







写在前面
前两篇已经概览了nlp话题中的词汇和句法,在本篇博客中,将讨论对语篇和歧义字词的处理。
本系列文章是我的学习笔记,涵盖了入门的基础知识与模型以及对应的上机实验,截图截取自老师的课程ppt。
- 概论
- 词汇分析
- 句法分析
- 语篇分析--词汇+句法综合
- 语义分析
- 语义计算
- 语言模型
- 文本摘要
- 情感分析
- 部分对应上机实验
目录
概念依存理论(Conceptual Dependency, CD)
词义消歧(Word Sense Disambiguation, WSD)
语义角色标注(Semantic Role Labeling, SRL)
概述
语义计算的核心目标是解释自然语言中各个组成部分的含义,包括:
- 词汇层面:词、词组的意义。
- 句子层面:句子的整体含义。
- 篇章层面:段落或篇章的语义连贯性。
语义计算需要将语言单元(如词、句)映射到机器可理解的逻辑或数学模型。涉及对歧义、上下文依赖、隐喻等复杂现象的处理。
语义计算面临的困难:
-
自然语言的歧义性
- 指代歧义:代词或名词的指代对象不明确。
例:“张三告诉李四他错了” → “他”指张三还是李四? - 同义/多义:同一词在不同语境有不同含义。
例:“bank”可指“银行”或“河岸”。 - 量词辖域:量化表达的范围模糊。
例:“每个学生读过一本书” → 是同一本书还是不同书? - 隐喻:非字面意义的表达。
例:“这件事让我头疼” → 实际指“困难”,非生理疼痛。
- 指代歧义:代词或名词的指代对象不明确。
-
主观理解的差异性
-
同一句子可能因文化背景、个人经验导致不同解读。
例:“这人真恶心!” → 可能指行为、外貌或道德评价。
-
-
理论与模型的不成熟
- 现有语义计算模型(如逻辑表示、统计方法)尚未完全解决语言复杂性。
- 缺乏统一的语义表示框架。
语义理论简介
语义理论试图从不同角度解释“意义”的本质,并构建形式化模型以支持自然语言处理。每种理论对“意义”的定义和计算方法不同。
- 词的指称作为意义:词的意义是它在现实世界中对应的具体事物(指称对象)。需构建世界模型(如知识图谱)将词映射到实体。
- “启明星”和“暮星”都指金星。“猫”指现实中的猫这种动物。
- 无法处理抽象概念(如“爱情”“正义”)。虚构实体(如“孙悟空”)无现实指称。
-
心理图像作为意义:词的意义是它在大脑中引发的心理图像或联想。
- “狗”可能让人联想到“吠叫”“四条腿”等形象。
- 心理图像难以形式化表示(计算机无法直接处理主观联想)。抽象词(如“民主”)缺乏清晰图像。
-
说话者意图作为意义:意义是说话者希望通过语言实现的行为(言语行为理论)。
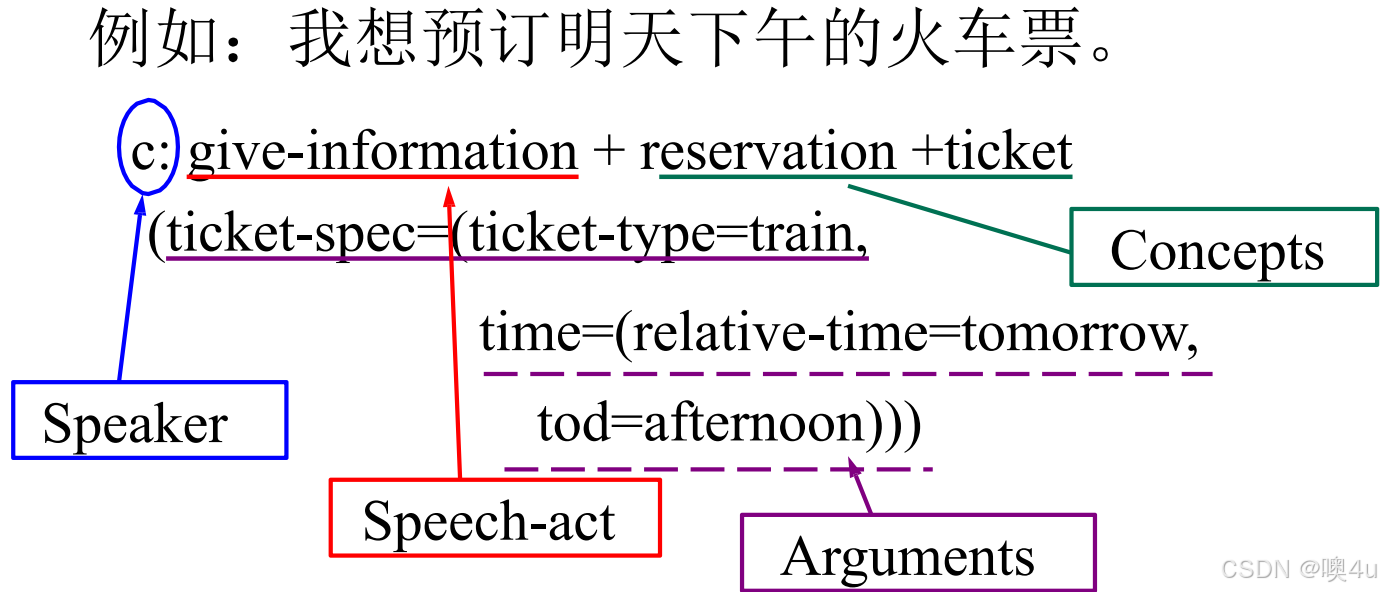
- 意图分类复杂(如讽刺、隐喻需额外推理)。意图的定义、划分、表示是困难的。
-
过程语义:句子的意义是计算机执行的动作或程序。
- 输入“打开灯” → 触发智能家居的开灯操作。
- 直接应用于任务型对话系统(如Siri)。但过度依赖具体应用,缺乏普适性。
-
词汇分解学派:词义可分解为有限个语义基元(Primitive),通过组合表示复杂意义。
- “杀” = [CAUSE] + [DIE]。
- 基元定义主观(如“爱”如何分解?)。组合规则难以标准化。
-
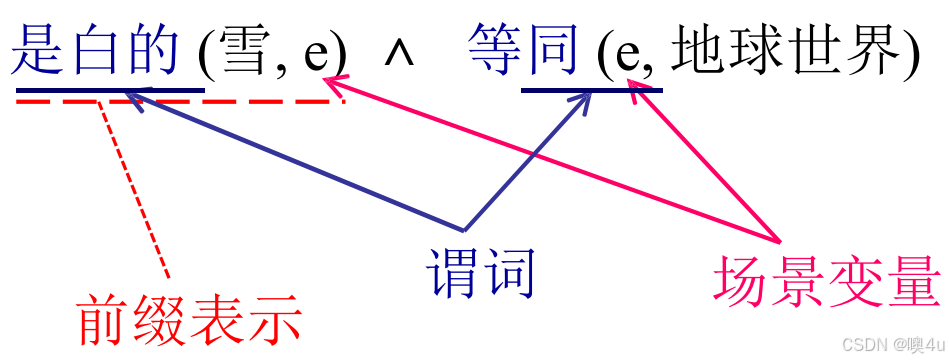
条件真理模型:句子的意义是其逻辑命题在真实世界中的真值。
- “雪是白的”为真 ⇔ 现实中雪是白的。
- 适合形式逻辑推理。但无法处理模糊表达(如“有点冷”)、无法处理对时间、场景的描述和一词多义的问题。
-
情景语义学:意义需结合具体场景(时间、地点、事件等变量)。
- 用逻辑“与”算子对变量加以控制。
- 可以解决上下文依赖问题。
- 用逻辑“与”算子对变量加以控制。
-
模态逻辑:用逻辑公理系统刻画特殊语言现象(如可能性、必要性)。
- “鸟会飞”是一般规则,但“企鹅不会飞”是例外。
- 公理系统难以覆盖所有例外。
- .......
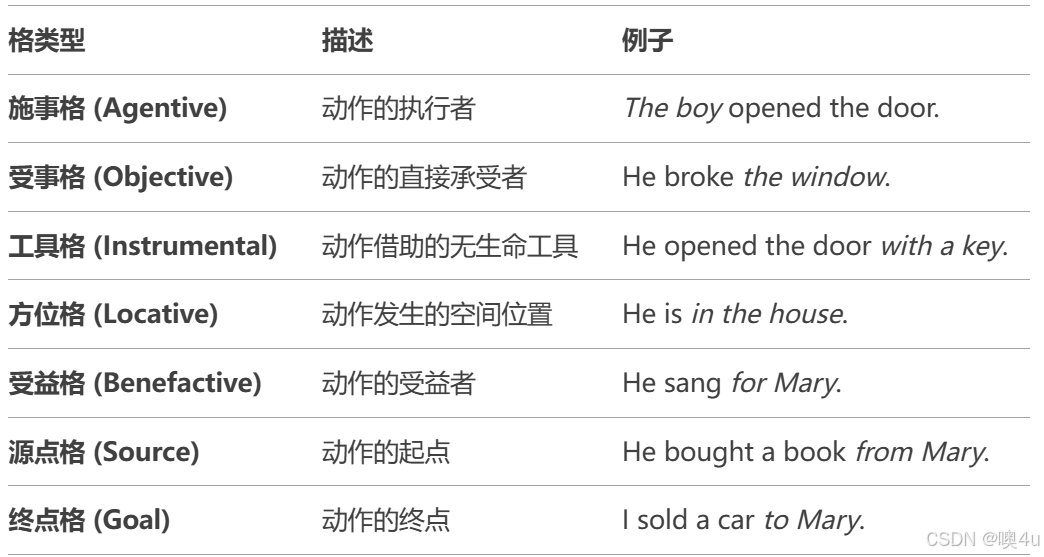
格语法(Case Grammar)
格语法由美国语言学家 Charles J. Fillmore 在1966年提出,是一种关注深层语义角色的理论,旨在揭示句子中名词短语与动词之间的及物性关系(如施事、受事、工具等),而非表层语法关系(如主语、宾语)。
诸如主语、宾语等语法关系实际上都是表层结构上的概念,在语言的底层,所需要的不是这些表层的语法关系,而是用施事、受事、工具、受益等概念所表示的句法语义关系。这些句法语义关系,经各种变换之后才在表层结构中成为主语或宾语。
应用与意义:
- 自然语言处理:
- 语义角色标注(SRL)的基础理论。
- 帮助机器理解“谁对谁做了什么”。
- 语言学:
- 揭示跨语言的共性语义关系。
关键贡献:
- 突破表层语法,揭示句子的深层语义结构。
- 为后续语义网络、概念依存理论提供启发。
格的定义
深层格 vs 表层格
- 表层格:传统语法中的主、宾、属等(如英语的主语/宾语形式)。
- 深层格:句子底层存在的语义角色,与动词的语义关系固定,不受表层语法变化影响。
动词中心论
- 动词是句子的核心,名词短语通过格角色依附于动词。
- 例如:“开”需要施事(谁开)、受事(开什么)、可选工具(用什么开)。
- 格的数目和名称是不固定的。
三条形式化基本规则
- 句子结构规则:S→M+P,句子 S 可以改写成情态(Modality)和命题(Proposition) 两大部分。
- M (Modality):情态(时态、否定、语气等)。
- P (Proposition):命题(动词+格角色)。
- 命题展开规则:P→V+C1+C2+⋯+Cn,命题 P 都可以改写成一个动词 V 和若干个格 C 。
- V:动词(广义,含形容词、名词等)。
- C:格角色(如施事、受事)。
- 格角色实现规则:C→K+NP
- K:格标记(如介词“with”标记工具格)。
- NP:名词短语。
格框架
格框架中可以有语法信息,也可以有语义信息,语义信息是整个格框架最基本的部分。
一个格框架可由一个主要概念和一组辅助概念组成,这些辅助概念以一种适当定义的方式与主要概念相联系。一般地,在实际应用中,主要概念可理解为动词,辅助概念理解为施事格、受事格、处所格、工具格等语义深层格。
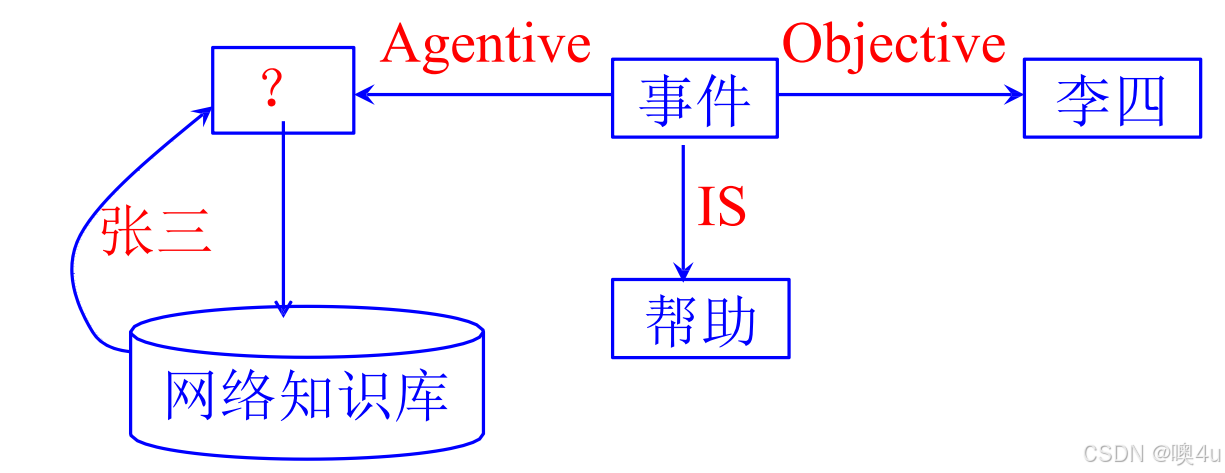
例句:In the room, he broke a window with a hammer.
[BREAK
[Case-frame:
[Agentive: HE]
[Objective: WINDOW]
[Instrumental: HAMMER]
[Locative: ROOM]
]
[MODALS:
[Time: past]
[Voice: active]
]
] - 确定核心动词:broke。
- 从词典查动词的格框架:break 需施事、受事,可选工具、方位。(规定它们所属的必备格、可选格或禁用格,同时填充这些格的名词的语义条件。如:《动词用法词典》把名词按其与动词格的关系分为14类:受事、结果、对象、工具、方式、处所、时间、目的、原因、致使、施事、同源、等同、杂类)
- 填充名词短语到对应格:(对于名词:识别语义信息,具体方法见本专栏第2.3篇)
- he → 施事格
- a window → 受事格
- with a hammer → 工具格
- in the room → 方位格
- 判断句子的情态Modal。
格语法描写汉语的局限性
格语法在处理汉语时面临挑战:
- 无主句:如“下雨了”(缺施事)。
- 连动句:如“他拿书上楼”含多个动词(拿、上),(需拆分多个格框架)。
- 省略与紧缩:如“选他当班长”隐含兼语结构(“他”既是“选”的受事,又是“当”的施事)。
- 流水句:(很多逗号)
语义网络(Semantic Network)
语义网络是一种基于图结构的知识表示方法,用于表达概念之间的语义关系。它由心理学家 M. R. Quilian 于1968年提出,后由AI学者 G. Hendrix 改进,结合了格语法和逻辑表示,广泛应用于自然语言理解和知识图谱构建。
现代应用
- 知识图谱:如Google Knowledge Graph。
- 问答系统:通过语义关系匹配答案。
- 自然语言生成:基于网络结构生成连贯文本。
基本概念
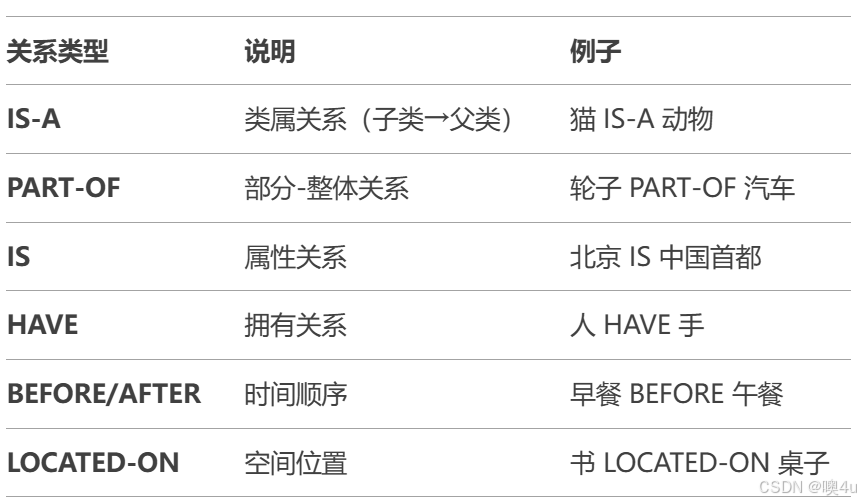
语义网络通过有向图表示知识:
- 节点(Node):表示概念(如对象、事件、属性)。
- 边(Edge):表示概念间的语义关系
常见语义关系
语义网络的表示能力
事件表示:结点之间的关系可以是施事、受事、时间等。

分类关系:通过 IS-A 层级表示概念的抽象与具体化:支持继承推理(如“企鹅是鸟 ⇒ 企鹅有翅膀”)。
动物
├─ IS-A → 鸟
│ ├─ IS-A → 企鹅
│ └─ IS-A → 鸽子
└─ IS-A → 哺乳动物 聚焦关系:表示由多个部分组成的复合概念:
汽车
├─ PART-OF → 发动机
├─ PART-OF → 轮子
└─ PART-OF → 方向盘 推论关系:由一个概念推出另一个概念(带伞--(推出)-->下雨了)。
时间、位置关系:事实发生或存在的时间、位置。
基于语义网络的推理、分析
(1)根据提出的问题构成局部网络;
(2)用变量代表待求的客体。
词义内涵:词本身的意义,是对词代表的概念描述。
词义外延:词所指代的物体。
语义网络支持以下推理任务:
- 继承推理:通过 IS-A 链推导属性。已知:鸽子 IS-A 鸟,鸟 HAVE 翅膀 ⇒ 鸽子 HAVE 翅膀。
- 关系查询:问:“汽车的组成部分有哪些?” → 遍历 PART-OF 边。
- 指代消解:通过上下文关联确定代词所指(如“它”指向网络中的“猫”)。
具有直观、灵活、可推理的优点;但关系表达具有局限性、计算复杂度高(大规模网络遍历困难)、无法解决起歧义问题(同一个词可能有多个节点。)
概念依存理论(Conceptual Dependency, CD)
概念依存理论(Conceptual Dependency, CD)由 Roger Schank 在20世纪70年代提出,是一种基于动作和事件的语义表示框架,旨在通过有限的抽象动作基元描述复杂的人类行为和心理活动,使计算机能更自然地理解语言。
现代影响:
- 对话系统:CD的脚本思想用于任务型对话流程设计。
- 故事生成:通过基元组合生成连贯叙事。
- 机器人规划:如“拿杯子”分解为GRASP + PTRANS。
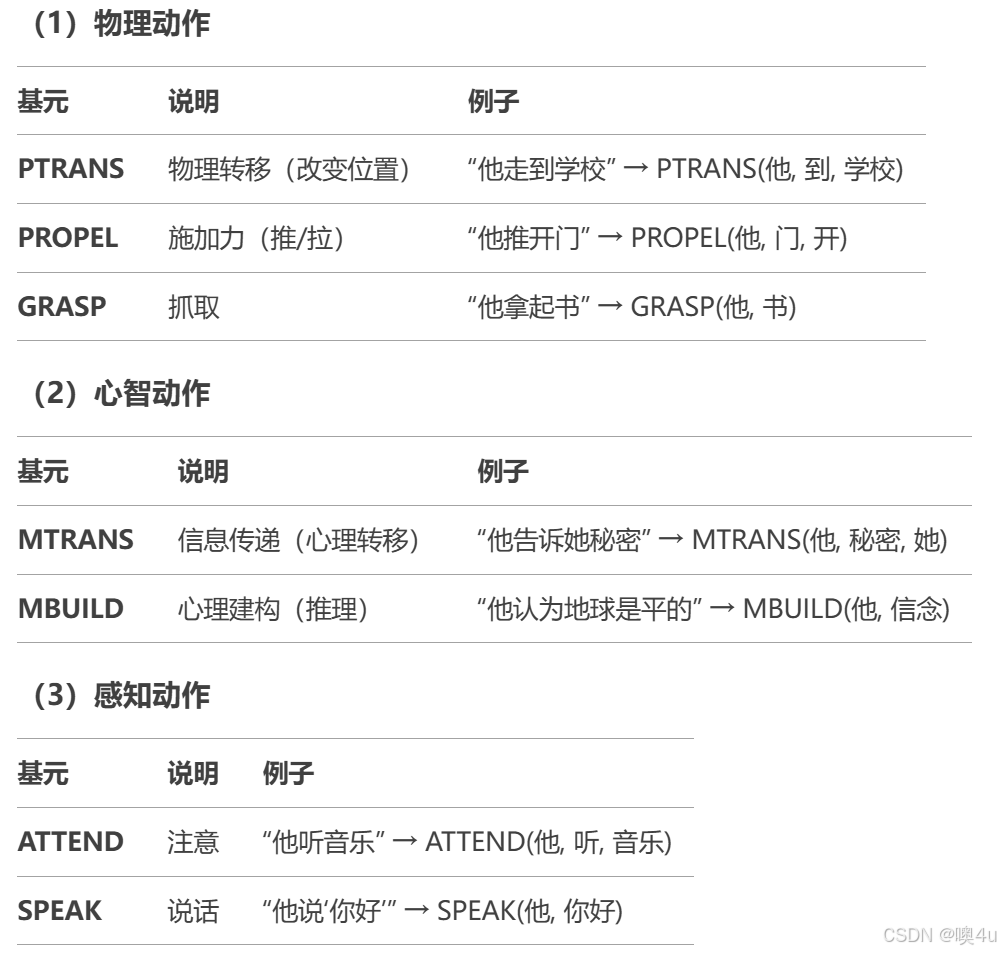
核心理论由三个层次组成:
- 动作基元(Primitive Acts):所有复杂动作均可分解为有限数量的原子动作(类似化学元素)。
- 例如:“吃”可拆解为 INGEST(摄入)+ MOVE(食物到嘴)。
- 事件脚本(Scripts):常见场景(如“餐厅用餐”)由固定动作序列组成。
- 进入餐厅 → PTRANS(顾客, 到, 餐厅)
- 点餐 → MTRANS(顾客, 菜单, 服务员) + SPEAK(顾客, “我要牛排”)
- 用餐 → INGEST(顾客, 牛排)
- 付款 → ATRANS(顾客, 钱, 服务员)
- 计划(Plans):高层次目标通过组合多个脚本来实现(如“旅行计划”)。
- 准备行李 → Script(打包)
- 前往机场 → PTRANS(人, 家, 机场)
- 乘飞机 → Script(登机)
- 若延误 → 触发 Script(改签)
Schank定义了11种基本动作基元,分为三类:
它严格标准化,但过于简化。
词义消歧(Word Sense Disambiguation, WSD)
词义消歧是自然语言处理中的核心任务,旨在根据上下文确定多义词的具体含义。例如:
- “bank”:银行(金融机构) / 河岸(地理实体)
- “打”:打电话(dial) / 打毛衣(weave) / 打人(hit)
词义消歧是NLP中的经典挑战,方法从早期规则到现代深度学习不断演进。
与其他任务的关联:
- 机器翻译:正确选择源语言词义以生成目标语(如“bank” → “银行”或“河岸”)。
- 信息检索:避免查询歧义(如“Java”指编程语言还是咖啡)。
- 知识图谱:链接实体时需消歧(如“苹果公司” vs “水果苹果”)。
三类基本方法
(1)基于规则的方法
- 思想:利用语言学规则(如搭配、语法约束)判断词义。
- 示例:
- 规则:若“bank”与“money”共现 → 义项“银行”。
- 规则:若“打”后接“电话” → 义项“dial”。
- 优缺点:
- ✅ 无需标注数据,可解释性强。
- ❌ 规则设计耗时,覆盖率低。
(2)基于统计机器学习的方法
① 有监督学习
- 步骤:
- 标注训练数据(标记多义词的义项)。
- 提取特征(上下文词、词性、句法关系等)。
- 训练分类器(如SVM、最大熵)。
- 经典算法:
- Flip-Flop算法(Brown et al., 1991):
- 基于双语对齐语料,利用互信息最大化划分义项。
- 例:法语“prendre”在“prendre une décision”中译作“make”,在“prendre une mesure”中译作“take”。
- 贝叶斯分类器:计算义项在上下文中的概率。
- Flip-Flop算法(Brown et al., 1991):
② 无监督学习
- 思想:通过聚类将相似上下文的词义归类。
- 示例:
- Schütze (1998) 的上下文分组法:
- 计算词的“关联向量”(上下文词分布)。
- 用EM算法聚类相似上下文,对应不同义项。
- Schütze (1998) 的上下文分组法:
- 优缺点:
- ✅ 无需标注数据。
- ❌ 聚类结果可能不符合真实义项。
(3)基于词典的方法
利用现有词典资源(如WordNet、HowNet)进行消歧:
① 基于语义定义的消歧
- 思想:若上下文词与词典中义项的定义匹配,则选择该义项。
- 例:
- “cone”在词典中的两个定义:
- 松树的球果(定义含“树”)→ 上下文出现“tree”则选此义。
- 冰激凌锥筒(定义含“冰”)→ 上下文出现“ice”则选此义。
- “cone”在词典中的两个定义:
② 基于义类辞典(Thesaurus)的消歧
- 思想:多义词的不同义项属于不同语义类,通过上下文词的语义类判断。
- 例:
- “crane”:
- 义项“鹤” → 语义类
ANIMAL(共现词:species, fly)。 - 义项“起重机” → 语义类
MACHINE(共现词:engine, lift)。
- 义项“鹤” → 语义类
- “crane”:
③ 基于双语词典的消歧
- 思想:利用另一种语言的翻译倾向性。
- 例:
- “plant”:
- “manufacturing plant”中“plant”的汉语翻译多与“工厂”共现 → 义项“工厂”。
- “plant life”中“plant”的汉语翻译多与“植物”共现 → 义项“植物”。
- “plant”:
④ Yarowsky算法(半监督方法)
- 核心假设:
- 单一文本单义性:同一文档中多义词的义项一致。
- 搭配一致性:特定搭配(如“银行账户”)总对应同一义项。
- 步骤:
- 初始种子:少量标注数据(如“bank”与“money”共现 → 银行)。
- 自举(Bootstrapping):迭代扩展高置信度样本。
关键技术挑战
- 特征选择:有效特征包括:窗口词(±5词)、词性、句法依赖、语义角色等。
- 数据稀疏性:低频义项或罕见上下文导致分类困难。
- 跨领域适应性:领域变化可能改变词义分布(如“病毒”在医学 vs 计算机领域)。
性能与评估
- 常用数据集:Senseval/SemEval评测任务、WordNet语料库。
- 指标:准确率(Accuracy)、F1值。
- 当前水平:
- 有监督方法:F1约70%-80%(依赖标注数据质量)。
- 无监督方法:F1约50%-60%。
领域适应与低资源消歧仍是该方向的研究热点。
指代消解(Coreference Resolution)
指代消解是确定文本中不同表述是否指向同一实体的任务。例如:
- 张三一大早就赶到了学校。他先到食堂吃早餐,然后[ ]到[ ]宿舍拿[ ]教材。
- 需要确定:
- “他” → 指代“张三”
- “[ ]”(零指代)→ 隐含主语“他”
- 需要确定:
应用场景:
| 应用领域 | 作用 |
|---|---|
| 机器翻译 | 确定代词性别/数(如“they” → “他们”/“她们”/“它们”) |
| 文本摘要 | 替换重复名称(如“比尔·盖茨” → “他”)以提高流畅性 |
| 信息抽取 | 建立实体关系(如“马云”与“阿里巴巴”的关联) |
| 对话系统 | 理解用户指代(如“它”指上文提到的“订单”) |
基本概念
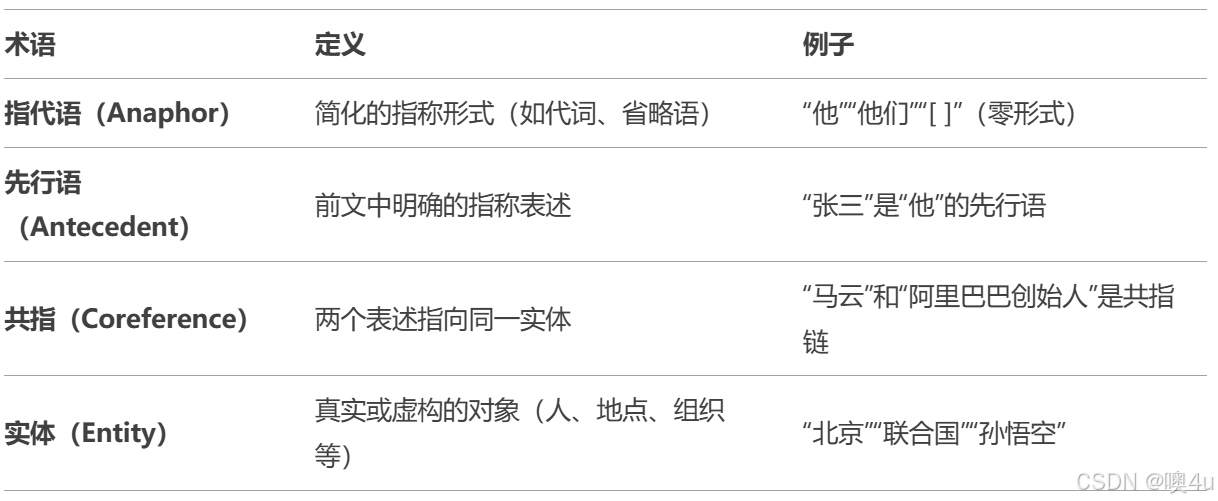
指代类型:
- 代词指代(Pronominal Anaphora)
- 例:李四提交了报告,他很满意。 → “他”指“李四”。
- 名词短语指代(Nominal Anaphora)
- 例:一只黑猫蹲在门口。这小动物看起来很饿。 → “这小动物”指“黑猫”。
- 零指代(Zero Anaphora)
- 汉语常见:省略主语或宾语,需通过上下文恢复。
- 例:张三对[ ]弟弟很好,[ ]总是帮[ ]整理书包。 → 省略部分均指“张三”。
- 汉语常见:省略主语或宾语,需通过上下文恢复。
- 抽象指代(Abstract Anaphora):指代抽象概念(如事件、观点)。
- 例:经济危机爆发了,这影响了全球市场。 → “这”指“经济危机”。
汉语的消解挑战:
- 零指代的高频性:例:医生让[ ]多喝水。(省略“你”)
- 称谓多样性:同一实体可能有多个称谓(如“马云”“阿里巴巴创始人”“马老师”)。
- 抽象指代:例:这种做法不合理,必须停止。 → “这种做法”需回溯前文事件。
指代消解方法
(1)基于规则的方法
- 过滤规则:
- 性别/数一致性:
- “玛丽” → “她”(而非“他”)。
- 句法平行:
- “A喜欢B,C也喜欢他” → “他”更可能指B(与A平行)。
- 性别/数一致性:
- 优选规则:
- 最近距离优先:选择最近的候选先行语。
(2)基于机器学习的方法
- 特征工程:

-
分类模型:
- 二分类:判断两个表述是否共指。
- 常用模型:最大熵、SVM、神经网络。
(3)基于端到端深度学习的方法
- 模型:SpanBERT(Joshi et al., 2020):直接预测文本跨度的共指关系。
- 优势:自动学习上下文特征,减少人工规则依赖。
指代消解是NLP中篇章理解的核心任务,需结合语法、语义、语用线索。
- 难点:零指代、抽象指代、跨句共指。
- 趋势:深度学习模型(如SpanBERT)逐步取代传统规则方法。
- 关键点:上下文建模与实体一致性维护。
语义角色标注(Semantic Role Labeling, SRL)
语义角色标注是以句子中的谓词(动词、形容词等)为核心,分析句子中其他成分与谓词之间的语义关系的任务。例如:[他们]ᴬᵍᵉⁿᵗ [昨天]ᵀᶦᵐᵉ [在北京]ᴸᵒᶜ [讨论]ᴾʳᵉᵈ 了 [方案]ᴾᵃᵗᶦᵉⁿᵗ。
标注结果明确谁(施事)在何时何地(时间/地点)对什么(受事)做了什么动作。
| 应用 | 作用 |
|---|---|
| 信息抽取 | 从“收购(A0:微软, A1:动视暴雪)”提取实体关系 |
| 问答系统 | 理解“谁在哪里做了什么”类问题 |
| 机器翻译 | 保留语义角色结构(如“被”字句→被动语态) |
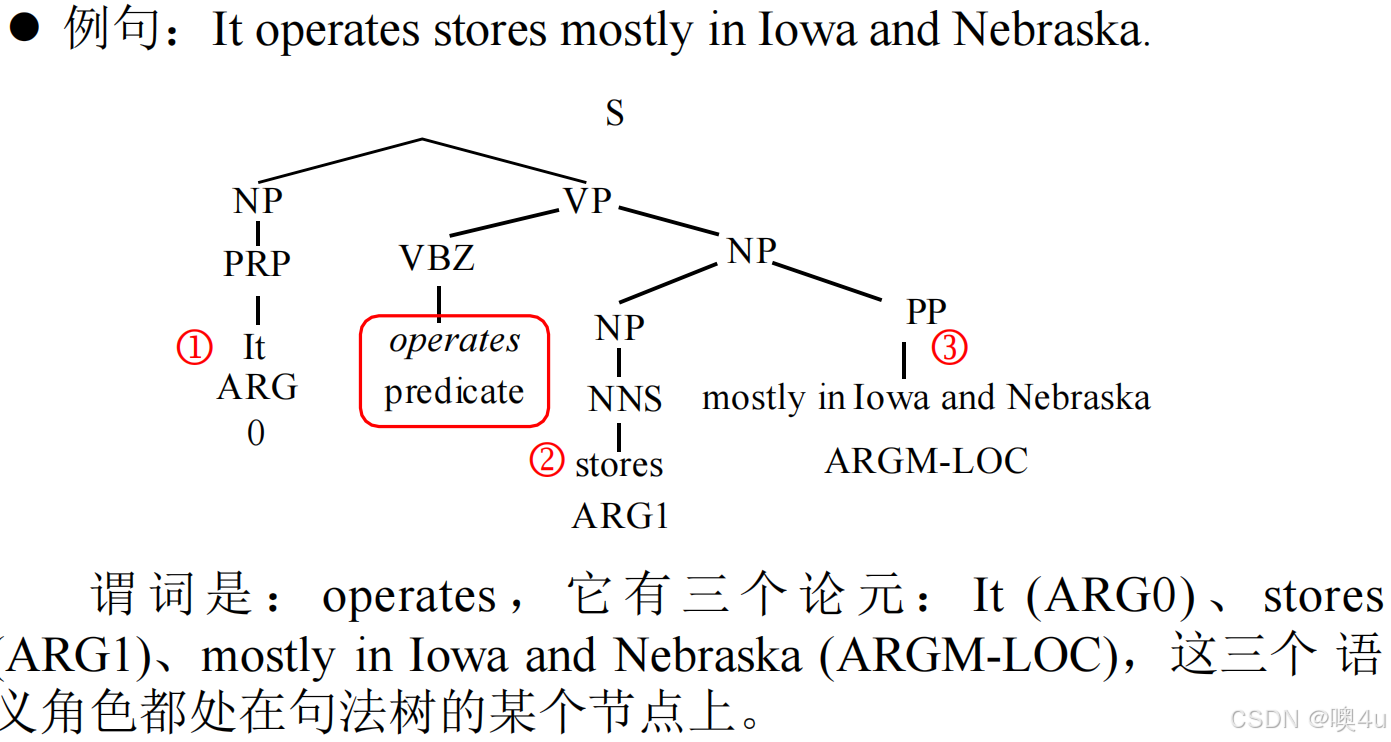
基本概念
| 术语 | 定义 | 例子 |
|---|---|---|
| 谓词(Predicate) | 句子中表达动作或状态的核心词(动词、形容词等) | “吃”“讨论”“美丽” |
| 论元(Argument) | 参与谓词所描述事件的成分(如施事、受事、工具等) | “张三”是“吃”的施事 |
| 语义角色 | 论元与谓词之间的功能关系(如Agent, Patient, Location) | “用刀”中“刀”是工具格(Instrument) |
语义角色分类:
以 PropBank 和 CPB(Chinese PropBank) 为例:
- 核心角色(Core Arguments):
- ARG0:施事者(Agent)
- ARG1:受事者(Patient)或主题
- ARG2-ARG5:依谓词而定(如接受者、工具、终点等)
- 附加角色(Adjuncts):
- ARGM-TMP:时间(昨天)
- ARGM-LOC:地点(在北京)
- ARGM-MNR:方式(仔细地)
中文SRL的特殊性:
-
零形式论元:
-
汉语常省略主语/宾语,需通过上下文恢复。
-
例:“[ ] 看完报告后,[ ] 提出了意见。” → 隐含主语需推断。
-
-
动词短语连用:
-
例:“他[打电话]ᴾʳᵉᵈ [叫车]ᴾʳᵉᵈ” → 需分别标注两个谓词的论元。
-
语义角色标注流程
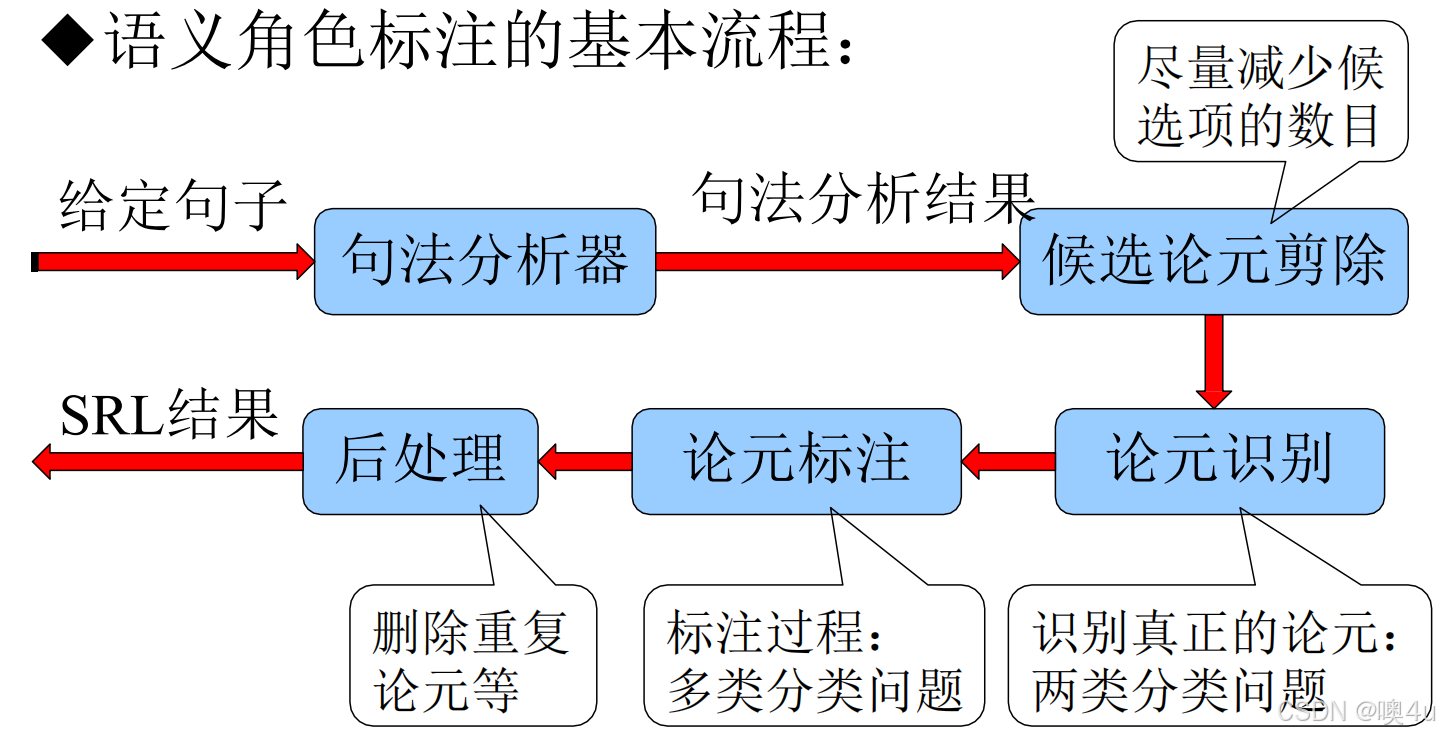

三种主要方法
(1)基于短语结构句法分析的SRL
-
步骤:
-
剪枝规则:
-
从谓词出发,遍历句法树,选择兄弟节点和父节点路径上的非并列成分。
-
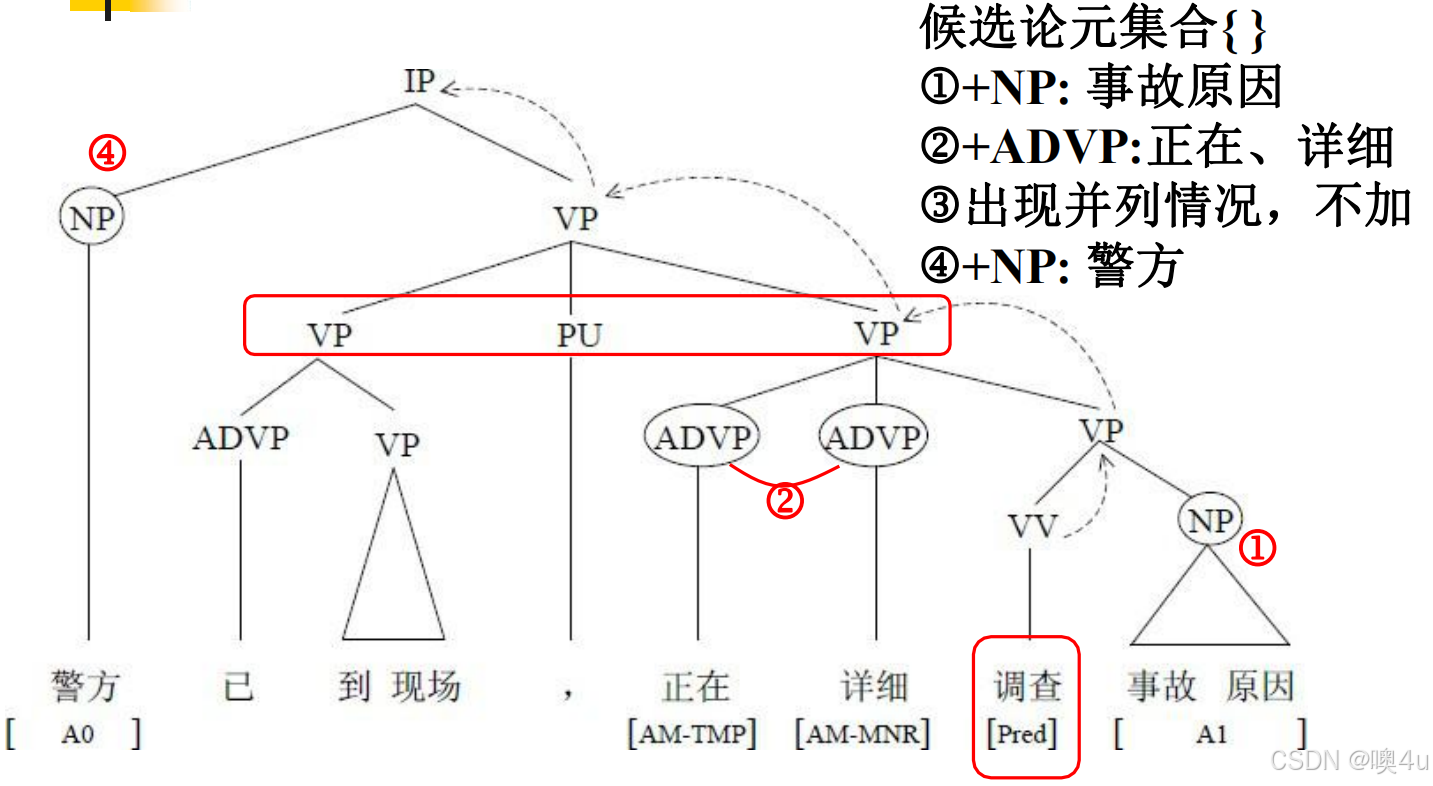
例:
[IP [NP 警方] [VP [ADVP 正在] [VP 调查 [NP 事故原因]]]] → 候选论元:警方(ARG0)、事故原因(ARG1)、正在(ARGM-TMP)
-
-
特征提取:
-
路径特征:句法树上从论元到谓词的路径(如
NP↑IP↓VP)。 -
短语类型:论元的句法标签(NP、PP等)。
-
中心词:论元的核心词及其词性。
-
-
(2)基于依存句法分析的SRL
- 特点:论元由中心词表示,而非完整短语。
- 剪枝规则:选择谓词的所有子节点及其祖先路径上的节点。
- 关键特征:
- 依存关系路径:如
nsubj←root→dobj。 - 谓词语态:主动/被动影响角色分配(如被动句中主语可能是ARG1)。
- 依存关系路径:如
(3)基于语块(Chunking)的SRL
- 将SRL视为序列标注问题,采用 BIO标签(Begin, Inside, Outside):
警察 ARG0 | 已 ARGM-TMP | 调查 Pred | 事故原因 ARG1 - 优点:无需句法分析器,适合轻量级应用。
性能与挑战
- F1值:英语/汉语SRL的F1约为70%-75%(依赖句法分析精度)。
- 主要挑战:
- 句法分析错误传播:依存树错误导致论元剪枝失败。
- 领域适应性:训练数据(如新闻)与目标领域(如医疗)的谓词论元模式差异大。
实验:词义消歧
直接可用的词义消极的工具包不多,可以使用基于词典的、基于词向量相似计算的、基于各类分类器的等思想编写语义消歧程序。
- 标注数据可用性:有监督方法(如BERT微调)通常最优,但无监督方法更通用。
- 领域适应性:预训练模型在跨领域场景表现更好。
- 可解释性:基于知识的方法更透明,但覆盖率有限。
实验内容:苹果:
- 水果。如,这个苹果真好吃,营养价值高。
- 电子品牌。如,苹果手机配置不高,但整体性能优化的很好。
- 电影名称。如,“苹果”上映了,听说非常精彩。
鉴于尚未有能力对大量数据进行标注,故采用“向量相似”计算的方法,使用现成模型。
from sentence_transformers import SentenceTransformer, util
import numpy as np
# 加载模型并指定缓存目录
MODEL_CACHE_DIR = r"D:\Microsoft VS Code\vs work\codeworkvs\pretrained-models"
model = SentenceTransformer(
'paraphrase-multilingual-MiniLM-L12-v2',
cache_folder=MODEL_CACHE_DIR
)
# 定义词义及其示例句子
sense_examples = {
"水果": [
"这个苹果真好吃,营养价值高。",
"苹果富含维生素C,对健康有益。",
"她从市场买了一斤红苹果。",
"苹果和香蕉都是常见的水果。",
"榨苹果汁需要新鲜的苹果。"
],
"电子品牌": [
"苹果手机配置不高,但整体性能优化的很好。",
"我刚买了最新款的苹果笔记本。",
"苹果公司的市值全球领先。",
"苹果耳机降噪效果非常出色。",
"苹果手表的心率监测功能很准。"
],
"电影名称": [
"“苹果”上映了,听说非常精彩。",
"电影《苹果》由范冰冰主演,讲述了都市女性的故事。",
"这部叫苹果的电影获得了柏林电影节提名。",
"导演李玉的作品《苹果》引发了社会讨论。",
"2007年的电影苹果反映了现实问题。"
]
}
# 待消歧的句子
test_sentences = [
"一天吃一个苹果,对身体很好。", # 水果
"这家饮品店的苹果茶味道很不错", # 水果
"我买了一部苹果14,拍照效果很棒。", # 电子品牌
"苹果和华为都是做手机很不错的品牌。", # 电子品牌
"苹果这部电影在豆瓣上的评分很不错。", # 电影名称
"去看电影吗?苹果重新上映了。" # 电影名称
]
# 计算每个义项的平均向量,物理意义:得到当前义项的“中心语义向量”,代表该义项的平均语义特征。
sense_embeddings = {
# 字典推导式:{key_expression: value_expression for item in iterable}
sense: np.mean([model.encode(ex, convert_to_tensor=True) for ex in examples], axis=0)
# 计算当前义项所有例句嵌入沿 axis=0(行方向)的平均
for sense, examples in sense_examples.items()
# 遍历每个义项和例句列表,examples:该义项的例句列表
}
# 对每个测试句子进行消歧
for sentence in test_sentences:
sentence_embedding = model.encode(sentence, convert_to_tensor=True)
# 其输出向量维度为384维,Transformer层的隐藏大小是固定的
print(f"句子: '{sentence}'")
# print(f"句子向量: {sentence_embedding}")
similarities = {
sense: util.pytorch_cos_sim(sentence_embedding, emb).item()
for sense, emb in sense_embeddings.items()
}
predicted_sense = max(similarities.items(), key=lambda x: x[1])[0]
# key=lambda x: x[1]:指定比较的是每个元组的第二个元素(即相似度分数)。
print(f"预测词义: {predicted_sense} (置信度: {similarities[predicted_sense]:.2f})")
print("---")config_sentence_transformers.json: 100%|████████████████████| 122/122 [00:00<00:00, 67.3kB/s]
README.md: 100%|████████████████████████████████████████████████| 3.89k/3.89k [00:00<?, ?B/s]
sentence_bert_config.json: 100%|██████████████████████████████████| 53.0/53.0 [00:00<?, ?B/s]
README.md: 100%|████████████████████████████████████████████████| 3.89k/3.89k [00:00<?, ?B/s]
sentence_bert_config.json: 100%|██████████████████████████████████| 53.0/53.0 [00:00<?, ?B/s]
sentence_bert_config.json: 100%|██████████████████████████████████| 53.0/53.0 [00:00<?, ?B/s]
config.json: 100%|██████████████████████████████████████████████████| 645/645 [00:00<?, ?B/s]
model.safetensors: 100%|██████████████████████████████████| 471M/471M [01:18<00:00, 6.02MB/s]
tokenizer_config.json: 100%|████████████████████████████████████████| 480/480 [00:00<?, ?B/s]
tokenizer.json: 100%|███████████████████████████████████| 9.08M/9.08M [00:00<00:00, 12.8MB/s]
tokenizer.json: 100%|███████████████████████████████████| 9.08M/9.08M [00:00<00:00, 12.8MB/s]
special_tokens_map.json: 100%|██████████████████████████████████████| 239/239 [00:00<?, ?B/s]
1_Pooling/config.json: 100%|████████████████████████████████████████| 190/190 [00:00<?, ?B/s]
句子: '一天吃一个苹果,对身体很好。'
预测词义: 水果 (相似度: 0.84)
---
句子: '我买了一部苹果14,拍照效果很棒。'
预测词义: 电子品牌 (相似度: 0.68)
---
句子: '去看电影吗?苹果重新上映了'
预测词义: 电影名称 (相似度: 0.80)
---最好需要多个例句以:
- 覆盖多样性:同一个词义在不同上下文中的表达可能不同(如“苹果”可以指“水果”或“苹果公司”)。
- 减少偏差:避免模型过度依赖某个特定句式(如只依赖“苹果手机”判断品牌义项)。
- 提升鲁棒性:模型通过多例句学习更广义的语义模式。
or如果网络不稳定,可直接去hugging_face官网手动下载。
-
点击
Files and versions选项卡,下载全部文件(包括config.json,pytorch_model.bin, 等)。 -
实验:角色语义标注
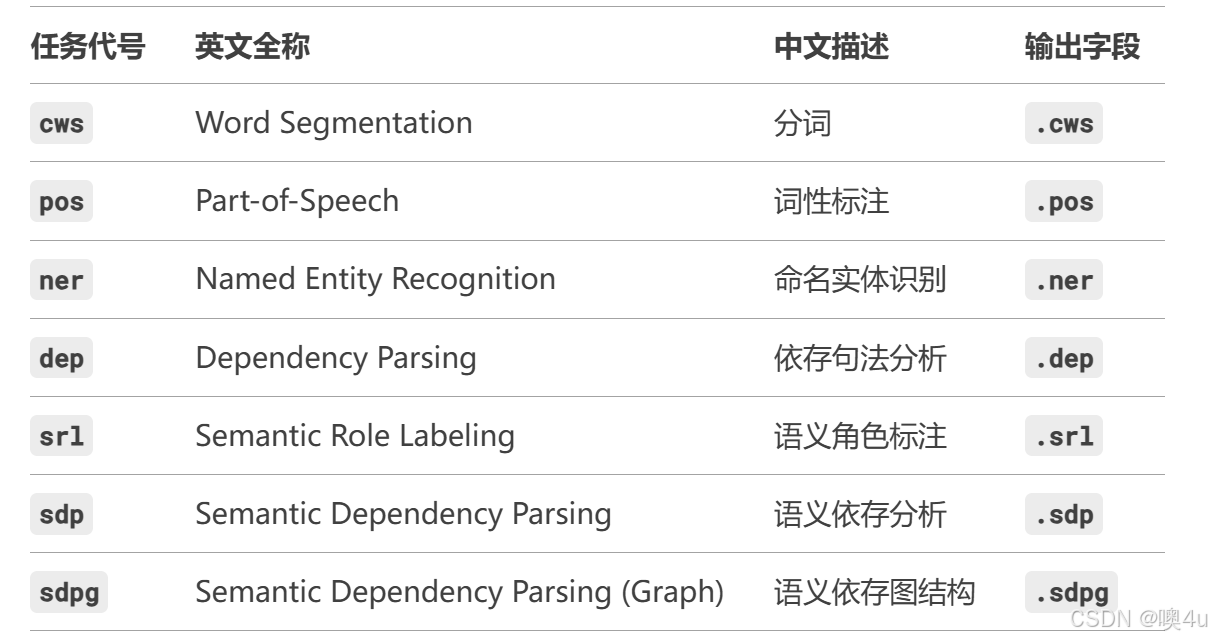
编写语义角色标注程序,并完成至少十句话的测试。使用LTP工具LTP/small模型进行中文 SRL 标注实验,依赖句法分析结果。
在 LTP v4.x 中,pipeline 支持的任务(tasks)主要包括以下 7种 核心 NLP 任务,可通过列表指定需要执行的任务:
from ltp import LTP
# 初始化LTP模型
ltp = LTP("LTP/small", cache_dir=".\pretrained-models\ltp")
# 测试句子(覆盖不同动词和论元结构)
test_sentences = [
"他打开了门", # 简单及物动词
"妈妈给孩子买了一本书", # 双宾语结构
"公司去年在深圳建立了新工厂", # 包含时间和地点
"这场暴雨导致道路积水", # 因果事件
"教授认为实验结果不够严谨", # 认知动词
"游客们兴奋地拍下了日出的照片", # 方式状语
"政府计划明年修建三座医院", # 未来事件
"小狗咬坏了我的拖鞋", # 结果补语
"会议上,经理提出了新的营销方案", # 场景描述
"如果明天下雨,比赛将延期" # 条件句
]
# 批量处理句子
output = ltp.pipeline(test_sentences, tasks=["cws", "srl"])
seg_results = output.cws
srl_results = output.srl
# 打印结果
for i, (sentence, seg, srl) in enumerate(zip(test_sentences, seg_results, srl_results)):
print(f"\n【句子 {i+1}】: {sentence}")
print(f"分词结果: {seg}")
if not srl:
print("未识别到谓词")
continue
for verb_info in srl:
print(f"谓词信息: {verb_info}")
verb = seg[verb_info["index"]] # 获取谓词
print(f"谓词: '{verb}' (位置: {verb_info['index']})")
for arg in verb_info["arguments"]:
role, word, start_idx, end_idx = arg
# 角色类型
role_name = {
# 核心论元
'A0': '施事', 'A1': '受事', 'A2': '间接宾语',
'A3': '起点', 'A4': '终点',
# 附加论元
'ARGM-TMP': '时间', 'ARGM-LOC': '地点', 'ARGM-MNR': '方式',
'ARGM-CND': '条件', 'ARGM-CAU': '原因', 'ARGM-PRP': '目的',
'ARGM-ADV': '修饰词', 'ARGM-REC': '结果', 'ARGM-BNF': '受益者'
}.get(role, role)
# 提取论元词语
arg_words = ''.join(seg[start_idx:end_idx+1])
print(f" {role_name}: {arg_words}")【句子 1】: 他打开了门
分词结果: ['他', '打开', '了', '门']
谓词信息: {'index': 1, 'predicate': '打开', 'arguments': [('A0', '他', 0, 0), ('A1', '门', 3, 3)]}
谓词: '打开' (位置: 1)
施事: 他
受事: 门
【句子 2】: 妈妈给孩子买了一本书
分词结果: ['妈妈', '给', '孩子', '买', '了', '一', '本', '书']
谓词信息: {'index': 3, 'predicate': '买', 'arguments': [('A0', '妈妈', 0, 0), ('ARGM-BNF', '给孩子', 1, 2), ('A1', '一本书', 5, 7)]}
谓词: '买' (位置: 3)
施事: 妈妈
受益者: 给孩子
受事: 一本书
【句子 3】: 公司去年在深圳建立了新工厂
分词结果: ['公司', '去年', '在', '深圳', '建立', '了', '新', '工厂']
谓词信息: {'index': 4, 'predicate': '建立', 'arguments': [('A0', '公司', 0, 0), ('ARGM-TMP', '去年', 1, 1), ('ARGM-LOC', '在深圳', 2, 3), ('A1', '新工厂', 6, 7)]}
谓词: '建立' (位置: 4)
施事: 公司
时间: 去年
地点: 在深圳
受事: 新工厂
【句子 4】: 这场暴雨导致道路积水
分词结果: ['这', '场', '暴雨', '导致', '道路', '积水']
谓词信息: {'index': 3, 'predicate': '导致', 'arguments': [('A0', '这场暴雨', 0, 2), ('A1', '道路积水', 4, 5)]}
谓词: '导致' (位置: 3)
施事: 这场暴雨
受事: 道路积水
【句子 5】: 教授认为实验结果不够严谨
分词结果: ['教授', '认为', '实验', '结果', '不', '够', '严谨']
谓词信息: {'index': 1, 'predicate': '认为', 'arguments': [('A0', '教授', 0, 0), ('A1', '实 验结果不够严谨', 2, 6)]}
谓词: '认为' (位置: 1)
施事: 教授
受事: 实验结果不够严谨
谓词信息: {'index': 6, 'predicate': '严谨', 'arguments': [('A0', '实验结果', 2, 3), ('ARGM-ADV', '不', 4, 4)]}
谓词: '严谨' (位置: 6)
施事: 实验结果
修饰词: 不
【句子 6】: 游客们兴奋地拍下了日出的照片
分词结果: ['游客', '们', '兴奋', '地', '拍', '下', '了', '日出', '的', '照片']
谓词信息: {'index': 4, 'predicate': '拍', 'arguments': [('A0', '游客们', 0, 1), ('ARGM-ADV', '兴奋地', 2, 3), ('A1', '日出的照片', 7, 9)]}
谓词: '拍' (位置: 4)
施事: 游客们
修饰词: 兴奋地
受事: 日出的照片
【句子 7】: 政府计划明年修建三座医院
分词结果: ['政府', '计划', '明年', '修建', '三', '座', '医院']
谓词信息: {'index': 1, 'predicate': '计划', 'arguments': [('A0', '政府', 0, 0), ('A1', '明 年修建三座医院', 2, 6)]}
谓词: '计划' (位置: 1)
施事: 政府
受事: 明年修建三座医院
谓词信息: {'index': 3, 'predicate': '修建', 'arguments': [('ARGM-TMP', '明年', 2, 2), ('A1', '三座医院', 4, 6)]}
谓词: '修建' (位置: 3)
时间: 明年
受事: 三座医院
【句子 8】: 小狗咬坏了我的拖鞋
分词结果: ['小', '狗', '咬', '坏', '了', '我', '的', '拖鞋']
谓词信息: {'index': 2, 'predicate': '咬', 'arguments': [('A0', '小狗', 0, 1), ('A1', '我的 拖鞋', 5, 7)]}
谓词: '咬' (位置: 2)
施事: 小狗
受事: 我的拖鞋
【句子 9】: 会议上,经理提出了新的营销方案
分词结果: ['会议', '上', ',', '经理', '提出', '了', '新', '的', '营销', '方案']
谓词信息: {'index': 4, 'predicate': '提出', 'arguments': [('ARGM-LOC', '会议上', 0, 1), ('A0', '经理', 3, 3), ('A1', '新的营销方案', 6, 9)]}
谓词: '提出' (位置: 4)
地点: 会议上
施事: 经理
受事: 新的营销方案
谓词信息: {'index': 6, 'predicate': '新', 'arguments': [('A0', '营销方案', 8, 9)]}
谓词: '新' (位置: 6)
施事: 营销方案
【句子 10】: 如果明天下雨,比赛将延期
分词结果: ['如果', '明天', '下雨', ',', '比赛', '将', '延期']
谓词信息: {'index': 2, 'predicate': '下雨', 'arguments': [('ARGM-TMP', '明天', 1, 1)]}
谓词: '下雨' (位置: 2)
时间: 明天
谓词信息: {'index': 6, 'predicate': '延期', 'arguments': [('ARGM-CND', '如果明天下雨', 0, 2), ('A1', '比赛', 4, 4), ('ARGM-ADV', '将', 5, 5)]}
谓词: '延期' (位置: 6)
条件: 如果明天下雨
受事: 比赛
修饰词: 将总结
语篇分析在词法和句法的分析上更进一步,且仍高度依赖于分词结果。本文系统介绍了自然语言处理中的语义计算理论与方法,首先概述了语义计算的核心任务(解释词、句、篇章含义)及其面临的歧义性、主观性和理论不成熟等挑战,随后详细阐述了多种语义理论:从格语法(Fillmore的深层语义角色,如施事、受事)到语义网络(基于图结构的IS-A/PART-OF关系表示),再到概念依存理论(Schank的动作基元与事件脚本),并深入探讨了词义消歧的规则、统计及词典方法(如Yarowsky算法),以及指代消解中代词、零形式和共指链的处理技术,最后解析了语义角色标注(PropBank框架下的谓词-论元关系标注)及其基于句法分析或深度学习的实现流程,整体呈现了从词汇、句法到篇章层面的语义解析技术体系,涵盖理论模型与实际应用,同时指出汉语特有的零指代、流水句等处理难点,为NLP语义理解提供了系统化的方法论支撑。
一系列工具包给语篇分析(实验,实际生产场景另论)带来了很大的便捷,不再需要进行规则匹配(极大可能不完整)或从头标注数据并训练(工作量耗时大)。

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









