







 通道用于缓存数据,确保数据的可靠传输。- `a1.sinks.k1.type = hdfs`:指定了数据汇 `k1` 的类型为 `hdfs`,表示数据将被写入Hadoop分布式文件系统(HDFS)。- `a1.sources.r1.channels = c1`:将数据源 `r1` 连接到通道 `c1`,表示从数据源获取的数据将通过通道传输到数据汇。- `a1.channels.c1.type = memory`:指定了通道 `c1` 的类型为 `memory`,表示数据将在内存中缓存。
通道用于缓存数据,确保数据的可靠传输。- `a1.sinks.k1.type = hdfs`:指定了数据汇 `k1` 的类型为 `hdfs`,表示数据将被写入Hadoop分布式文件系统(HDFS)。- `a1.sources.r1.channels = c1`:将数据源 `r1` 连接到通道 `c1`,表示从数据源获取的数据将通过通道传输到数据汇。- `a1.channels.c1.type = memory`:指定了通道 `c1` 的类型为 `memory`,表示数据将在内存中缓存。
目录
2.创建 user_behavior-mem-hdfs.conf 文件
4.修改 user_behavior-mem-hdfs.conf 文件
4.查看 user_shopping_behavior.txt 文件
5.1切换到flume配置文件目录 /opt/server/flume/file
问题1:Hadoop中的 guava 版本和 Flume中的 guava 版本不一致
一、编辑配置文件
1.打开目录
在正式做flume数据迁移之前先检查flume是否配置完成、免密是否正常、防火墙是否关闭。打开flume下的file目录,没有file目录就自己创建一个。
cd /opt/server/flume/file/
2.创建 user_behavior-mem-hdfs.conf 文件
vim user_behavior-mem-hdfs.conf![]()
3.打开Flume中文网
Flume 1.9用户手册中文版 — 可能是目前翻译最完整的版本了
3.1查找Exec Source
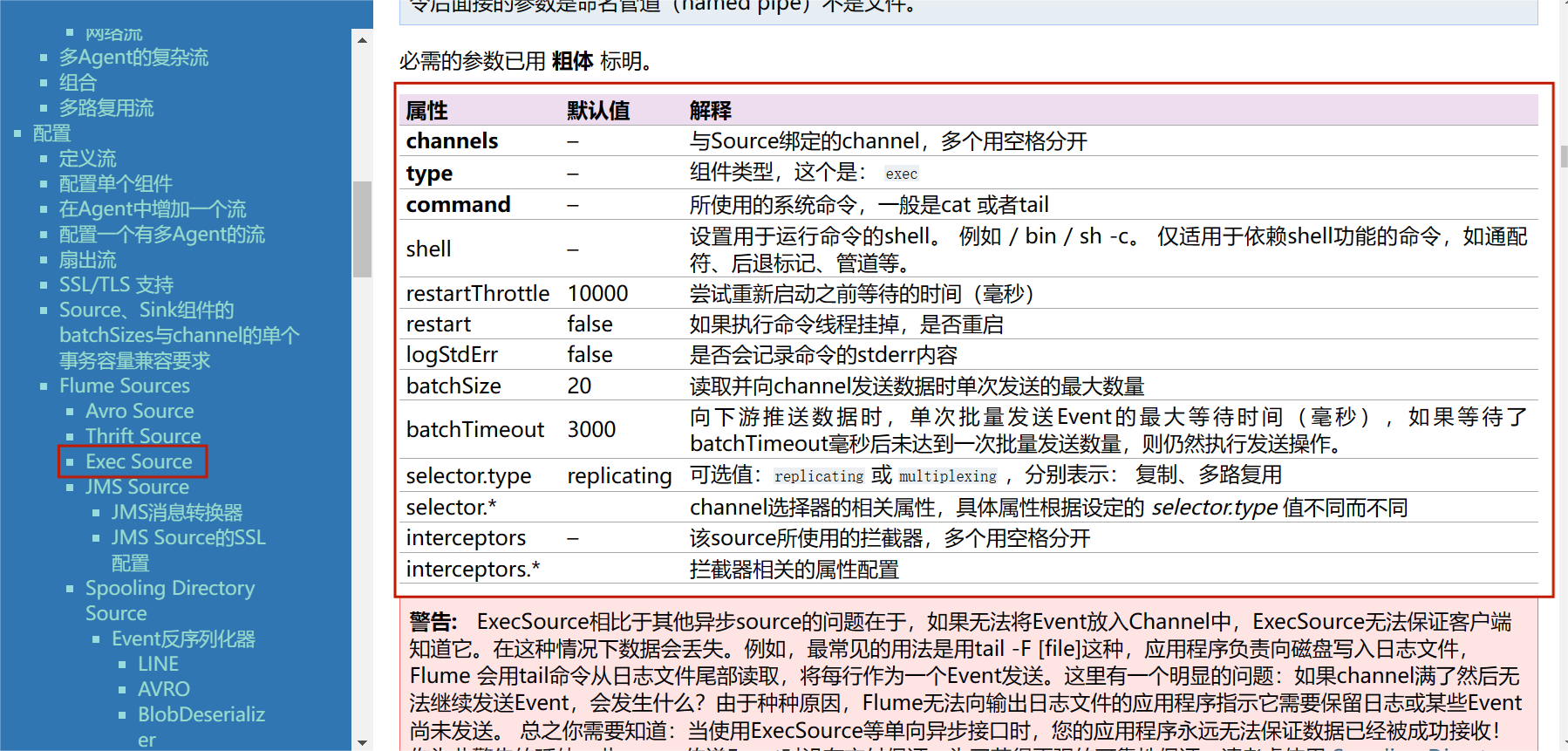

3.2查找Memory Channel

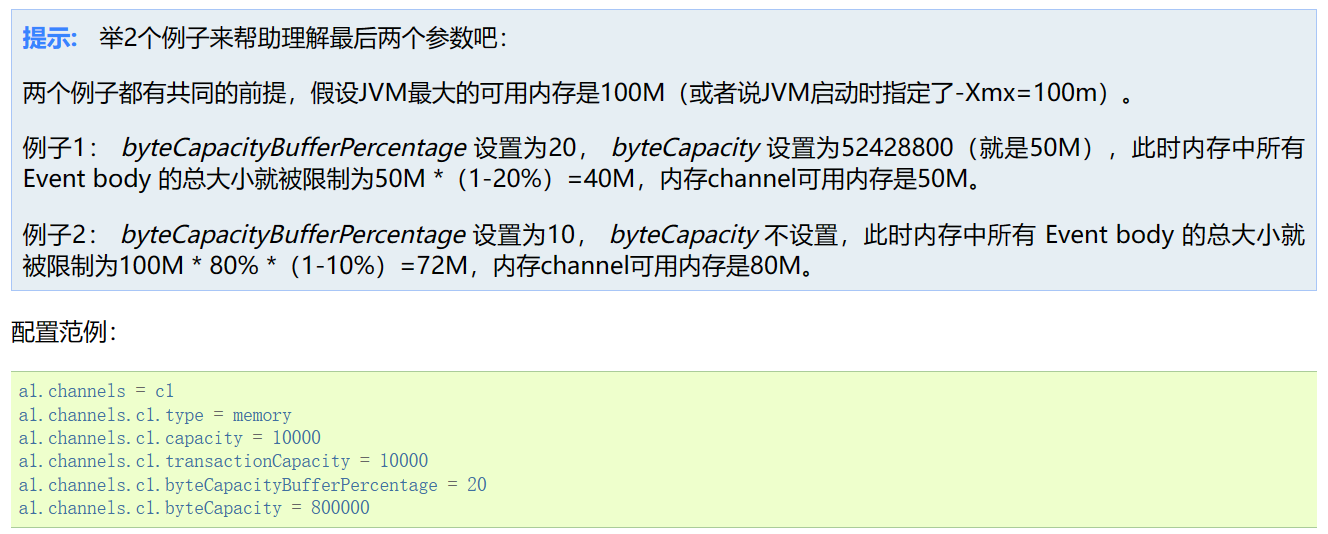
3.3查找HDFS Sink
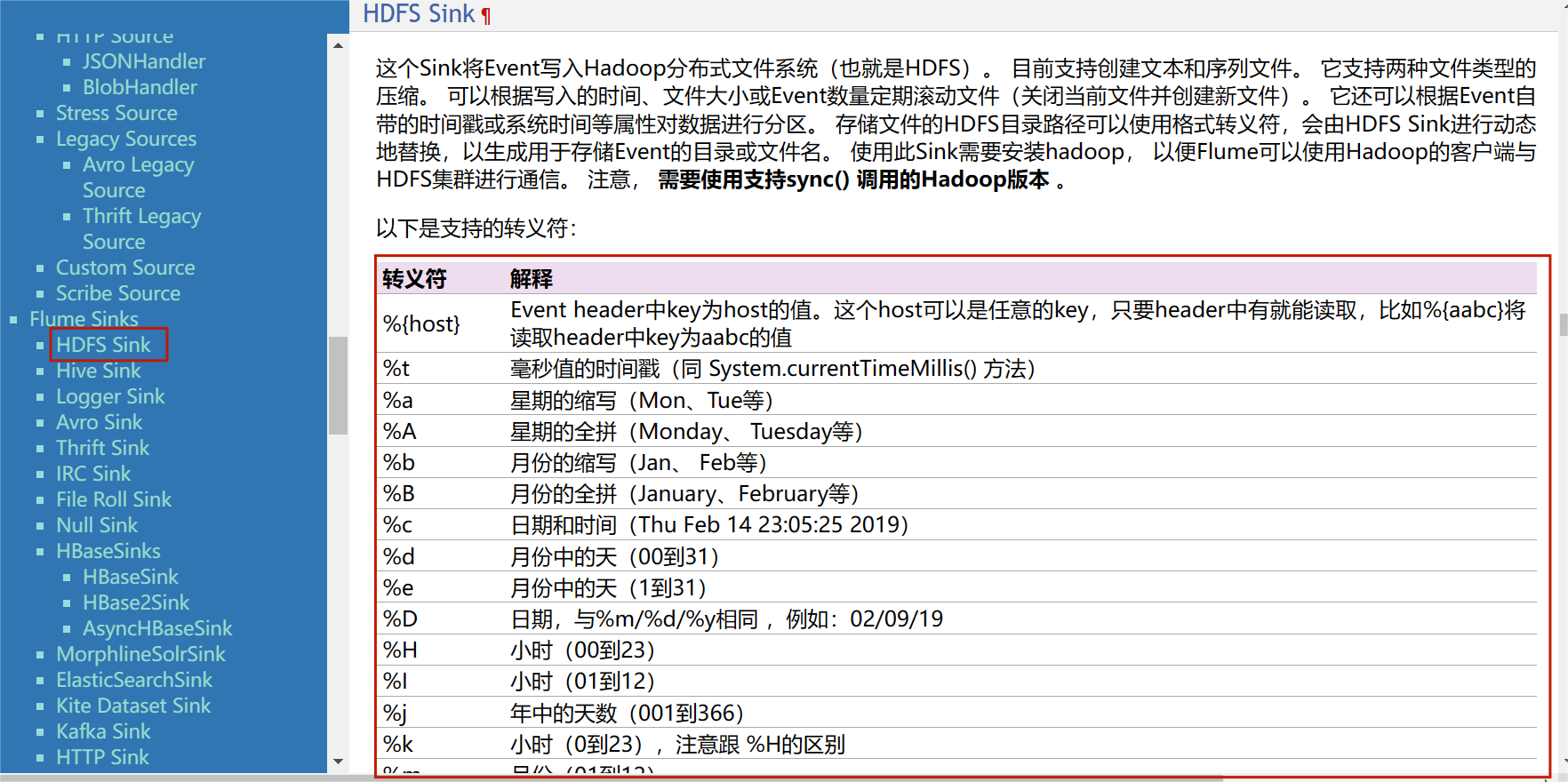

4.修改 user_behavior-mem-hdfs.conf 文件
# 别名
a1.sources = r1
a1.channels = c1
a1.sinks = k1
# 编辑sources
a1.sources.r1.type = exec
a1.sources.r1.conmmand = tail -F /opt/data/user_shopping_behavior.txt
# 编辑channels
a1.channels.c1.type = menory
a1.channels.c1.capacity = 10000
a1.channels.c1.transactionCapacity = 10000
a1.channels.c1,byteCapacityBufferPercentage = 20
a1.channels.c1.byteCapacity = 800000
# 编辑sinks
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = /flume/events/%y-%m-%d
a1.sinks.k1.hdfs.filePrefixs = user-
a1.sinks.k1.hdfs.round = true
a1.sinks.k1.hdfs.roundValue =10
a1.sinks.k1.hdfs.roundUnit = mimute
a1.sinks.k1.hdfs.rollInterval = 0
a1.sinks.k1.hdfs.rollSize = 0
a1.sinks.k1.hdfs.rollCount = 0
a1.sinks.k1.hdfs.useLocalTimeStamp = true
a1.sinks.k1.hdfs.fileType = DataStream
# 编辑通道
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1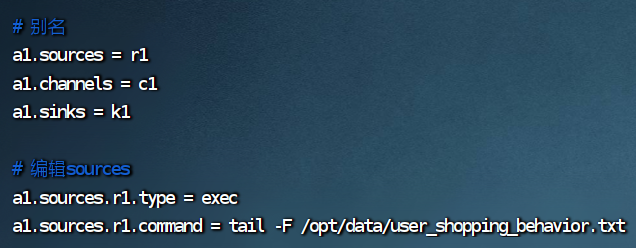

这是一个Apache Flume配置文件示例,用于定义Flume数据传输流程。Flume是一个用于收集、传输和存储大量数据的分布式数据采集工具。这个配置文件的意义:
1. 别名部分:
- `a1.sources = r1`:定义了一个数据源(source)的别名为 `r1`。
- `a1.channels = c1`:定义了一个通道(channel)的别名为 `c1`。
- `a1.sinks = k1`:定义了一个数据汇(sink)的别名为 `k1`。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 429
429











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









