






SMOTE(Synthetic Minority Over-sampling Technique)是一种处理不平衡数据集的流行方法,通过在少数类样本之间合成新的样本来平衡数据集,从而提高分类模型的性能 。SMOTE算法的基本原理是识别少数类样本的K近邻,然后在这些近邻之间通过线性插值生成新的合成样本 。
SMOTE方法的实现步骤如下:
- 识别少数类样本。
- 对于每个少数类样本,通过
K-近邻算法找到其K个最近的邻居。 - 选择其中一个邻居,然后在该邻居和当前样本之间生成新的合成样本。
- 重复上述过程,直到达到所需的样本平衡 。
SMOTE算法的优点在于它不简单地复制少数类样本,而是通过合成新样本来避免过拟合的问题 。然而,SMOTE也存在一些问题,比如合成样本的质量可能受到噪声样本的影响,以及在类边界附近合成样本可能会模糊类边界 。
为了解决这些问题,研究者们提出了SMOTE的多种改进算法,例如:
- Borderline-SMOTE:只考虑分类边界附近的少数类样本进行过采样 。
- Safe-Level-SMOTE:在合成新样本前为每个样本分配安全系数,以保证新样本分布在安全区域内 。
- ADASYN:根据少数类样本的分布自适应地改变不同样本的权重,为较难学习的样本合成更多的新样本 。
此外,还有结合欠采样和SMOTE的方法,如AdaBoost-SVM-MSA算法,它结合了SMOTE过采样和基于聚类的欠采样 。还有基于数据清洗的过滤算法,如SMOTE-Tomek和SMOTE-ENN,它们结合了SMOTE过采样和样本清洗技术 。
在实际应用中,SMOTE算法可以通过Python的imblearn库来实现,该库提供了SMOTE及其变体的实现,使得在机器学习项目中处理不平衡数据变得更加方便 。例如,使用imblearn库中的SMOTE类,可以很容易地对数据集进行过采样处理 。
在Python中使用SMOTE算法的一个简单案例可以通过以下步骤实现:
-
安装所需的库:首先,确保安装了
imbalanced-learn库,它提供了SMOTE算法的实现。如果尚未安装,可以通过以下命令进行安装:pip install -U imbalanced-learn -
导入库:导入所需的Python库,包括
imblearn中的SMOTE,以及sklearn中的数据集生成器和可视化工具。from imblearn.over_sampling import SMOTE from sklearn.datasets import make_classification import matplotlib.pyplot as plt -
生成数据集:使用
sklearn的make_classification函数生成一个不平衡的数据集。X, y = make_classification(n_classes=2, class_sep=2, weights=[0.1, 0.9], n_informative=3, n_redundant=1, flip_y=0, n_features=20, n_clusters_per_class=1, n_samples=1000, random_state=42) -
使用SMOTE进行过采样:创建SMOTE实例并使用它来平衡数据集。
smote = SMOTE(random_state=42) X_resampled, y_resampled = smote.fit_resample(X, y) -
可视化原始和平衡后的数据集:使用
matplotlib可视化原始数据集和经过SMOTE处理后的数据集。plt.figure(figsize=(12, 6)) plt.subplot(1, 2, 1) plt.scatter(X[y == 0][:, 0], X[y == 0][:, 1], label='Class 0', alpha=0.5) plt.scatter(X[y == 1][:, 0], X[y == 1][:, 1], label='Class 1', alpha=0.5) plt.title('Original dataset') plt.legend() plt.subplot(1, 2, 2) plt.scatter(X_resampled[y_resampled == 0][:, 0], X_resampled[y_resampled == 0][:, 1], label='Class 0', alpha=0.5) plt.scatter(X_resampled[y_resampled == 1][:, 0], X_resampled[y_resampled == 1][:, 1], label='Class 1', alpha=0.5) plt.title('Resampled dataset with SMOTE') plt.legend() plt.tight_layout() plt.show()
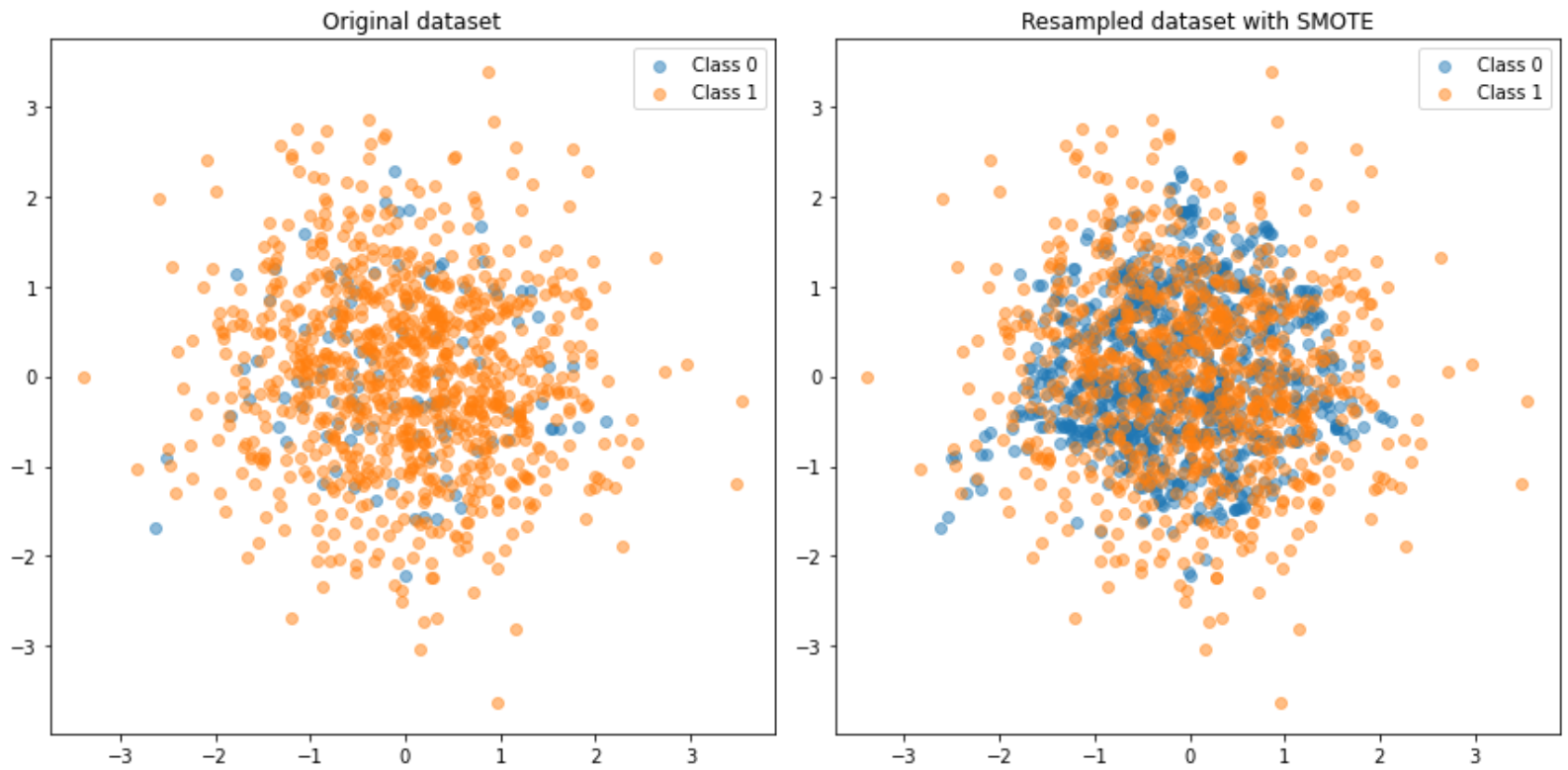
上述案例展示了如何使用SMOTE算法来平衡一个合成的二分类数据集,并通过可视化展示了处理前后的数据分布。
总的来说,SMOTE是一个强大的工具,用于处理不平衡数据集,并且有多种变体和改进算法来解决其潜在的问题。在实际应用中,可以根据具体问题选择合适的SMOTE变体或改进算法来提高模型性能。















 853
853

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









