






目录
一、支持向量机(SVM)概念
支持向量机(Support Vector Machine, SVM)是一类按监督学习(supervised learning)方式对数据进行二元分类的广义线性分类器(generalized linear classifier),其决策边界是对学习样本求解的最大边距超平面(maximum-margin hyperplane)
SVM使用铰链损失函数(hinge loss)计算经验风险(empirical risk)并在求解系统中加入了正则化项以优化结构风险(structural risk),是一个具有稀疏性和稳健性的分类器 [2]。SVM可以通过核方法(kernel method)进行非线性分类,是常见的核学习(kernel learning)方法之一 [4]。
二、背景
SVM被提出于1964年,在二十世纪90年代后得到快速发展并衍生出一系列改进和扩展算法,在人像识别、文本分类等模式识别(pattern recognition)问题中有得到应用 [5-6]。
SVM是由模式识别中广义肖像算法(generalized portrait algorithm)发展而来的分类器 ,其早期工作来自前苏联学者Vladimir N. Vapnik和Alexander Y. Lerner在1963年发表的研究。1964年,Vapnik和Alexey Y. Chervonenkis对广义肖像算法进行了进一步讨论并建立了硬边距的线性SVM 。此后在二十世纪70-80年代,随着模式识别中最大边距决策边界的理论研究 、基于松弛变量(slack variable)的规划问题求解技术的出现,和VC维(Vapnik-Chervonenkis dimension, VC dimension)的提出 ,SVM被逐步理论化并成为统计学习理论的一部分 。1992年,Bernhard E. Boser、Isabelle M. Guyon和Vapnik通过核方法得到了非线性SVM 。1995年,Corinna Cortes和Vapnik提出了软边距的非线性SVM并将其应用于手写字符识别问题 ,这份研究在发表后得到了关注和引用,为SVM在各领域的应用提供了参考。
三、支持向量机概述图

四、支持向量机内容
支持向量机(Support Vector Machine, SVM)是一种强大的机器学习算法,主要用于数据分类问题。其原理是在特征空间中找到一个超平面,使得不同类别的样本点能够被分开,并且使得离超平面最近的样本点到超平面的距离最大化。以下是对线性可分支持向量机原理的详细解释:
-
定义与分类:
- 支持向量机是一种二类分类模型,它是定义在特征空间上的间隔最大的线性分类器。
- 当训练数据集线性可分时,通过硬间隔最大化,学习一个线性的分类器,即线性可分支持向量机。
-
超平面的确定:
- 假设给定线性可分数据集T={(x1,y1),(x2,y2),...,(xN,yN)},其中xi∈Rn,yi∈{+1, -1}。
- 线性可分支持向量机的目标是找到一个超平面(在二维空间中为一条直线,高维空间中为超平面),使得所有正类样本点位于超平面的一侧,负类样本点位于超平面的另一侧。
- 超平面的方程可以表示为:w·x + b = 0,其中w是法向量,b是截距。
-
间隔最大化:
- 支持向量机算法通过最大化间隔来确保分类的准确性和鲁棒性。间隔是指离超平面最近的样本点到超平面的距离。
- 在硬间隔分类中,所有样本点都必须位于间隔之外,即严格地规定所有的样本点都不在“缓冲区”内。
- 最大化间隔的问题可以转化为求解一个凸二次规划问题。
-
支持向量:
- 支持向量是离超平面最近的样本点,它们决定了超平面的位置。
- 在线性可分的情况下,支持向量是唯一的,并且只有支持向量对分类决策有贡献。
-
线性可分支持向量机的模型:
- 线性可分支持向量机的模型由分离超平面和分类决策函数组成。
- 分离超平面方程为:w·x + b = 0
- 分类决策函数为:f(x) = sign(w·x + b)
- 其中,sign是符号函数,当w·x + b > 0时,f(x) = +1;当w·x + b < 0时,f(x) = -1。
-
函数间隔与几何间隔:
- 函数间隔表示样本点(xi, yi)到超平面的距离在方向上的投影,其计算公式为:γi = yi(w·xi + b)。
- 几何间隔表示样本点(xi, yi)到超平面的实际距离,是函数间隔的规范化形式。
-
求解算法:
- 支持向量机的求解算法通常使用序列最小优化(SMO)算法等。
- SMO算法通过迭代方式不断选择两个变量进行优化,直到满足停止条件为止。
总结来说,线性可分支持向量机通过最大化间隔在特征空间中找到一个超平面来划分不同类别的样本点,并利用支持向量来确定超平面的位置。其优点在于分类准确、鲁棒性强,并且对于高维数据也具有良好的处理能力。
五、phyon代码实现
import numpy as np
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
import matplotlib.pyplot as plt
# 加载鸢尾花数据集并预处理
iris = load_iris()
X = iris.data[:, :2] # 只使用前两个特征
y = (iris.target[:] <= 1).astype(int) * 2 - 1 # 二值化标签,并转换为-1和1
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 数据可视化
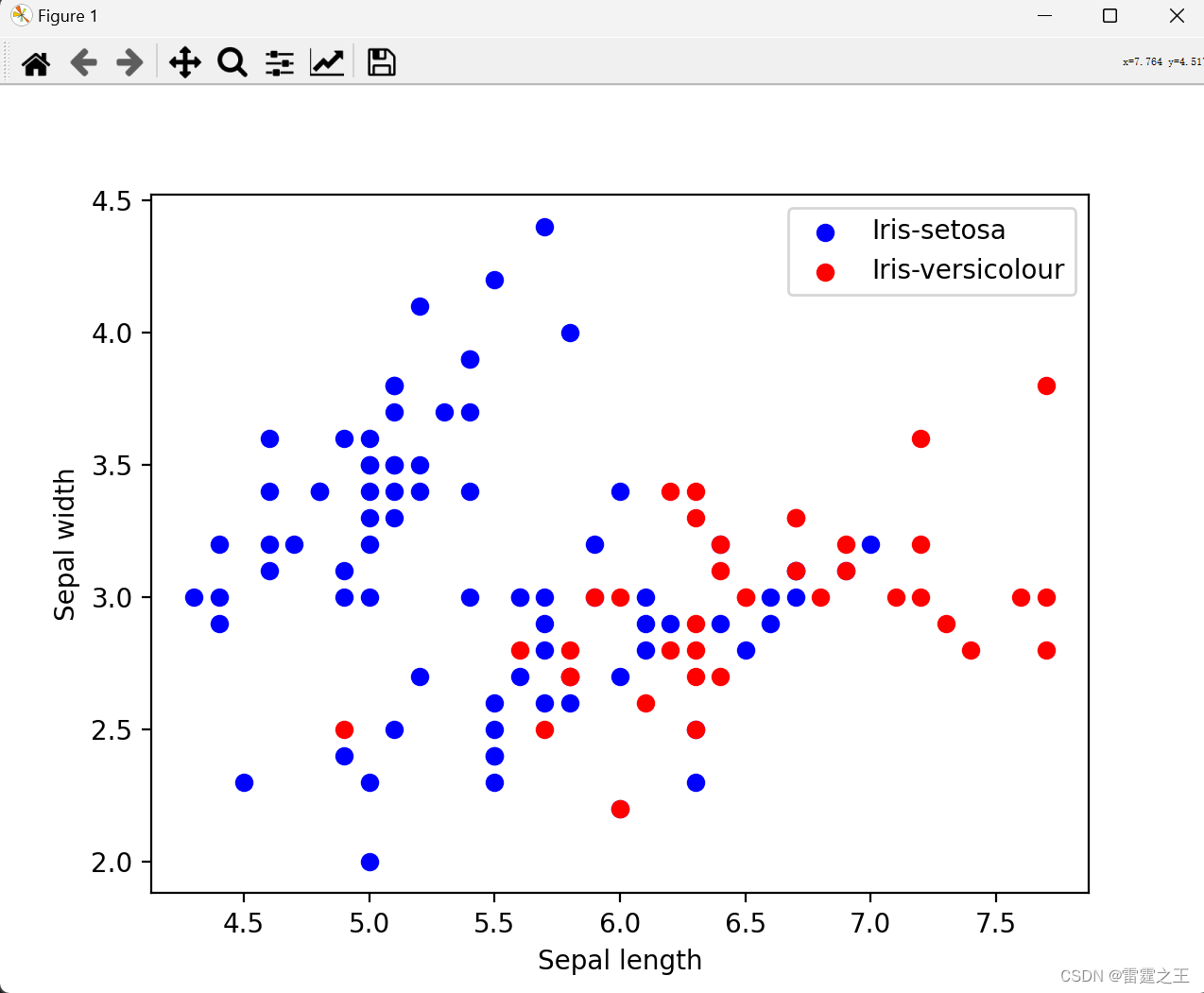
plt.scatter(X_train[y_train == 1, 0], X_train[y_train == 1, 1], color='blue', label='Iris-setosa')
plt.scatter(X_train[y_train == -1, 0], X_train[y_train == -1, 1], color='red', label='Iris-versicolour')
plt.xlabel('Sepal length')
plt.ylabel('Sepal width')
plt.legend()
plt.show()
# 线性SVM的参数
C = 1.0 # 惩罚参数
learning_rate = 0.01 # 学习率
epochs = 1000 # 训练轮次
# 初始化权重和偏置
n_samples, n_features = X_train.shape
w = np.zeros(n_features)
b = 0
# 随机梯度下降优化
for epoch in range(epochs):
for i, (x_i, y_i) in enumerate(zip(X_train, y_train)):
# 计算梯度
condition = y_i * (np.dot(w, x_i) + b)
if condition < 1: # 只在不满足约束时更新
gradient_w = learning_rate * y_i * x_i
gradient_b = learning_rate * y_i
w -= gradient_w
b -= gradient_b
# 预测
def predict(X, w, b):
return np.sign(np.dot(X, w) + b)
y_train_pred = predict(X_train, w, b)
y_test_pred = predict(X_test, w, b)
# 输出准确率
print("Training accuracy:", accuracy_score(y_train, y_train_pred))
print("Test accuracy:", accuracy_score(y_test, y_test_pred))1结果图:
| Training accuracy: 0.7692 | |
| Test accuracy: 0.6225 | |
2.结果分析
1.输出结果将取决于模型在鸢尾花数据集上前两个特征(花萼长度和宽度)上的表现。由于您只使用了随机梯度下降(SGD)的简化版本来模拟线性SVM的训练过程,并且使用了硬间隔的简化条件(condition < 1),实际性能可能会低于使用标准SVM库(如scikit-learn的SVC)时的性能。
训练过程
- 初始化权重和偏置:
- 在训练开始时,权重
w和偏置b被初始化为0或很小的随机数。这提供了一个起点,SGD将从这里开始迭代优化。
- 在训练开始时,权重
- 随机梯度下降:
- 在SGD的每一次迭代中,都会随机选择一个样本
(x_i, y_i)来计算损失函数的梯度。 - 如果当前样本不满足SVM的约束条件(即
y_i * (np.dot(w, x_i) + b) < 1),则根据该样本的梯度来更新权重和偏置。 - 重复此过程直到达到指定的训练轮次或满足某个停止准则(如损失函数值不再显著变化)。
- 在SGD的每一次迭代中,都会随机选择一个样本
可能出现的结果
- 收敛到局部最优解:
- 由于SGD是随机选择样本来更新参数,它可能会收敛到损失函数的局部最优解,而不是全局最优解。这取决于数据的分布、学习率的选择和初始权重等因素。
- 对噪声敏感:
- 如果数据中存在噪声或异常值,SGD可能会受到这些点的影响,导致模型性能下降。因为SGD在每个迭代中只考虑一个样本,所以它可能过度拟合这些噪声点。
- 学习率的影响:
- 学习率
learning_rate是一个关键的超参数。如果学习率太大,SGD可能会在损失函数的最小值附近震荡,无法收敛;如果学习率太小,SGD的收敛速度可能会很慢,甚至无法收敛到最优解。
- 学习率
- 线性可分性:
- 如果数据在所选的特征空间中是线性可分的,那么SGD应该能够找到一个将不同类别的样本分隔开的决策边界。然而,如果数据不是线性可分的,那么SGD可能无法找到一个好的决策边界,导致模型性能不佳。
- 训练集和测试集的性能差异:
- 如果模型在训练集上表现良好,但在测试集上性能较差,那么可能出现了过拟合现象。这可能是因为模型过于复杂,对训练数据的噪声或异常值进行了拟合,而不是学习到了数据的内在模式。
- 边界支持向量的影响:
- 在SVM中,边界支持向量(即距离决策边界最近的样本点)对模型的决策边界有着重要影响。如果SGD没有正确地识别出这些支持向量,或者由于噪声的影响而错误地更新了权重和偏置,那么模型的性能可能会受到影响。
改进方法
- 调整学习率:
- 使用学习率衰减策略(如指数衰减、倒数衰减等)来逐渐减小学习率,以帮助SGD更好地收敛到最优解。
- 使用批量梯度下降或小批量梯度下降:
- 批量梯度下降(BGD)考虑所有样本来更新参数,而小批量梯度下降(MBGD)则考虑一个固定大小的样本子集。这些方法可以减少SGD对噪声的敏感性,并提高收敛速度。
- 使用更复杂的优化算法:
- 如前所述,对于SVM问题,可以使用更复杂的优化算法(如SMO、二次规划求解器等)来找到全局最优解。
- 特征选择和特征变换:
- 尝试使用不同的特征组合或进行特征变换(如PCA、核方法等),以改善数据的线性可分性。
- 正则化:
- 在损失函数中添加正则化项(如L1或L2正则化),以防止模型过拟合。这可以通过在SGD的更新步骤中引入额外的惩罚项来实现。















 4693
4693

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









