






一.数据准备
从 官方网站 下载 MOT17 和 MOT20
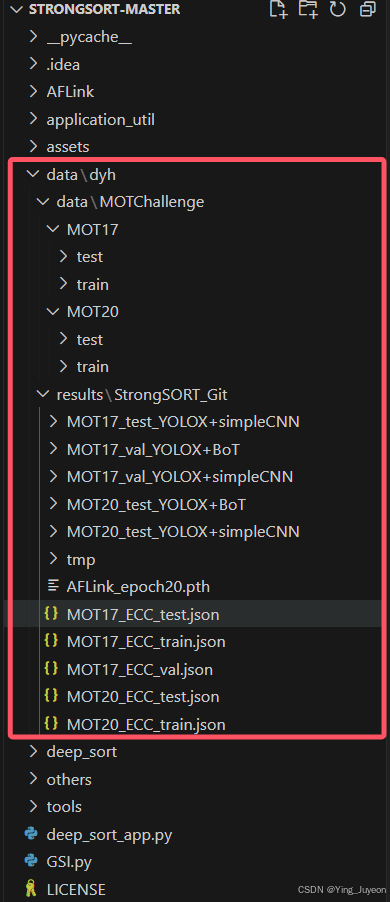
path_to_dataset/MOTChallenge ├── MOT17 │ ├── test │ └── train └── MOT20 ├── test └── train下载我们准备 的 数据 在Google磁盘(或 百度磁盘 用代码“排序”)
path_to_dataspace ├── AFLink_epoch20.pth # checkpoints for AFLink model ├── MOT17_ECC_test.json # CMC model ├── MOT17_ECC_val.json # CMC model ├── MOT17_test_YOLOX+BoT # detections + features ├── MOT17_test_YOLOX+simpleCNN # detections + features ├── MOT17_trainval_GT_for_AFLink # GT to train and eval AFLink model ├── MOT17_val_GT_for_TrackEval # GT to eval the tracking results. ├── MOT17_val_YOLOX+BoT # detections + features ├── MOT17_val_YOLOX+simpleCNN # detections + features ├── MOT20_ECC_test.json # CMC model ├── MOT20_test_YOLOX+BoT # detections + features ├── MOT20_test_YOLOX+simpleCNN # detections + features在"opts.py"中设置数据集和其他文件的路径,即root_dataset、path_AFLink、dir_save、dir_dets、path_ECC。
注意:如果您想自己生成ECC结果、检测和特征,请参考 辅助教程 。
按照"opts.py"中root_dataset、path_AFLink、dir_save、dir_dets、path_ECC的路径
self.parser.add_argument(
'--root_dataset',
type=str,
default='data/dyh/data/MOTChallenge'
)
self.parser.add_argument(
'--path_AFLink',
type=str,
default='data/dyh/results/StrongSORT_Git/AFLink_epoch20.pth'
)
self.parser.add_argument(
'--dir_save',
type=str,
default='data/dyh/results/StrongSORT_Git/tmp'if opt.BoT:
opt.max_cosine_distance = 0.4
opt.dir_dets = 'data/dyh/results/StrongSORT_Git/{}_{}_YOLOX+BoT'.format(opt.dataset, opt.mode)
else:
opt.max_cosine_distance = 0.3
opt.dir_dets = 'data/dyh/results/StrongSORT_Git/{}_{}_YOLOX+simpleCNN'.format(opt.dataset, opt.mode)
if opt.MC:
opt.max_cosine_distance += 0.05
if opt.EMA:
opt.nn_budget = 1
else:
opt.nn_budget = 100
if opt.ECC:
path_ECC = 'data/dyh/results/StrongSORT_Git/{}_ECC_{}.json'.format(opt.dataset, opt.mode)创建data文件夹,路径如下
二.环境
- pytorch
- opencv
- scipy
- sklearn
conda create -n strongsort python=3.8 -y conda activate strongsort pip3 install torch torchvision torchaudio pip install opencv-python pip install scipy pip install scikit-learn==0.19.2
三.运行
-
Run DeepSORT on MOT17-val
python strong_sort.py MOT17 val
-
Run StrongSORT on MOT17-val
python strong_sort.py MOT17 val --BoT --ECC --NSA --EMA --MC --woC
-
Run StrongSORT++ on MOT17-val
python strong_sort.py MOT17 val --BoT --ECC --NSA --EMA --MC --woC --AFLink --GSI
-
Run StrongSORT++ on MOT17-test
python strong_sort.py MOT17 test --BoT --ECC --NSA --EMA --MC --woC --AFLink --GSI
-
Run StrongSORT++ on MOT20-test
python strong_sort.py MOT20 test --BoT --ECC --NSA --EMA --MC --woC --AFLink --GSI
报错1:
KeyError: 'data\\dyh\\data\\MOTChallenge\\MOT17\\train\\MOT17-02-FRCNN'print("Available keys in opt.ecc:", opt.ecc.keys())
print("Attempted to access key:", video)输出结果:
Available keys in opt.ecc: dict_keys(['MOT17-02-FRCNN', 'MOT17-04-FRCNN', 'MOT17-05-FRCNN', 'MOT17-09-FRCNN', 'MOT17-10-FRCNN', 'MOT17-11-FRCNN', 'MOT17-13-FRCNN'])
Attempted to access key: data\dyh\data\MOTChallenge\MOT17\train\MOT17-02-FRCNN问题原因
在 camera_update 方法中,video 参数传递的是完整路径(如 data\dyh\data\MOTChallenge\MOT17\train\MOT17-02-FRCNN),但 opt.ecc 字典的键是序列名称(如 MOT17-02-FRCNN),因此无法找到对应的键。
解决方法
我们需要从完整路径中提取出序列名称,然后用序列名称去访问 opt.ecc 字典。
修改代码
在 camera_update 方法中,添加一行代码来提取序列名称
def camera_update(self, video, frame):
# 从完整路径中提取序列名称
sequence_name = video.split('\\')[-1]# 如果是 Unix 系统(如 Linux 或 macOS),使用 '/' 替换 '\\'
dict_frame_matrix = opt.ecc[sequence_name]opts.py代码解析
这段代码的主要功能是解析命令行参数,并根据这些参数配置一个目标跟踪任务(如 MOT17 或 MOT20 数据集)的运行选项。它使用了 Python 的 argparse 模块来处理命令行输入,并根据输入参数设置一些默认值和路径。
以下是代码的详细解释:
1. 数据结构 data
data = {
'MOT17': {
'val': ['MOT17-02-FRCNN', 'MOT17-04-FRCNN', ...],
'test': ['MOT17-01-FRCNN', 'MOT17-03-FRCNN', ...]
},
'MOT20': {
'test': ['MOT20-04', 'MOT20-06', ...]
}
}
'''
这是一个嵌套字典,定义了 MOT17 和 MOT20 数据集的验证集(val)和测试集(test)中包含的序列名称。
例如,MOT17 数据集的验证集包含 MOT17-02-FRCNN、MOT17-04-FRCNN 等序列。
'''
2. opts 类
opts 类的主要功能和结构
-
初始化方法
__init__:-
该方法创建了一个
ArgumentParser对象,并定义了一系列命令行参数。每个参数都有名称、类型和帮助信息。 -
一些重要的参数包括:
-
dataset: 指定数据集(MOT17 或 MOT20)。 -
mode: 指定模式(验证val或测试test)。 -
BoT,ECC,NSA,EMA,MC,woC,AFLink,GSI: 这些是可选参数,通过--前缀来标识,通常用于控制程序的不同特性或算法选项。 -
其他参数如
--root_dataset,--path_AFLink,--dir_save以及一些与模型相关的参数。
-
-
-
parse方法:-
该方法负责解析命令行参数并返回相应的设置(一个包含所有参数及其值的对象)。
-
如果没有提供参数(
args为空),则使用argparse默认方法解析命令行参数;否则使用传入的参数列表进行解析。 -
在解析后,该方法设置了一些额外的属性(如
min_confidence,nms_max_overlap, 等),并根据指定的参数调整一些值,尤其是与模型的行为相关的参数(例如,使用BoT和MC等)。 -
通过
opt.sequences = data[opt.dataset][opt.mode]将传入的数据集和模式对应的序列(例如,MOT17 的验证集或测试集)提取到选项中。 -
最后,计算数据集的目录路径,
train或test目录基于所选择的模式。
-
报错2
File "D:\StrongSORT-master\StrongSORT-master\deep_sort\linear_assignment.py", line 65, in min_cost_matching
if col not in indices[:, 1]:
TypeError: tuple indices must be integers or slices, not tuple这个错误表明在 linear_assignment.py 文件中,代码尝试对一个 tuple 类型的对象使用切片操作,但 tuple 的索引只能是整数或切片,而不能是 tuple 类型。
具体来说,错误发生在以下代码行:
问题原因
indices 是一个 tuple,而不是 NumPy 数组。tuple 不支持类似 [:, 1] 的切片操作,因此会抛出 TypeError。
解决方法
检查 indices 的来源,并确保它是一个 NumPy 数组,而不是 tuple。以下是可能的解决方案:
1. 检查 indices 的来源
在 linear_assignment.py 文件中,找到 indices 的定义或赋值代码。通常,indices 是通过某种匹配算法(如匈牙利算法)生成的。
例如,如果 indices 是通过 scipy.optimize.linear_sum_assignment 生成的,那么它确实是一个 tuple,包含两个数组:
row_ind, col_ind = linear_sum_assignment(cost_matrix)
indices = (row_ind, col_ind)在这种情况下,你需要将 indices 转换为 NumPy 数组,或者直接使用 row_ind 和 col_ind。
2. 修改代码
indices 是通过 scipy.optimize.linear_sum_assignment 生成的,以下是修改后的代码:
from scipy.optimize import linear_sum_assignment
# 假设 cost_matrix 是代价矩阵
row_ind, col_ind = linear_sum_assignment(cost_matrix)
# 直接使用 col_ind
if col not in col_ind:
...总结
-
错误的原因是
indices是一个tuple,而不是 NumPy 数组,因此不支持[:, 1]的切片操作。 -
你需要检查
indices的来源,并将其转换为 NumPy 数组,或者直接使用row_ind和col_ind。


















 5877
5877

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











