






假设某棵二叉树有N个叶结点。给定这些叶结点的权值,求所有可能的二叉树中带权路径长度(WPL)的最小值。
注:
- 结点的带权路径长度(WPL):结点的权值乘以该结点的深度(假设根节点的深度为0);
- 二叉树的带权路径长度(WPL):二叉树中所有叶结点的带权路径长度之和。
输入描述
每个输入文件中一组数据。
第一行是一个整数N(2<=N<=100),表示叶结点的个数。
第二行为用空格隔开的N个不超过1000的正整数(不保证唯一),表示所有叶结点的权值。
输出描述
输出一个正整数,表示最小带权路径长度。
样例1
输入
5
16 30 21 10 12
输出
200
思路:
构建一颗哈夫曼树,然后dfs遍历求带权路径,我感觉这样应该是最小的
下面是我模仿的代码(错的)
#include<iostream>
#include<algorithm>
#include<cstring>
#include<string>//to_string(value)
#include<cstdio>
#include<cmath>
#include<vector>//res.erase(unique(res.begin(), res.end()), res.end())
#include<queue>
#include<stack>
#include<map>
#include<set>//iterator,insert(),erase(),lower/upper_bound(value)/find()return end()
#define ll long long
using namespace std;
int a[110];
bool cmp(int k1, int k2) {
return k1 > k2;
}
typedef struct Tree {
int data;
struct Tree* lc;
struct Tree* rc;
}tree;
vector<tree*>nm;
int dfs(tree* tr, int l) {
if (tr == NULL) {
return 0;
}
else if (tr->lc == NULL && tr->rc == NULL) {
return tr->data * l;
}
return dfs(tr->lc, l + 1) + dfs(tr->rc, l + 1);
}
signed main() {
int n;
cin >> n;
for (int i = 0; i < n; i++) {
cin >> a[i];
}
sort(a, a + n, cmp);
for (int i = 0; i < n; i++) {
tree* T;
T = new tree;
T->data = a[i];
T->lc = NULL;
T->rc = NULL;
nm.push_back(T);
}
while (nm.size() != 1) {
tree* T, * T1, * T2;
T1 = nm.back();
nm.pop_back();
T2 = nm.back();
nm.pop_back();
T = new tree;
T->data = T1->data + T2->data;
T->lc = T1;
T->rc = T2;
nm.push_back(T);
}
tree* head;
head = nm.back();
cout << dfs(head, 0);
}
输出结果:
208
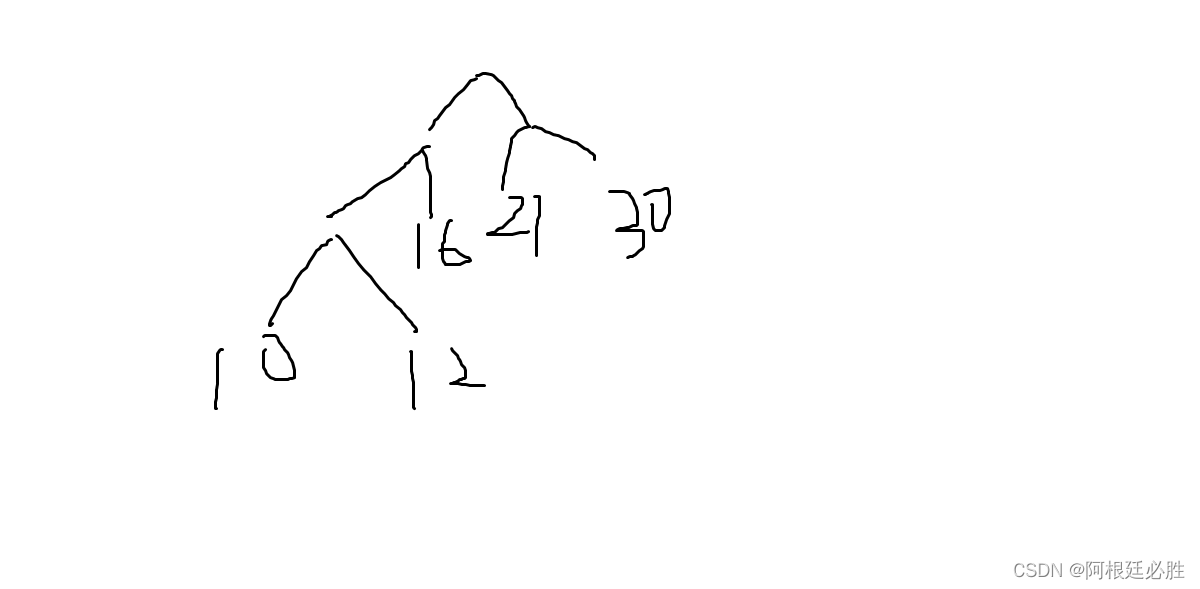
我输出的树

题目可能要求的树
我参考的代码
#include <cstdio>
#include <queue>
#include <vector>
using namespace std;
vector<int> vi;
struct node {
int v;
node* left = nullptr;
node* right = nullptr;
};
struct cmp {
// 优先队列排序规则按权值最小的放队首
bool operator()(const node* a, const node* b) {
return a->v > b->v;
}
};
int dfs(node* root, int l) {
if (root == nullptr) return 0;
if (root->left == nullptr && root->right == nullptr) {
return root->v * l; // 返回叶节点的带权路径长度
} else {
return dfs(root->left, l + 1) + dfs(root->right, l + 1); // 左右子树的递归结果之和
}
}
int getWpl() {
priority_queue<node*, vector<node*>, cmp> q;
// 将所有叶节点加入队列
for (int i = 0; i < vi.size(); i++) {
node* t = new node();
t->v = vi[i]; // 叶节点
t->left = nullptr;
t->right = nullptr;
q.push(t);
}
// 每次合并两个最小权值节点
while(q.size() != 1) {
node* a = q.top();
q.pop();
node* b = q.top();
q.pop();
node* t = new node();
t->v = a->v + b->v; // 新节点权值之和
t->left = a; // 关联左孩子
t->right = b; // 关联右孩子
q.push(t); // 新节点入队
}
node* root = q.top(); // 构建出的二叉树根节点
return dfs(root, 0); // 计算wpl
}
int main() {
int n, x;
scanf("%d", &n);
for (int i = 0; i < n; i++) {
scanf("%d", &x);
vi.push_back(x);
}
printf("%d\n", getWpl());
return 0;
}下面是chatGPT给我的思路
二叉树的带权路径长度(Weighted Path Length,WPL)是指所有叶子节点的权值乘以它们到根节点的路径长度之和。带权路径长度最小值是指在所有可能的二叉树中,WPL最小的那个二叉树。 计算二叉树的带权路径长度最小值可以使用哈夫曼树算法。哈夫曼树是一种特殊的二叉树,它的叶子节点是给定的权值,每个非叶子节点的权值是其左右子树权值之和。哈夫曼树的带权路径长度最小,因此可以用来计算二叉树的带权路径长度最小值。 具体算法如下: 1. 将所有节点按照权值从小到大排序,构造n棵只有一个节点的二叉树。 2. 从这n棵二叉树中选择两棵权值最小的二叉树,合并成一棵新的二叉树,新的二叉树的根节点权值为两棵子树的权值之和。 3. 将新的二叉树插入到原来的二叉树集合中,删除原来的两棵子树。 4. 重复步骤2和3,直到只剩下一棵二叉树为止。 5. 计算这棵二叉树的带权路径长度,即为二叉树的带权路径长度最小值。 时间复杂度为O(nlogn),其中n为节点数。
第二遍写发现问题所在
我忘记在vector中对新建的树的大小进行比较
#include<iostream>
#include<algorithm>
#include<cstring>
#include<string>//to_string(value)
#include<cstdio>
#include<cmath>
#include<vector>//res.erase(unique(res.begin(), res.end()), res.end())
#include<queue>
#include<stack>
#include<map>
#include<set>//iterator,insert(),erase(),lower/upper_bound(value)/find()return end()
#define ll long long
using namespace std;
int a[110];
bool cmp(int k1, int k2) {
return k1 > k2;
}
typedef struct Tree {
int data;
struct Tree* lc;
struct Tree* rc;
}tree;
vector<tree*>nm;
int dfs(tree* tr, int l) {
if (tr == NULL) {
return 0;
}
else if (tr->lc == NULL && tr->rc == NULL) {
return tr->data * l;
}
return dfs(tr->lc, l + 1) + dfs(tr->rc, l + 1);
}
bool cmp1(tree *k1,tree *k2){
return k1->data>k2->data;
}
signed main() {
int n;
cin >> n;
for (int i = 0; i < n; i++) {
cin >> a[i];
}
sort(a, a + n, cmp);
for (int i = 0; i < n; i++) {
tree* T;
T = new tree;
T->data = a[i];
T->lc = NULL;
T->rc = NULL;
nm.push_back(T);
}
while (nm.size() != 1) {
tree* T, * T1, * T2;
T1 = nm.back();
nm.pop_back();
T2 = nm.back();
nm.pop_back();
T = new tree;
T->data = T1->data + T2->data;
T->lc = T1;
T->rc = T2;
nm.push_back(T);
sort(nm.begin(),nm.end(),cmp1);
}
tree* head;
head = nm.back();
cout << dfs(head, 0);
}















 2512
2512











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









