




引言
随着智能交通系统的快速发展,车牌识别技术作为其核心组成部分,正在各个领域得到广泛应用。无论是智慧停车场、高速公路收费站、还是社区安防系统,高效准确的车牌识别能力都是保障系统正常运行的关键。本文将分享一个基于YOLOv8目标检测和PaddleOCR文字识别技术的车牌识别系统实践,展示如何结合深度学习的最新成果,构建一个高性能的车牌识别应用。
系统概述
本文介绍的是一套基于YOLOv8和PaddleOCR的车牌识别系统,采用Flask框架搭建,能够高效准确地识别中国各类车牌。系统通过组合深度学习目标检测和OCR技术,实现了智能化的车牌定位与识别,并具备车牌记录管理、历史查询和统计分析等功能。
系统特点
- 多模式识别:支持纯OCR模式和YOLO+OCR混合模式,用户可自由切换
- 智能容错:当单一模式失效时会自动尝试替代方案
- 高精度识别:针对中文车牌格式优化,支持识别新能源车牌
- 分割图像展示:直观展示车牌区域,便于验证识别结果
- 数据统计分析:提供识别率、置信度等关键指标的统计
- 完整历史记录:所有识别结果保存入库,支持查询和管理
技术架构
核心技术栈
- 前端:HTML/CSS/JavaScript + Bootstrap
- 后端:Python + Flask
- 目标检测:YOLOv8(用于车牌定位)
- 文字识别:PaddleOCR(用于车牌文字识别)
- 数据存储:MySQL(记录识别结果)
识别流程
- 图像上传与预处理
- 车牌检测(YOLOv8)和区域分割
- 文字识别(PaddleOCR)
- 格式验证与后处理
- 结果展示与存储
技术实现细节
1. YOLOv8车牌检测
YOLOv8是目标检测领域的最新进展,相比前代模型,它具有更高的检测精度和更快的推理速度。在车牌检测任务中,我们对YOLOv8进行了特定优化:
-
使用包含各种场景(不同光照、角度、遮挡情况)的车牌数据集进行训练
-
针对中国车牌的特征(蓝牌、黄牌、新能源绿牌等)进行特化处理
-
优化模型大小和推理速度,使系统能在普通硬件上流畅运行
2. PaddleOCR文字识别
PaddleOCR是百度开源的OCR工具集,具有识别精度高、速度快、使用简单等特点。在本系统中:
-
使用了PaddleOCR的检测和识别模型,针对车牌字符进行了优化
-
实现了对车牌特殊字符的正确识别,如中间的点"·"
-
结合正则表达式验证,确保识别结果符合车牌格式规范
3. 智能识别策略
系统采用了自适应的识别策略,提高了整体识别成功率:
-
首先尝试OCR直接识别,对简单清晰的车牌效果好
-
如果OCR无法得到有效结果,且用户启用了YOLO选项,则切换到YOLO+OCR模式
-
对于YOLO检测到的多个车牌区域,系统会智能合并相邻区域,处理分段检测的情况
4. Web界面实现
系统前端基于Flask框架和Tailwind CSS构建,具有现代化的UI设计和良好的用户体验:
-
响应式设计,适配不同设备屏幕
-
实时识别反馈,清晰展示识别结果
-
交互式数据可视化,基于ECharts实现直观的数据展示
-
优化的滚动和模态框体验,确保操作流畅
关键代码解析
1. PaddleOCR初始化(优化版)
# 初始化PaddleOCR(兼容有无GPU环境)
try:
# 尝试指定use_gpu参数
ocr = PaddleOCR(use_angle_cls=True, lang="ch", use_gpu=False)
except ValueError:
# 如果发生错误,尝试不使用use_gpu参数
print("初始化PaddleOCR时发生错误,尝试不指定GPU参数")
ocr = PaddleOCR(use_angle_cls=True, lang="ch")2. 车牌识别核心函数
def detect_plate_with_yolo(image_path, only_detect=False):
"""使用YOLOv8检测车牌,并结合PaddleOCR进行识别
Args:
image_path: 图像路径
only_detect: 如果为True,只进行检测不进行识别
"""
# 读取图片
img = cv2.imread(image_path)
if img is None:
return None, "无法读取图片"
# 原始图像的副本,用于绘制结果
img_result = img.copy()
plates = []
# 使用YOLOv8检测车牌
detections = yolo_detector.detect_plates(img)
# 对检测结果进行合理性分析
if len(detections) > 1:
print(f"检测到 {len(detections)} 个可能的车牌区域,尝试分析它们的关系")
# 对所有检测到的区域进行合并尝试
merged_detections = []
used_indices = set()
# 合并相近的车牌区域(双层车牌处理)
for i, det1 in enumerate(detections):
if i in used_indices:
continue
x1_1, y1_1, x2_1, y2_1 = det1['box']
merged_box = list(det1['box'])
merged = False
for j, det2 in enumerate(detections):
if i == j or j in used_indices:
continue
x1_2, y1_2, x2_2, y2_2 = det2['box']
# 检查两个区域是否接近(水平或垂直方向)
horizontal_close = (x1_2 <= x2_1 + 50 and x2_2 >= x1_1 - 50)
vertical_close = (y1_2 <= y2_1 + 30 and y2_2 >= y1_1 - 30)
# 如果两个区域接近,合并它们
if horizontal_close and vertical_close:
# 合并区域代码...
merged = True
# 添加合并后的区域到结果中
if merged:
# 添加合并区域...
elif i not in used_indices:
merged_detections.append(det1)
used_indices.add(i)
# 使用合并后的检测结果
if len(merged_detections) < len(detections):
detections = merged_detections
# 处理检测到的每个车牌区域
if detections:
for detection in detections:
# 获取检测框坐标
x1, y1, x2, y2 = detection['box']
confidence = detection['confidence']
# 仅处理置信度高于0.5的检测结果
if confidence < 0.5:
continue
# 获取裁剪后的车牌图像
plate_img = detection['plate_img']
# 确保图像足够大,如果太小则调整大小
# 图像预处理代码...
# 使用PaddleOCR识别车牌号
try:
ocr_result = ocr.ocr(plate_img, cls=True)
if ocr_result and isinstance(ocr_result, list) and len(ocr_result) > 0:
# 处理OCR识别结果...
# 组合文本、验证车牌格式等
except Exception as e:
print(f"处理车牌图像时出错: {str(e)}")
# 异常处理...
# 生成输出图片并返回结果
# ...3. 智能识别模式实现
# 智能识别模式:先用OCR识别整图,再用YOLO分割显示
if use_yolo and yolo_detector.is_available():
print("使用智能识别模式: 先用OCR识别整图,再用YOLO分割显示")
try:
# 第一步:先用OCR识别整图,找到完整车牌
ocr_result, ocr_error = detect_plate(filepath)
if ocr_error:
print(f"OCR识别出错: {ocr_error}")
# 直接使用YOLO+OCR完整流程
result, error = detect_plate_with_yolo(filepath)
else:
# 检查OCR是否找到有效车牌
ocr_valid_plates = [p for p in ocr_result['plates'] if p['is_valid_plate']] if ocr_result and 'plates' in ocr_result else []
if ocr_valid_plates:
print(f"OCR识别到 {len(ocr_valid_plates)} 个有效车牌")
# 第二步:使用YOLO进行车牌分割
print("使用YOLO分割车牌区域用于显示")
yolo_result, yolo_error = detect_plate_with_yolo(filepath, only_detect=True)
# 如果YOLO检测到车牌区域,将OCR识别结果与YOLO分割图像关联
if yolo_result and 'plates' in yolo_result and yolo_result['plates']:
# 更新结果,使用OCR的识别结果但保留YOLO的分割图像
# 关联代码...
else:
# 使用OCR结果
result = ocr_result
else:
# OCR未识别到有效车牌,使用YOLO+OCR完整流程
result, error = detect_plate_with_yolo(filepath)
except Exception as e:
# 异常处理...
result, error = detect_plate_with_yolo(filepath)
else:
# 使用纯OCR方法
# 纯OCR识别逻辑...系统功能模块
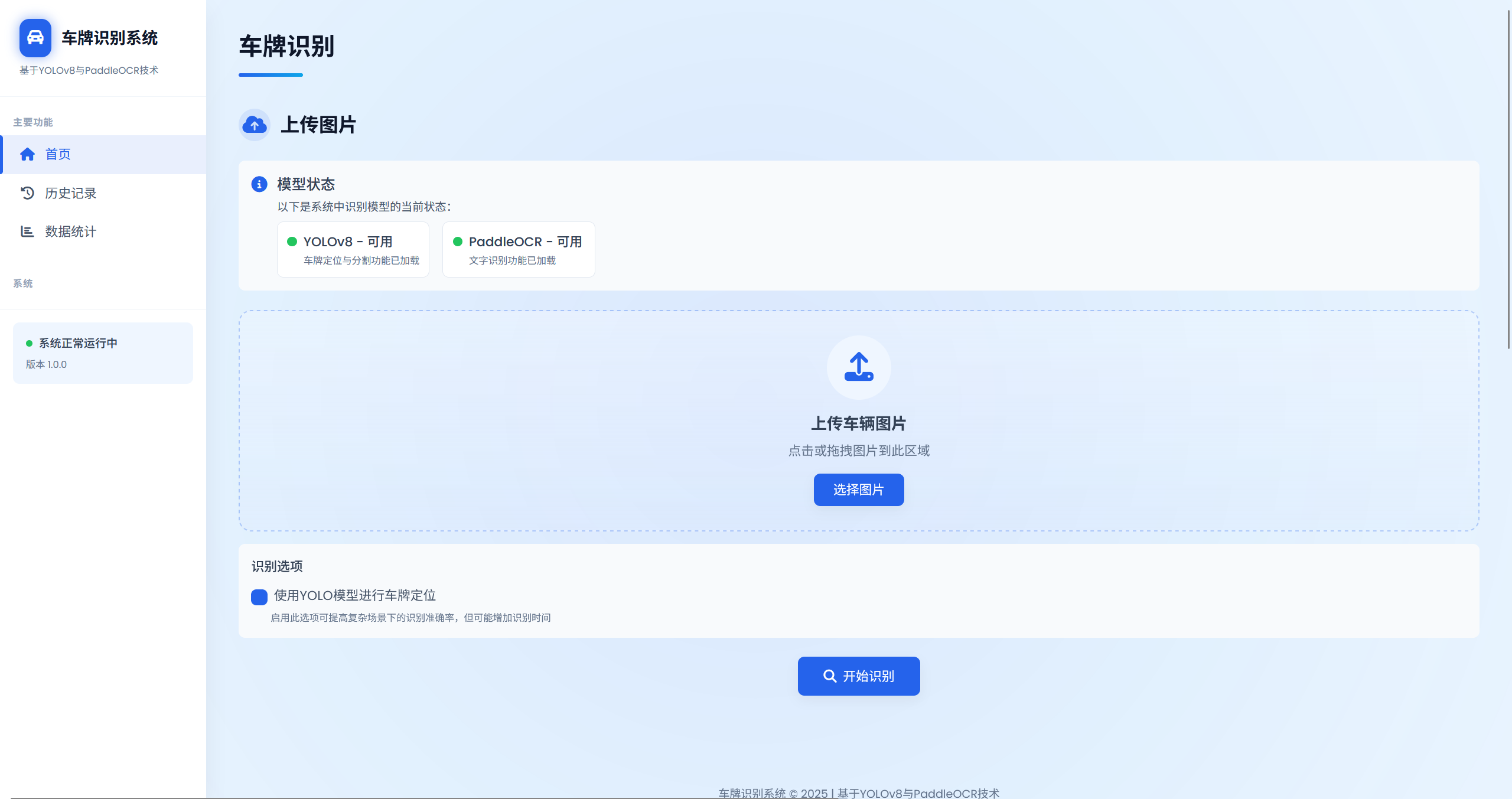
1. 主页识别模块
主页提供车牌上传和识别功能,用户可选择是否使用YOLO进行检测,系统会自动调整识别策略。
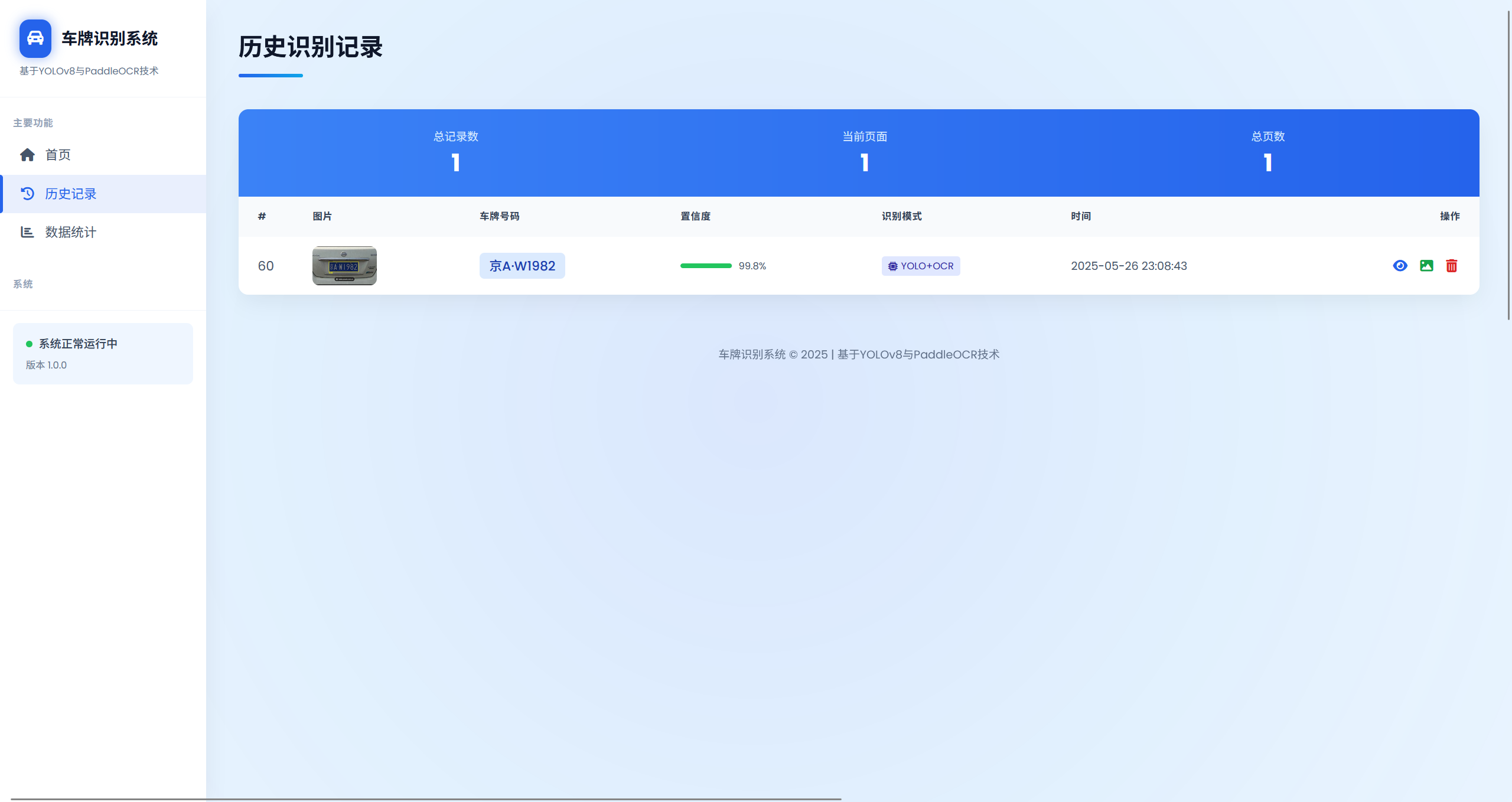
2. 历史记录管理
系统会自动记录所有识别结果,包括原始图像、识别结果、置信度等信息,支持分页查询和删除操作。
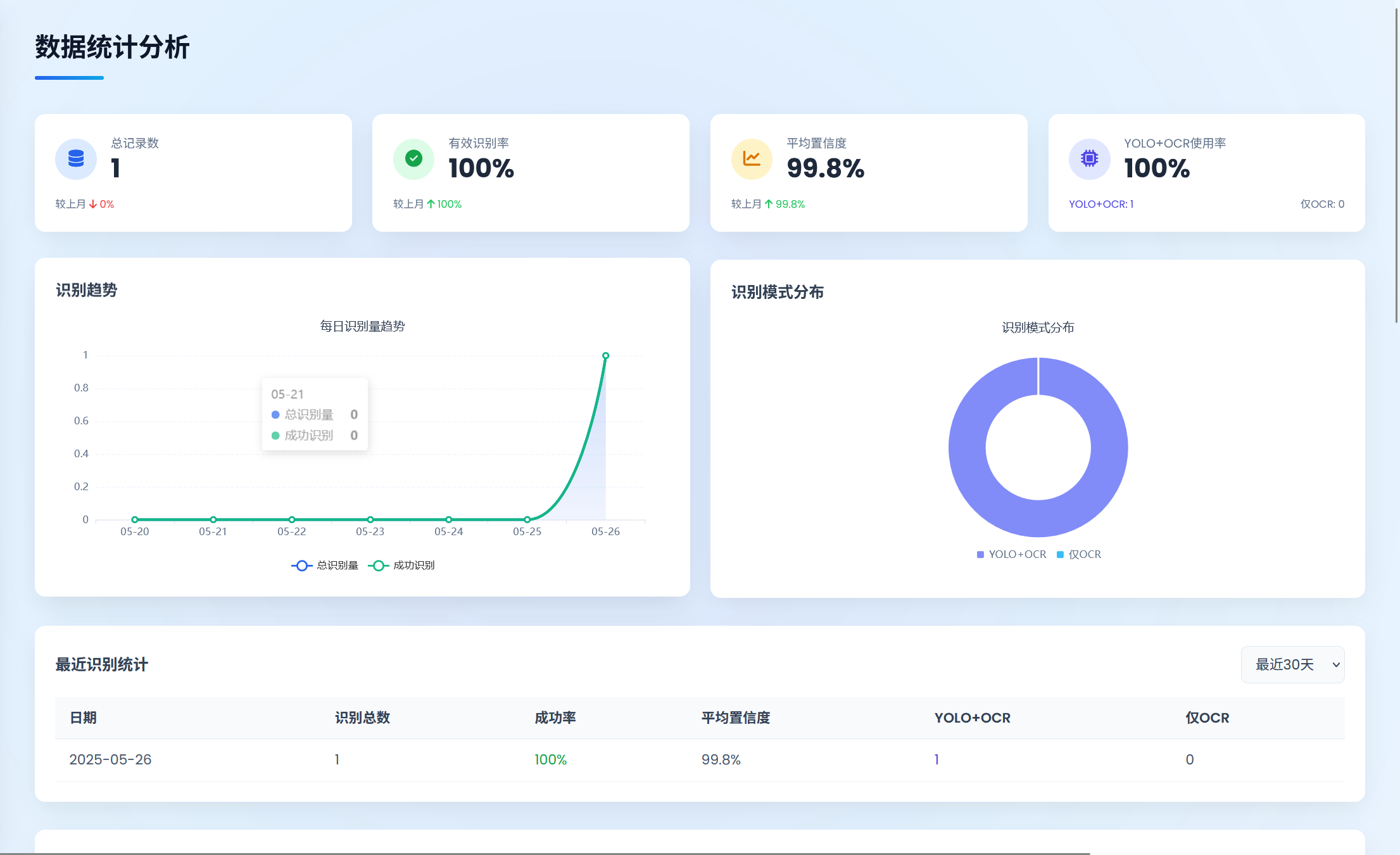
3. 统计分析功能
提供识别成功率、置信度、YOLO与OCR使用率等关键指标的统计分析,支持查看每日、每月数据趋势。
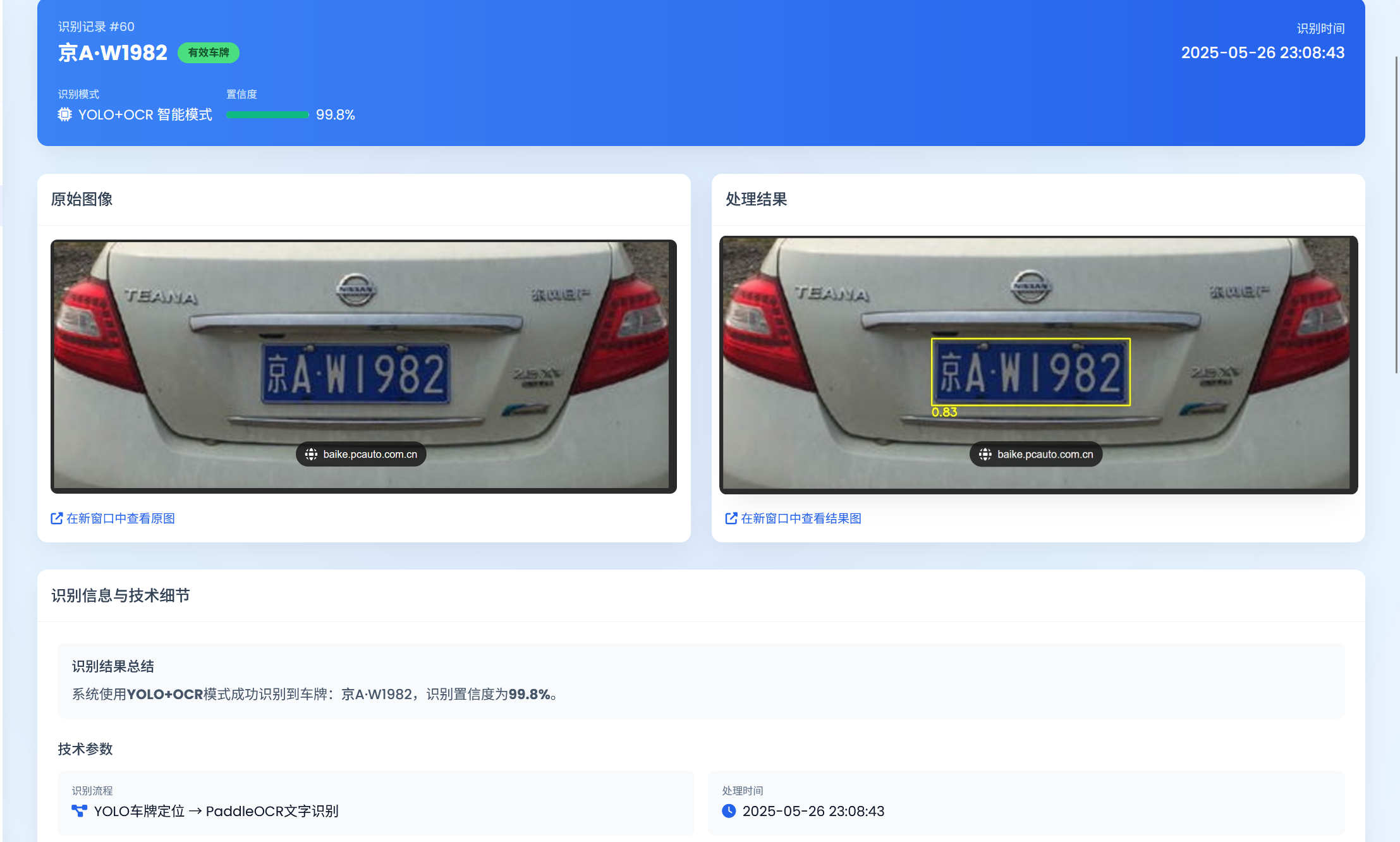
4. 详细记录查看
支持查看每条识别记录的详细信息,包括识别模式、车牌号码、置信度、分割车牌图像等。
系统优化
1. 容错处理
系统对各种异常情况都有处理机制,包括图像无法读取、模型加载失败、车牌检测失败等,确保系统稳定运行。
2. 环境适应性
针对不同环境(有无GPU)做了适配,确保在各种环境下都能正常运行。
3. 性能优化
- 对大尺寸图像进行适当缩放,提高处理速度
- 使用缓存减少重复计算
- 并行处理提高多车牌场景下的识别效率
实际应用场景
- 智慧停车场管理系统
- 交通监控系统
- 小区门禁系统
- 高速公路收费系统
- 公安交通违章检测系统
总结
获取系统方式
点击下方链接,阅读原文并关注公众号【YOLO检测与算法】发送车牌,获取本系统的全部源码+数据集
基于YOLOv8与PaddleOCR的智能车牌识别系统实践![]() https://mp.weixin.qq.com/s/Agd5ZduEuII6R1R2ASpJtg
https://mp.weixin.qq.com/s/Agd5ZduEuII6R1R2ASpJtg



















 554
554

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











