






 文章探讨了浮点数编码中的反直觉现象,如0.1+0.2不等于0.3,解释了二进制表示的局限性、IEEE754标准,以及如何处理浮点数误差,包括编码误差、运算误差和类型转换误差,提供了解决策略如宽松的判等和精度选择。
文章探讨了浮点数编码中的反直觉现象,如0.1+0.2不等于0.3,解释了二进制表示的局限性、IEEE754标准,以及如何处理浮点数误差,包括编码误差、运算误差和类型转换误差,提供了解决策略如宽松的判等和精度选择。
从一个浮点的“Bug”说起
关于浮点数,有一个很反直觉的现象:
if(0.1 + 0.2 == 0.3)
Debug.log("相等"); // 直觉上觉得应该走的分支
else
Debug.log("不相等"); // 实际会走的分支
为什么会这样?简单的回答就是:计算机的浮点数是二进制编码的,而二进制分数不能准确表示所有的小数。
以上面为例,0.1,0.2,0.3 这种的小数,在二进制小数里是找不到对应的,只能找个近似的。就像1/3 十进制里找不到对应的,只能用0.3334这种来近似一样。 上面代码里的0.1,计算里实际上大概近似为 0.100000001490116119384765, 不是准准确确的0.1.
那么有人不安心了,对浮点数彻底失去信心了: 浮点数这么不靠谱,是不是关于它的判等统统都不管用了,一个都不能信? 也不全是,再看一个例子:
if(0.1 + 0.2 == 0.1 + 0.2)
Debug.log("相等"); // 实际走的分支
else
Debug.log("不相等");
比如 0.1 + 0.2 == 0.1 + 0.2这样的等式,返回值还是true。
要理解0.1 + 0.2 != 0.3 的误差是发生在编码过程,不是在运算过程。 你在代码里写的0.1, 0.2这种数,是程序运行时候,第一步转成内存里的float的时候,变成的误差。还是拿你代码里写的0.1为例,在运行时内存里二进制是这么存的:00111101110011001100110011001101,也就是0.100000001490116119384765625。
当然,因为计算浮点数的机制造成的误差不止这一个原因,文章后面会列举一遍。
二进制分数
有一个不错文章来解释其原理 https://floating-point-gui.de/formats/binary/
这里就简单通过对比二进制整数,来总结一下二进制分数是怎么表示的
二进制的整数
第 � 位代表 2�−1 ,以数字13为例:
十进制二进制13十进制=1101二进制=1∗23+1∗22+0∗21+1∗20
二进制的分数运作也是类似的:
小数点后第 � 为代表 2−� ,以小数0.625给个例子:
十进制二进制0.625十进制=0.101二进制=1∗2−1+0∗2−2+1∗2−3
进位制对有理数的表示误差
有理数是由整数和分数组成,所谓的“小数”其实是由“分数”,即两个整数相除的方式来定义的。进位制并不能一对一精确地表示所有的分数,这取决于它的基数。比如基数为10的十进制,是通过 10−1 , 10−2 ,...相加表示,基数为2的二进制 2−1 , 2−2 ...来相加表述。
这就会出现误差,即表示不了就通过舍入找个最近的,比如1/3 用十进制,则用0.33334来近似
| 分数 | 二进制来表示 | 二进制表示 |
| 1/3 | 数值上约等于 0.333333343267440 | 数值上约等于 0.333333343267440 |
| 1/10 | 精确的0.1 | 数值上约等于 0.100000001490116 |
浮点数编码标准-IEEE 754
然后我以编码的角度,看一下当前已广泛采用的IEEE754浮点数标准,是怎么以二进制的方式存储的。这里推荐一个网站,可视化的帮你理解转化过程: https://www.h-schmidt.net/FloatConverter/IEEE754.html
a) 一个例子:浮点数0.625是怎么编码的
用这个网站的转化器,0.625用IEE754标准的转化结果如下:
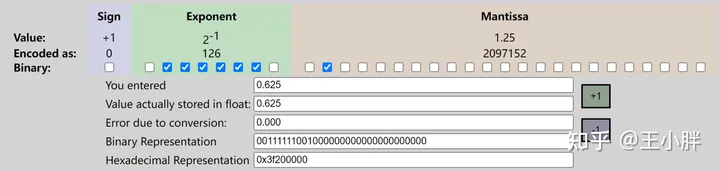
“0.625”在IEEE754 单精度标准下的表示
我们一步步分析,其编码规则
第一步:将其用类似科学计数法的方式,表示为 浮点数【符号】【指数】【有效数字】浮点数=【符号】∗【指数】∗【有效数字】 方式
即 ()0.625=(+1)∗(2−1)∗(1.25)
- 符号为 +1 :这个很好理解,正或负
- 指数部分为 2−1 :这里表示以2为底的形式
- 有效数字为1.25 : 注意,IEEE规定了浮点数的有效数字第一位约定是1, 也就是一定是1.xxxx的形式。也是为什么是 ()0.625=(+1)∗(2−1)∗(1.25) 而不是 ()0.625=(+1)∗(20)∗(0.625)
第二步:对符号,指数,有效数字 三个部分进行编码
即 二进制二进制二进制0.625=0二进制∗01111110二进制∗01000000000000000000000二进制
- 符号二进制编码为0 :0表示正数,1表示负数
- 指数部分二进制编码为:01111110: 对于 2� 我们是对 � 进行编码的,所以这里的 2−1 我们是对“-1”进行编码的。又因为 � 是有正有负的,所以我们统一加一个“指数偏移”,保证最终的数肯定都是正数,再进行编码。以单精度为例,指数部分有8bit,所以指数偏移是 ()2(8−1)=127 , 对于这里的 2−1 的"-1"编码为 −1+127=126 所以最终编码为01111110
- 有效数字二进制编码为01000000000000000000000:1.25这部分,因为IEEE754规定了第一位肯定是1,所以对于这个1我们就不编码了。我们编码的是0.25部分。按照二进制分数的那一节说的,这里就不赘述了,编码后为(0.01)二进制 ,对应编码01000000000000000000
b) IEEE754标准细节
其他更多的标准可以参考一下:IEEE 754_百度百科
这里提炼一下这个标准常用的几个点
- 因为我们默认第一个有效数字一定是1, 那么0就没法表示了。 所以IEEE规定,指数和有效数字全为0的时候,表示0
- 因为符号位的原因,我们有两个0. 即+0 和 -0
- 我们把指数部分全为1,有效数字全为0来表示无穷大。
- 我们吧指数部分全为1,有效数字只要不是全为0的所有数字,都来表示NaN (not a number )
c) 聊一聊IEEE规定的NaN
在代码里写 a = 1/0 , 实际跑起来会发生什么? 有同学会以为,肯定是抛异常,程序崩溃呀。
但未必是这样的,这要看编程语言的时候,有的编程语言是能继续正常运行的,因为IEEE规定了NaN来表示所有没有意义的数,可以看做“浮点数的Null”
NaN的产生
- 没有意义的运算,比如1/0, 0 *无穷大, 0^0 这种数学上没有意义的值
- 任何带NaN的运算:比如1+NaN; 2*NaN
NaN的比较法则
简单的说就是,NaN 和任何数的比较,返回都是false,NaN不等于任何数,包括NaN自己
| 比较 | NaN >= x | NaN > x | NaN <= x | NaN < x | NaN == x | NaN != x |
|---|---|---|---|---|---|---|
| 结果 | False | False | False | False | False | False |
NaN的处理以及相关讨论
对数学上没有意义的运算,是返回NaN还是触发异常,这个要看编程语言或编译器自己想怎么处理了。
这里有一个关于NaN or Exception的讨论 https://github.com/dotnet/csharplang/discussions/2198
个人觉得,NaN的弊病,在于没听说过NaN规则的同学,会觉得反直觉,没有crush,但是却在其他地方产生的表现不一样的bug, 比如用==, >之类的符号。
但从规则设计上,NaN也算是一种让浮点的表示范围完成一个闭环:浮点和浮点的运算一定能产生浮点数(不能的就 变成NaN)
其次保护你crush还是当错误暴露出来,这个在开发里,本身就是仁者见仁智者见智的东西,视情况而定。而且,NaN很多情况也是很好debug的,因为NaN的运算结果会像病毒一样传下去(所以等式只要是有一个NaN,结果就是NaN了)
浮点数误差的产生
文章一开始举的 0.1+0.2!=0.3 例子是由于编码造成的误差,而使用浮点的误差不止这一种,这一节总结一下,
a) 进位制编码造成的误差
这个就是上面说的,造成0.1+0.2 !=0.3的主要原因了。详细不再展开,其主要原因我们写代码,在代码文件里一般都是写的十进制, 比如float a = 0.345(不会有人习惯写代码的时候用float a = 010101101这种来表示数字吧?),而不是每个十进制小数都能一一对应的找到二进制小数的。
b) 运算上的误差
由于运算导致的浮点的精度溢出,或者最大值溢出,这大概是最众所周知的浮点误差了,这里就不赘述了。
https://zh.wikipedia.org/zh-cn/%E7%AE%97%E8%A1%93%E6%BA%A2%E5%87%BA
c) 平台误差
不同平台处理浮点的算法不一致,会导致运算结果不一致。
存在这几个方面:
- 编码规则,这个IEEE一般都是有颁布运算标准的,这个部分基本是已经标准化了
- 舍入方式:其实是规则的一部分,但是IEEE自己也保留了好几套舍入方式
- 硬件:具体的就是,浮点寄存器的位宽。 比如IBM提供过一个拓展,可以将float拓展到80bit, 那么用了这个拓展和不用,就会导致精度的不同。
- 平台对float设置和优化不同:如/fp指令(https://docs.microsoft.com/en-us/cpp/build/reference/fp-specify-floating-point-behavior?view=msvc-170 )
像网络游戏的帧同步方案,对平台的之间的误差会造成玩家之间的不同步,常用的最直接的做法就是,运算层面做一层封装,禁用浮点数,用定点数之类的代替。不过根据上面造成平台误差的原因,把造成浮点数误差的因素干掉来来保证浮点数的一致性(可以参考下 https://github.com/Tencent/xLua/issues/834 ),这样也似乎不是不可以,只是没见过有人在帧同步还是用浮点数的,可能用定点直接且最省心?
d) 类型转换导致的误差
以C#为例 https://docs.microsoft.com/en-us/dotnet/csharp/programming-guide/types/casting-and-type-conversions
如果转换能将原有的信息完全保留(比如int转long,而long包含了所以int能表示的数和不能表示的数), 这种叫隐式转换(implicit conversion)。这个没误差,C#自动帮你做的。
而反过来会信息丢失造成误差的,就需要自己手动转(explicit conversion), 比如 int a = (int)10.0f。
所以在C#这里还挺方便,当你发现必须自己手动转的时候,就是可能有误差了。
浮点数误差的应对
a) 优雅且正确地判等
对运算后的浮点数用 “==” 十有八九会翻车,得到得不是你想要的结果。
既然用==对浮点数太严格了,就用放点水:不用完全相等,大小差不多就算相等了。
把f1 == f2 判等改成他们的绝对值是否在你误差允许范围捏, Math.Abs(f1-f2) < A_VARY_SMALL_NUMBER(你自己定义的误差,比如0.000000001f)
b) 选择合适的精度
因为溢出这种误差,最粗暴的就是加精度。但运算性能在有些场景下可能得有权衡,尤其是像图形渲染里每帧写在着色器里的运算。
c) 优化计算步骤
很多步骤的运算,会把误差一点点累积。尽量避免,列一下等式,看下公式运算上能不能替换成步骤少一点的等价运算。
d) 干脆别用
世间花草千千万,不止浮点这一朵。比如怕平台运算误差的,可以用定点数。比如避免编码上的舍入,可以了解下decimal类型: https://docs.microsoft.com/en-u

















 868
868

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









