







目录
一、爬取第一章
1.引入requests 和 parsel库
import requests
import parsel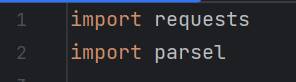
如果requests 和 parsel报错,单击requests再按Alt+Enter,Install package requests。
单击parsel再按Alt+Enter,Install package parsel。
依然报错可以使用pip命令安装requests和parsel模块
pip install requests
pip install parsel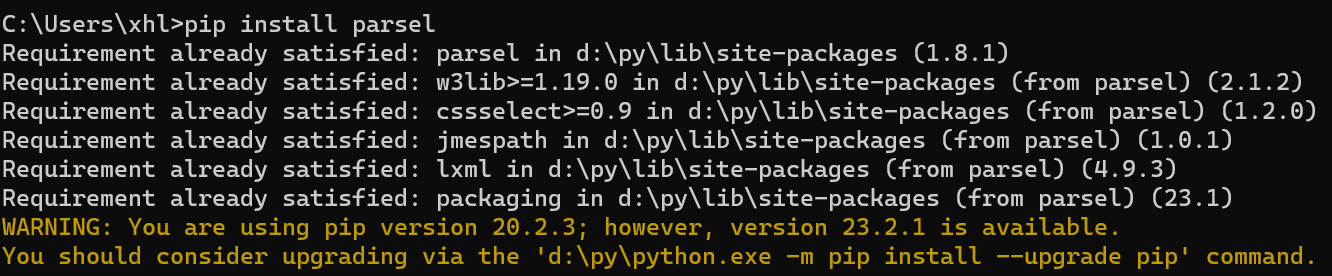
可以查看Python中安装了哪些第三方库
pip list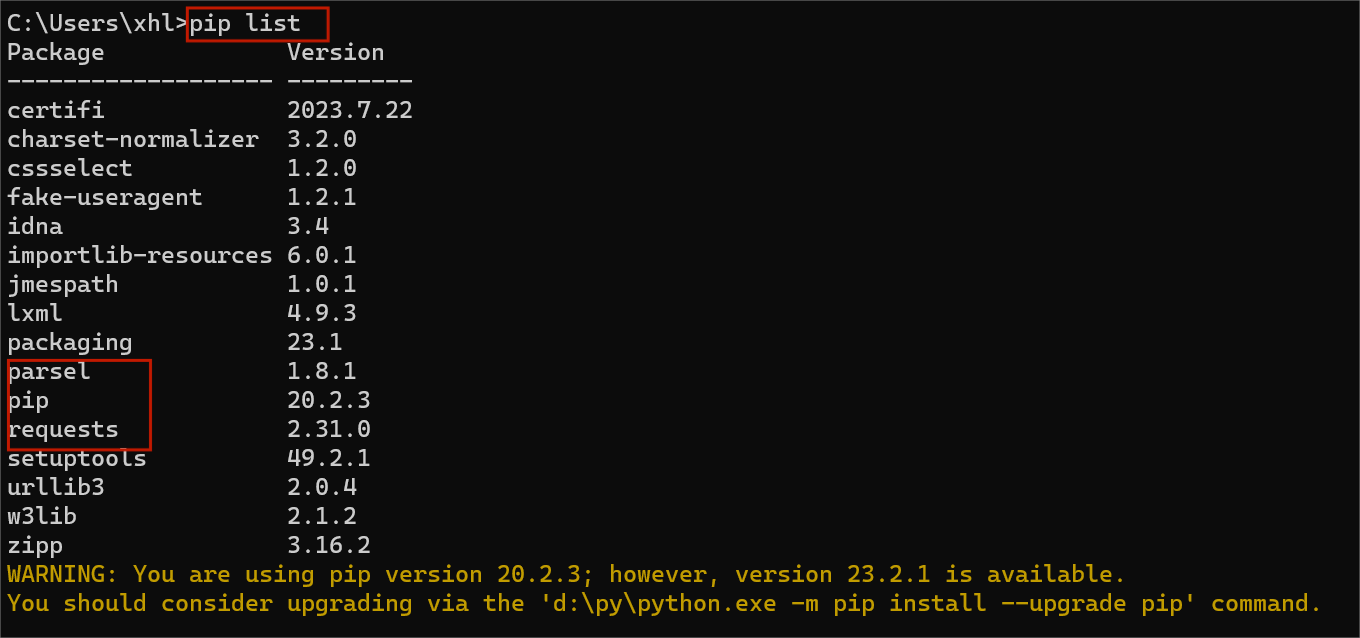
2.代码实现步骤:
(1).发送请求,对于刚刚分析得到的url地址发送请求
(2).获取数据,获收服务器返回的response响应数据
(3).解析数据,提取我们想要的数据内容小说章节名字以及小说内容
(4).保存数据,把提取出来的内容保存到本地
(1).发送请求
小说第一章导航栏地址:
![]()
用response变量接收返回的内容
url = 'http://www.ibiquge.cc/19666/5687111.html'
response= requests.get(url) # <Response[200]>返回response响应对象,200表示请求成功
print(response)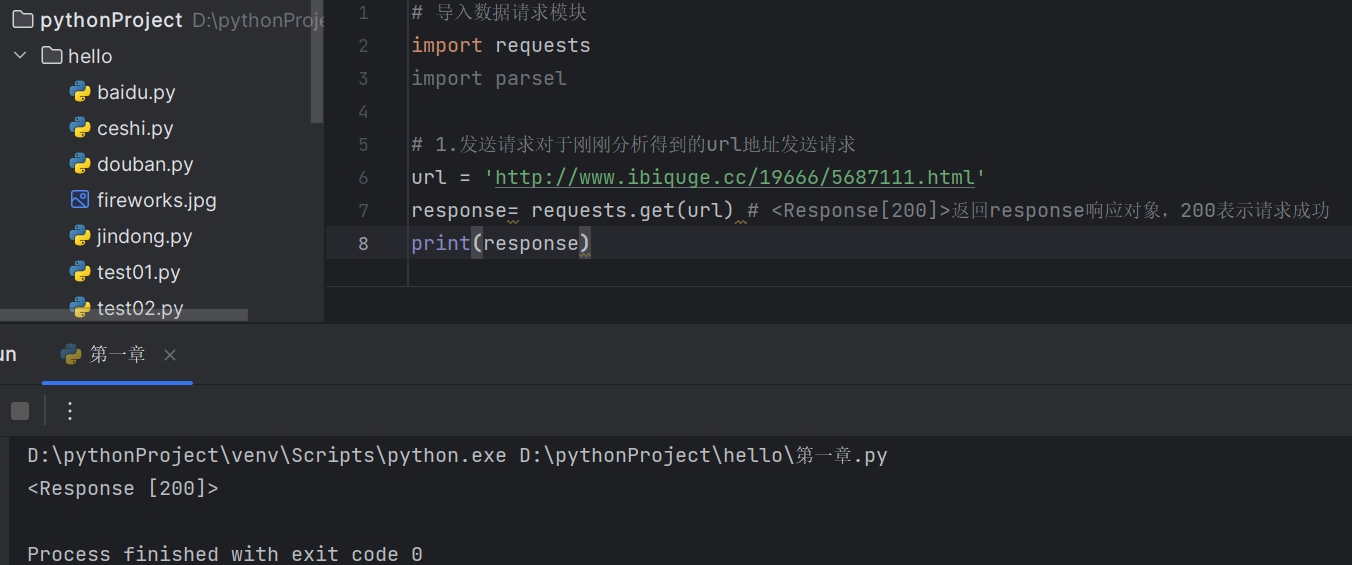
(2).获取数据
print(response.text) 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 622
622











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









