







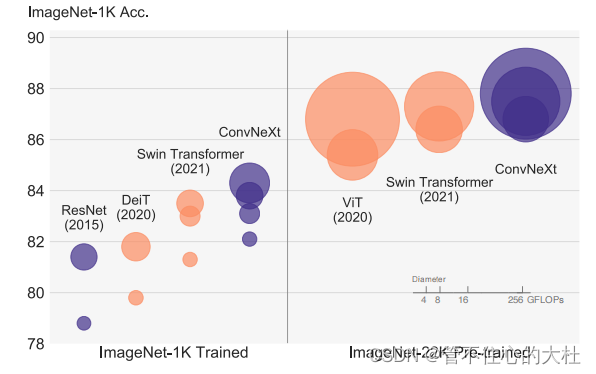
摘要
Swin Transformer表现得很好,并且可以作为通用的骨干网络。然而,这种混合方法的有效性在很大程度上归功于Transformer的内在优越性,而不是卷积的固有的归纳偏差。于是,我们重新调查了设计空间并且测试了纯卷积网络所能达到的极限。将一个标准resnet朝着Vit的方向现代化.
1.introduction
卷积神经网络在计算机视觉的主导地位是必然的:滑动窗口.平移方差的归纳偏置让他在目标检测任务中大放异彩。卷积神经网络也很有效率,因为在滑动窗口时计算是共享的。
SwinTransformer的成功和快速被采纳也揭示了一件事:卷积的本质并不是变得无关紧要;相反,它仍然非常重要。
我们的探索涉及到一个关键问题:怎么用Transformer的设计决策提高卷积网络。我们发现了导致性能差异的几个关键组件。并给得到的卷积网络其名为convnext。和Transformer相比,他在准确性,可拓展性和鲁棒性都表现得很好,而且具有标准卷积网络的高效性和全部卷积网络的特性,以及实现起来非常简单。
2.Modernizing a ConvNet: a Roadmap
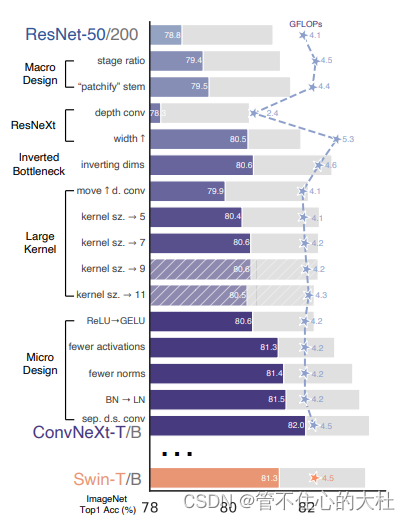
起点是一个ResNet-50模型。用类似于训练Vit的训练技术来训练它.然后总结了一系列的设计决策:
1) macro design,
2) ResNeXt,
3) inverted bottleneck,
4) large kernel size, and
5) various layer-wise micro designs
并且可能比参考模型的flops更高。
2.1 Training Techniques
Transformers不仅带来了新的模块集和架构设计决策,也带来了新的训练技术。(比如AdamW optimizer)。这主要涉及到优化策略和相关的超参数设置。因此,我们探索的第一步是用Vit的训练程序来训练一个基线模型。在我们的研究中,我们使用了一个接近DeiT的和Swin Transformer的训练方法。相比resnet,该训练从90个epochs扩展到300个epochs。我们使用AdamW优化器,
数据增强技术:mixup,cutmix,random augment,random erasing,
正则化方案:stochas-depth,Label Smoothing
就其本身而言,这种增强的训练配方将ResNet-50模型的性能从76.1%提高到78.8%(+2.7%),这意味着传统的网络和视觉变压器之间的性能差异很大一部分可能是由于训练技术.
2.2. Macro Design
我们现在分析Swin Transformer的宏观网络设计.有两个有意思的考虑因素:stage计算模块比例,stem模块的设计.
1、改变stage比率:传统的resnet50各个stage中计算模块的比例是3:4:6:3,而Swin-T是1:1:3:1,Swin-L是1:1:9:1,于是降resnet也调整为3,3,9,3(1:1:3:1),这将模型精度从78.8%提高到79.4%,但仍然可能存在更优的设计.
2、改变stem模块:通常,stem的设计关注的是在网络在开始时如何处理输入的图像.
标准ResNet中的stem包含一个7×7的卷积层,步幅为2,然后是一个最大池。
Vit使用“pachify”策略作为stem,它对应于一个大的核大小(14或16)和非重叠卷积。
Swin Transformer一个较小的patch,4,以适应架构的多级设计。
我们用patchify替换resnet的stem,使用4×4,步幅4卷积层。准确率从79.4%变到79.5%。说明ResNet中的stem可以被一个更简单的“patchify”所取代。
2.3. ResNeXt-ify
ResNeXt的指导原则是“使用更多的组,扩大宽度”。
我们使用DW卷积,并且我们发现DW卷积类似于自注意力机制中的加权和操作,将DW conv和1*1卷积核的conv结合。根据ResNeXt中提出的策略,将网络宽度增加到与swint相同的通道数(从64增加到96)。随着flops的增加,网络性能达到80.5%。
2.4. Inverted Bottleneck
每个Transformer的一个重要设计是,它创建了一个反向的瓶颈,MLP块的隐藏维度比输入维度宽四倍。
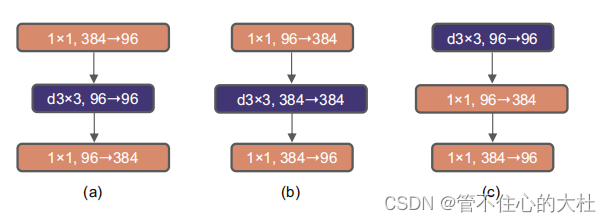
于是我们探索反向瓶颈,见图3从(a)到(b)的配置。这一变化使整个网络的flops降至4.6G,尽管DW conv层的FLOPs增加,但由于在下采样层的大幅减少,整个网络的FLOPs显著减少。有趣的是,这略微改善了性能(80.5%到80.6%)。在ResNet-200 / Swin-B中,这一步带来了更多(81.9%到82.6%),并减少了flops。
2.5. Large Kernel Sizes
Vit最显著的方面之一是它们的非局部自注意,这使每一层都有一个全局感受野。虽然过去ConvNets 使用过大内核大小,但黄金标准(VGGNet)是堆叠小卷积核(3×3)来代替大卷积核。虽然SwinTransformer重新将局部窗口引入了自注意块,但窗口大小至少为7×7,明显大于ResNe (X)t内核大小:3×3。
向上移动DW conv层:
为了探索大内核,首先要向上移动DW conv层的位置(图3 (b)到(c))。这个设计决策在Transformer中也有所体现:MSA在MLP之前。由于我们有一个反向的瓶颈块,这是一个自然的设计选择——复杂/低效的模块(MSA,大内核conv)将有更少的通道,而高效、密集的1×1层将完成繁重的工作。这一中间步骤将flops降低到4.1G,导致性能暂时下降到79.9%。
Increasing the kernel size:
我们实验了几个内核大小,包括3、5、7、9和11。网络的性能从79.9%(3×3)增加到80.6%(7×7),而网络的flop基本保持不变。此外,我们观察到,更大的内核大小的好处在7×7达到饱和点。我们在大容量模型中也验证了这种情况:当我们增加内核大小超过7×7时,ResNet-200模型不会显示出进一步的增益。
2.6. Micro Design
我们将研究尺度上的其他几个架构差异——大多数探索都在层级上完成,重点关注激活函数和规范化层的特定选择。
生词:
inductive bias 归纳偏置
design decision 设计决策
scalablity 可拓展性
resemblance 相似性















 2820
2820











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









