







我的Github实现:gym(GitHub)
如果想要使用模型可以直接去GitHub仓库,注释完善且规范。
觉得有用请给我点个star!
前言
使用最基础的深度强化学习技巧虽然解决了CartPole-v1 的任务:上篇博客,但是DQN的训练实在是太看脸了,每一次训练都只是有概率收敛(我觉得这很大概率是因为我的超参设置的不够好,但我实在不想再花时间调参了:)),所以我决定在解决下一个问题之前,先学习一下更好的算法,看看能不能在超参完全不变的情况下使agent的表现有一个较大的提高。
如标题所见,本篇博客内容是“D2QN算法实现”,实质上从DQN到D2QN的理论创新不难理解,代码改动更是只有两行,所以本篇博客会有一定程度发散。
D2QN简介
原文链接Deep Reinforcement Learning with Double Q-Learning
我们先来回顾一下DQN的目标函数:
J
=
1
N
∑
i
=
0
N
(
r
i
+
γ
m
a
x
a
∈
A
(
s
i
′
)
q
^
(
s
i
′
,
a
,
w
T
)
−
q
^
(
s
i
,
a
i
,
w
)
)
2
J= { \frac{1}{N} \sum_{i=0}^{N} ( r_i+ \gamma \underset{ a\in \mathcal{A} (s^{'}_{i}) }{max} \hat{q}(s^{'}_{i},a,w_T) -\hat{q}(s_i,a_i,w) ) }^2
J=N1i=0∑N(ri+γa∈A(si′)maxq^(si′,a,wT)−q^(si,ai,w))2
D2QN的改动就是一个,那就是把取极大值的操作分割成了两步。
1.根据主网络选择q值最大的动作
2.根据target网络计算该动作的q值
如果我们用目标函数的形式来表达那就是这样的
J
=
1
N
∑
i
=
0
N
(
r
i
+
γ
q
^
(
s
i
′
,
a
r
g
m
a
x
a
∈
A
(
s
i
′
)
q
^
(
s
i
′
,
a
,
w
)
,
w
T
)
−
q
^
(
s
i
,
a
i
,
w
)
)
2
J= { \frac{1}{N} \sum_{i=0}^{N} ( r_i+ \gamma \hat{q}(s^{'}_{i}, \underset{a\in \mathcal{A}(s_i^{'})}{argmax} \hat{q}(s_i^{'},a,w) ,w_T) -\hat{q}(s_i,a_i,w) ) }^2
J=N1i=0∑N(ri+γq^(si′,a∈A(si′)argmaxq^(si′,a,w),wT)−q^(si,ai,w))2
这样的改动其实是为了一个目的,那就是减少因为q值过高估计所导致的误差。
原论文按照:
1.是否存在q值过高估计?
2.q值过高估计导致的误差是否会影响最终的表现?
3.提出一个简单方法解决这种过高估计。
的顺序进行了组织,这里我就用自己的理解来说一说
1.是否存在q值过高估计?
是存在的,用原论文的一张图就可以很好的解释了
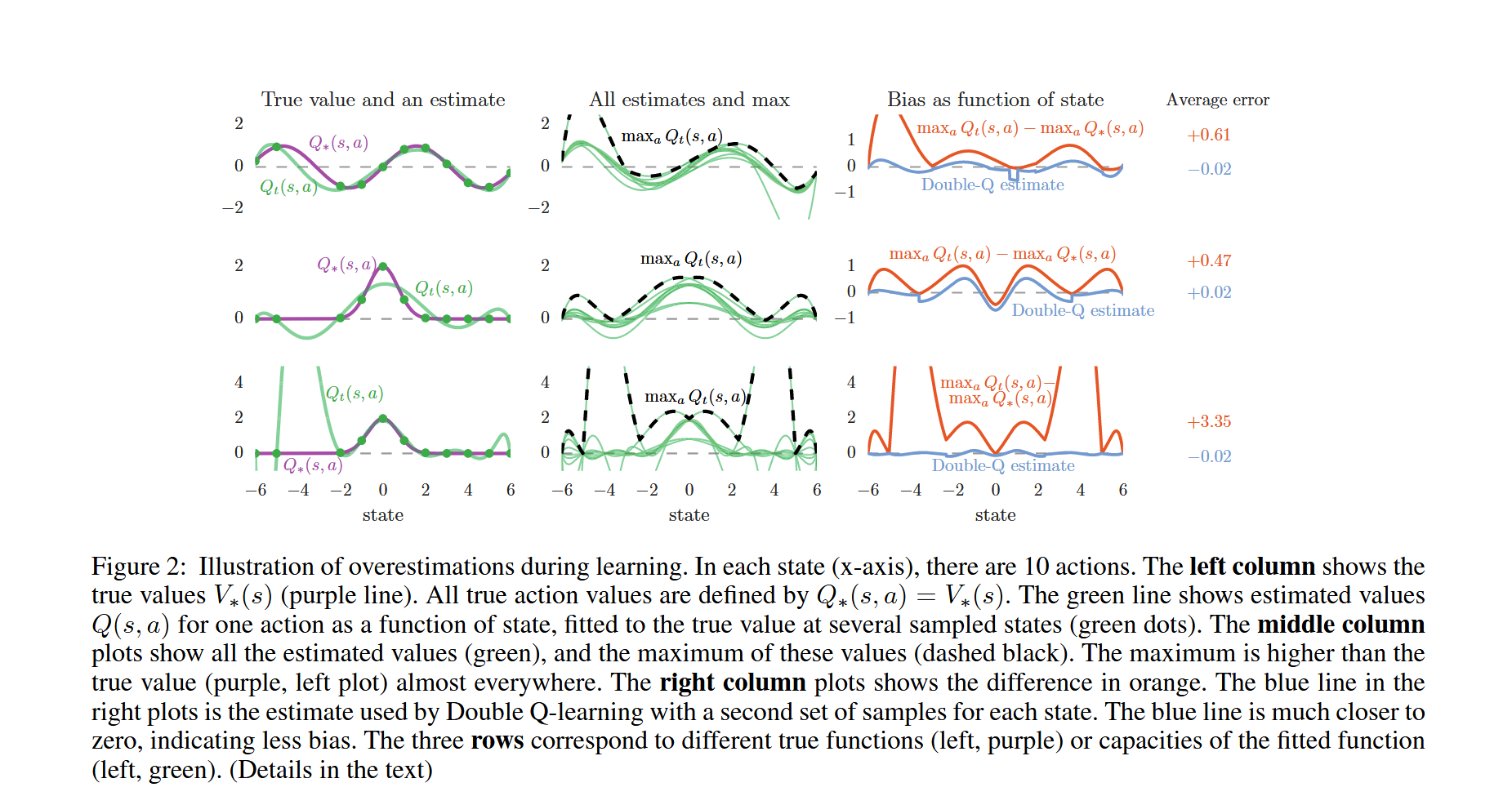
我们先从左列开始看,这里定义横坐标的值代表不同的状态,纵坐标的值代表Q值大小。
左列的紫线代表的是Qstar,也就是理想的Q函数,我们的任务应该就是向Qstar逼近(注意这里假设每个状态的不同动作的Q值都是相同的,所以我们看到的是一条线)。左列的绿线代表的是我们学习到的Q函数(这里特指固定的一个动作在不同的状态下的Q值)。
左列的一个个绿点就是我们的采样点(直观点说就是我们更新函数里的Qtarget,当然Qtarget肯定不等于Qstar,这里做了简化),我们的Q函数就是根据采样点学习的。
而这里的上中下三个图中的绿线都没有完美的吻合紫线,这是很正常的。
因为这本质上就是一个线性回归任务,样本数量不够、神经网络的复杂度不够/太多都会导致error的出现。(这就是机器学习的基础理论了,对于error的成因的拆分,这里推荐一本机器学习的教材,PRML。虽然很老了,但是学习理论方面还是很有用的)
其中第二行的问题是神经网络复杂度不够(这里是多项式秩太小了),第三行的问题是神经网络复杂度太高(这里是多项式的秩太大了)。无论是什么原因,总之就是在某些状态时,该动作的Q值会低于或者高于Qstar。如果是比Qstar低,那么不会有问题。但是如果高于Qstar的话,配合上取最大值(max)的操作就会导致过高的q值估计了。
注意,这里提到的过高的Q值估计并不是指在这个状态下的这个动作的单独的一个/几个Q值过高估计了,而是指整体的Q值(所有状态空间和动作空间的组合)被过高估计了。具体我们接着说
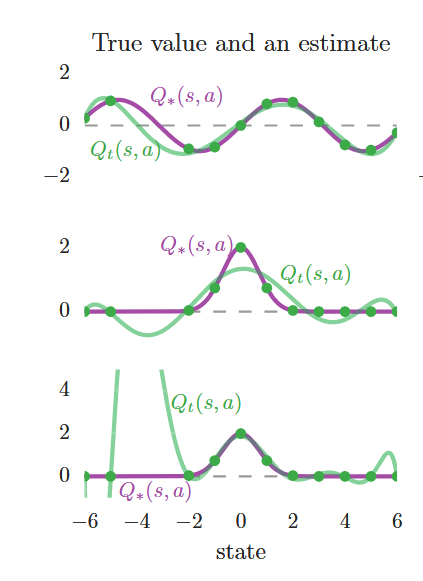
我们再来看第二列也就是中间一列图,这里的绿线的定义和第一列相同,同时每一行的Qstar并没有改变,只是避免太乱省去了。
这里的每个图都有很多的绿线,这是因为每个状态有很多的动作。
而这条黑色虚线是什么呢?
其实它并不是具体的某一种动作在不同状态下的Q值,而是指在每一个状态下取Q值最大的动作的Q值,并把它们连起来,对应的就是我们的函数里的max操作。
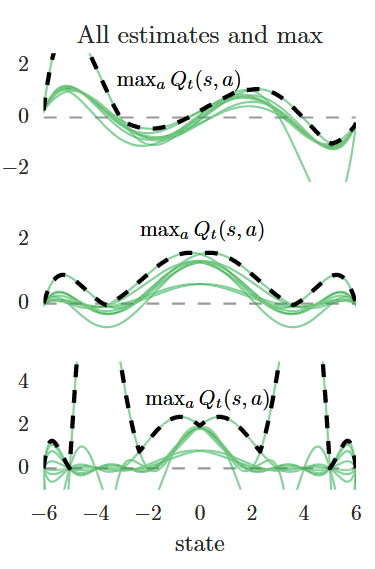
至于第三列图片的橙色线,则是将第二列得到的虚线减去Qstar对应的紫线所得出的误差,可以看到,当我们使用DQN的算法进行迭代的时候,
m
a
x
a
∈
A
(
s
i
′
)
q
^
(
s
i
′
,
a
,
w
T
)
\underset{ a\in \mathcal{A} (s^{'}_{i}) }{max} \hat{q}(s^{'}_{i},a,w_T)
a∈A(si′)maxq^(si′,a,wT)的使用会导致无可避免的过高估计,而这种过高估计会通过神经网络的迭代不断传播,最后导致整体的过高估计。
用一句话来总结的话就是: 不需要每个Q值都是过高估计的,对于一个状态来说,只要最大的Q值是被过高估计了,那么这个状态就会在更新中将这种过高估计传播出去。
当然了,上面的情况已经是很理想了,因为我们实践中的采样点并不是从Qstar中采样而得,反而是从一个不精准的Qtarget采样而得,那么有理由相信,事件中的过高估计会更严重。
有趣的联想
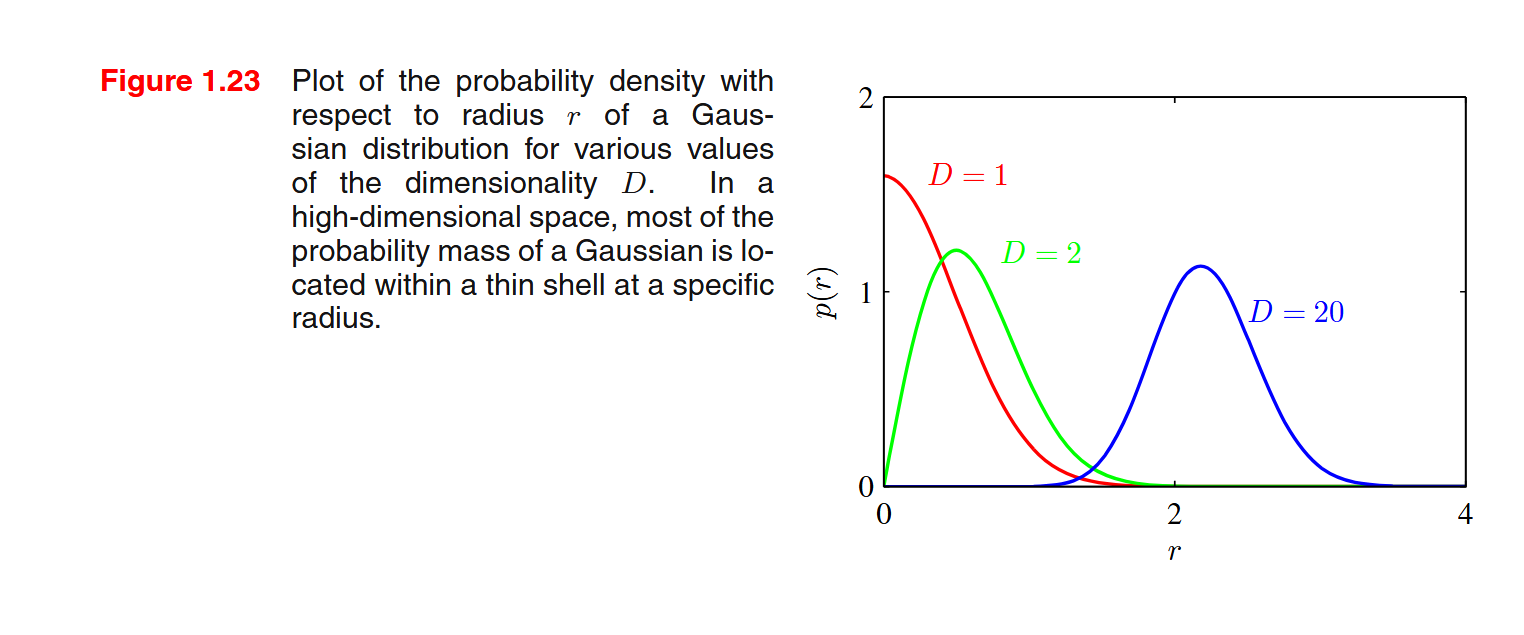
在机器学习中我们学到过,多维高斯分布随着维度的增加大部分的分布质量会集中在特定半径的薄壳中,这里的半径概念其实就是二阶范数。
而取极大值事实上就是无穷阶范数。
那么我们将每个动作看成一个维度,则动作空间越大,这种Q值的过高估计就会越严重
(下图为PRML p37)
2.q值过高估计导致的误差是否会影响最终的表现?
直接上图
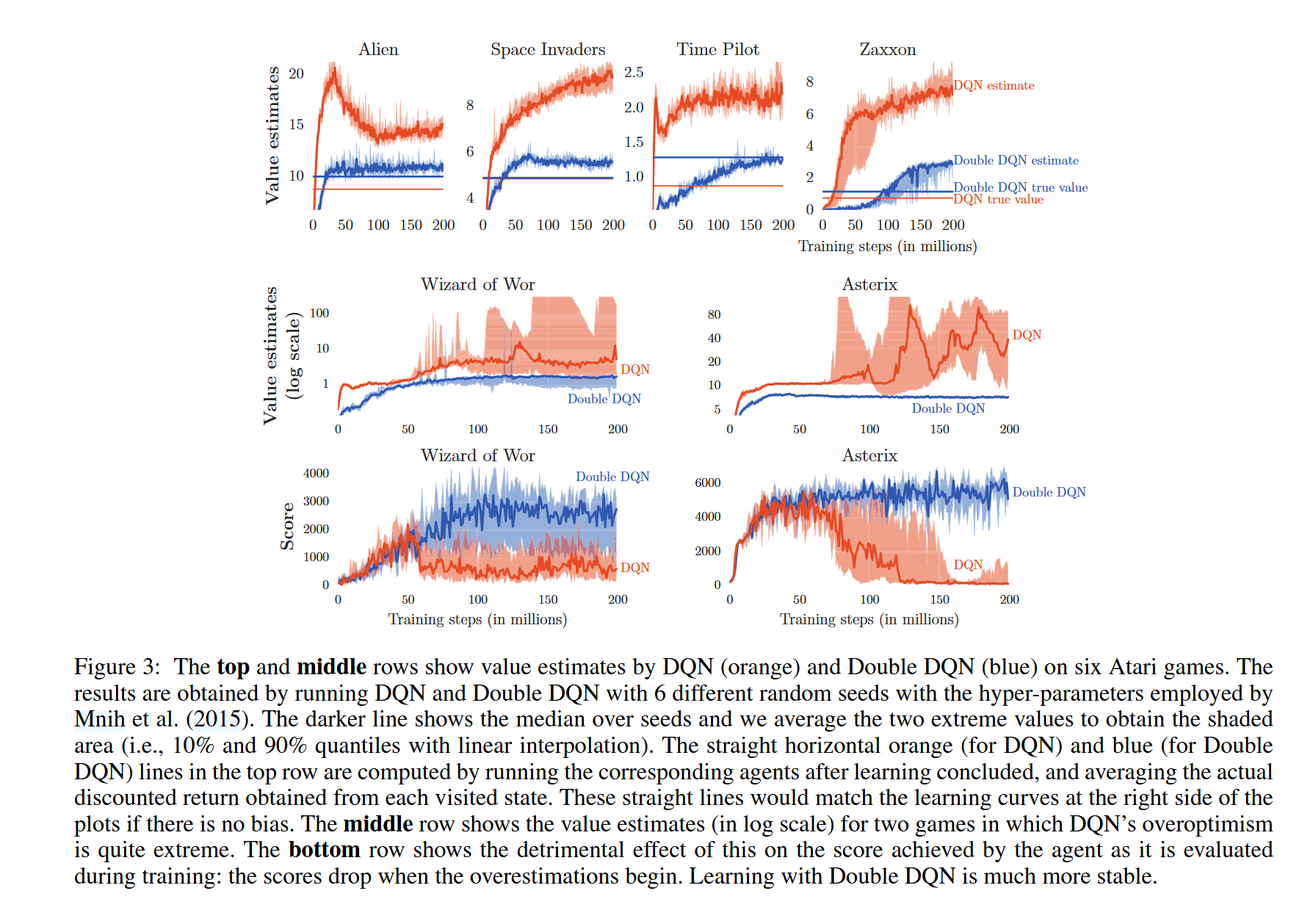
怎么证明q值过高估计导致的误差会影响最终的表现?
实验结果证明
博主之前学习机器学习以及扩散模型的时候都被概率推导整的苦不堪言,这篇论文倒是十分友好,没有那么多的概率论推导。
好了,我们言归正传,看一看这一张实验数据图到底讲了什么。
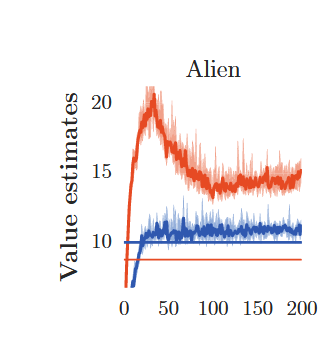
其实我们只需要看这个图就足够了(每个图代表一个雅达利游戏)。
横轴对应的是训练步数(只针对曲线),纵轴对应的是该步所采取行动对应的Q值。
先看两条粗的曲线,橙色代表DQN所对应的Q值变化,蓝色代表D2QN所对应的Q值变化,可以很明显的看到在网络更新的过程中DQN的Q值是远远大于DQN的。
再看两条横线,代表的是:
两种算法的迭代过程中所产生的策略,选取最优的,并利用它生成一次完整的trajectory,这个trajectory的带权重衰减的return。
那么就很明显了,DQN的Q值偏大,反而最终return偏小,这就证明了Q值估计偏大会降低策略表现。
(其实这种表述并不严谨,应该是在策略迭代的过程中,Q值估计偏大会影响到迭代过程,从而导致策略表现降低。毕竟将Qstar加上99999也不会影响表现)
3.提出一个简单方法解决这种过高估计
这里我就简单再说说它的思想,毕竟目标函数已经在开始的时候给出了。
其实作者的想法很简单,就是说将原本由同一个网络做的事情,分开来让两个网络来做。
(D2QN的改动就是一个,那就是把取极大值的操作分割成了两步。
1.根据主网络选择q值最大的动作
2.根据target网络计算该动作的q值)
我们从概率上来讲是说的通的,毕竟主网络认为Q值大,实际上target网络可能认为不是很大,这样就避免了选取到过大的Q值。
但是这里其实我是有点疑问的,这样还能够用OBE来证明收敛到最优吗?
或者说这里要如何重新证明Q会收敛到Qstar。
效果对比
为了亲自验证D2QN的效果,我自己在wandb上跑了一组对比试验(超参未更改),结果显示还是不错的。
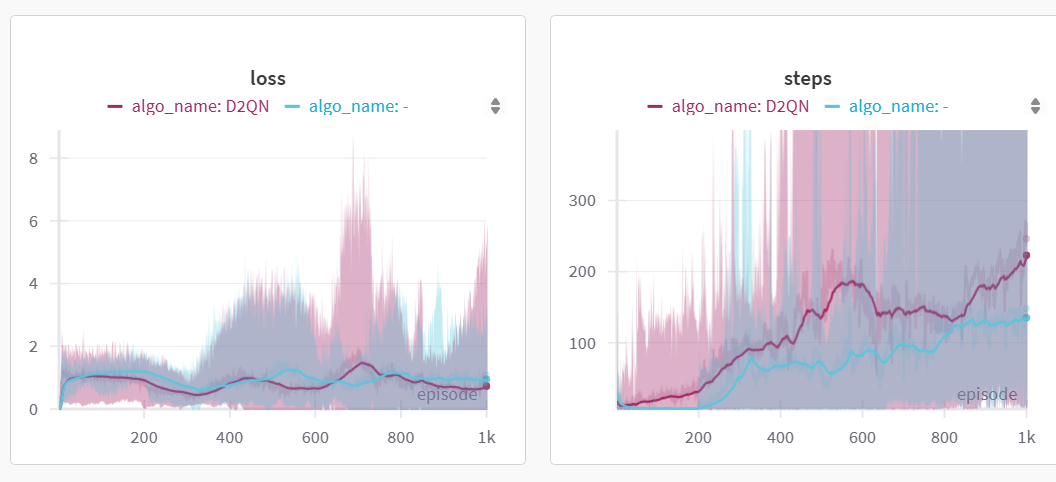
其中紫色曲线代表的是D2QN,蓝色曲线代表的是DQN。
横坐标是episode数,纵坐标左边是loss,右边是steps(在这个任务里其实就是分数)
可以很明显的看到紫色的线整体是优于蓝色的线的。
说开来去
总的来说这篇博客是有点水的,但是我还是想要记录一下这次试验。主要是这几天将日志工具由tensorboard变为了wandb,稍微熟悉了wandb之后感觉这玩意真好用,于是迫不及待的想要用wandb做出一张好看的图来。
上面的两张图片每条曲线其实就是在wandb里集合了10组测试结果而来的。
个人感觉D2QN并没有什么严谨的推理,却从直觉上理解很顺畅,结果也确实显而易见。
这不经让我有了一点疑惑,从概率论工具入手,推导出一些复杂的上界或是下界证明自己方法有效性真的是一个很好的讲故事的口径吗?

















 1747
1747

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









