







一、任务简介
这次任务是钢蹦子为了参加2025全国大学生统计建模大赛准备的。数据来源于阿里天池,有需要的可以自行获取。我们选取了其中一个子任务即疾病诊断作为我们的任务主题。而我们使用到的模型是Bert+BiLSTM。Bert模型的介绍可以参考这篇文章《BERT模型的详细介绍》,LSTM模型的介绍可以参考这篇文章《LSTM模型全面解析》。这篇文章主要追求实战过程即代码实现过程,在文章中一些部分会有部分代码展示方便阅读,最终的完整代码也会放在文章结尾处,感兴趣的朋友可以试着自己实现一下。其中涉及到的一些模型、方法的原理并没有过多叙述。
数据介绍
评测数据基于医院脱敏病历构建,共1500条数据。数据分为训练集、验证集和测试集,数据量分别为800、200和500。本任务仅公开训练集数据和无标签的验证集数据,测试集数据不公开。数据由json格式给出。我们在这个任务中使用到的数据仅为训练集,数据量为800条。
标注数据字段说明:
ID:患者入院的唯一id
性别:男或女
职业:患者的职业信息,如职员、退(离)休人员等
年龄:患者的年龄。
婚姻:描述婚姻状况,如已婚、未婚等
病史陈述者:入院时描述患者身体状况的人员与患者本人的关系,如患者本人
发病节气:患者出现病情时所处于的节气,如清明、小雪等
主诉:患者在就诊时向医生描述的最主要、最直接的不适或症状,用一句简短的文本概括描述,通常是患者就医的主要原因
症状:患者入院时所表现出的主要症状和体征的概述
中医望闻切诊:医师对患者进行“望”、“闻”、“切”后,对患者状态的描述
病史:包括现病史、既往史、个人史、婚育史、家族史
体格检查:患者的体格检查
辅助检查:患者的其他检查项目,如CT、心电图报告等
疾病:患者对应中医的疾病,如心悸病、胸痹心痛病等
证型:患者对应的中医证型,如气虚血瘀证、痰热蕴结证等
处方(不包括剂量):患者中药处方,如黄芪、白芷等
二、文本预处理
文本预处理在自然语言处理任务中扮演着重要角色,它可以将原始的文本数据转换为规范化、结构化和数值化的形式,方便计算机进行处理和分析。同时还可以减少特征空间的维度,提高计算效率,并且有助于模型的泛化能力和准确性。所以我们在进行模型训练之前要对目标文本进行预处理操作。
文本拼接
我们在拿到数据时可以知晓原数据是以多字段的形式存储在json文件中,而我们的自然语言处理任务一次只能对一个字段文本进行分析,所以我们将原数据的各个字段按照顺序进行首尾拼接并保留各个字段名称。
# 读取JSON文件
with open("D:/竞赛/CCL2025-中医辨证辨病及中药处方生成测评/TCM-TBOSD-train.json", 'r', encoding='utf-8') as f:
data = json.load(f)
# 转换为DataFrame
df = pd.DataFrame(data)
df = df.drop(columns=['处方'])
columns = ['性别','职业','年龄','婚姻','病史陈述者','发病节气','主诉','症状','中医望闻切诊','病史','体格检查','辅助检查']
df["text"] = df[columns].apply(
lambda row: ";".join([f"{col}:{val}" for col, val in zip(columns, row)]),
axis=1
)去除噪声数据
在这里我们的噪声数据主要包含一些无关紧要的信息,例如特殊字符、标点符号、HTML标签、常见词等,这些噪声数据会对后续的文本处理和分析造成干扰。所以我们可以使用python中的re库来将特殊字符进行清除,使用NLTK库提供的停用词列表,或者根据具体文本数据自定义停用词列表,然后实现停用词的过滤。在这一步我们还可以考虑保留一些医学领域特殊的字符例如体温符号℃等。
文本增强
对原始数据进行统计发现,各疾病类型的样本分布严重不平衡:原始数据分布分析表明,眩晕病样本量(353例)显著高于其他疾病类型,其中胸痹心痛病、心悸病和心衰病分别包含152例、172例和123例。这种分布差异可能导致模型训练过程中对多数类样本过拟合,同时弱化对少数类别的识别能力。
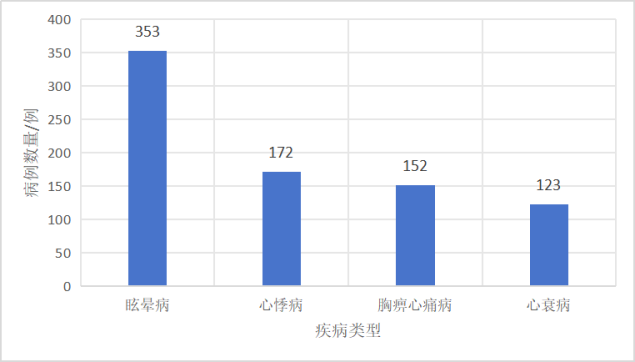
为提升模型泛化性能,本文设计了多模态数据增强策略,通过语义保持的文本变换方法平衡各类别样本量。即在常规的文本清洗和分词处理基础上,进一步引入数据增强(Data Augmentation)策略,以扩充少数类别样本数量并丰富其表达形式。数据增强是通过对原始文本做一系列保持标签不变的变换来生成新的“伪样本”,既能提高训练集规模,又能引入更多语义和结构的多样性,增强模型的鲁棒性。考虑到中医临床文本的专业性,我们在增强过程中既保证医学术语和临床意义的一致性,又尽量模拟真实病例的多样表达。
数据增强过程采用分层处理框架,针对不同疾病类型独立实施增强操作。首先构建基于中医临床术语词典的同义词替换机制,将症状描述中的关键术语替换为语义等价的专业词汇,如将“心慌”替换为“心悸”或“心中悸动”,“胸闷”替换为“胸憋”或“胸脘痞闷”,从而在不改变临床描述实质的前提下生成新的文本变体。该词典涵盖7类常见症状的42组近义词对。其次采用句式重组技术,利用中文标点特性将症状描述拆分为独立子句后随机排列顺序,例如将“活动后加重,偶有头晕”重构为“偶有头晕,活动后加重”。该方法保持症状完整性且符合临床记录特征,改变陈述顺序但不改变整体含义,模拟不同医师或患者的习惯性表述。针对病程时间、年龄等数值字段,设计±1的扰动机制以模拟实际诊疗中的记录误差,如将“病程7年”调整为“6年”或“8年”,同时设置边界约束避免生成负值。通过在±1范围内的小幅度随机扰动,生成轻微差异化的病例描述,以提升模型对数值特征微小变化的敏感度。
增强过程中实施严格的质量控制。原始数据通过深度拷贝保留完整信息,新增样本在ID字段添加“aug_”前缀标识。对于原始样本充足的类别(如胸痹心痛病),采用随机下采样避免过拟合;对样本不足的类别(如心衰病),通过组合增强策略生成新样本。最终构建的均衡数据集包含1,412例样本(原始800例+增强612例),四类疾病样本量均达到353例。数据分布检验显示,KL散度从增强前的0.38降至0.01,表明类别平衡目标有效达成。
import json
import random
import jieba
from random import shuffle
from collections import defaultdict
from copy import deepcopy
# 1. 加载原始数据集
with open("TCM-TBOSD-train.json", "r", encoding="utf-8") as f:
original_data = json.load(f)
# 2. 按疾病类型分类数据
disease_groups = defaultdict(list)
for entry in original_data:
disease_groups[entry["疾病"]].append(entry)
# 打印原始数据分布
print("原始数据分布:")
for disease, cases in disease_groups.items():
print(f"{disease}: {len(cases)}例")
# 3. 定义数据增强方法
# 同义词替换字典(可根据需要扩展)
medical_synonyms = {
"心慌": ["心悸", "心中悸动"],
"胸闷": ["胸憋", "胸脘痞闷"],
"头晕": ["头昏", "眩晕"],
"乏力": ["疲倦", "疲乏"],
"疼痛": ["痛感", "不适"],
"加重": ["加剧", "变重"],
"缓解": ["减轻", "好转"],
}
def synonym_replacement(text):
"""同义词替换增强"""
words = jieba.lcut(text)
new_words = []
for word in words:
if word in medical_synonyms:
new_words.append(random.choice(medical_synonyms[word]))
else:
new_words.append(word)
return "".join(new_words)
def sentence_shuffle(text):
"""句式重组增强"""
clauses = [c.strip() for c in text.split('。') if c.strip()]
if len(clauses) >= 2:
shuffle(clauses)
return '。'.join(clauses) + '。'
def perturb_numbers(text):
"""数值扰动增强"""
def replace_number(match):
num = int(match.group())
return str(num + random.randint(-1, 1))
import re
return re.sub(r'\d+', replace_number, text)
# 4. 数据增强主函数
def augment_data(disease_group, target_count):
"""
将指定疾病类型的数据增强到目标数量
:param disease_group: 该疾病类型的原始数据列表
:param target_count: 目标数量
:return: 增强后的数据列表
"""
original_count = len(disease_group)
if original_count >= target_count:
# 如果原始数据已经足够,则随机采样
return random.sample(disease_group, target_count)
augmented_data = []
# 首先保留所有原始数据
augmented_data.extend(deepcopy(disease_group))
# 计算需要生成的新样本数量
needed = target_count - original_count
# 生成新样本
for _ in range(needed):
# 随机选择一个基础样本
base_sample = deepcopy(random.choice(disease_group))
# 应用多种增强方法
if "主诉" in base_sample:
base_sample["主诉"] = synonym_replacement(base_sample["主诉"])
base_sample["主诉"] = perturb_numbers(base_sample["主诉"])
if "症状" in base_sample:
base_sample["症状"] = sentence_shuffle(base_sample["症状"])
base_sample["症状"] = synonym_replacement(base_sample["症状"])
if "病史" in base_sample:
base_sample["病史"] = perturb_numbers(base_sample["病史"])
# 修改ID以标识这是增强样本
base_sample["ID"] = f"aug_{base_sample['ID']}_{random.randint(1000,9999)}"
augmented_data.append(base_sample)
return augmented_data
# 5. 执行数据增强
target_diseases = ["心悸病", "胸痹心痛病", "心衰病"]
reference_disease = "眩晕病"
target_count = len(disease_groups[reference_disease])
print(f"\n目标数量: {target_count}例(与{reference_disease}相同)")
augmented_dataset = []
# 增强目标疾病类型
for disease in target_diseases:
augmented = augment_data(disease_groups[disease], target_count)
augmented_dataset.extend(augmented)
print(f"{disease} 增强后: {len(augmented)}例")
# 添加原始眩晕病数据
augmented_dataset.extend(disease_groups[reference_disease])
# 6. 保存增强后的数据集
output_file = "TCM-TBOSD-augmented.json"
with open(output_file, "w", encoding="utf-8") as f:
json.dump(augmented_dataset, f, ensure_ascii=False, indent=2)
print(f"\n增强完成! 数据已保存到 {output_file}")
# 7. 验证最终分布
final_distribution = defaultdict(int)
for case in augmented_dataset:
final_distribution[case["疾病"]] += 1
print("\n增强后数据分布:")
for disease, count in final_distribution.items():
print(f"{disease}: {count}例")(注意我们在后续模型训练时采用的数据集应是经过增强后的而不是原始数据。)
三、模型构建
在本节中我们将详细介绍Bert+LSTM模型的构建和代码实现。
模型组件
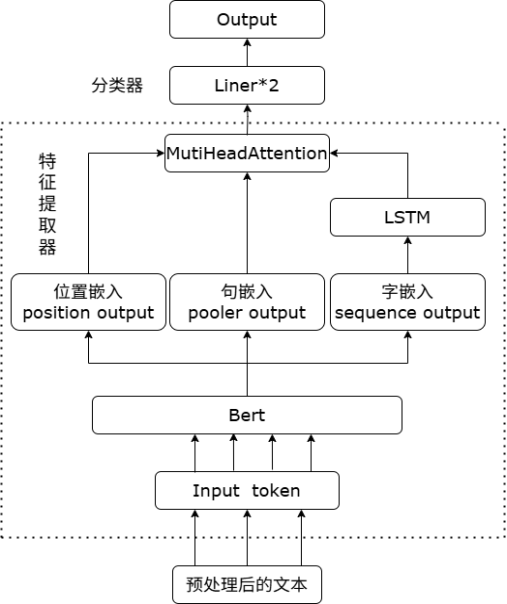
Bert特征提取层。在此层前我们先将目标文本进行预处理后,再进行词向量嵌入,然后输入Bert特征提取层。Bert特征提取层的核心在于通过双向Transformer编码器实现动态、层次化的上下文建模,结合预训练任务编码丰富的语言知识。其关键特征包括多头注意力机制、位置感知编码和层次化特征抽象,使其在NLP任务中展现出强大的泛化能力和适应性。这种设计不仅解决了传统词嵌入的静态性问题,还为下游任务提供了统一的特征表示框架。在训练模型时我们并未显示的调整Bert预训练模型参数,而是默认在训练时通过模型自身微调整个模型的参数。最终通过该层将输入词向量转换成了位置嵌入向量、句嵌入向量、字嵌入向量三部分,输出形状为[batch_size, sequence_length, 768]。
双向LSTM时序建模层。双向LSTM时序建模层的核心作用在于通过双向信息流的协同建模,实现对序列数据中复杂时序依赖关系的全局感知与动态解析。我们调用python中torch库的LSTM网络,并且对其进行自定义设置,通过num_layers=2将两层LSTM网络进行堆叠、通过bidirectional=True构建双向LSTM层、通过dropout=0.3设置层间随机失活权数且仅当LSTM层数大于1运行。双向隐藏状态拼接后的输出序列大小 [batch_size, seq_len, 512](256每个方向×2)。
多头注意力层。Attention起源于对人脑注意力特征的模拟,该方法首先应用于图像处理领域。在深度学习领域,Attention机制根据不同的特征分配权重的大小,对关键的内容分配更大的权重,对其他内容分配较小的权重,通过差异化的权重分配可提高信息处理的效率。将经过LSTM处理后的sequence output与position output和pooler output通过多头注意力层进行序列合并,合并后的序列融合了位置信息和文本信息,且对序列进行了维度压缩,最后输出序列大小为[batch_size, 512]。
分类决策层。我们的分类决策层由一个池化层和一个线性层组成。池化概率为0.5的池化层核心作用如下:
1.正则化与防止过拟合。通过随机屏蔽50%的神经元(训练阶段),迫使网络学习冗余特征表示,避免模型对特定神经元过度依赖,从而提升泛化能力。此过程通过缩放保留神经元的激活值以保持训练和推理阶段的期望一致性。
2.提升鲁棒性。在训练中引入随机性,模拟多模型集成的效果(类似随机森林的Bagging思想),增强模型对输入噪声和特征缺失的适应性。
3.优化权重分布。通过动态调整神经元激活状态,间接优化全连接层的权重参数,避免权重过度集中于少数特征。
线性层nn.Linear(512, num_labels)的核心作用如下:
1.特征空间映射。将高维特征(512维)压缩到标签空间(num_labels维),通过线性变换完成分类决策。权重矩阵W和偏置b是模型学习的关键参数,直接影响分类边界。
2.分类置信度输出。输出的num_labels维向量通常对应各标签的未归一化得分(logits),后续通过Softmax等函数转化为概率分布,支持多分类任务。
3.信息瓶颈控制。从512维到标签数的维度压缩迫使网络提取与分类目标强相关的特征,过滤冗余信息,形成决策关键路径。
模型设计原理
Bert结构虽然在特征提取能力上更有优势,但对文本序列中的单词顺序不敏感。双向长短期记忆模型(BiLSTM)天然地具有适应序列建模的特性。因此,本文提出了一种新的字符级中医药文本处理框架,该框架具有更强的特征提取器,称为 Bert-BiLSTM,它结合了优越的BERT 模型和可以处理可变长度序列数据的BiLSTM模型。
| 模块 | 核心优势 | 功能补充 |
| Bert | 基于Transformer的并行化上下文编码,擅长提取细粒度语义(如词义消歧、语法结构) | 提供全局语义理解能力,捕捉文本中跨位置的复杂依赖关系(如长距离指代、句间逻辑) |
| LSTM | 对序列方向敏感,通过门控机制显式建模局部时序依赖(如递进式情感变化) | 补充Bert在时序动态性和局部模式捕捉上的不足,增强对序列中渐进、转折等方向敏感特征的建模能力 |
模型结构代码:
class BertLSTMModel(nn.Module):
def __init__(self, bert_model_name, num_labels, lstm_hidden_size=256, lstm_layers=2):
super().__init__()
# 加载预训练BERT(不要最后的分类层)
self.bert = BertModel.from_pretrained(bert_model_name)
self.bert_config = self.bert.config
# LSTM层(双向)
self.lstm = nn.LSTM(
input_size=self.bert_config.hidden_size,
hidden_size=lstm_hidden_size,
num_layers=lstm_layers,
bidirectional=True,
batch_first=True,
dropout=0.3 if lstm_layers > 1 else 0
)
# 分类层
self.classifier = nn.Sequential(
nn.Dropout(0.5),
nn.Linear(lstm_hidden_size * 2, num_labels) # 双向需要*2
)
def forward(self, input_ids, attention_mask, labels=None):
# BERT编码
outputs = self.bert(
input_ids=input_ids,
attention_mask=attention_mask,
return_dict=True
)
sequence_output = outputs.last_hidden_state # [batch_size, seq_len, hidden_size]
# LSTM处理
lstm_out, _ = self.lstm(sequence_output) # [batch, seq_len, lstm_hidden*2]
# 取最后一个时间步的输出
last_hidden = lstm_out[:, -1, :] # [batch, lstm_hidden*2]
# 分类
logits = self.classifier(last_hidden)
# 计算损失
loss = None
if labels is not None:
loss_fct = nn.CrossEntropyLoss()
loss = loss_fct(logits.view(-1, self.classifier[-1].out_features),
labels.view(-1))
return {'loss': loss, 'logits': logits}四、实验设置
数据集划分
针对数据样本规模有限的特点,本研究采用训练集-验证集的划分策略以避免过度分割数据。在具体实现过程中,我们借助sklearn.model_selection模块的train_test_split函数,将原始数据集按照8:2的比例进行划分,其中80%的样本用于模型训练,20%的样本作为验证集。为确保实验的可重复性,特别设定随机状态参数random_state=42,通过固定随机种子保证每次实验的数据划分一致性。在完成数据拆分后,我们进一步将两个子集分别封装为torch.utils.data.Dataset对象,既保持了数据与标签的对应关系,又适配了PyTorch框架的批量数据加载机制,为后续模型训练与验证建立了规范化的数据接口。
超参数设置
本实验采用如下超参数配置,涵盖模型架构、训练策略及评估方法:
1.在模型架构方面,使用预训练语言模型,基于huggingface预训练的Bert模型“google-Bert/Bert-base-chinese”,其继承自Bert-base架构,输出维度为768;对于LSTM层,使用双向LSTM结构,隐层维度为384,堆叠层数为2,Dropout率为0.3,且仅当层数大于1时启用;对于分类层,全连接层输入维度为768,即双向输出拼接,Dropout率为0.5,输出维度为4
2. 训练策略方面,使用优化器AdamW优化器,并分层设置学习率,即沿用迁移学习的惯例将Bert的参数学习率设置为2e-5,以避免破坏预训练特征,LSTM及分类层学习率则设置为1e-4;训练配置如下,批量大小为16,训练轮次为20,最大序列长度为512;损失函数使用交叉熵损失
3. 数据划分与评估方面,将训练集与验证集按照比例8:2对数据集进行划分,随机种子设置为42;最佳模型保存依据选择验证集F1分数,且因任务为多分类且需均衡各类别表现,指标的计算方式为宏平均
4. 计算资源方面,受限于实验环境配置,训练设备使用CPU;分词器使用Bert配套中文分词器,即与预训练模型一致
五、模型效果
在模型训练过程中,我们设置了20个训练周期(epoch),并实时监控训练集和验证集的损失变化。由于我自己的设备限制,我设置的训练epoch比较少,有条件的同学可以适当加大训练轮数看看效果会不会还有提升,有提升的欢迎评论讨论。
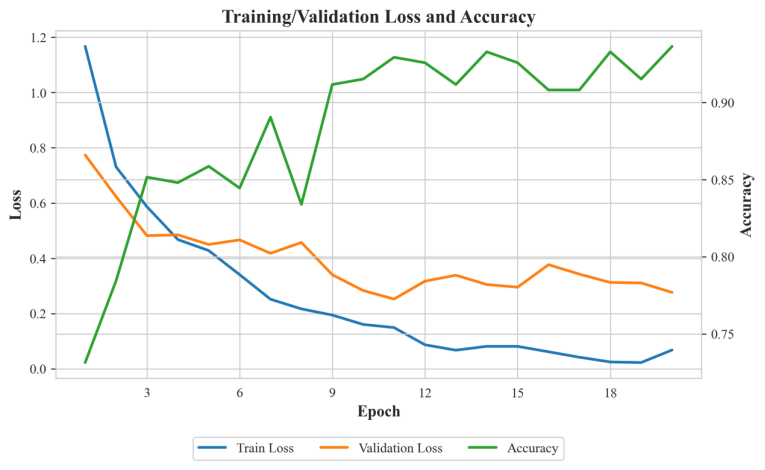
下图展示了模型训练过程中的训练损失、测试损失和准确率变化曲线。可以看到,训练损失在前5个epoch快速下降,测试损失同步降低且保持稳定,最终收敛至0.12,表明模型具有良好的收敛性和泛化能力。训练完成后,我们在测试集上对模型性能进行了评估,可以看到准确率变化曲线图随着损失的降低逐渐增高,且在第20个epoch达到峰值0.9364。
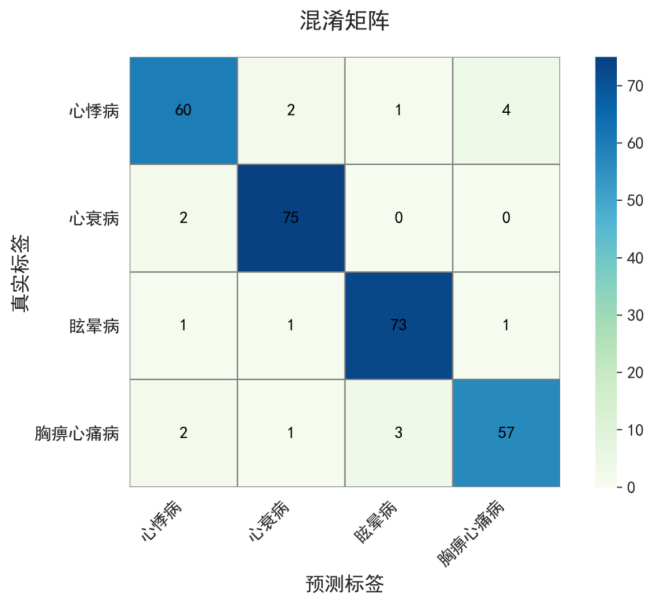
为了进一步分析模型对不同疾病的分类效果,我们统计了四类疾病的详细性能指标,如下表和在最优分类效果下各类疾病的混淆矩阵显示,可以看出模型各个类别都具有较好的识别能力。
| 疾病类型 | Accuracy | F1 | Precision | Recall |
| 眩晕病 | 0.9605 | 0.9542 | 0.9481 | 0.9605 |
| 胸痹心痛病 | 0.9048 | 0.9120 | 0.9194 | 0.9048 |
| 心悸病 | 0.8955 | 0.9091 | 0.9231 | 0.8955 |
| 心衰病 | 0.9740 | 0.9615 | 0.9494 | 0.9740 |
六、结论
本次任务通过对比不同模型架构在中医文本分类任务中的性能,验证关键模块的有效性。实验选取了Bert、LSTM、Bert-CNN来进行对比和消融,(这里我们只需要将上面模型构建模块的代码将不同模型进行替换就可以实现对比实验了,所以我们后面的完整代码就只展示主模型)实验结果如下表所示:
| 模型 | Accuracy | Precision | Recall | F1-Score |
| Bert | 0.8125 | 0.7676 | 0.7700 | 0.7571 |
| LSTM | 0.6813 | 0.4203 | 0.4500 | 0.3624 |
| Bert-CNN | 0.9125 | 0.8590 | 0.8535 | 0.8486 |
| Bert-LSTM | 0.9364 | 0.9350 | 0.9337 | 0.9342 |
改进点:
1.我觉得在超参数设置那可以新增一个对比实验,就是不同超参数下的模型效果。
2.在模型构建那可以将Bert的预训练模型换成更加符合中医领域或者医学领域的预训练模型,这样效果可能会更好。
3.可以多尝试一些新的模型看看效果,毕竟本文体现出的模型数量很少,说服力并不大。
完整代码
大家注意好文件路径就行,还有就是导入模型训练的数据要是经过增强后的,所以我建议数据增强那一操作单独做就好,然后输出一个新的数据,大家导入那个新的数据路径即可。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import json
import torch
import torch.nn as nn
from torch.utils.data import Dataset, DataLoader
from transformers import BertTokenizer, BertModel, AdamW # 修改1:使用基础BERT模型
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder
from sklearn.metrics import accuracy_score
from sklearn.metrics import classification_report, confusion_matrix, precision_score, recall_score, f1_score
import re
"""
一、文本拼接
"""
# 读取JSON文件
with open("D:/竞赛/CCL2025-中医辨证辨病及中药处方生成测评/TCM-TBOSD-train.json", 'r', encoding='utf-8') as f:
data = json.load(f)
# 转换为DataFrame
df = pd.DataFrame(data)
df = df.drop(columns=['处方'])
columns = ['性别','职业','年龄','婚姻','病史陈述者','发病节气','主诉','症状','中医望闻切诊','病史','体格检查','辅助检查']
df["text"] = df[columns].apply(
lambda row: ";".join([f"{col}:{val}" for col, val in zip(columns, row)]),
axis=1
)
print(df["疾病"].value_counts())
"""
二、数据预处理函数
"""
def preprocess_data(df):
# 清洗特殊字符
df["text"] = df["text"].apply(lambda x: re.sub(r'\s+', ' ', x))
# 单标签编码器
le = LabelEncoder()
# 转换标签为数字编码
encoded_labels = le.fit_transform(df["疾病"])
return df["text"].tolist(), encoded_labels, le
"""
三、构架Datasets
"""
class MedicalDataset(Dataset):
def __init__(self, texts, labels, tokenizer, max_len):
self.texts = texts
self.labels = labels
self.tokenizer = tokenizer
self.max_len = max_len
def __len__(self):
return len(self.texts)
def __getitem__(self, idx):
text = str(self.texts[idx])
label = self.labels[idx]
encoding = self.tokenizer.encode_plus(
text,
add_special_tokens=True,
max_length=self.max_len,
padding="max_length",
truncation=True,
return_attention_mask=True,
return_tensors="pt",
)
return {
"input_ids": encoding["input_ids"].flatten(),
"attention_mask": encoding["attention_mask"].flatten(),
"labels": torch.LongTensor([label])
}
"""
四、模型架构
"""
class BertLSTMModel(nn.Module):
def __init__(self, bert_model_name, num_labels, lstm_hidden_size=256, lstm_layers=2):
super().__init__()
# 加载预训练BERT(不要最后的分类层)
self.bert = BertModel.from_pretrained(bert_model_name)
self.bert_config = self.bert.config
# LSTM层(双向)
self.lstm = nn.LSTM(
input_size=self.bert_config.hidden_size,
hidden_size=lstm_hidden_size,
num_layers=lstm_layers,
bidirectional=True,
batch_first=True,
dropout=0.3 if lstm_layers > 1 else 0
)
# 分类层
self.classifier = nn.Sequential(
nn.Dropout(0.5),
nn.Linear(lstm_hidden_size * 2, num_labels) # 双向需要*2
)
def forward(self, input_ids, attention_mask, labels=None):
# BERT编码
outputs = self.bert(
input_ids=input_ids,
attention_mask=attention_mask,
return_dict=True
)
sequence_output = outputs.last_hidden_state # [batch_size, seq_len, hidden_size]
# LSTM处理
lstm_out, _ = self.lstm(sequence_output) # [batch, seq_len, lstm_hidden*2]
# 取最后一个时间步的输出
last_hidden = lstm_out[:, -1, :] # [batch, lstm_hidden*2]
# 分类
logits = self.classifier(last_hidden)
# 计算损失
loss = None
if labels is not None:
loss_fct = nn.CrossEntropyLoss()
loss = loss_fct(logits.view(-1, self.classifier[-1].out_features),
labels.view(-1))
return {'loss': loss, 'logits': logits}
"""
五、训练函数
"""
def train_model(model, train_loader, val_loader, le, epochs=5):
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = model.to(device)
optimizer = AdamW([
{'params': model.bert.parameters(), 'lr': 2e-5}, # BERT层较小学习率
{'params': model.lstm.parameters(), 'lr': 1e-4},
{'params': model.classifier.parameters(), 'lr': 1e-4}
])
train_losses = []
val_losses = []
val_accuracies = []
best_f1 = 0
for epoch in range(epochs):
model.train()
total_loss = 0
for batch in train_loader:
optimizer.zero_grad()
input_ids = batch["input_ids"].to(device)
attention_mask = batch["attention_mask"].to(device)
labels = batch["labels"].to(device)
outputs = model(input_ids, attention_mask, labels)
loss = outputs['loss']
total_loss += loss.item()
loss.backward()
optimizer.step()
# 计算并存储平均训练损失
avg_train_loss = total_loss / len(train_loader)
train_losses.append(avg_train_loss)
# 验证阶段
val_metrics = evaluate(model, val_loader, device, le)
val_losses.append(val_metrics['loss'])
val_accuracies.append(val_metrics['accuracy'])
print(f"\nEpoch {epoch + 1}/{epochs}")
print(f"Train Loss: {total_loss / len(train_loader):.4f}")
print(f"Val Loss: {val_metrics['loss']:.4f}")
print(f"Accuracy: {val_metrics['accuracy']:.4f}")
print(f"Precision: {val_metrics['precision']:.4f}")
print(f"Recall: {val_metrics['recall']:.4f}")
print(f"F1-Score: {val_metrics['f1']:.4f}")
print("\nClassification Report:")
print(val_metrics['classification_report'])
print("\nConfusion Matrix:")
print(pd.DataFrame(val_metrics['confusion_matrix'],
index=le.classes_,
columns=le.classes_))
# 保存最佳模型(用F1判断)
if val_metrics['f1'] > best_f1:
torch.save(model.state_dict(), "D:/APP/Jupyter/统计建模大赛/best_model.bin")
best_f1 = val_metrics['f1']
#可视化模块
plt.figure(figsize=(12, 6))
# 创建双轴
fig, ax1 = plt.subplots()
ax1.set_xlabel('Epoch')
ax1.set_ylabel('Loss', color='tab:blue')
ax1.plot(train_losses, label='Train Loss', marker='o', color='tab:blue')
ax1.plot(val_losses, label='Val Loss', marker='o', color='tab:orange')
ax1.tick_params(axis='y', labelcolor='tab:blue')
ax2 = ax1.twinx()
ax2.set_ylabel('Accuracy', color='tab:green')
ax2.plot(val_accuracies, label='Val Accuracy', marker='o', color='tab:green')
ax2.tick_params(axis='y', labelcolor='tab:green')
# 合并图例
lines1, labels1 = ax1.get_legend_handles_labels()
lines2, labels2 = ax2.get_legend_handles_labels()
ax1.legend(lines1 + lines2, labels1 + labels2, loc='upper center', bbox_to_anchor=(0.5, -0.15), ncol=3)
plt.title('Training Progress Metrics')
plt.grid(True)
plt.tight_layout()
plt.show()
return model
"""
六、评价函数
"""
def evaluate(model, data_loader, device, le):
model.eval()
total_loss = 0
predictions = []
true_labels = []
with torch.no_grad():
for batch in data_loader:
input_ids = batch["input_ids"].to(device)
attention_mask = batch["attention_mask"].to(device)
labels = batch["labels"].to(device)
outputs = model(
input_ids=input_ids,
attention_mask=attention_mask,
labels=labels
)
loss = outputs['loss']
total_loss += loss.item()
logits = outputs['logits']
preds = torch.argmax(logits, dim=1).cpu().numpy() # 取最大值索引
predictions.extend(preds)
true_labels.extend(labels.cpu().numpy())
# 计算各项指标(直接比较类别索引)
acc = accuracy_score(true_labels, predictions)
precision = precision_score(true_labels, predictions, average='macro') # 宏平均
recall = recall_score(true_labels, predictions, average='macro')
f1 = f1_score(true_labels, predictions, average='macro')
# 生成分类报告矩阵
class_report = classification_report(
true_labels,
predictions,
target_names=le.classes_, # 使用标签编码器的类别名称
digits=4
)
# 生成混淆矩阵(数值矩阵)
conf_matrix = confusion_matrix(true_labels, predictions)
return {
'loss': total_loss / len(data_loader),
'accuracy': acc,
'precision': precision,
'recall': recall,
'f1': f1,
'classification_report': class_report,
'confusion_matrix': conf_matrix
}
"""
七、预测函数
"""
def predict(text, model, tokenizer, le, max_len):
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
model.eval()
encoding = tokenizer.encode_plus(
text,
add_special_tokens=True,
max_length=max_len,
padding="max_length",
truncation=True,
return_tensors="pt",
)
with torch.no_grad():
input_ids = encoding["input_ids"].to(device)
attention_mask = encoding["attention_mask"].to(device)
outputs = model(input_ids=input_ids, attention_mask=attention_mask)
logits = outputs['logits']
probs = torch.softmax(logits, dim=1).cpu().numpy() # 使用softmax
predicted_label = le.inverse_transform([np.argmax(probs)])
print(f"预测疾病: {predicted_label[0]}")
"""
八、主函数
"""
def main():
# 加载数据
texts, labels, le = preprocess_data(df)
# 划分数据集
train_texts, val_texts, train_labels, val_labels = train_test_split(
texts, labels, test_size=0.2, random_state=42
)
# 初始化tokenizer
tokenizer = BertTokenizer.from_pretrained("google-bert/bert-base-chinese")
max_len = 512 # 文本长度
# 创建数据集
train_dataset = MedicalDataset(train_texts, train_labels, tokenizer, max_len)
val_dataset = MedicalDataset(val_texts, val_labels, tokenizer, max_len)
# 创建DataLoader
batch_size = 16
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
val_loader = DataLoader(val_dataset, batch_size=batch_size)
# 初始化模型
model = BertLSTMModel(
bert_model_name="google-bert/bert-base-chinese",
num_labels=len(le.classes_),
lstm_hidden_size=384, # 可调整
lstm_layers=2
)
# 训练
trained_model = train_model(model, train_loader, val_loader, le, epochs=5)
# 测试预测
test_text = "性别: 女; 职业: 退休; 年龄: 82岁; 婚姻: 丧偶; 病史陈述者: 患者及家属; 发病节气: 小雪; 主诉: 主 诉:阵发性头晕2年余,加重1月余。; 症状: 阵发性头晕,伴心慌,无头痛头胀,无胸闷胸痛,体力可,偶有反酸,心情焦虑,纳可,睡前一片安定,二便调。; 中医望闻切诊: 中医望闻切诊:表情自然,面色少华,形体正常,动静姿态,语气清,气息平;无异常气味,舌红,苔少,有裂纹,舌下络脉无异常,脉弦细。; 病史: 现病史,患者于2年前无明显诱因出现阵发性头晕,诊为高血压病,最高血压可达200/100mmHg,曾服用罗布麻控制血压,现服用伲福达,平素血压可控制在130/80mmHg,患者于1月前无明显诱因血压升高,血压波动较大,口服伲福达不能缓解,现为求进一步中西医结合专科诊疗,入住我病区,入院症见,既往史,既往腰椎间盘突出病史20余年,骨质疏松病史1年余,双眼青光眼病史6年余,否认糖尿病等慢性疾病病史,否认肝炎、否认结核等传染病史,预防接种史不详,曾于2014年,2018年分别行左右眼青光眼小梁切除术,否认重大外伤史,否认输血史,自述有B族维生素过敏史、否认其他接触物过敏史,个人史,久居本地,无疫水、疫源接触史,无嗜酒史,无吸烟史,无放射线物质接触史,否认麻醉毒品等嗜好,否认冶游史,自述有B族维生素过敏史,否认传染病史,婚育史,适龄婚育,育有1子1女,月经史,既往月经规律正常,现已绝经,家族史,否认家族性遗传病史。; 体格检查: 生命体征体温:36.6℃ 脉搏:71次/分 呼吸:18次/分 血压:185/90mmHg VTE评分:1分 卒中风险评估:中危一般情况:患者,老年女性,发育正常,营养良好,神志清楚,查体合作,皮肤黏膜:全身皮肤及粘膜无黄染,未见皮下出血,淋巴结浅表淋巴结未及肿大。标题定位符头颅五官无畸形,眼睑无水肿,巩膜无黄染,双侧结膜充血,双侧瞳孔欠圆,对光反射灵敏,外耳道无异常分泌物,鼻外观无畸形,口唇红润,伸舌居中,双侧扁桃体正常,表面未见脓性分泌物,标题定位符颈软,无抵抗感,双侧颈静脉正常,气管居中,甲状腺未及肿大,未闻及血管杂音。标题定位符胸廓正常,双肺呼吸音清晰,未闻及干、湿罗音,未闻及胸膜摩擦音。心脏心界不大,心率71次/分,心律齐整,心音有力,各瓣膜听诊区未闻及杂音,未闻及心包摩擦音。脉搏规整,无水冲脉、枪击音、毛细血管搏动征。腹部腹部平坦,无腹壁静脉显露,无胃肠型和蠕动波,腹部柔软,无压痛、反跳痛,肝脏未触及,脾脏未触及,未触及腹部包块,麦氏点无压痛及反跳痛,Murphy's征-,肾脏未触及,肝浊音界正常,肝肾区无明显肾区叩击痛,肝脾区无明显叩击痛,腹部叩诊鼓音,移动性浊音-,肠鸣音正常,无过水声,直肠肛门、生殖器肛门及外生殖器未查,神经系统:脊柱生理弯曲存在,四肢无畸形、无杵状指、趾,双下肢无水肿。生理反射存在,病理反射未引出。; 辅助检查: 2020-12-01 新型冠状病毒核酸检测示:阴性;2020-12-02 心电图示:完全右束支传导阻滞。"
predict(test_text, trained_model, tokenizer, le, max_len)
if __name__ == "__main__":
main()

















 392
392

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











