









各位观众姥爷们晚上好,今天想要跟大家分享的是如何利用Stable Diffusion图生图,图生图说白了就是根据已有的一张图片给它变化成不同的风格,三次元图片变成二次元图片,二次元变成三次元图片等等。那么具体该如何操作呢?跟着我一步步来吧。
首先第一步我们需要有我们的开源软件Stable Diffusion,在这里跟大家分享一个整合包,秋叶大神的整合包。
需要的可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

–来自百度网盘超级会员V1的分享
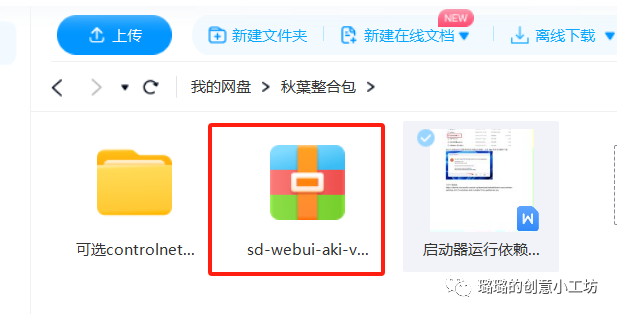
这三个文件夹都要下载下来,这里需要注意的是解压包解压的时候要选择全英文的路径。
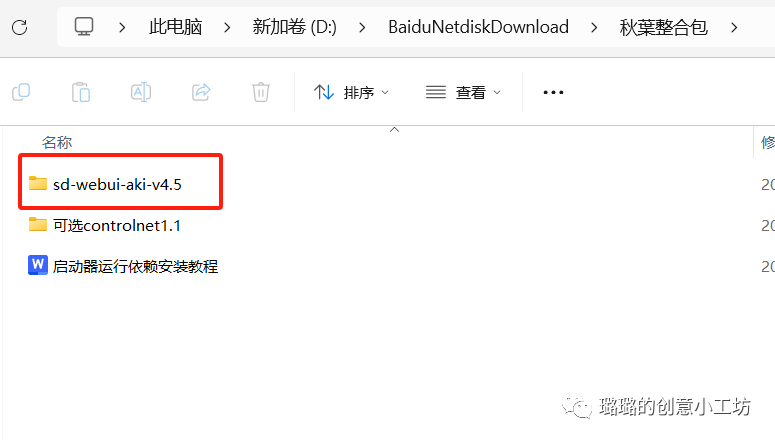
解压完成之后是这个样子,然后我们打开我框出来的文件夹
里面有个A绘世启动器,点击一下
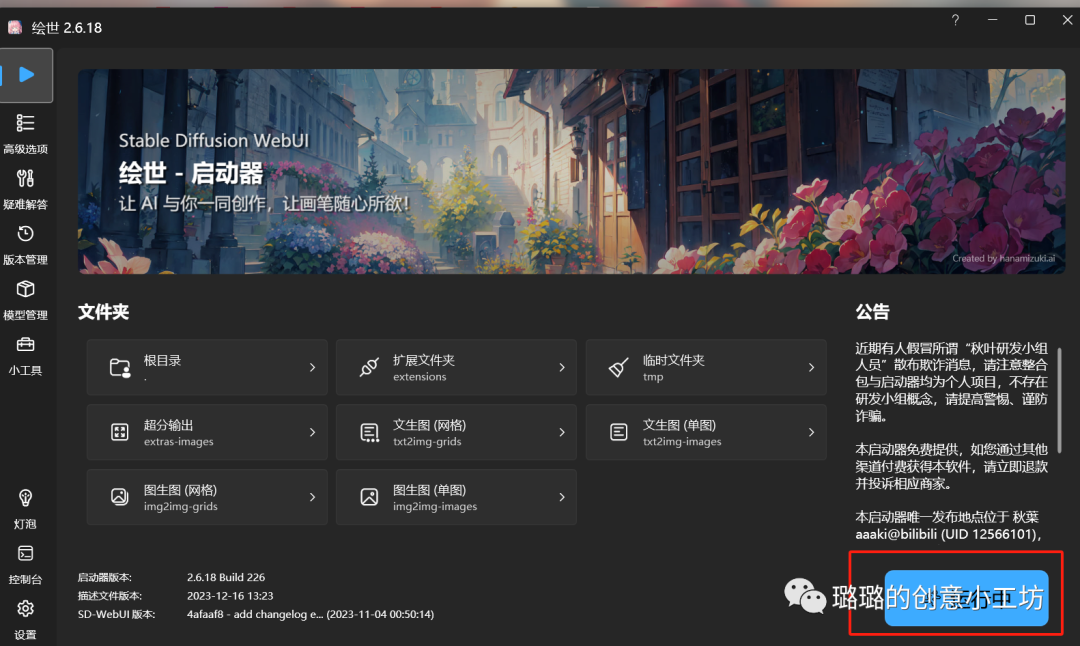
然后耐心等待就可以进入到我们的SD Webui界面
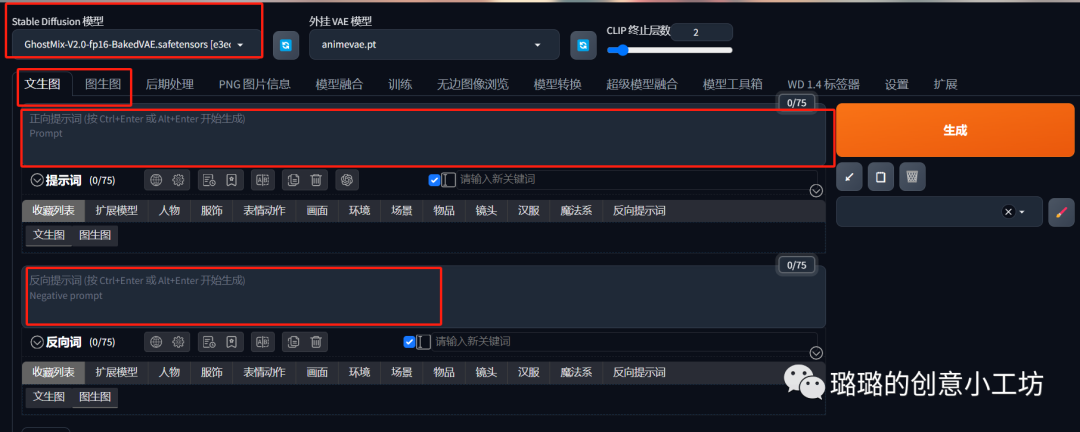
最上面是我们的模型,一般如果刚安装的话会默认只有一个模型Anything,那个是比较偏向于二次元的模型,具体如何下载更多的模型可以参考我之前的文章。我们下载好了大模型一般是存在这个路径下面。

然后底下是文生图或者图生图,今天我们要讲的是图生图,所以我们就可以点击图生图。
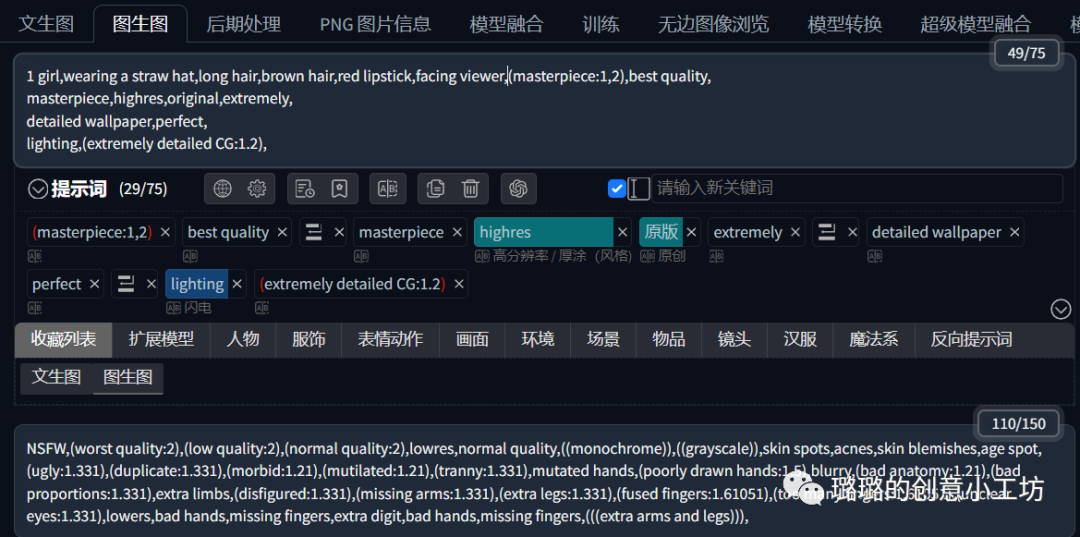
然后下面是正面提示词,就是我们希望在画面上呈现的东西,我们可以在这里输入指令告诉AI我们想要什么,以下是正面提示词的参考,当然我们也可以去抄作业,具体怎么抄作业也可以翻阅我之前的文章哈。
(masterpiece:1,2), best quality,
masterpiece, highres, original, extremely
detailed wallpaper, perfect
lighting,(extremely detailed CG:1.2),
这个是最基本的一个正面提示词(PS:我们要输入提示词只能用英文,因为AI只听得懂英文指令,如果英文实在不好的小伙伴可以借助翻译软件进行翻译)
然后是反面提示词:
NSFW, (worst quality:2), (low quality:2), (normal quality:2), lowres,normal quality, ((monochrome)), ((grayscale)), skin spots, acnes,skin blemishes, age spot, (ugly:1.331),(duplicate:1.331),(morbid:1.21), (mutilated:1.21),(tranny:1.331),mutated hands,(poorly drawn hands:1.5), blurry, (bad anatomy:1.21), (bad proportions:1.331), extra limbs, (disfigured:1.331), (missing arms:1.331), (extra legs:1.331), (fused fingers:1.61051), (too many fingers:1.61051), (unclear eyes:1.331), lowers, bad hands,missing fingers, extra digit,bad hands, missing fingers, (((extra arms and legs)))
在这里说一下NSFW是Not Safety For Work也就是工作场合不宜打开的,懂得都懂哈~如果我们想生成一些少儿不宜的画面的话,我们就可以把NSFW放在我们的正面提示词里面,这里就靠你们自由发挥了哈,但是不要被查水表哦。
我们点完图生图之后就可以放入我们想要处理的图片
这里我随便放个图片来举例子吧
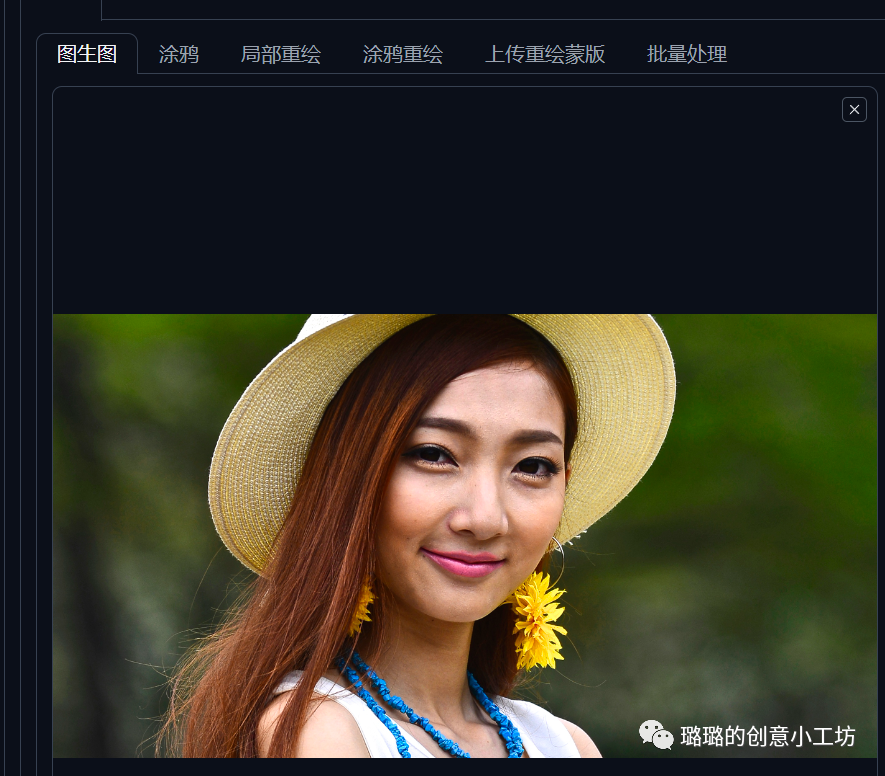
我们光有图片还是不够,AI是不会只根据图片就能判断出来我们想要生成的图片的,所以我们还要在正面提示词部分加入我们想要给AI呈现的信息,不一定是完整的一个句子,我们输入一些关键词就可以,比如棕色头发Brown hair,红唇 red lip,戴着帽子wearing hat,一个女孩 1 girl,在这里我们需要注意的是我们在生成每个提示词中间的逗号一定要是英文输入法状态下的逗号哈,否则我们的AI也是不会识别的。
如何正确地去写提示词,我在这里再放一个网站给大家。
http://www.atoolbox.net/Tool.php?Id=1101
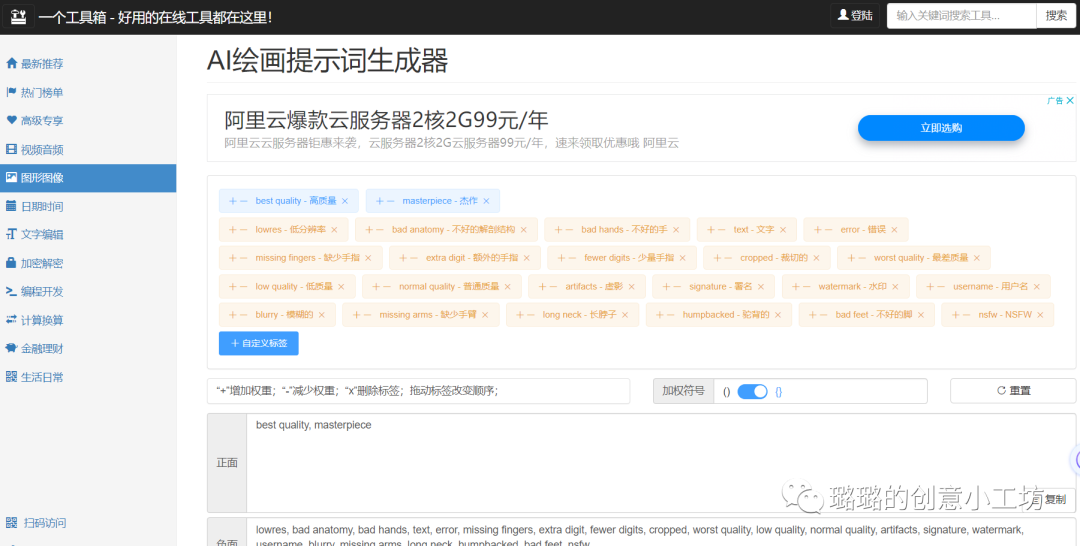
在这里就可以去找到我们需要添加的正面或者反面提示词

然后我们如何增加或减少我们的提示词权重,就可以增加括号或者赋予提示词值来实现。

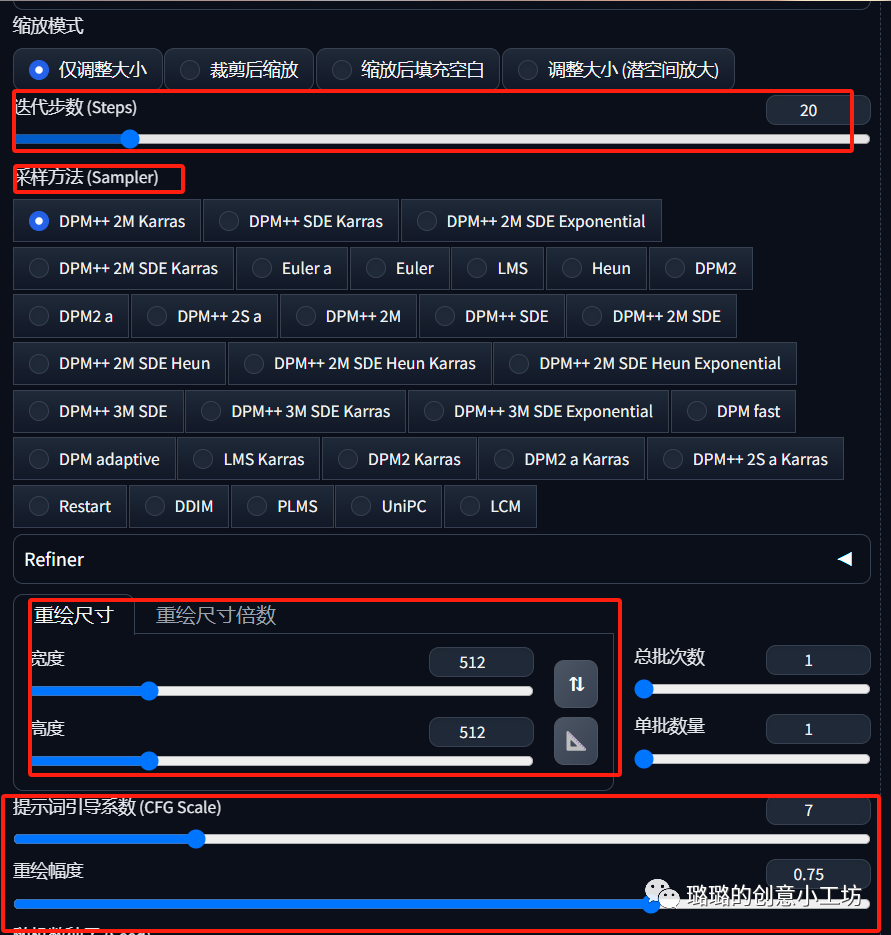
迭代步数:是AI自己通过计算生成图片的步数,一般控制在20-30之间,不宜过高,要不然生成的图片会画蛇添足或者超出我们的预期。
采样方法:在这里默认DPM2++Karras
重绘尺寸:是我们希望生成的图片的尺寸,可以调整宽度和高度
总批次数:一次让AI生成几张图片
单批数量:默认为1,不要调太高,这里是AI计算生成图片的次数,如果单批数量调成2.然后总批次数是4就会是2X4,同样的是生成四张图片但是AI会计算两次,很容易爆显存,在这里建议就默认为1就好。
提示词引导系数:顾名思义,就是AI多大程度上去依赖我们给他赋予的提示词。
重绘幅度:就是给AI多大的自由发挥空间,在这里0.2-0.5是一个安全值,超过了之后AI就会放飞自我。
如果想要AI生成的图片更加精准,那么还可以借助我们的另一个工具Control Net
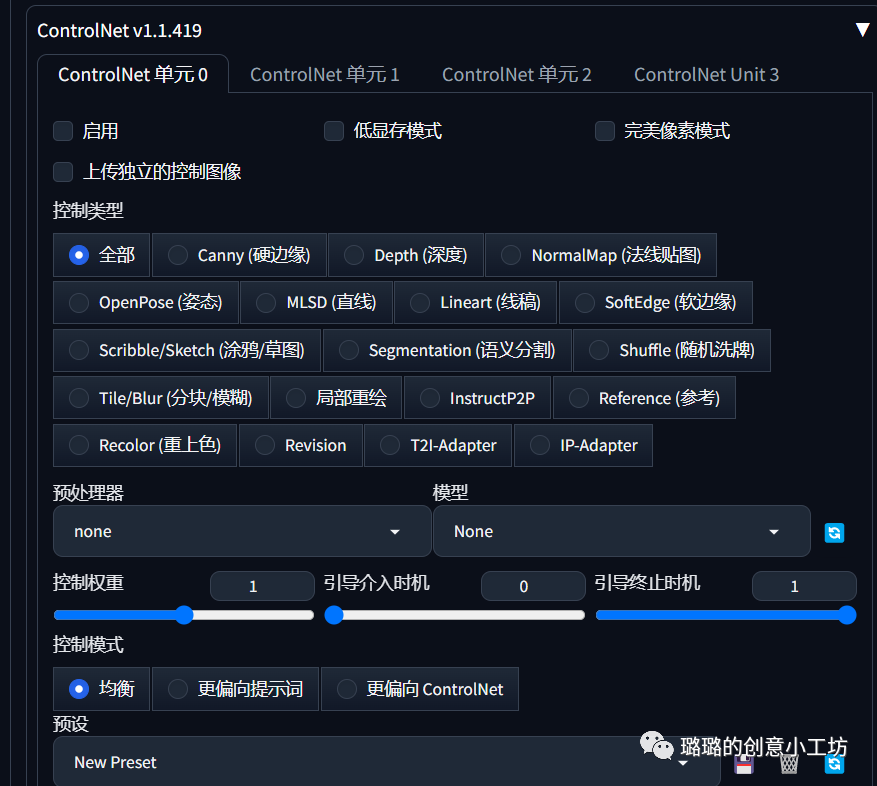
在这里我们可以启用,如果显存不够的还可以点击我们的低显存模式。
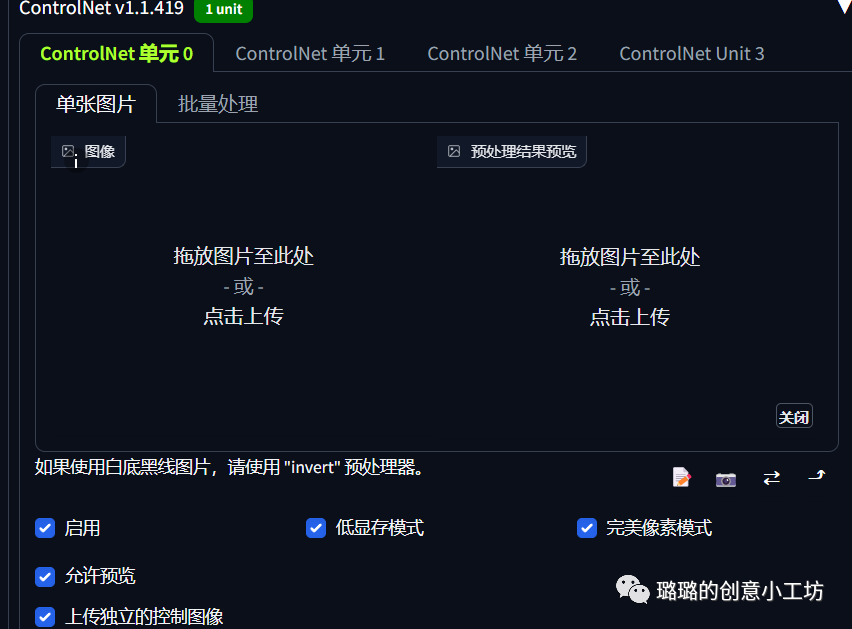
在这里如果是图生图的话我建议可以全都选上
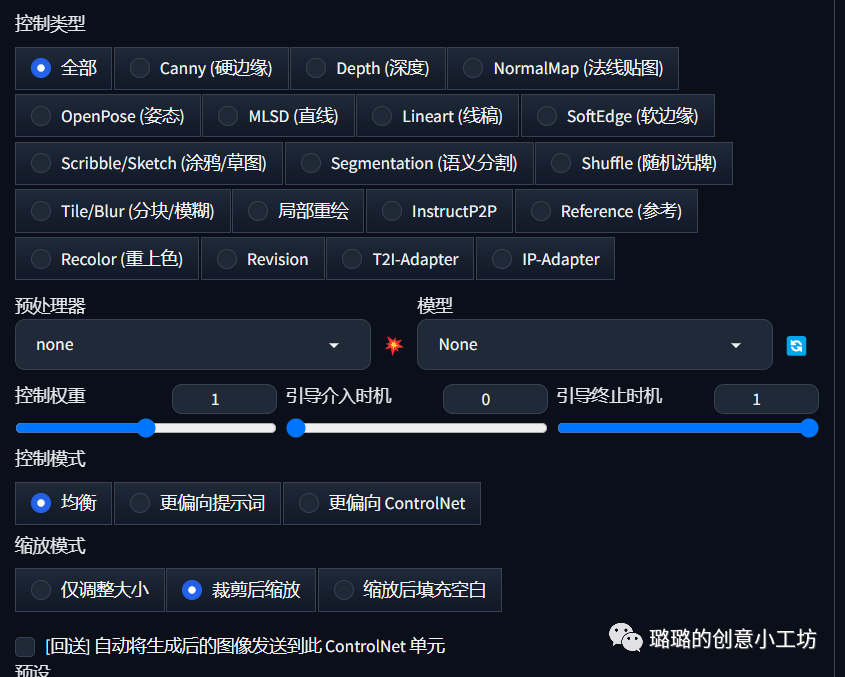
然后我们这里可以选择控制类型,我们可以根据我们的图像去选择不同的控制类型,如果图片是文字或者线稿的话我们可以选择Canny,如果是带有姿势的人物图片的话我们就可以选择OpenPose,如果在这里只是一张人脸的话我们就直接默认全部就行,其他的控制类型你们可以后期自己去尝试。
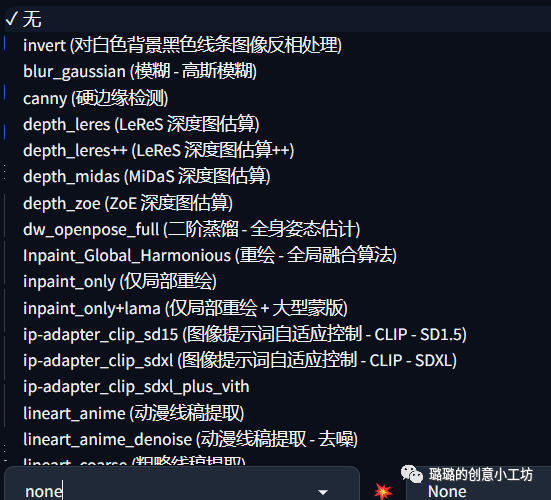
预处理器这里我们也可以根据不同的图片类型去选择
在这里我选择的是Faceonly,然后模型这里我们可以选择open pose然后点击中间的爆炸按钮,就会有神奇的事情发生~
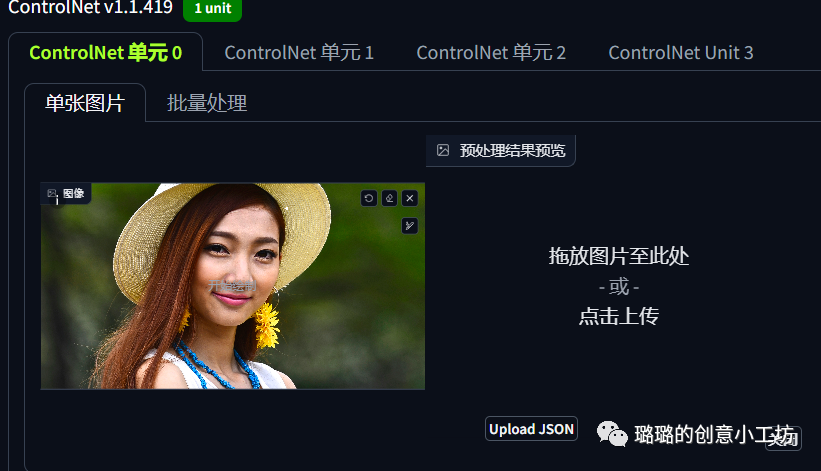
我们现在这里上传我们的图片,然后再点击爆炸的小按钮。
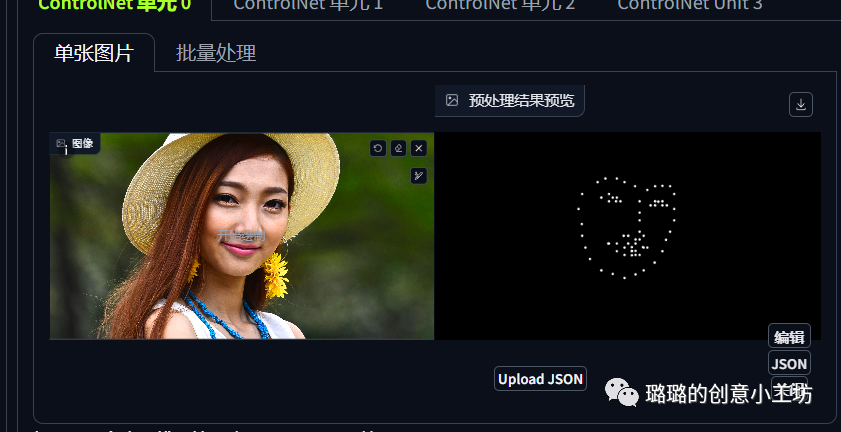
然后这里AI就会捕捉到我们的人脸
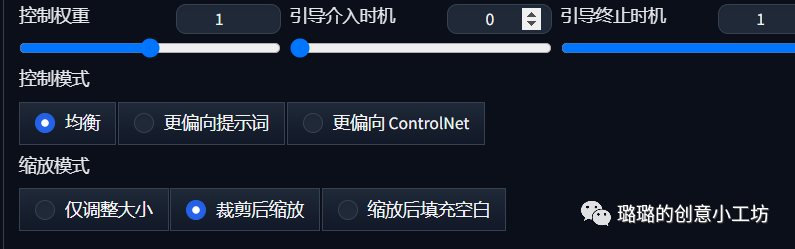 这里的控制权重我们默认为1就好,然后控制模式我们一般也是默认均衡,如果你想更偏向提示词,或者更偏向Control Net也是可以的哈。
这里的控制权重我们默认为1就好,然后控制模式我们一般也是默认均衡,如果你想更偏向提示词,或者更偏向Control Net也是可以的哈。
 然后这里我们可以选择让AI一次生成几张图片,如果你想多生成几张那就可以把这个总批次数给往上调整几个数值,这里最多一次跑10张。
然后这里我们可以选择让AI一次生成几张图片,如果你想多生成几张那就可以把这个总批次数给往上调整几个数值,这里最多一次跑10张。

在一切都准备就绪之后我们点击生成就可以坐等AI出图了哈
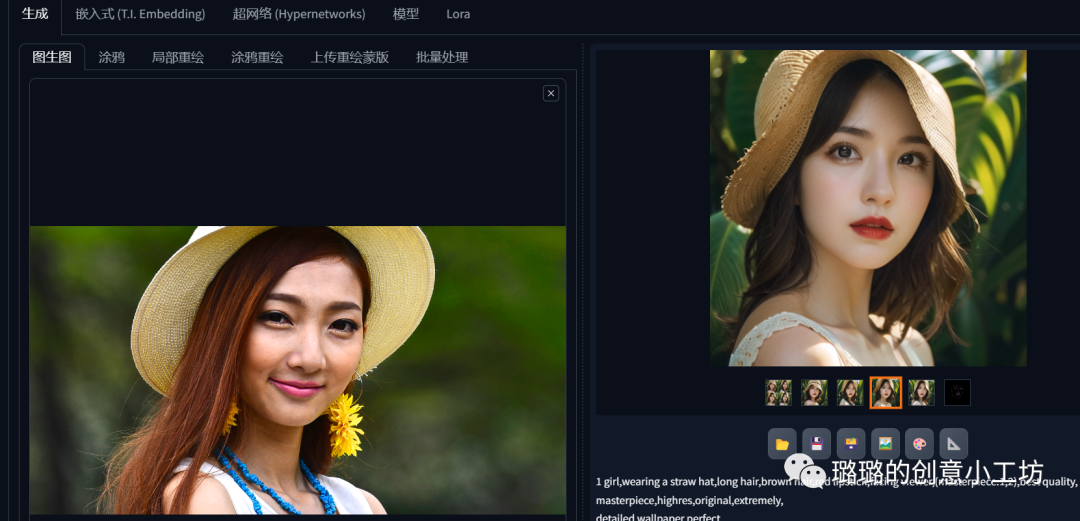
各位对比一下像不像呢?
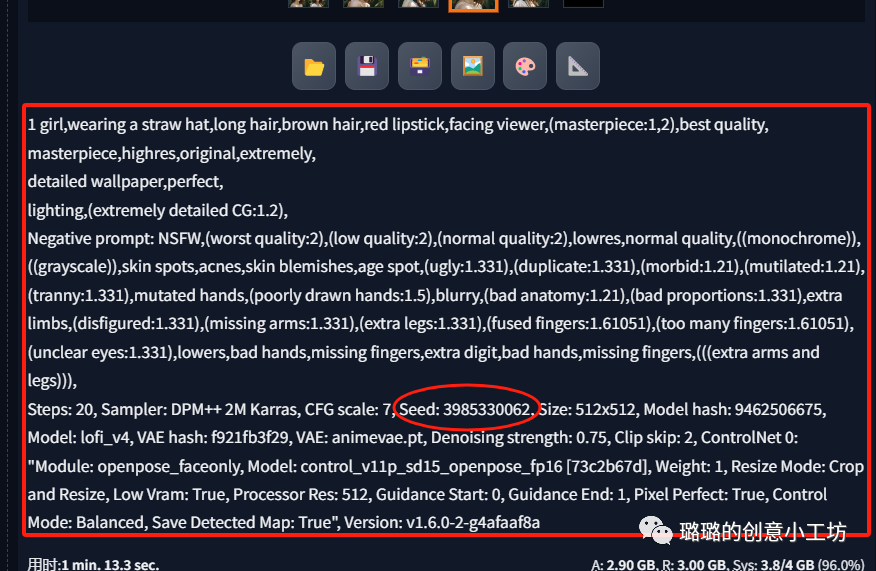
然后底下这个就是我们的作弊码哈,如果我们对我们的作品满意想分享给其他一样在使用SD的小伙伴,那我们就可以把我们的作弊码复制给他们,在这里我要着重说下我们的随机数种子,就是我圈出来的Seed,如果我们对这次生成的作品满意下次还想生成一个跟这个大差不差的作品,我们就可以把这个随机数种子给复制下来。

然后放在这里,下次再生成同样风格的作品的时候就可以根据这个随机数种子去生成一个大差不差的作品。
写在最后:
如果有的小伙伴实在不会写证明提示词怎么办呢?那也不用担心,我们还有一招。
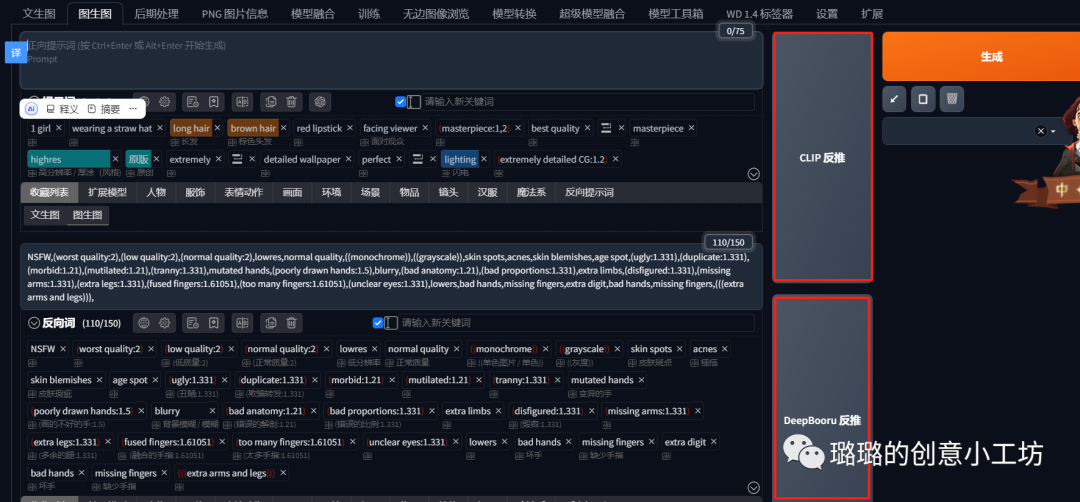
我们可以点击Clip反推或者Deepbour反推,这样就可以根据画面自动生成一些提示词了。

然后再加上我前面附上的正面提示词就可以啦。
好了,今天的分享到这里就结束了,你学会(废)了吗?

















 3796
3796

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









