






前言
首先为什么放一起呢,显然是因为这两个相互关联.....EM算法会用到极大似然估计,总之,开始吧
正文
极大似然估计
极大似然估计(Maximum Likelihood Estimation,简称MLE)是一种用于估计模型参数的统计方法。其核心思想是通过找到能够最大化观测数据的似然函数的参数值,来估计模型的未知参数。似然函数表示在给定参数值的情况下,观测到已有数据的概率。MLE的目标是找到能够最大化这个概率的参数值。
假设我们有一组独立同分布(i.i.d)的观测数据 (x_1, x_2, ..., x_n),这些数据来自某个概率分布,其概率密度函数为 f(x; theta)),其中 (theta) 是未知的参数。似然函数 L(theta) 定义为给定参数 (theta) 下观测数据出现的概率,即:
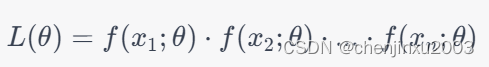
对似然函数取log函数的话通常更方便处理,它是似然函数的对数:

极大似然估计的目标是找到能够最大化对数似然函数的参数值,即:

通常,为了求解这个最优化问题,我们使用数学优化方法,例如梯度上升、牛顿法等。
例子:
考虑一个简单的二项分布的例子。假设有一枚硬币,投掷结果为正面(1)或反面(0),我们希望估计硬币投掷得到正面的概率 p。这个问题可以建模为二项分布,其概率质量函数为:
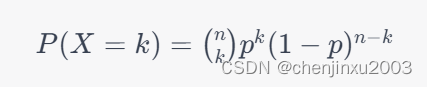

好,接下来就是EM算法了
EM算法
期望最大化算法(Expectation-Maximization,简称EM)是一种用于处理含有潜在变量(latent variables)的概率模型参数估计问题的迭代优化算法。EM算法的目标是找到能够最大化观测数据的似然函数的参数值,尤其适用于存在未观测或缺失数据的情况。
EM算法包含两个主要步骤:E步(Expectation Step)和M步(Maximization Step)。这两个步骤交替进行,直到收敛为止。
1. E步(Expectation Step):
在E步中,通过引入潜在变量,计算观测数据来自每个成分的后验概率。这个后验概率表示给定当前参数值下,每个观测数据属于每个成分的概率。对于一维Laplacian混合模型的情况,E步的概率计算如下,也就是先随机生成我们要求的值,然后用这个值进行计算:
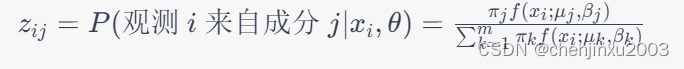
2. M步(Maximization Step):
在M步中,通过最大化完全数据对数似然函数,更新模型参数,也就是更新我们假设的那个值。对于一维Laplacian混合模型,M步的更新如下:
更新混合权重

更新均值参数 \( \mu_j \):

例子:















 1509
1509











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









