






目录
安装所需要的库:http://t.csdnimg.cn/znzdj
(1)在本机的这个地方建立文件夹test_images然后将待检测的图片导入其中。
i.在detect.py文件中找到if save_img语句
iiii.运行detect.py,在输出文件里面得到添加了帧率的视频(!!但是到这里只有在输出视频里面显示了帧率)
iiiii.将此代码放入图片中所示位置后将在开启摄像头的画面中输出帧率
A创建pytorch环境,pycharm配置环境
参考链接:
Windows安装Anaconda,创建pytorch环境,pycharm配置环境_安装pytorch时卡在100%下不下来-CSDN博客
(1)为conda添加清华源: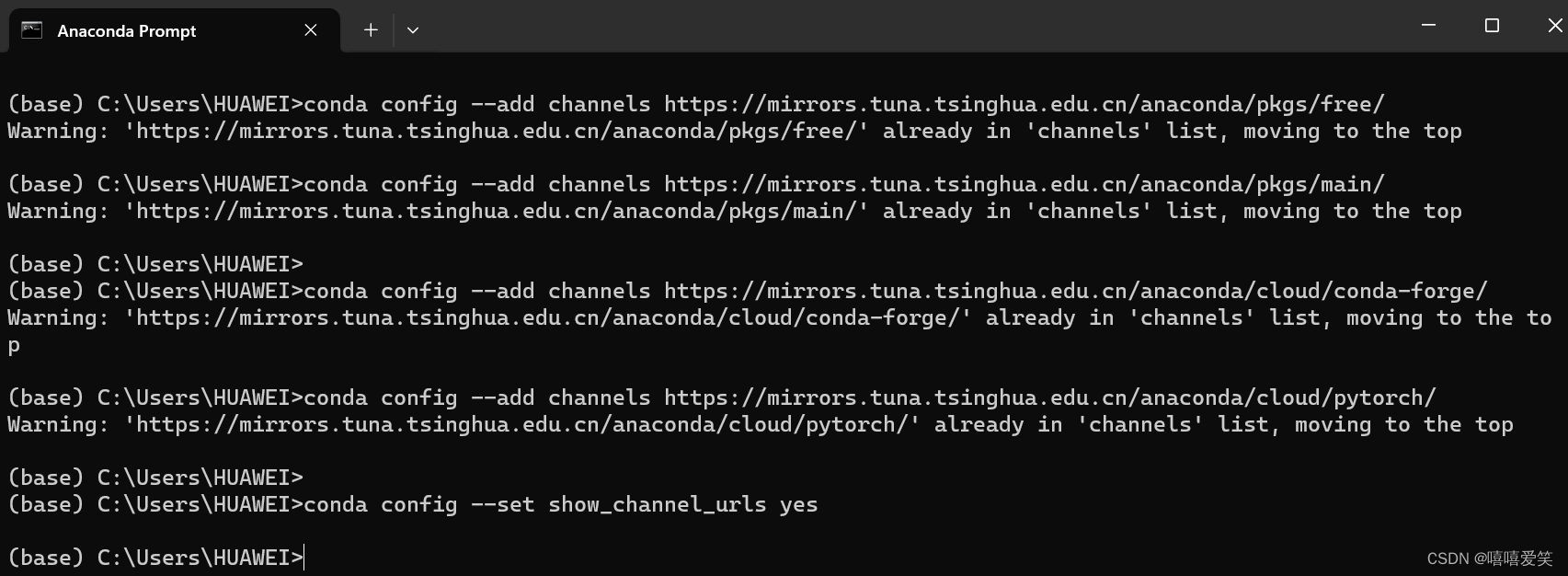
(2)创建一个新的环境:

创建完成的指令界面:

(3)查看我们刚才创建的环境是否成功:

(4)切换到新的环境:

(5)安装依赖的库:(1.26.4)

i.(6)安装pytorch:GPU
- 确定自己cuda的版本(前提是你有英伟达的显卡) 。命令: nvidia-smi
- 上pytorch官网找对应版本的torch和cudatoolkit , PyTorch 翻到最下面可以看到

- 找到对应命令下载:

- 使用 conda list 查看安装的依赖:
![]()

ii.(6)安装pytorch:CPU
- 进入Pytorch官网PyTorch,点击Get Started.(我的电脑是集成显卡,只能选择CPU版本,如下图所示)

- 复制Run this Command后面这段代码,在之前的命令行窗口中输入(输入之前要激活pytorch环境),记得删掉后面的-c pytorch(前提是Anaconda中添加了清华大学镜像源,否则不能删除),它表示从官网进行下载,可能会出现下载速度慢或者卡顿。

- 检查pytorch是否安装成功,输入下面三条代码,如图所示,即表示安装成功

安装成功:
pycharm中配置环境成功

安装所需要的库:http://t.csdnimg.cn/znzdj
(1)先下载yolov5项目:将文件解压缩后,剪切到创建的pycharm项目所在文件夹内


(2)在pycharm的终端里面安装所需要的库(先打开文件)

(3)测验detect.py --环境配置成功


B制作数据集
参考教程
使用Labelimg制作VOC数据集或yolo数据集的入门方法_dic-labels labelimgtoyol-CSDN博客
(1)在pycharm的终端里面安装labelimg

(2)终端输入:labelimg,打开labelimg

拍摄了207张照片放到一个文件夹中

(3)打标签

问题:由于训练的数据需要分为三个文件夹:训练集、测试集和验证集。(而我们做的时候只有yolo数据集,因此参考此链接将yolo数据集分为我们需要的三种)http://t.csdnimg.cn/cBTrc
import os
import shutil
import random
random.seed(0) # 确保随机操作的可复现性
def split_data(file_path, xml_path, new_file_path, train_rate, val_rate, test_rate):
# 存储图片和标注文件的列表
each_class_image = []
each_class_label = []
# 将图片文件名添加到列表
for image in os.listdir(file_path):
each_class_image.append(image)
# 将标注文件名添加到列表
for label in os.listdir(xml_path):
each_class_label.append(label)
# 将图片和标注文件打包成元组列表并随机打乱
data = list(zip(each_class_image, each_class_label))
total = len(each_class_image)
random.shuffle(data)
# 解压元组列表,回到图片和标注文件列表
each_class_image, each_class_label = zip(*data)
# 按照指定的比例分配数据到训练集、验证集和测试集
train_images = each_class_image[0:int(train_rate * total)]
val_images = each_class_image[int(train_rate * total):int((train_rate + val_rate) * total)]
test_images = each_class_image[int((train_rate + val_rate) * total):]
train_labels = each_class_label[0:int(train_rate * total)]
val_labels = each_class_label[int(train_rate * total):int((train_rate + val_rate) * total)]
test_labels = each_class_label[int((train_rate + val_rate) * total):]
# 定义复制文件到新路径的操作
def copy_files(files, old_path, new_path1):
# 遍历列表中的每一个文件名
for file in files:
# 打印当前处理的文件名,这只是为了在处理过程中输出信息,便于跟踪进度
print(file)
# 使用os.path.join连接旧路径和新文件名,形成完整的旧文件路径
old_file_path = os.path.join(old_path, file)
# 检查新的路径是否存在,如果不存在则创建新的路径,这可以确保复制操作不会因为路径不存在而出错
if not os.path.exists(new_path1):
os.makedirs(new_path1)
# 使用os.path.join连接新路径和新文件名,形成完整的新文件路径
new_file_path = os.path.join(new_path1, file)
# 使用shutil模块的copy函数复制旧文件到新路径,生成与旧文件相同的新的文件
shutil.copy(old_file_path, new_file_path)
# 复制训练、验证和测试的图片和标注文件到指定目录
copy_files(train_images, file_path, os.path.join(new_file_path, 'train', 'images'))
copy_files(train_labels, xml_path, os.path.join(new_file_path, 'train', 'labels'))
copy_files(val_images, file_path, os.path.join(new_file_path, 'val', 'images'))
copy_files(val_labels, xml_path, os.path.join(new_file_path, 'val', 'labels'))
copy_files(test_images, file_path, os.path.join(new_file_path, 'test', 'images'))
copy_files(test_labels, xml_path, os.path.join(new_file_path, 'test', 'labels'))
# 判断当前脚本是否为主程序入口,即直接运行该脚本
if __name__ == '__main__':
# 定义文件路径变量,指向数据集的原图像文件所在路径
file_path = "E:\myyolo\yolo\data"
# 定义xml路径变量,指向数据集的标注后文件所在路径
xml_path = "E:\myyolo\yolo\mydata"
# 定义新文件路径变量,指向输出结果文件的新路径
new_file_path = "E:\myyolo\yolo\final_data"
# 调用split_data函数,分割数据集,并将结果分别存储到指定的路径中
split_data(file_path, xml_path, new_file_path, train_rate=0.7, val_rate=0.1, test_rate=0.2)


运行结束后:

数据集已准备完毕。
C开始训练
参考链接:http://t.csdnimg.cn/znzdj(从4.修改yolov5命令行参数开始)
【踩坑】YOLO5 训练模型的测试结果全部相反(标签混乱):http://t.csdnimg.cn/2OJIO

解决:
使用 labelImg 为图片打好标签后,在为模型配置数据集的 yaml 文件中,class name 列表中的元素顺序应该与标签文件夹中 classes.txt 文件中的标签顺序一致。
报错1:

解决:
在import os后加上
os.environ["GIT_PYTHON_REFRESH"] = "quiet"

解决:点击报错里面的链接下载arial.ttf剪切到这个目录里面再重新运行一下train.py
训练成功:


D训练结果
参考链接:http://t.csdnimg.cn/znzdj
(1)在本机的这个地方建立文件夹test_images然后将待检测的图片导入其中。

(2)修改图片中第三、四行中的部分代码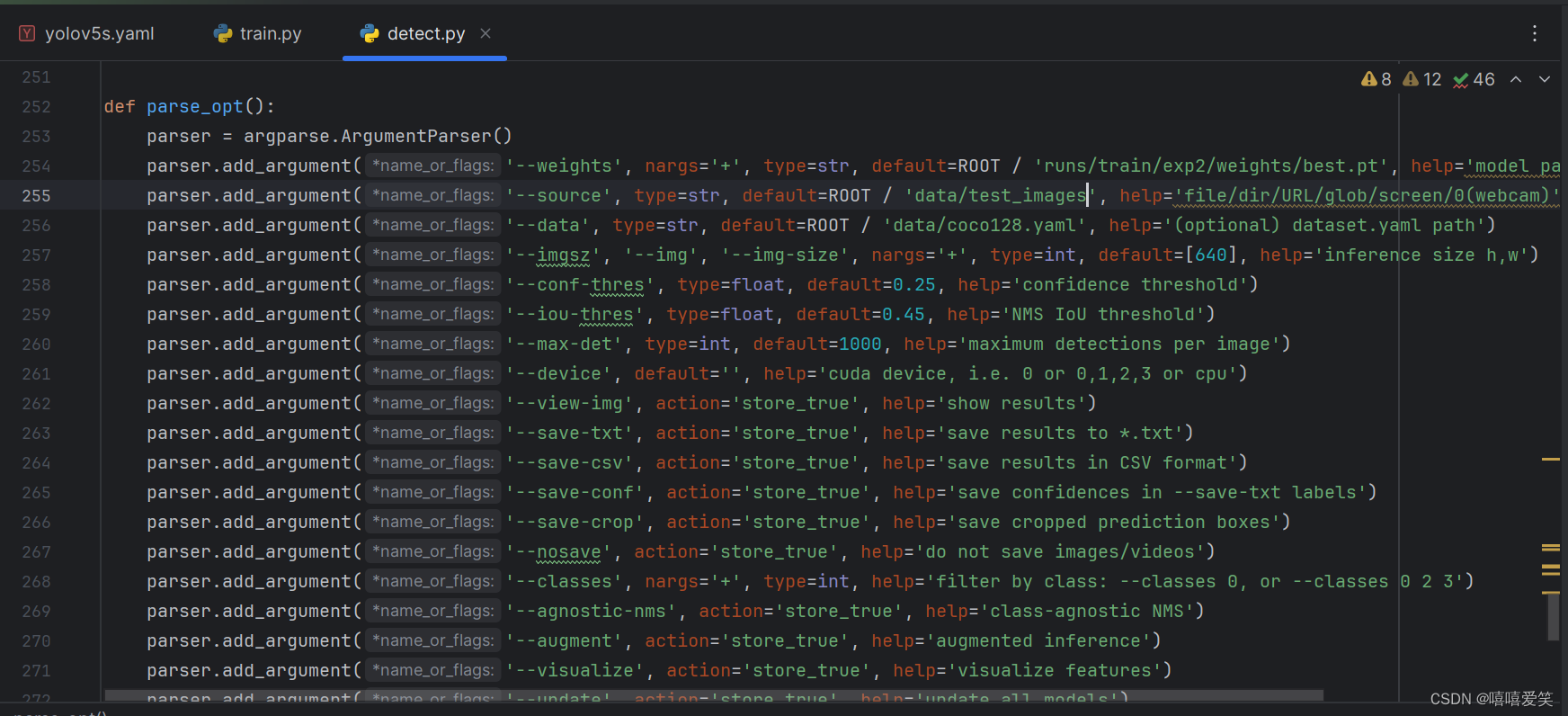
(3)运行结果可视化!!此处做了一个对比



左为GPU,右为CPU






结果:左边的置信度明显高于右边!!
Yolov5实时目标检测(视频流)
参考链接:http://t.csdnimg.cn/a8Mwq
1. 修改detect.py
将红色框的default设置为0

2. 修改utils文件夹下的dataloaders.py
将387-395行中的代码注释,并将396行中的s修改为0,在运行detect.py。

- 在输出视频中添加帧率
参考链接:http://t.csdnimg.cn/lbQq8
i.在detect.py文件中找到if save_img语句

ii.在if save_img所在函数开头加入
tt = time.time()

iii.在if save_img:语句里面加入
# 添加帧率检测
cv2.putText(im0, "FPS:{:.1f}".format(1. / (time.time() - tt)), (50, 50), cv2.FONT_HERSHEY_SIMPLEX, 2, (0, 0, 235), 4)
tt = time.time()

iiii.运行detect.py,在输出文件里面得到添加了帧率的视频(!!但是到这里只有在输出视频里面显示了帧率)

iiiii.将此代码放入图片中所示位置后将在开启摄像头的画面中输出帧率

代码注释
一.代码参数的注释
i.detect.py
def parse_opt():
parser = argparse.ArgumentParser()
parser.add_argument('--weights', nargs='+', type=str, default='runs/train/exp/weights/best.pt', help='model path or triton URL') #需要的模型地址,选择best.pt
parser.add_argument('--source', type=str, default='data/compare_images', help='file/dir/URL/glob/screen/0(webcam)')
#图片或mp4视频存放地址
parser.add_argument('--conf-thres', type=float, default=0.25, help='confidence threshold')
#设置的检测概率大于0.25才显示出来
parser.add_argument('--iou-thres', type=float, default=0.45, help='NMS IoU threshold')
#框选物体的框框重合度
parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
#default 默认为空,自动检测为cuda还是cpu
parser.add_argument('--save-txt', action='store_true', help='save results to *.txt')
parser.add_argument('--save-csv', action='store_true', help='save results in CSV format')
parser.add_argument('--save-conf', action='store_true', help='save confidences in --save-txt labels')
#class name 列表中的元素顺序应该与标签文件夹中 classes.txt 文件中的标签顺序一致。
ii.train.py
def parse_opt(known=False):
parser = argparse.ArgumentParser()
parser.add_argument('--weights', type=str, default=ROOT / 'yolov5s.pt', help='initial weights path') #参数yolov5s是在models里s、m、l几种不同大小的网络模型,s是最基础的也是跑起来最快的.
parser.add_argument('--epochs', type=int, default=100, help='total training epochs')
#default=100 训练过程数据将被轮100次
parser.add_argument('--batch-size', type=int, default=8, help='total batch size for all GPUs, -1 for autobatch')
#default=8 一次往gpu中塞8张照片
parser.add_argument('--imgsz', '--img', '--img-size', type=int, default=640, help='train, val image size (pixels)')
#模型训练和验证时输入图片的尺寸
parser.add_argument('--nosave', action='store_true', help='only save final checkpoint')
#只保留最后一次训练的权重
parser.add_argument('--project', default=ROOT / 'runs/train', help='save to project/name')
#设置每次训练结果保存的主路径名称
parser.add_argument('--name', default='exp', help='save to project/name')
#设置每次训练结果保存的子路径名称
iii.yolov5s.yaml
nc: 2 #修改分类数
#再yolov5s.yaml里修改分类数
iiii.新建的mydata.yaml
train: D:\robort403\yolo_task\final_data\train #训练集地址
val: D:\robort403\yolo_task\final_data\val #验证集地址
test: D:\robort403\yolo_task\final_data\test #测试集地址
nc: 2 #分类数
names: ['cell phone', 'mouse'] #类名
二.代码中结果可视化部分的注释
i. 打印目标检测结果
# Write results
for *xyxy, conf, cls in reversed(det):
c = int(cls) #整数类别
label = names[c] if hide_conf else f'{names[c]}' #标签名称
confidence = float(conf) #置信度
confidence_str = f'{confidence:.2f}' #格式化为两位小数的字符串
if save_csv: #保存为CSV文件
write_to_csv(p.name, label, confidence_str)
if save_txt: #保存为文本文件 xywh = (xyxy2xywh(torch.tensor(xyxy).view(1, 4)) / gn).view(-1).tolist() #归一化后的xywh坐标
line = (cls, *xywh, conf) if save_conf else (cls, *xywh) #标签格式
with open(f'{txt_path}.txt', 'a') as f:
f.write(('%g ' * len(line)).rstrip() % line + '\n') #写入对应的文件夹里,路径默认为“runs\detect”
if save_img or save_crop or view_img: #添加边界框到图像
c = int(cls) #整数类别
label = None if hide_labels else (names[c] if hide_conf else f'{names[c]} {conf:.2f}') #标签名称和置信度
annotator.box_label(xyxy, label, color=colors(c, True)) #在图像上绘制边界框和标签
if save_crop: #保存裁剪的图像
save_one_box(xyxy, imc, file=save_dir / 'crops' / names[c] / f'{p.stem}.jpg', BGR=True) #保存裁剪后的图像到指定路径中
ii. 在窗口中实时查看检测结果
# Stream results
im0 = annotator.result() #获取到处理后的图像,保存在im0中
cv2.putText(im0, "FPS:{:.1f}".format(1. / (time.time() - tt)), (50, 50), cv2.FONT_HERSHEY_SIMPLEX, 2,(0, 0, 235), 4) #在图像上显示当前图像帧率(FPS)
if view_img: #如果设置了view_img为True,即需要显示图像
if platform.system() == 'Linux' and p not in windows:
windows.append(p)
cv2.namedWindow(str(p), cv2.WINDOW_NORMAL | cv2.WINDOW_KEEPRATIO) # allow window resize (Linux)
cv2.resizeWindow(str(p), im0.shape[1], im0.shape[0])
cv2.imshow(str(p), im0) #在窗口中显示图像
cv2.waitKey(1) #等待用户输入,每1毫秒处理一次键盘事件
iii.设置保存结果
# Save results (image with detections)
if save_img: #如果save_img为True,则保存图像
tt = time.time() #获取当前时间tt
#根据数据集的模式进行不同的保存操作
if dataset.mode == 'image': #如果数据集模式为’image’,即处理的是单张图像,则使用cv2.imwrite函数将im0保存到指定的路径save_path
cv2.imwrite(save_path, im0)
else: # 'video' or 'stream' #如果数据集模式为’video’或’stream’,即处理的是视频或实时流,则需要进行一些判断。
if vid_path[i] != save_path: #判断当前保存路径save_path是否与之前的视频路径vid_path[i]不同,如果不同,说明要保存新的视频。
vid_path[i] = save_path
if isinstance(vid_writer[i], cv2.VideoWriter): #释放之前的视频写入器(如果已存在)
vid_writer[i].release()
#获取视频的帧率(fps)、宽度和高度
if vid_cap: #如果是视频文件,则使用cv2.VideoCapture函数打开视频文件获取这些信息
fps = vid_cap.get(cv2.CAP_PROP_FPS)
w = int(vid_cap.get(cv2.CAP_PROP_FRAME_WIDTH))
h = int(vid_cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
else: #如果是实时流,则将帧率fps设置为30,宽度w和高度h设置为im0的形状
fps, w, h = 30, im0.shape[1], im0.shape[0]
save_path = str(Path(save_path).with_suffix('.mp4')) #保存路径save_path转换为以’.mp4’为后缀的文件名,强制使用.mp4格式保存结果视频。
vid_writer[i] = cv2.VideoWriter(save_path, cv2.VideoWriter_fourcc(*'mp4v'), fps, (w, h)) #cv2.VideoWriter函数创建视频写入器,写入器的参数包括保存路径、视频编码格式(使用mp4v编码)、帧率和视频大小(宽度和高度)。
vid_writer[i].write(im0) #使用写入器的write函数将im0写入视频中。
















 2770
2770

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









