






看之前我先了解了一下,当下的主流标记方法,分为两种一个是半监督一个是弱监督,
弱监督:降低标注质量,弱监督分割方法通常使用弱注释,但是大多数要么难以区分一些模糊边界,有额外的大计算负担。弱监督设置通常需要对每一幅图像进行粗注释。
半监督:减少标注数量,用少量手工标记数据和大量未标记数据训练分割模型
主要思想解读

本文提出了一种了新的稀疏标注方法——正交标注 既在其正交方向上标记两个切片(横面和冠状面)
优点:可以在很大程度上迫使模型从两个不同初始化的标记切片的互补视图中学习 它可以充分利用片间相似性,极大地降低标签成本。
缺点:通过稀疏标记加上配标,得到的正交伪标签无法直接利用半监督方法训练分割模型。
为了解决以上问题,本文提出一种密集-稀疏的协同训练范式,如下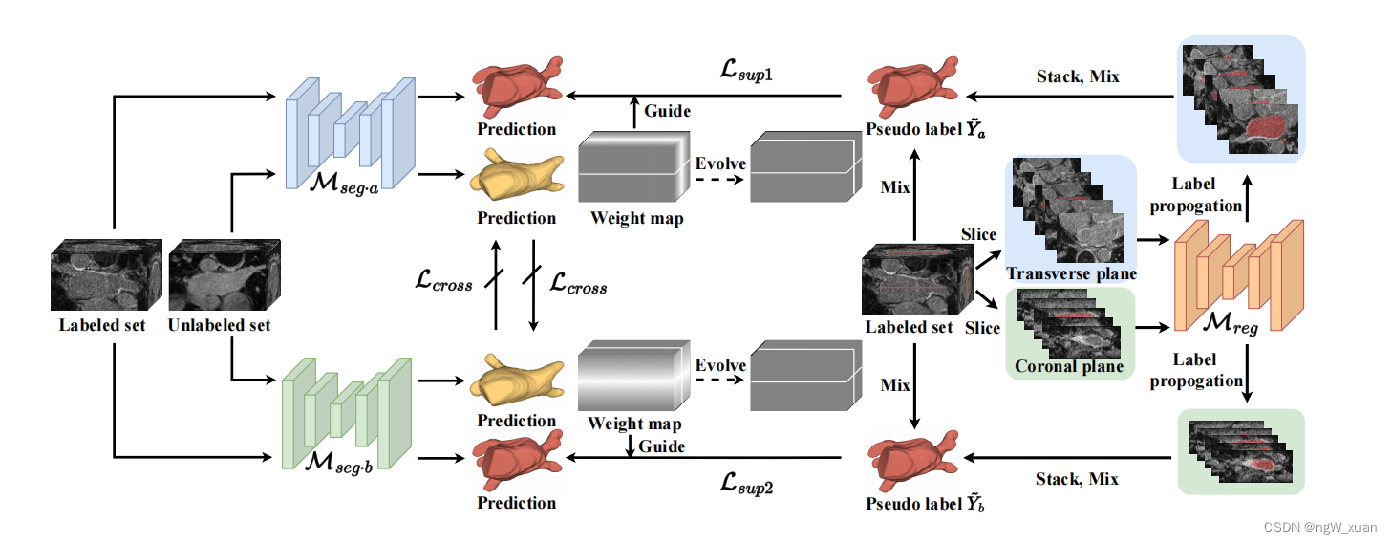 先从密集的伪标签中学习,然后降低噪声,并在后期从稀疏注释中获得进一步的提升。
先从密集的伪标签中学习,然后降低噪声,并在后期从稀疏注释中获得进一步的提升。
带有正交注释的体积数据,Mreg是一种配准方法,它在两个方向上将正交注释传播到整个体积中。这种配准的结果被用作伪标签,分别指导两个分割模型Mseg·a和Mseg·b的训练。 对于未标记的体积数据,两个分割模型Mseg·a和Mseg·b使用它们自己的输出互相监督。
具体来说,定义了两个分割网络(m_seg1 和 m_seg2)进行训练。在每个epoch中,首先遍历trainloader1和trainloader2中的每个批次数据。对于每个批次,首先获取输入数据(volume_batch、label_batch 和 maskz),然后将这些数据送入m_seg1网络得到初步的输出结果。接下来,使用未标记的数据部分生成新的输入数据(cs_inputs),并将其送入m_seg2网络进行进一步处理。通过将m_seg2的输出经过softmax激活函数,得到预测结果(preds)。然后计算预测结果的不确定性(uncertainty)。
接着,计算有监督损失(supervised_loss),包括交叉熵损失(loss_seg)和Dice损失(loss_seg_dice)。这两个损失项分别衡量了模型在已标记数据上的分类准确性和分割质量。然后,根据当前迭代次数计算一致性权重(consistency_weight),并根据阈值(threshold)生成掩码(mask)。该掩码用于选择不确定性较低的预测结果。接下来,计算一致性损(consistency_loss),它衡量了模型在未标记数据上生成的伪标签与原始预测结果之间的一致性。最后,将监督损失和一致性损失加权求和得到最终的损失(loss),并使用梯度下降法更新m_seg1网络的参数。实现了一个基于半监督学习的训练过程,使用了两个分割网络(m_seg1 和 m_seg2),并结合了有监督损失和一致性损失来优化模型的性能。
代码解读
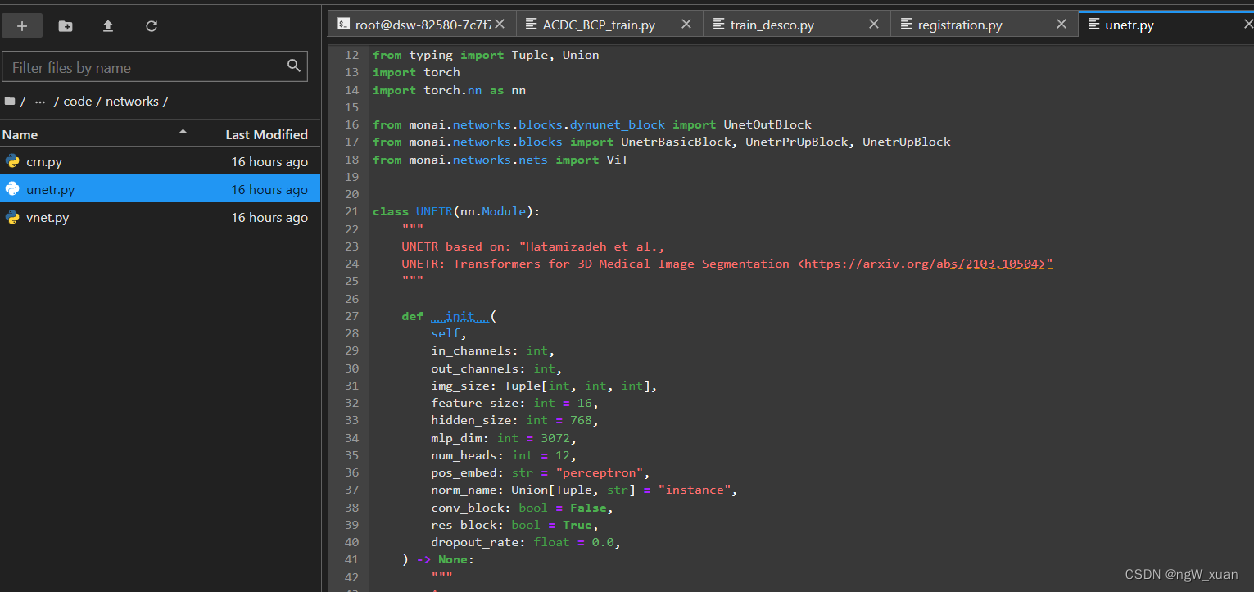
分割模型用的unetr
设置的两个m_seg用于后续不同的处理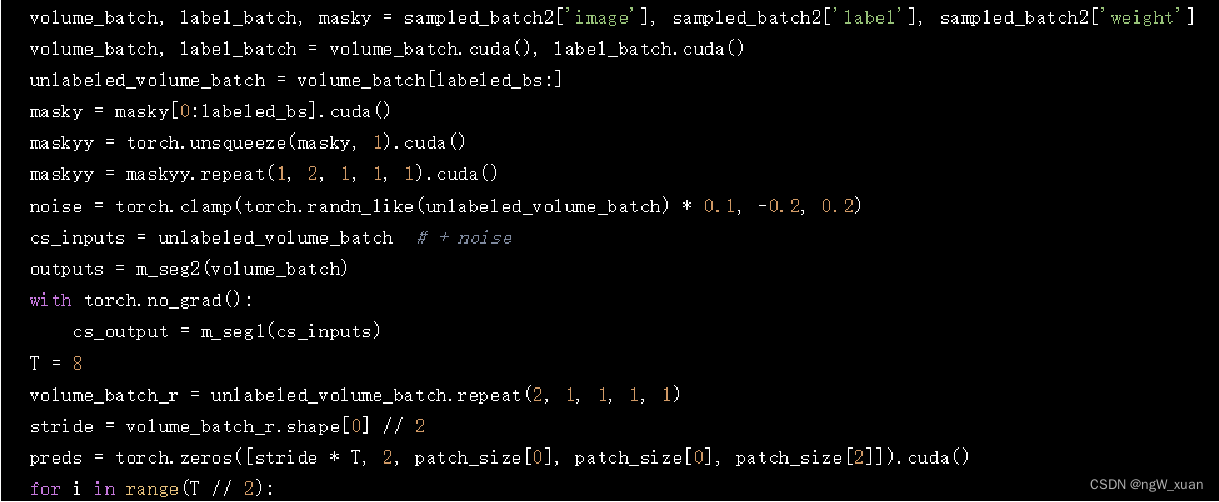 这里使用m_seg2模型处理整个批次(volume_batch),得到输出(outputs) 使用m_seg1模型处理无标签的批次(cs_inputs),得到输出(cs_output)
这里使用m_seg2模型处理整个批次(volume_batch),得到输出(outputs) 使用m_seg1模型处理无标签的批次(cs_inputs),得到输出(cs_output)
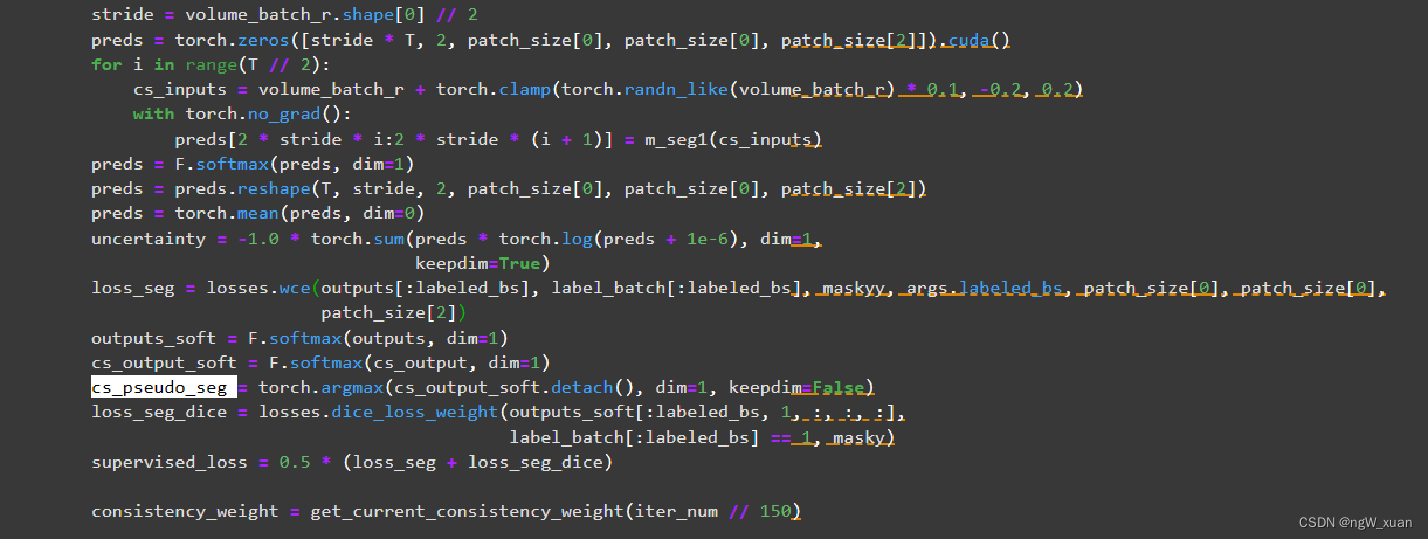
获取cs_pseudo_seg伪标签
















 236
236











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









