







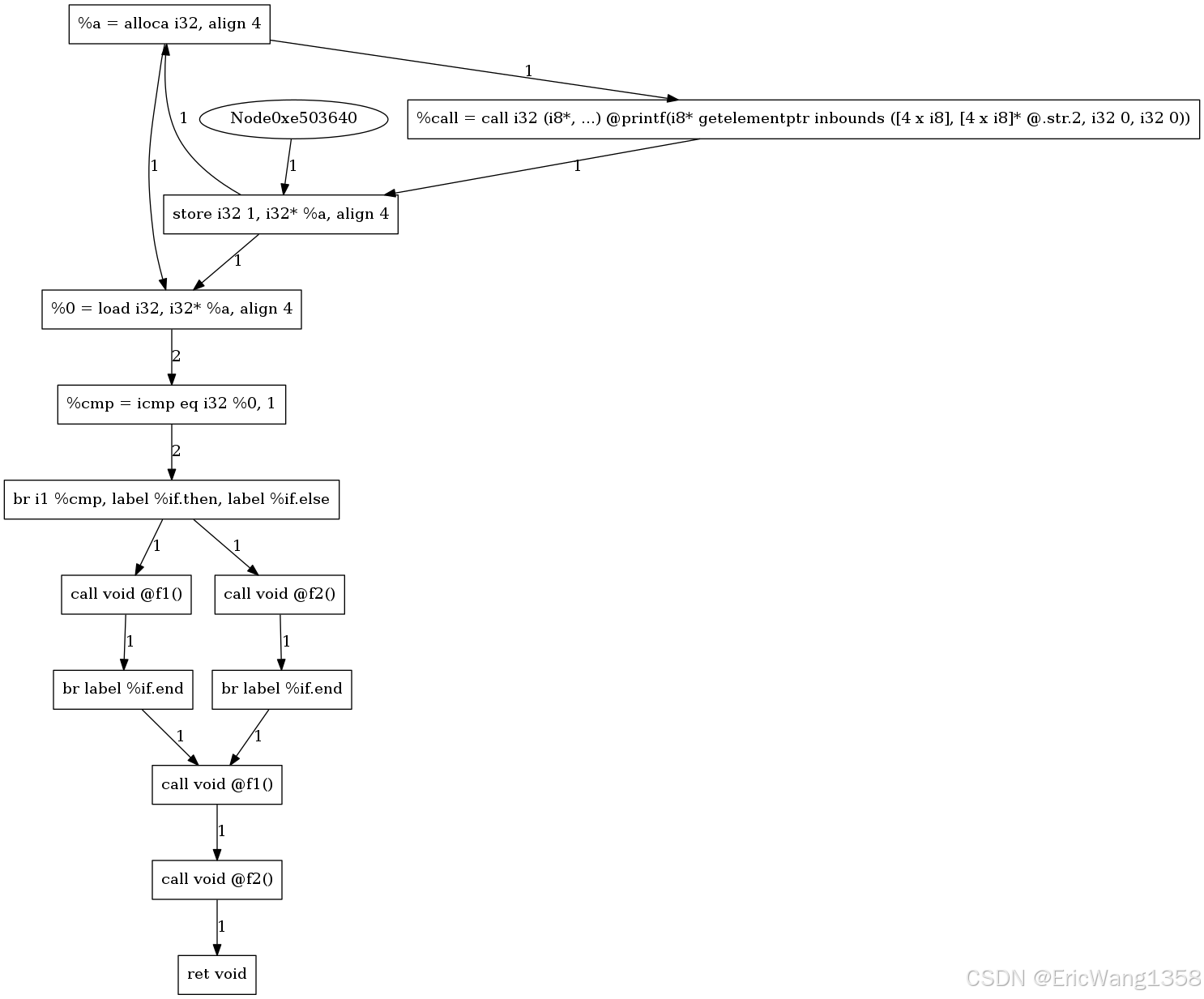
以下是对这个图中不同格式的节点和边的解释,包括它们的含义以及如何解读:
1. 节点 (Nodes)
1.1 矩形节点
-
示例:
%a = alloca i32, align 4- **含义:**为变量
a分配内存 (alloca),类型为i32(32位整数),对齐方式为4字节。 - **说明:**这是
alloca指令的行为,用于在栈上为变量分配空间。 - **解读:**每个函数中的局部变量在运行时会分配一个内存地址,这里表示的是分配操作。
- **含义:**为变量
-
示例:
store i32 1, i32* %a, align 4- **含义:**将值
1存储到变量a的内存地址(%a)中,数据类型为i32,对齐方式为4字节。 - **说明:**这是
store指令,表示写入操作。 - 解读:
store是变量写入操作的重要部分,标识值和目标地址。
- **含义:**将值
-
示例:
%0 = load i32, i32* %a, align 4- **含义:**从变量
a的地址中加载值,存储到临时变量%0中,数据类型为i32,对齐方式为4字节。 - **说明:**这是
load指令,表示读取操作。 - 解读:
load是从变量地址读取数据的操作,临时变量%0是中间值。
- **含义:**从变量
-
示例:
%cmp = icmp eq i32 %0, 1- **含义:**比较
%0和1是否相等 (eq表示 equal),结果存储在%cmp中。 - **说明:**这是
icmp(整数比较)指令,用于条件分支。 - **解读:**表示程序中的条件判断语句,例如
if (%0 == 1)。
- **含义:**比较
-
示例:
br i1 %cmp, label %if.then, label %if.else- **含义:**根据布尔值
%cmp的结果跳转到if.then或if.else基本块。 - **说明:**这是
br(条件分支)指令。 - **解读:**对应于
if语句的条件跳转。
- **含义:**根据布尔值
1.2 椭圆节点
- 示例:
Node0xe503640- **含义:**表示一个匿名或无具体含义的节点。
- **说明:**通常是 LLVM 编译器生成的中间状态,可能没有对应的源代码含义。
- **解读:**这可能是临时节点,用于连接其他节点。
1.3 特殊函数调用节点
- 示例:
call void @f1()或call i32 (i8*, ...) @printf(...)- **含义:**表示函数调用指令。
- 说明:
call指令用于调用其他函数,例如printf或用户定义的f1。 - **解读:**在程序执行中,这是一次函数调用操作。
1.4 终止节点
- 示例:
ret void- **含义:**返回语句,表示函数的结束。
- 说明:
ret指令表示函数的返回值。 - **解读:**程序流的终点。
2. 边 (Edges)
2.1 普通边
- 示例:
Node0 -> Node1- **含义:**表示两条指令之间的控制流或数据流依赖。
- **说明:**普通的边没有特殊的属性,表示节点间的关系。
- **解读:**例如,
alloca和store之间的边表示变量的分配后立即被写入值。
2.2 带权边
- 示例:
NodeA -> NodeB [label="1"]- **含义:**边上有权重标签,表示操作的发生次数或关系的权重。
- **说明:**权重可能由编译器的分析结果生成,例如某条路径的执行频率。
- 解读:
label="1"表示这条边的权重为1,可能表示这条路径执行了一次。
3. 图的整体结构
3.1 基本块(Basic Block)
- **解释:**图中由多条指令组成的矩形序列,可以视为一个基本块。
- **说明:**基本块是没有分支和跳转的指令序列,每个基本块通过
br指令连接到其他基本块。
3.2 函数入口和出口
- **入口:**图的起点是函数的入口,如
%a = alloca i32。 - **出口:**图的终点是函数的返回值,如
ret void。
3.3 循环与条件分支
- **循环:**通过
br指令的回边(循环体与循环条件之间的边)表示。 - **条件分支:**通过
br指令分支到不同的基本块,形成两个出口。
4. 解析方法总结
4.1 逐步解读图
- 找到起点(函数入口),如
%a = alloca i32。 - 按顺序解读图中的节点,记录每条指令的含义。
- 通过边找到指令的执行依赖关系。
4.2 理解特殊符号
%开头:临时变量。@开头:全局变量或函数。alloca:内存分配。load和store:变量的读取和写入。call:函数调用。br:分支跳转。ret:返回语句。
4.3 观察结构模式
- **线性结构:**表示程序的顺序执行。
- **分支结构:**表示
if-else条件。 - **回边:**表示循环。
好的,让我们详细地分析代码和图之间的每一部分对应关系,逐行解释代码中的语句是如何映射到图上的节点和边。通过这种分析,可以帮助你理解图的生成过程和含义。
代码
#include <stdio.h>
void f1() {
printf("f1\n");
}
void f2() {
printf("f2\n");
f1();
}
int main() {
int a = 1;
printf("a = %d\n", a);
if (a == 1) {
f1();
} else {
f2();
}
f1();
f2();
return 0;
}
图分析
我们结合图和代码,一步步说明图的生成过程和各部分对应的关系。
1. 图中的起点
图的第一个节点:
%a = alloca i32, align 4
对应代码:
int a = 1;
说明:
- 这条 IR 指令是 LLVM 在栈上为局部变量
a分配内存的过程。 - 变量
a是类型int(32 位整型),因此分配大小为i32,并要求 4 字节对齐(align 4)。 - 图中,这一节点是程序的起始点,因为变量
a是main函数中的第一个局部变量。
2. 图中的第二部分
图中的节点:
store i32 1, i32* %a, align 4
对应代码:
int a = 1;
说明:
- 这条指令将值
1存储到指针%a所指向的内存中。 - 在图中,它是第二个节点,说明变量
a被初始化为1,并存储到之前分配的内存中。
3. 图中的打印操作
图中的节点:
%call = call i32 (i8*, ...) @printf(i8* getelementptr inbounds ([4 x i8], [4 x i8]* @.str.2, i32 0, i32 0))
对应代码:
printf("a = %d\n", a);
说明:
- 这条指令是
printf的调用,用于输出变量a的值。 - 具体而言:
call表示一次函数调用。getelementptr是计算格式化字符串地址的指令。- 图中,这部分是
printf的相关调用,并和%a的加载和存储节点相连。
4. 图中的条件判断
图中的节点:
%0 = load i32, i32* %a, align 4
%cmp = icmp eq i32 %0, 1
br i1 %cmp, label %if.then, label %if.else
对应代码:
if (a == 1) {
f1();
} else {
f2();
}
说明:
load:从指针%a中加载变量的值,用于后续比较。- 对应代码中的
a,图中表示加载操作。
- 对应代码中的
icmp eq:比较%0是否等于1,表示if条件的判断。- 对应代码中的
a == 1。
- 对应代码中的
br:根据条件跳转到if.then或if.else。- 对应代码中的分支结构。
- 图中的边分为两条:
- **
label %if.then:**对应if的true分支,跳转到调用f1()。 - **
label %if.else:**对应else的分支,跳转到调用f2()。
- **
5. 图中的分支操作
图中的节点:
call void @f1()
call void @f2()
br label %if.end
对应代码:
f1();
f2();
说明:
- **
call void @f1():**调用f1函数,对应if (a == 1)分支。 - **
call void @f2():**调用f2函数,对应else分支。 - **
br label %if.end:**条件分支结束后跳转到后续代码。
6. 图中的后续调用
图中的节点:
call void @f1()
call void @f2()
ret void
对应代码:
f1();
f2();
return 0;
说明:
- **
call void @f1():**再次调用f1。 - **
call void @f2():**再次调用f2。 - **
ret void:**返回void,表示main函数结束。
总结图的结构
-
变量声明:
alloca指令分配栈内存,生成了变量的指针。- 后续对变量的所有操作(
store和load)都通过这个指针完成。
-
数据操作:
store:将值写入内存。load:从内存中读取值。- 每次对变量的操作都会以一个节点的形式出现在图中。
-
条件和分支:
- 条件判断由
icmp和br指令实现,生成多个分支节点。 - 每个分支中的操作对应独立的调用。
- 条件判断由
-
函数调用:
- 所有
printf和用户定义的函数(如f1和f2)都以call指令表示,生成了对应的调用节点。
- 所有
理解复杂性来源
-
为什么图复杂?
- 每一个简单的代码语句都会被分解为多个底层指令,例如变量声明、条件判断和函数调用。
- 这些底层指令以节点和边的形式出现在图中,使图的规模和复杂度显著增加。
- 特别是
alloca、store、load等指令频繁出现,增加了大量的节点和边。
-
如何优化图的直观性?
- 可以合并节点,将相关操作(如
alloca、store和load)简化为单个节点。 - 减少冗余边,只保留关键的控制流和数据流边。
- 增加节点的语义信息,例如显示变量名和地址。
- 可以合并节点,将相关操作(如
改进建议
如果最终目标是通过图直观体现 数据访问序列 和 变量间的依赖关系,建议:
- 通过简化节点的方式,过滤掉中间操作,只保留高层的逻辑(如变量的使用和依赖关系)。
- 在图中加入变量的访问地址信息,以体现访问序列和地址的映射关系。
- 定义明确的图生成规则,例如:
- 每个变量一个节点。
- 每次对变量的操作增加访问顺序编号。
- 使用边权重表示访问频率或依赖关系强度。
通过这些改进,可以使图更加直观、紧凑,也更贴近目标需求。

















 5016
5016

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









