






目录
类:CBAM (Convolutional Block Attention Module)
算法小白从0学习YOLOv8,代码看不懂一点儿!呜呜呜~
于是翻译成中文人话,方便自己理解,顺便记录一下自己的学习过程,说的不全面的地方请友友在评论区补充指正~
这篇博客记录了YOLOv8里的注意力实现方式:Focus注意力 (缩HW增C)、通道注意力(ChannelAttention)、空间注意力(SpatialAttention)、CBAM注意力(Convolutional Block Attention Module),有需要请目录跳转。
源代码摘自https://github.com/ultralytics/ultralytics/blob/main/ultralytics/nn/modules/conv.py
类:Focus (缩HW增C)
class Focus(nn.Module):
"""Focus wh information into c-space."""
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True):
"""Initializes Focus object with user defined channel, convolution, padding, group and activation values."""
super().__init__()
self.conv = Conv(c1 * 4, c2, k, s, p, g, act=act)
# self.contract = Contract(gain=2)
def forward(self, x):
"""
Applies convolution to concatenated tensor and returns the output.
Input shape is (b,c,w,h) and output shape is (b,4c,w/2,h/2).
"""
return self.conv(torch.cat((x[..., ::2, ::2], x[..., 1::2, ::2], x[..., ::2, 1::2], x[..., 1::2, 1::2]), 1))
# return self.conv(self.contract(x))Focus类的主要功能是降低输入张量的空间尺寸(高度和宽度),同时增加通道数。Focus类的输入值是(B,C,H,W),输出值变为了(B,4C,H/2,W/2)。这可以降低空间分辨率,可以加快计算速度并降低内存使用量,特别是在处理大型图像时;通过连接每个通道中不同空间位置的元素,模型可以潜在捕捉到图像中特征的更全面表示。
return self.conv(torch.cat((x[..., ::2, ::2], x[..., 1::2, ::2], x[..., ::2, 1::2], x[..., 1::2, 1::2]), 1))上面的代码中,x的形状是(B,C,H,W),x[... , ::2 , ::2]中的...指的是取了前两个维度Batchsize和Channel的所有值,按照一定步长取了Height和Width维度的一部分值。
x[... , ::2 , ::2]取了偶数行和偶数列的元素;
x[... , 1::2 , ::2]取了奇数行和偶数列的元素;
x[... , ::2 , 1::2]取了偶数行和奇数列的元素;
x[... , 1::2 , 1::2]取了奇数行和奇数列的元素;
torch.cat函数将这四个子张量沿通道维度(轴 1)进行拼接。这有效地将来自所有四种采样方式的信息组合成一个单一张量,该张量的通道数是原始通道数的4倍。
Focus类在进行前向传播的时候,对每一个通道切片(,1,H,W)都进行四次采样,并在通道维度上叠加,得到(,4,H/2,W/2)的切片,然后再把整体(B,4C,H/2,W/2)的特征图送进卷积。
类:ChannelAttention (通道注意力)
class ChannelAttention(nn.Module):
"""Channel-attention module https://github.com/open-mmlab/mmdetection/tree/v3.0.0rc1/configs/rtmdet."""
def __init__(self, channels: int) -> None:
"""Initializes the class and sets the basic configurations and instance variables required."""
super().__init__()
self.pool = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Conv2d(channels, channels, 1, 1, 0, bias=True)
self.act = nn.Sigmoid()
def forward(self, x: torch.Tensor) -> torch.Tensor:
"""Applies forward pass using activation on convolutions of the input, optionally using batch normalization."""
return x * self.act(self.fc(self.pool(x)))在类的初始化过程中,channels代表输入张量的通道数;
self.pool = nn.AdaptiveAvgPool2d(1)self.pool使用自适应平均池化层 (nn.AdaptiveAvgPool2d),用于将输入特征图缩小到空间尺寸为 1x1 的张量。
self.fc = nn.Conv2d(channels, channels, 1, 1, 0, bias=True)self.fc用卷积层 (nn.Conv2d)实现全连接层的功能,用于将池化后的特征图中的信息转换为通道注意力权重。它具有和输入通道数相同的输出通道数,内核大小为 1x1,无填充 (padding=0),并带有偏置项 (bias=True)。
self.act = nn.Sigmoid()self.act为激活函数 (nn.Sigmoid),用于将注意力权重值压缩到 0 到 1 之间。
def forward(self, x: torch.Tensor) -> torch.Tensor:
return x * self.act(self.fc(self.pool(x)))前向推理的返回值中,self.act(self.fc(self.pool(x)))计算得到的是注意力权重,它以逐元素乘法的方式与原始输入特征图 x 相乘,相当于放大模型关注的重要的通道信息,同时削弱不重要的通道信息。
| 操作 | 输入 | 输出 |
| self.pool(x) | (B,C,H,W) | (B,C,1,1) |
| self.fc(x) | (B,C,1,1) | (B,C,1,1) |
| self.act(x) | (B,C,1,1) | (B,C,1,1) |
| x*self.act(self.fc(self.pool(x))) | (B,C,H,W) | (B,C,H,W) |
在论文CBAM: Convolutional Block Attention Module中提出的channel attention使用了最大池化和平均池化的并联,但本文所述的模块中只使用了平均池化 (nn.AdaptiveAvgPool2d)。

类:SpatialAttention (空间注意力)
class SpatialAttention(nn.Module):
"""Spatial-attention module."""
def __init__(self, kernel_size=7):
"""Initialize Spatial-attention module with kernel size argument."""
super().__init__()
assert kernel_size in (3, 7), 'kernel size must be 3 or 7'
padding = 3 if kernel_size == 7 else 1
self.cv1 = nn.Conv2d(2, 1, kernel_size, padding=padding, bias=False)
self.act = nn.Sigmoid()
def forward(self, x):
"""Apply channel and spatial attention on input for feature recalibration."""
return x * self.act(self.cv1(torch.cat([torch.mean(x, 1, keepdim=True), torch.max(x, 1, keepdim=True)[0]], 1)))
这个类用于实现空间注意力机制,帮助模型在处理图像时更加关注重要的空间信息。
assert kernel_size in (3, 7), 'kernel size must be 3 or 7'这句话使用断言,规定了卷积核大小一定是3或者7,否则会报错
padding = 3 if kernel_size == 7 else 1k=3,p=1或者k=7,p=3可以保证卷积操作之后特征图H和W不变
self.cv1 = nn.Conv2d(2, 1, kernel_size, padding=padding, bias=False)self.cv1定义了一个输入通道数2,输出通道数1的普通卷积
def forward(self, x):
return x * self.act(self.cv1(torch.cat([torch.mean(x, 1, keepdim=True), torch.max(x, 1, keepdim=True)[0]], 1)))
上面这句话当中,假如输入张量的大小是(B,C,H,W),torch.mean(x, 1, keepdim=True)指的是取x在通道维度(dim=1)的平均值,输出为(B, 1, H, W);torch.max(x, 1, keepdim=True)返回的是x的通道最大值(B, 1, H, W)和其对应的通道索引,torch.max(x, 1, keepdim=True)[0]取出了通道最大值,抛弃了最大值的索引,所以返回的是(B, 1, H, W)的张量。
torch.cat([torch.mean(x, 1, keepdim=True), torch.max(x, 1, keepdim=True)[0]], 1)的操作将torch.mean(x, 1, keepdim=True)计算得到的(B, 1, H, W)平均值和torch.max(x, 1, keepdim=True)[0]计算得到的(B, 1, H, W)最大值进行通道相加(dim=1),得到(B, 2, H, W)的张量。
然后再把(B, 2, H, W)的张量先后送入self.cv1和self.act进行卷积和激活,得到(B, 1, H, W)的空间注意力权重值。卷积是为了浓缩空间信息,激活函数是为了把张量映射到0到1之间,成为权重值。
最后再用原来(B, C, H, W)的x与(B, 1, H, W)的空间注意力权重值进行逐元素相乘,相当于放大模型关注的重要的空间信息,同时削弱不重要的空间信息。
| 操作 | 输入 | 输出 |
| torch.mean(x, 1, keepdim=True) | (B,C,H,W) | (B,1,H,W) |
| torch.max(x, 1, keepdim=True)[0] | (B,C,H,W) | (B,1,H,W) |
| torch.cat(y, 1) | [(B,1,H,W),(B,1,H,W)] | (B,2,H,W) |
| self.cv1(x) | (B,2,H,W) | (B,1,H,W) |
| self.act(x) | (B,1,H,W) | (B,1,H,W) |
| x * self.act(self.cv1(torch.cat([torch.mean(x, 1, keepdim=True), torch.max(x, 1, keepdim=True)[0]], 1))) | (B,C,H,W) | (B,C,H,W) |
本类所实现的空间注意力就如在论文CBAM: Convolutional Block Attention Module中绘制的空间注意力图:
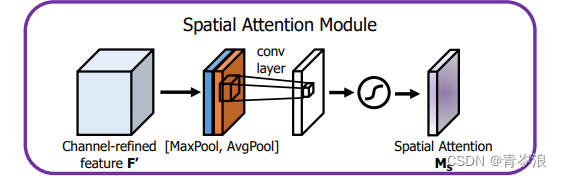
类:CBAM (Convolutional Block Attention Module)
class CBAM(nn.Module):
"""Convolutional Block Attention Module."""
def __init__(self, c1, kernel_size=7):
"""Initialize CBAM with given input channel (c1) and kernel size."""
super().__init__()
self.channel_attention = ChannelAttention(c1)
self.spatial_attention = SpatialAttention(kernel_size)
def forward(self, x):
"""Applies the forward pass through C1 module."""
return self.spatial_attention(self.channel_attention(x))类CBAM先定义了两个分支self.channel_attention和self.apatial_attention,分别使用了上文所定义的两个类,然后再前向传播的时候,先让输入x通过通道注意力self.channel_attention,再通过空间注意力self.apatial_attention。与论文CBAM: Convolutional Block Attention Module中绘制的CBAM整体结构图一模一样:

类:Concat (通道连接)
class Concat(nn.Module):
"""Concatenate a list of tensors along dimension."""
def __init__(self, dimension=1):
"""Concatenates a list of tensors along a specified dimension."""
super().__init__()
self.d = dimension
def forward(self, x):
"""Forward pass for the YOLOv8 mask Proto module."""
return torch.cat(x, self.d)self.d指定了连接张量的维度,例如,self.d=1表示沿通道维度 (channel dimension) 进行连接,self.d=2表示沿高度维度 (height dimension) 进行连接。x是一个包含要连接的张量列表的输入,函数返回值指的是将x沿着self.d指定的方向进行连接。















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









