






五、时间处理
一、时间戳-----Timestamp类型
方法1:使用Timestamp创建
pandas.Timestamp(ts_input, freq=None, tz=None, unit=None, year=None, month=None, day=None, hour=None, minute=None, second=None, microsecond=None, tzinfo=None, offset=None)
import pandas as pd
ts1=pd.Timestamp('2023/4/19')
ts2=pd.Timestamp('20230419')
ts3=pd.Timestamp('2023-4-19')
print(ts1,ts2,ts3)#2023-04-19 00:00:00 2023-04-19 00:00:00 2023-04-19 00:00:00方法2:使用to_datetime函数
pandas.to_datetime(arg, errors='raise', dayfirst=False, yearfirst=False, utc=None, box=True, format=None, exact=True, unit=None, infer_datetime_format=False, origin='unix')
参数说明:
arg:需要转换的时间和日期
errors:值为ignore(无效的解析将返回原值),值为raise(无效的解析将引发异常),值为coerce(无效的解析将被置为NaT)
dayfirst:第一个为天,例如:23/11/2022,置为True:解析为 2022-11-23,置为False:解析为 2022-23-11
date_range()方法,用于生成一个固定频率的DatetimeIndex时间索引。
pandas.date_range(start=None, end=None, periods=None, freq=None, tz=None, normalize=False, name=None, closed=None, **kwargs)
常用参数为start、end、periods、freq。
start:指定生成时间序列的开始时间
end:指定生成时间序列的结束时间
periods:指定生成时间序列的数量
freq:生成频率,默认‘D’,可以是‘D’(天)、‘10D’、’H’(时)、‘5H’、‘T’(分)、‘S’(秒)、‘15T’、‘M’(月)
重采样(Resample方法)
Resample()方法: resample能搭配各种不同时间维度,进行分组聚合。针对分组情况你可以搭配使用max、min、sum、mean等使用
resample(rule, how=None, axis=0, fill_method=N one, closed=None, label=None, ..
To_period()方法可以将时间戳转换为日期,从而实现按照日期显示数据
示例 1:将时间序列数据进行降采样为3分钟间隔,对每个区间内的数值求和。

示例2:将时间序列数据进行上采样为30秒间隔,利用ffill和bfill填充

降采样:将高频率转换为低频率,使用聚合函数 升采样:将低频率转为高频率,会引入缺失值。
滑动窗口rolling函数
根据指定的单位长度来框住时间序列,从而计算框内的统计指标
DataFrame.rolling(window, min_periods=None, center=False, win_type=None, on=None, axis=0, closed=None)

六、机器学习
机器学习就是通过算法,使得机器能从大量历史数据中学习规律,并利用规律对新的样本做智能识别或对未来做预测。
机器学习的分类
1.按学习目标的不同,机器学习可分为:
监督学习(Supervised Learning)---有标签
无监督学习(Unsupervised Learning) ---无标签
半监督学习(Semi-Supervised Learning) ---有部分标签
强化学习(Reinforcement Learning, RL) ---有延迟的标签
2. 根据训练数据是否有标注,机器学习可划分为:
监督学习
无监督学习
1.监督学习
监督式学习需要使用有输入和预期输出标记的数据集。
监督学习的目的是通过学习许多有标签的样本,然后对新的数据做出预测。
监督学习又可分为“分类”和“回归”问题。
(1)分类问题
在分类问题中,机器学习的目标是对样本的类标签进行预测,判断样本属于哪一个分类,结果是离散的数值。
(2)回归问题 在回归问题中,其目标是预测一个连续的数值或者是范围。
数据集的划分
把数据分割成训练集(我们从中学习数据的属性)和测试集(我们测试这些性质)
训练集(Training set):用来拟合模型,通过设置分类器的参数,训练分类模型。
测试集(Test set):通过训练,得出最优模型后,使用测试集进行模型预测。用来衡量该最优模型的性能和分类能力。即可以把测试集视为从来不存在的数据集,当已经确定模型后,使用测试集进行模型性能评价。
Scikit-learn提供了train_test_split函数来帮助完成这一任务,train_test_split在model_selection模块下
聚类算法实现需要使用sklearn估计器(estimator)。
sklearn估计器拥有fit()和predict()两个方法,其说明如下表所示

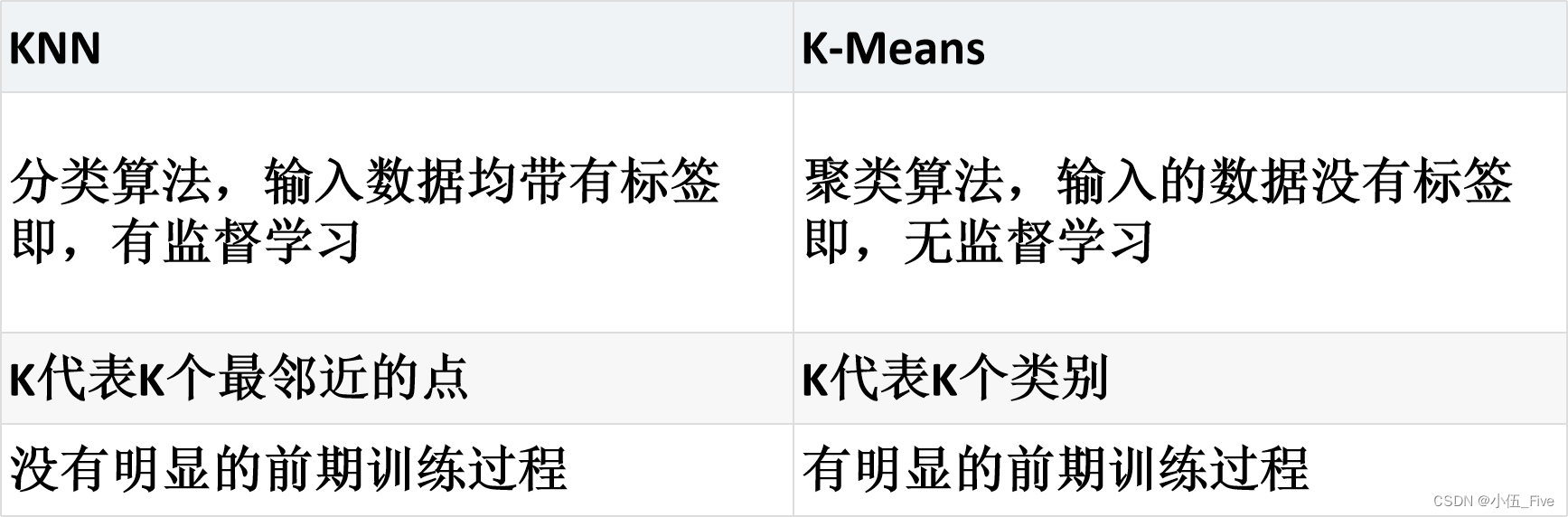
K-means算法
(1)参数k的选取方法
k-means算法需要事先确定簇的数量,也即,参数k。过大或过小的k值均不能获得高质量的聚类结果。
(2)初始质心的选择问题
(3)K-means的方法实现
model = KMeans (n_clusters = 4)
KNN算法
K最近邻算法原理:给定一个训练数据集,对新的输入实例,在训练数据集中找到与该实例最邻近的k个实例,这k个实例的多数属于某个类,就把该输入实例分类到这个类中。
流程:
(1)计算已知类别数据集中的点与当前点之间的距离;
(2)按照距离递增次序排序;
(3)选取与当前点距离最小的k个点;
(4)确定前k个点所在类别的出现频率;
(5)返回前k个点所出现频率最高的类别作为当前点的预测分类。
















 7654
7654

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











