







 文章探讨了批量大小(BatchSize)在神经网络训练中的作用,指出批量大小影响训练速度、收敛点和性能。小批量训练倾向于收敛到平坦极小化,而大批量训练可能更尖锐。通过调整学习率和考虑并行化优势,可以优化大批量训练性能,但两者性能差距相对较小。
文章探讨了批量大小(BatchSize)在神经网络训练中的作用,指出批量大小影响训练速度、收敛点和性能。小批量训练倾向于收敛到平坦极小化,而大批量训练可能更尖锐。通过调整学习率和考虑并行化优势,可以优化大批量训练性能,但两者性能差距相对较小。
文章目录
一、Batch Size解释
训练神经网络以最小化以下形式的损失函数:
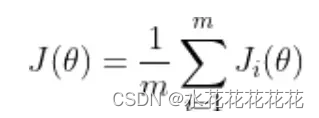
- theta 代表模型参数
- m 是训练数据样本的数量
- i 的每个值代表一个单一的训练数据样本
- J_i 表示应用于单个训练样本的损失函数
通常,这是使用梯度下降来完成的,它计算损失函数相对于参数的梯度,并在该方向上迈出一步。随机梯度下降计算训练数据子集 B_k 上的梯度,而不是整个训练数据集。

B_k 是从训练数据集中采样的一批,其大小可以从 1 到 m(训练数据点的总数)。这通常称为批量大小为 |B_k| 的小批量训练。我们可以将这些批次级梯度视为“true”梯度的近似值,即整体损失函数相对于 theta 的梯度。我们使用小批量是因为它倾向于更快地收敛,因为它不需要完全遍历训练数据来更新权重。
二、Batch Size影响训练的过程
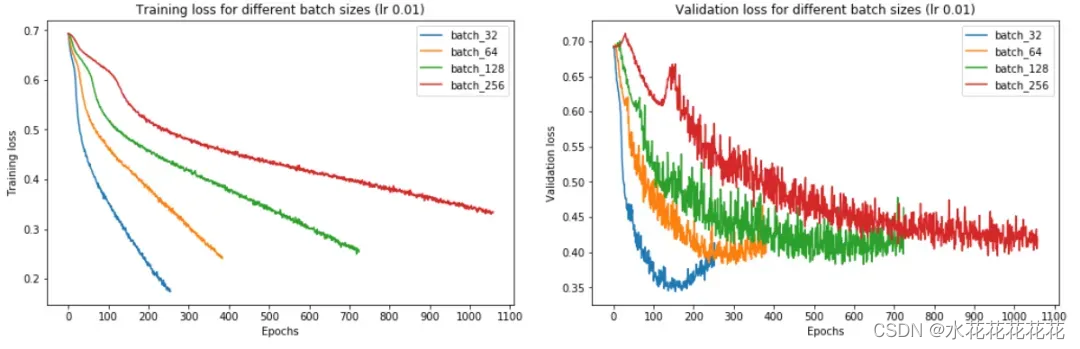
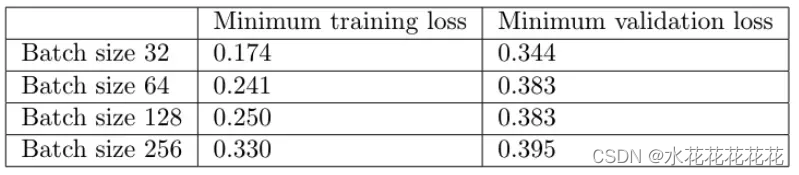
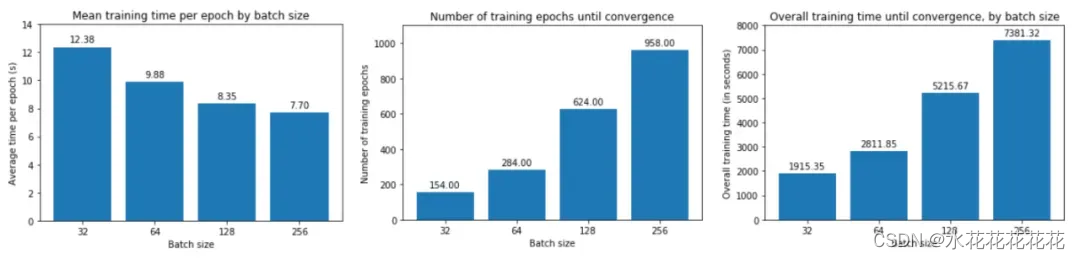
结论:batch size越大:
- 训练损失减少的越慢。
- 最小验证损失越高。
- 每个时期训练所需的时间越少。
- 收敛到最小验证损失所需的 epoch 越多。
三、较小的批量与大批量性能对比
Keskar 等人对小批量和大批量之间的性能差距提出了一种解释:使用小批量的训练倾向于收敛到平坦的极小化,该极小化在极小化的小邻域内仅略有变化,而大批量则收敛到尖锐的极小化,这变化很大。平面minimizers 倾向于更好地泛化,因为它们对训练集和测试集之间的变化更加鲁棒 。
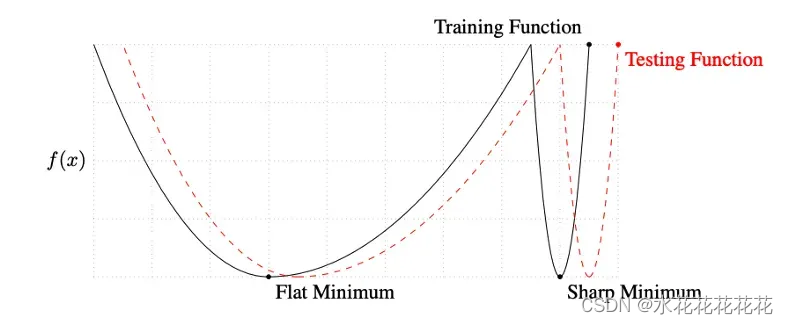
他们发现与大批量训练相比,小批量训练可以找到距离初始权重更远的最小值。他们解释说,小批量训练可能会为训练引入足够的噪声,以退出锐化minimizers 的损失池,而是找到可能更远的平坦minimizers 。
四、如何优化大批量性能
通过提高学习率,这种方法以前曾被建议过,例如 Goyal 等人提出:“线性缩放规则:当 minibatch 大小乘以 k 时,将学习率乘以 k。”
批量大小为 32、64、128 和 256。我们将对批量大小 32 使用 0.01 的基本学习率,并相应地缩放其他批量大小。
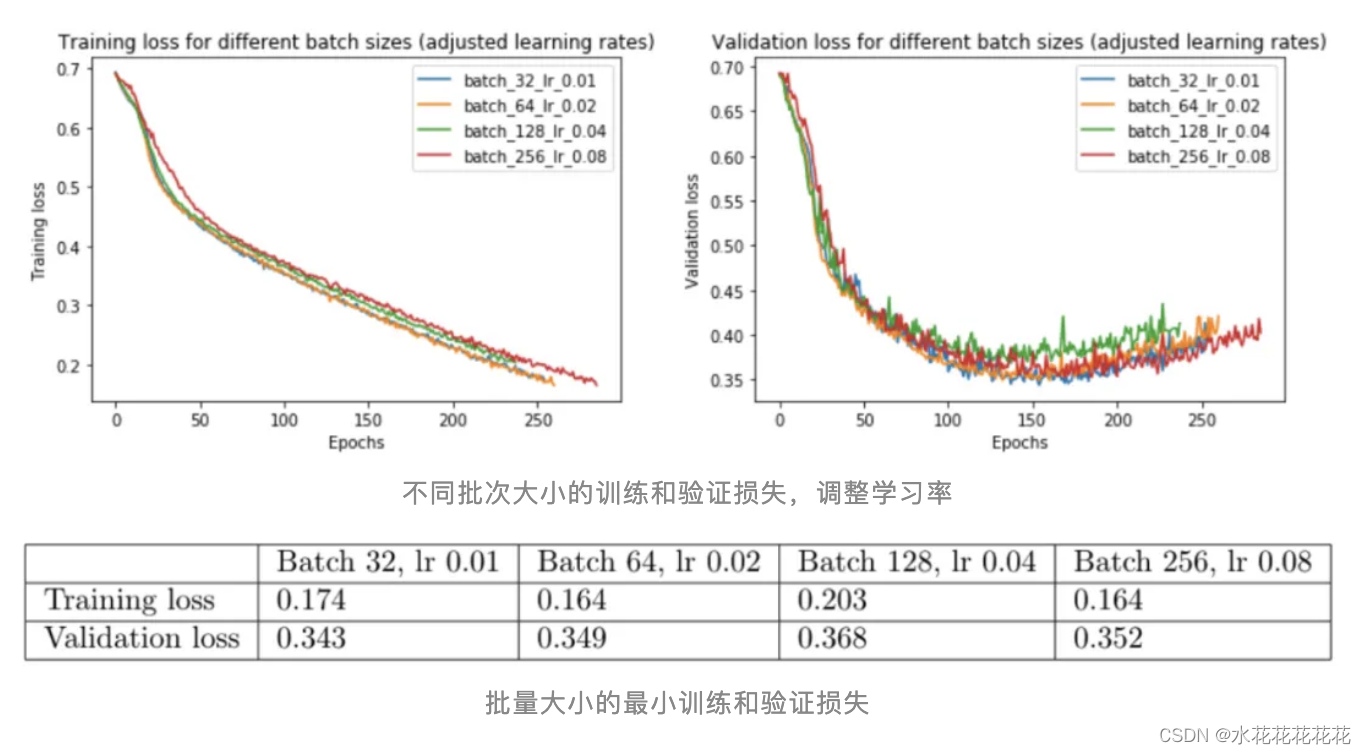
调整学习率确实消除了小批量和大批量之间的大部分性能差距。现在,批量大小 256 的验证损失为 0.352 而不是 0.395——更接近批量大小 32 的损失 0.345。
线性缩放规则:当 minibatch 大小乘以 k 时,将学习率乘以 k。尽管我们最初发现大批量性能更差,但我们能够通过提高学习率来缩小大部分差距。我们看到这是由于较大的批次大小应用了较小的批次更新,这是由于批次内梯度向量之间的梯度竞争。
选择合适的学习率时,较大的批量尺寸可以更快地训练,特别是在并行化时。对于大批量,我们不受 SGD 更新的顺序性质的限制,因为我们不会遇到与将许多小批量顺序加载到内存中相关的开销。我们还可以跨训练示例并行化计算。
然而,当学习率没有针对较大的批量大小向上调整时,大批量训练可能比小批量训练花费的时间更长,因为它需要更多的训练时期来收敛。因此,您需要调整学习率以实现更大批量和并行化的加速。
大批量,即使调整了学习率,在我们的实验中表现稍差,但需要更多的数据来确定更大的批量是否总体上表现更差。我们仍然观察到最小批量大小(val loss 0.343)和最大批量大小(val loss 0.352)之间的轻微性能差距。一些人认为小批量具有正则化效果,因为它们将噪声引入更新,帮助训练摆脱次优局部最小值的吸引力 。然而,这些实验的结果表明,性能差距相对较小,至少对于这个数据集。这表明,只要您为批量大小找到合适的学习率,您就可以专注于可能对性能产生更大影响的其他方面的训练。
参考:
- Keskar, Nocedal, Mudigere, Smelyanskiy, and Tang. On Large-Batch Training for Deep Learning: Generalization Gap and Sharp Minima. https://arxiv.org/pdf/1609.04836.pdf
- Li, Xu, Taylor, Studer, and Goldstein. Visualizing the Loss Landscape of Neural Nets. https://papers.nips.cc/paper/7875-visualizing-the-loss-landscape-of-neural-nets.pdf.
- Goyal, Dollar, Girshick, Noordhuis, Wesolowski, Kyrola, Tulloch, Jia, and He. Accurate, Large Minibatch SGD: Training ImageNet in 1 Hour. https://research.fb.com/wp-content/uploads/2017/06/imagenet1kin1h5.pdf.
- https://zhuanlan.zhihu.com/p/41533289















 1915
1915











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









