决策边界可视化(以二分类的SVM模型为例)
具体解释见“机器学习”专栏《4.4分类》。
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_classification
from sklearn.svm import SVC
# 设置中文字体和负号显示
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 生成伪数据
X, y = make_classification(n_samples=100, n_features=2, n_classes=2, n_informative=2, n_redundant=0, n_repeated=0, random_state=42)
# 训练支持向量机分类器
model = SVC(kernel='linear')
model.fit(X, y)
# 绘制决策边界
xx, yy = np.meshgrid(np.linspace(X[:, 0].min(), X[:, 0].max(), 100),
np.linspace(X[:, 1].min(), X[:, 1].max(), 100))
Z = model.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
plt.contourf(xx, yy, Z, alpha=0.3)
plt.scatter(X[:, 0], X[:, 1], c=y, edgecolors='k', marker='o')
plt.title('分类器的决策边界可视化')
plt.show()
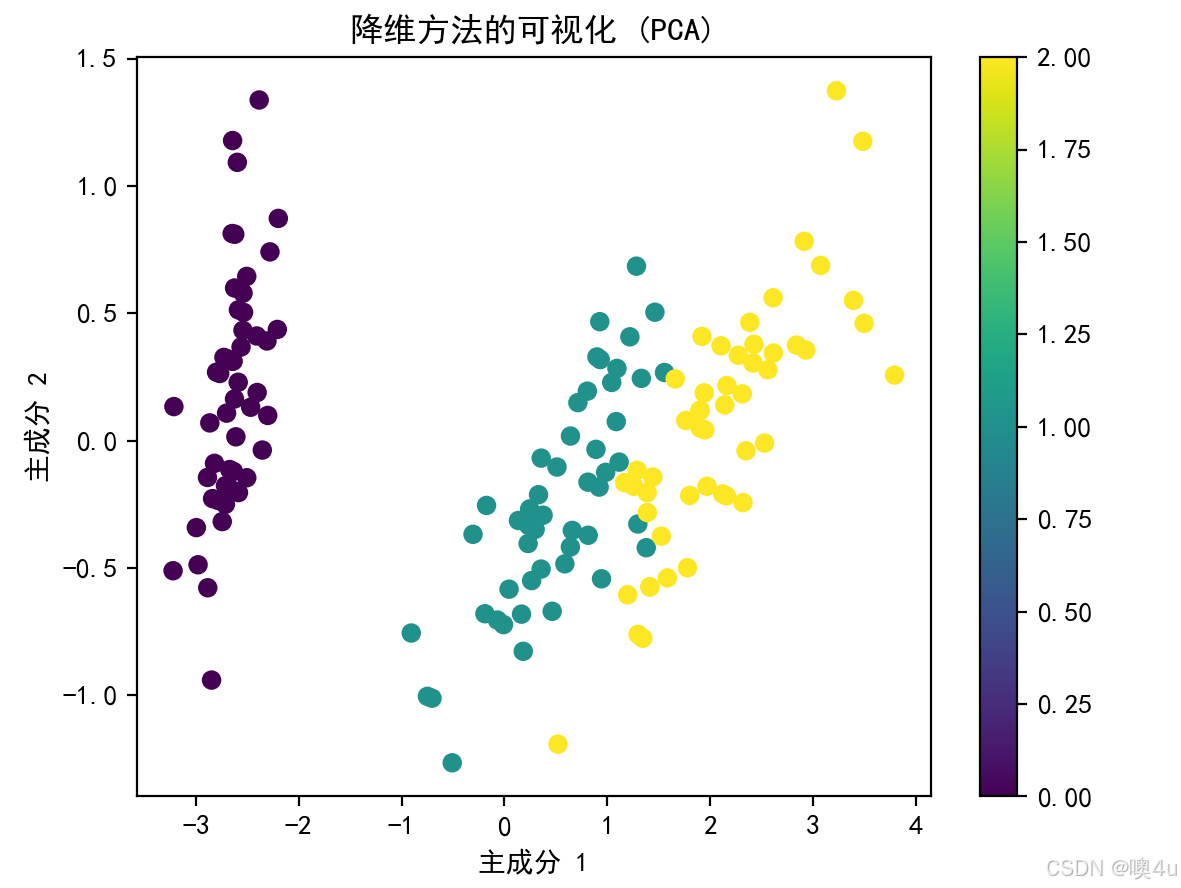
降维方法可视化(以PCA为例)
具体解释见“机器学习”专栏《4.2降维》。用散点图实现,聚类效果除上述树状图外也同样可用散点图实现(Kmeans)。
import numpy as np
import matplotlib.pyplot as plt
from sklearn.decomposition import PCA
from sklearn.datasets import load_iris
import pandas as pd
# 设置中文字体和负号显示
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 加载数据集
iris = load_iris()
X = iris.data
y = iris.target
# 主成分分析(PCA)
pca = PCA(n_components=2)
X_pca = pca.fit_transform(X)
# 绘制PCA结果
plt.scatter(X_pca[:, 0], X_pca[:, 1], c=y, cmap='viridis')
plt.title('降维方法的可视化 (PCA)')
plt.xlabel('主成分 1')
plt.ylabel('主成分 2')
plt.colorbar()
plt.show()
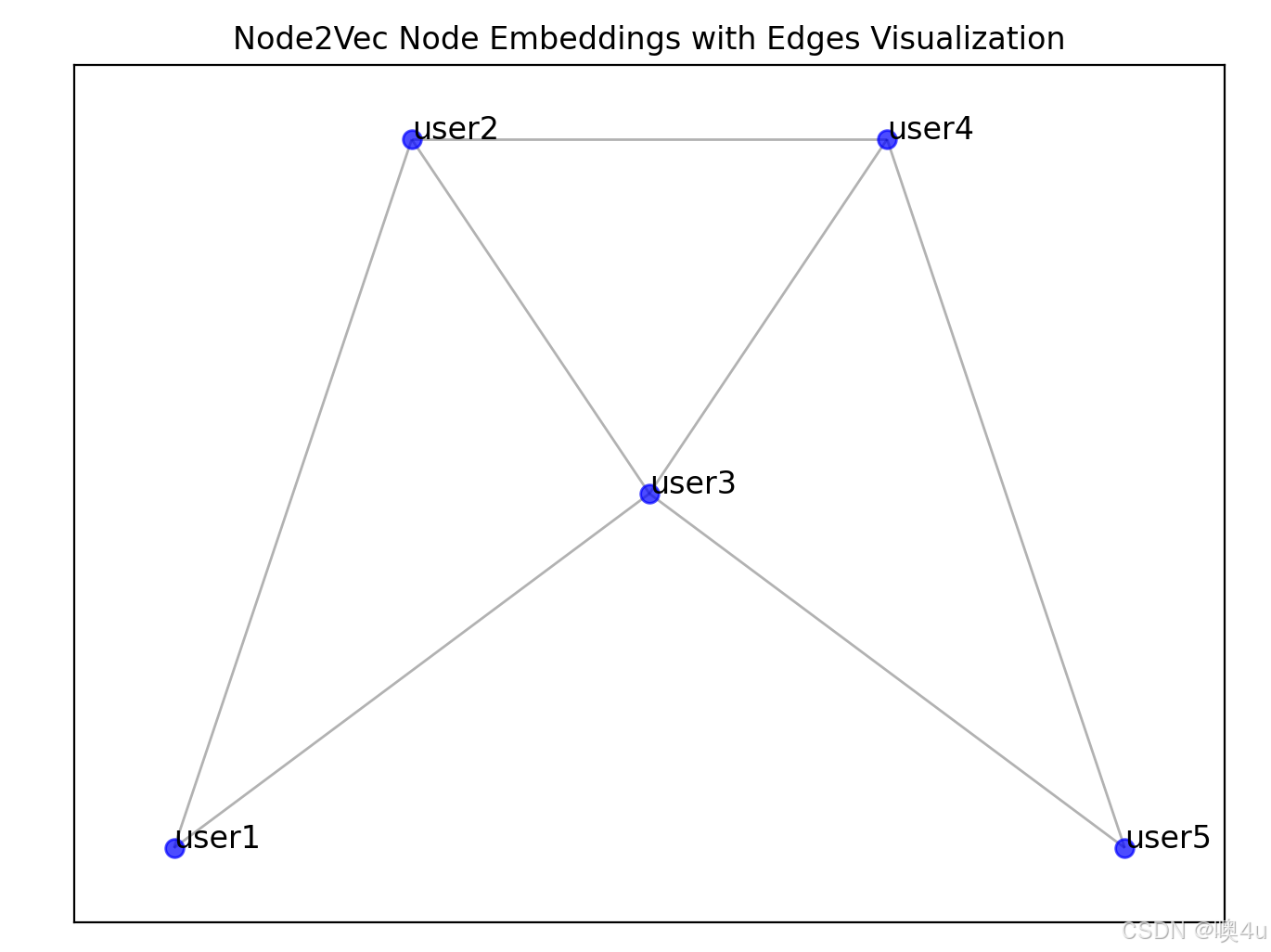
node2vec模型连通图可视化
与上文中的“网络图”相同
使用 node2vec 模型生成节点的嵌入后,可以利用 networkx 结合 matplotlib 可视化节点的嵌入结果。
import pandas as pd
import networkx as nx
import matplotlib.pyplot as plt
from node2vec import Node2Vec
from sklearn.decomposition import PCA
import numpy as np
# 根据用户属性和边文件构建图
def build_user_graph(user_attributes, edges):
G = nx.Graph()
for _, row in edges.iterrows():
user1, user2 = str(row.iloc[0]), str(row.iloc[1])
if user1 in user_attributes and user2 in user_attributes:
G.add_edge(user1, user2)
return G
# 假设有用户属性数据
user_attributes = {
"user1": {"age": 25, "location": "A"},
"user2": {"age": 30, "location": "B"},
"user3": {"age": 22, "location": "A"},
"user4": {"age": 27, "location": "C"},
"user5": {"age": 35, "location": "B"},
}
# 直接在代码中生成伪数据(边数据)
edges_data = {
'user1': ['user2', 'user3'],
'user2': ['user3', 'user4'],
'user3': ['user4', 'user5'],
'user4': ['user5']
}
# 将伪数据转化为 DataFrame 格式
edges = []
for user, friends in edges_data.items():
for friend in friends:
edges.append([user, friend])
edges_df = pd.DataFrame(edges, columns=['user1', 'user2'])
# 构建用户图
G = build_user_graph(user_attributes, edges_df)
# 使用node2vec模型生成节点嵌入
node2vec = Node2Vec(G, dimensions=2, walk_length=30, num_walks=200, workers=4)
model = node2vec.fit()
# 获取节点的嵌入
embeddings = model.wv
# 获取每个节点的嵌入
node_embeddings = np.array([embeddings[str(node)] for node in G.nodes])
# 使用PCA将高维嵌入降维到2D
pca = PCA(n_components=2)
reduced_embeddings = pca.fit_transform(node_embeddings)
# 可视化嵌入
plt.figure(figsize=(8, 6))
# 手动指定节点坐标(例如,可以指定每个节点的X, Y坐标)
manual_pos = {
'user1': (0, 0),
'user2': (1, 1),
'user3': (2, 0.5),
'user4': (3, 1),
'user5': (4, 0)
}
# 绘制图的边
# nx.draw_networkx_edges(G, pos={node: reduced_embeddings[i] for i, node in enumerate(G.nodes)}, alpha=0.3)
nx.draw_networkx_edges(G, pos=manual_pos, alpha=0.3)
# 绘制节点的嵌入位置
# plt.scatter(reduced_embeddings[:, 0], reduced_embeddings[:, 1], s=50, c='blue', alpha=0.7)
plt.scatter([manual_pos[node][0] for node in G.nodes], [manual_pos[node][1] for node in G.nodes], s=50, c='blue', alpha=0.7)
# 为每个节点添加标签
# for i, node in enumerate(G.nodes):
# plt.text(reduced_embeddings[i, 0], reduced_embeddings[i, 1], str(node), fontsize=12)
for node, (x, y) in manual_pos.items():
plt.text(x, y, node, fontsize=12)
plt.title("Node2Vec Node Embeddings with Edges Visualization")
plt.show()
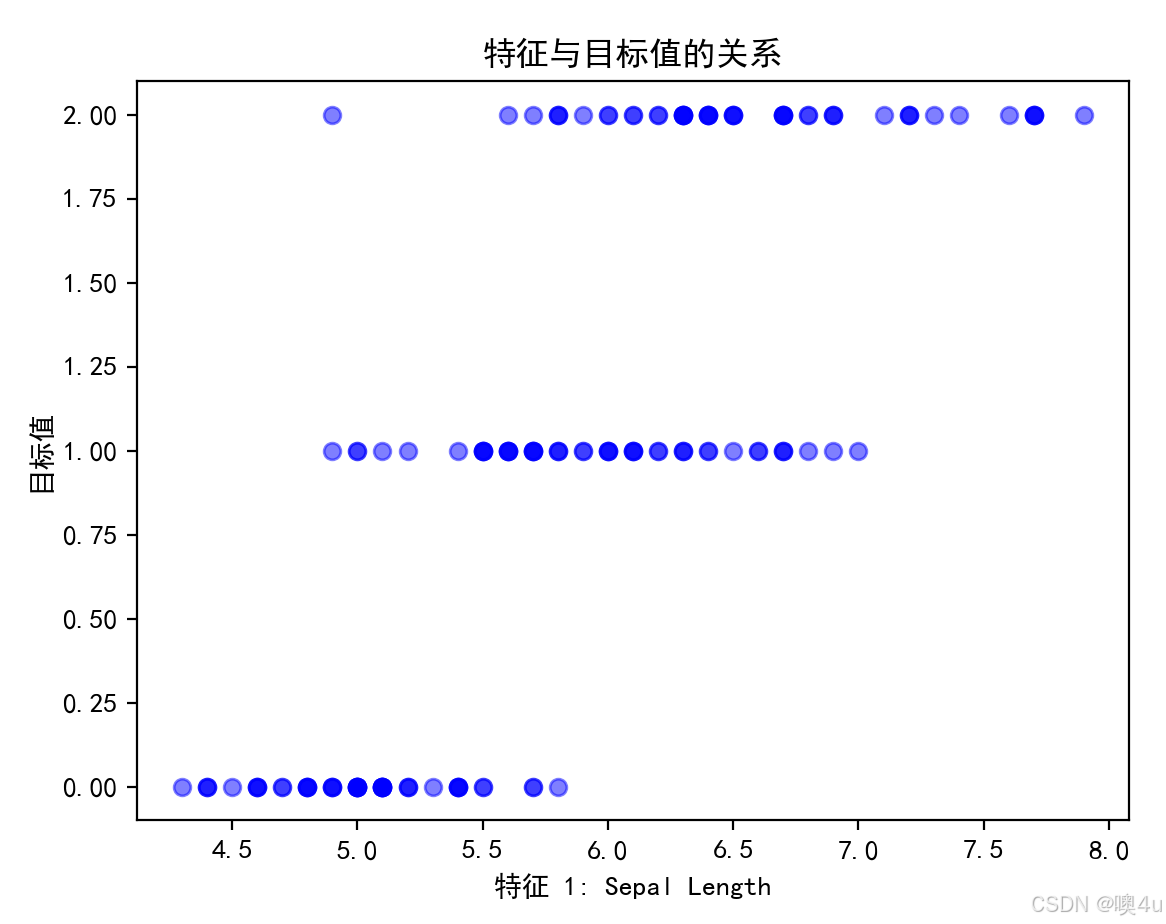
特征与目标值的关系可视化
通过可视化特征与目标值之间的关系,帮助识别哪些特征可能与目标值相关,进而决定是否使用该特征进行训练。 用散点图实现。
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
# 设置中文字体和负号显示
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 加载数据集
iris = load_iris()
X = iris.data
y = iris.target
# 绘制特征与目标值的关系
plt.scatter(X[:, 0], y, color='blue', alpha=0.5)
plt.title('特征与目标值的关系')
plt.xlabel('特征 1: Sepal Length')
plt.ylabel('目标值')
plt.show()
总结
本文详细介绍了多种数据可视化方法,涵盖了数据分析和模型解释性可视化。首先,介绍了常见的数据可视化图表,包括核密度图、箱线图、小提琴图、气泡图、蜂群图、三维散点图、折线图、雷达图、散点图回归线、条形分布图、堆叠条形图、饼图、配对图、热力图、极坐标图、分面图、区域图、平行坐标图、漏斗图、瀑布图、树状图、甘特图、桑基图、旭日图、蜡烛图、地图,以及文字形式的词云图、网络图等,它们用于分析数据分布、比较不同类别的特征以及展示数据间的关系。最后,介绍了多种用于模型解释的图表,如梯度下降过程的三维可视化、训练集与测试集分布对比图等,这些图表有助于分析模型的拟合效果以及数据的分布情况。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









