










1. 背景介绍
1.1 多模态数据的兴起与挑战
近年来,随着互联网和移动设备的普及,多模态数据(如文本、图像、视频、音频等)呈爆炸式增长。如何有效地处理和理解这些多模态数据成为了人工智能领域的一个重要挑战。传统的单模态模型(如自然语言处理模型或计算机视觉模型)在处理多模态数据时往往会遇到瓶颈,难以充分利用不同模态之间的互补信息。
1.2 多模态大模型的优势
多模态大模型(Multimodal Large Language Models, MLLMs)的出现为解决这一挑战带来了新的希望。MLLMs能够融合不同模态的信息,学习更全面、更准确的表示,从而在各种多模态任务中取得更好的效果。相比于传统的单模态模型,MLLMs具有以下优势:
- 更强的表达能力: MLLMs能够学习到更丰富的语义表示,更好地理解多模态数据中的复杂关系。
- 更广泛的应用范围: MLLMs可以应用于各种多模态任务,例如图像描述生成、视频摘要、跨模态检索等。
- 更高的效率: MLLMs可以一次性处理多种模态的数据,避免了多次训练和推理的成本。
1.3 基于人工反馈的强化学习
为了进一步提升MLLMs的性能,研究者们引入了基于人工反馈的强化学习(Reinforcement Learning from Human Feedback, RLHF)技术。RLHF通过将人类的反馈融入到模型的训练过程中,使得MLLMs能够更好地理解人类的意图,生成更符合人类期望的结果。
2. 核心概念与联系
2.1 多模态表示学习
多模态表示学习旨在将不同模态的数据映射到一个共同的语义空间,以便于进行跨模态的比较和推理。常见的 多模态表示学习方法包括:
- 联合嵌入(Joint Embedding): 将不同模态的数据映射到同一个向量空间,使得不同模态的特征能够相互比较。
- 跨模态注意力机制(Cross-modal Attention): 利用注意力机制捕捉不同模态之间的语义关联,从而学习更有效的表示。
- 图神经网络(Graph Neural Networks): 将不同模态的数据表示为图结构,利用图神经网络学习节点之间的关系,从而获得更全面的表示。
2.2 强化学习
强化学习是一种机器学习方法,其目标是通过与环境的交互来学习最优策略。在RLHF中,MLLMs被视为一个智能体,它通过接收来自人类的反馈来学习如何生成更符合人类期望的输出。
2.3 人工反馈
人工反馈是指由人类提供的关于MLLMs输出质量的评价。人工反馈可以是显式的(例如,对模型输出进行评分),也可以是隐式的(例如,用户点击或停留时间)。
3. 核心算法原理具体操作步骤
3.1 数据准备
- 收集多模态数据集,包括文本、图像、视频、音频等。
- 对数据进行预处理,例如文本清洗、图像缩放、音频降噪等。
- 将数据划分为训练集、验证集和测试集。
3.2 模型训练
- 选择合适的MLLM架构,例如CLIP、ALIGN、Florence等。
- 使用训练集对MLLM进行预训练,学习多模态数据的联合表示。
- 使用验证集对模型进行评估,并进行超参数调整。
3.3 强化学习训练
- 收集人工反馈,例如对模型输出进行评分或排序。
- 将人工反馈转化为奖励信号,用于指导强化学习过程。
- 使用强化学习算法(例如,PPO、SAC)对MLLM进行微调,使其能够生成更符合人类期望的输出。
3.4 模型评估
- 使用测试集对模型进行评估,例如计算BLEU分数、ROUGE分数等指标。
- 进行人工评估,例如让用户对模型输出进行评分或排序。
4. 数学模型和公式详细讲解举例说明
4.1 联合嵌入
联合嵌入的目标是将不同模态的数据映射到同一个向量空间。一种常见的联合嵌入方法是使用双编码器架构。
双编码器架构
双编码器架构包含两个编码器:一个用于文本编码,另一个用于图像编码。两个编码器将输入数据映射到同一个向量空间,然后计算两个向量之间的相似度。
公式:
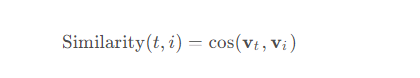

举例:
假设我们希望训练一个MLLM来生成图像描述。我们可以使用人工反馈来评估模型生成的描述质量,并将其转化为奖励信号。然后,我们可以使用强化学习算法(例如,PPO、SAC)来优化模型参数,使其能够生成更符合人类期望的描述。
5. 项目实践:代码实例和详细解释说明
5.1 CLIP模型
CLIP (Contrastive Language-Image Pre-training) 是一种多模态模型,它可以学习文本和图像之间的联合表示。
代码示例:
import clip
# 加载 CLIP 模型
model, preprocess = clip.load("ViT-B/32", device="cuda")
# 加载图像
image = preprocess(Image.open("cat.jpg")).unsqueeze(0).to("cuda")
# 加载文本
text = clip.tokenize(["一只猫坐在沙发上"]).to("cuda")
# 计算图像和文本之间的相似度
with torch.no_grad():
image_features = model.encode_image(image)
text_features = model.encode_text(text)
logits_per_image, logits_per_text = model(image, text)
probs = logits_per_image.softmax(dim=-1).cpu().numpy()
# 打印相似度得分
print("相似度得分:", probs)
解释说明:
- 首先,我们使用
clip.load()函数加载 CLIP 模型。 - 然后,我们使用
preprocess()函数对图像进行预处理。 - 接下来,我们使用
clip.tokenize()函数对文本进行编码。 - 最后,我们使用
model()函数计算图像和文本之间的相似度得分。
5.2 ALIGN模型
ALIGN (A Large-scale ImaGe and Noisy-text embedding) 是一种多模态模型,它可以学习大规模图像和噪声文本之间的联合表示。
代码示例:
import align
# 加载 ALIGN 模型
model = align.load("base")
# 加载图像
image = model.preprocess_image(Image.open("cat.jpg"))
# 加载文本
text = "一只猫坐在沙发上"
# 计算图像和文本之间的相似度
similarity = model.similarity(image, text)
# 打印相似度得分
print("相似度得分:", similarity)
解释说明:
- 首先,我们使用
align.load()函数加载 ALIGN 模型。 - 然后,我们使用
model.preprocess_image()函数对图像进行预处理。 - 接下来,我们直接使用文本字符串作为输入。
- 最后,我们使用
model.similarity()函数计算图像和文本之间的相似度得分。
6. 实际应用场景
6.1 图像描述生成
MLLMs可以用于生成图像的文本描述。例如,给定一张猫坐在沙发上的图片,MLLM可以生成描述 “一只猫坐在沙发上”。
6.2 视频摘要
MLLMs可以用于生成视频的摘要。例如,给定一段关于猫的视频,MLLM可以生成摘要 “这只猫很可爱,它喜欢玩玩具”。
6.3 跨模态检索
MLLMs可以用于跨模态检索。例如,给定一个文本查询 “猫”,MLLM可以检索包含猫的图片或视频。
7. 工具和资源推荐
7.1 Hugging Face Transformers
Hugging Face Transformers 是一个用于自然语言处理的 Python 库,它提供了各种预训练的语言模型,包括多模态模型。
7.2 TensorFlow Hub
TensorFlow Hub 是一个用于发布、发现和重用机器学习模型的平台,它提供了各种预训练的多模态模型。
7.3 PyTorch Lightning
PyTorch Lightning 是一个用于简化 PyTorch 代码的 Python 库,它可以用于训练和评估多模态模型。
8. 总结:未来发展趋势与挑战
8.1 未来发展趋势
- 更大规模的模型: 随着计算能力的提升,MLLMs的规模将会越来越大,从而学习到更丰富的语义表示。
- 更精细的模态融合: 研究者们将会探索更精细的模态融合方法,以更好地利用不同模态之间的互补信息。
- 更广泛的应用场景: MLLMs将会应用于更广泛的领域,例如医疗、金融、教育等。
8.2 挑战
- 数据偏差: 多模态数据集往往存在偏差,例如种族、性别、文化等方面的偏差。
- 可解释性: MLLMs的可解释性较差,难以理解模型的决策过程。
- 伦理问题: MLLMs可能会被用于生成虚假信息或进行其他恶意活动。
9. 附录:常见问题与解答
9.1 什么是多模态大模型?
多模态大模型 (MLLMs) 是一种能够处理和理解多种模态数据 (如文本、图像、视频、音频等) 的人工智能模型。
9.2 什么是基于人工反馈的强化学习?
基于人工反馈的强化学习 (RLHF) 是一种将人类反馈融入到模型训练过程中的技术,旨在提升模型的性能,使其能够生成更符合人类期望的结果。
9.3 多模态大模型有哪些应用场景?
多模态大模型可以应用于各种领域,例如图像描述生成、视频摘要、跨模态检索等。
如何学习大模型
现在社会上大模型越来越普及了,已经有很多人都想往这里面扎,但是却找不到适合的方法去学习。
作为一名资深码农,初入大模型时也吃了很多亏,踩了无数坑。现在我想把我的经验和知识分享给你们,帮助你们学习AI大模型,能够解决你们学习中的困难。
我已将重要的AI大模型资料包括市面上AI大模型各大白皮书、AGI大模型系统学习路线、AI大模型视频教程、实战学习,等录播视频免费分享出来,需要的小伙伴可以扫取。
一、AGI大模型系统学习路线
很多人学习大模型的时候没有方向,东学一点西学一点,像只无头苍蝇乱撞,我下面分享的这个学习路线希望能够帮助到你们学习AI大模型。

二、AI大模型视频教程

三、AI大模型各大学习书籍

四、AI大模型各大场景实战案例

五、结束语
学习AI大模型是当前科技发展的趋势,它不仅能够为我们提供更多的机会和挑战,还能够让我们更好地理解和应用人工智能技术。通过学习AI大模型,我们可以深入了解深度学习、神经网络等核心概念,并将其应用于自然语言处理、计算机视觉、语音识别等领域。同时,掌握AI大模型还能够为我们的职业发展增添竞争力,成为未来技术领域的领导者。
再者,学习AI大模型也能为我们自己创造更多的价值,提供更多的岗位以及副业创收,让自己的生活更上一层楼。
因此,学习AI大模型是一项有前景且值得投入的时间和精力的重要选择。
作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。
朋友们如果有需要全套《AGI大模型学习资源包》,可以扫描下方二维码免费领取
需要的朋友 点击下方👇👇👇【微信名片】,100%免费领取

















 1609
1609

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









