









 该研究通过改造ResNet模型,结合ResNeXt和反向瓶颈设计,以及使用大卷积核,提出了一种新的卷积网络架构。在训练技术上应用了数据增强、正则化和优化器AdamW,同时发现指数滑动平均(EMA)对带有BatchNorm层的模型有害。实验结果显示,这种改进的卷积网络在ImageNet预训练和微调策略上表现优越,且在目标检测和语义分割等下游任务中展现出强效性能。
该研究通过改造ResNet模型,结合ResNeXt和反向瓶颈设计,以及使用大卷积核,提出了一种新的卷积网络架构。在训练技术上应用了数据增强、正则化和优化器AdamW,同时发现指数滑动平均(EMA)对带有BatchNorm层的模型有害。实验结果显示,这种改进的卷积网络在ImageNet预训练和微调策略上表现优越,且在目标检测和语义分割等下游任务中展现出强效性能。
A ConvNet for the 2020s
讨论通过改善卷积网络模型,使其达到优于transformer模型的效果(文章基于ResNet模型框架进行改造升级)
研究基线:
基于训练transformer模型的训练技术训练ResNet-50
设计决策:
- 宏观设计
- ResNeXt
- 反向 bottleneck
- 大kernel尺寸
训练技巧:
- AdamW优化器
- 数据增强:Mixup、Cutmix、RandAugment、RandomErasing
- 正则化:Stochastic Depth、Label Smoothing
EMA—指数滑动平均,好处在于:1.平滑数据、2.可以存储近似n个时刻的平均值,而不用在内存中保留n个时刻的历史数据,减少了内存消耗。本研究发现EMA会严重损害带有BatchNorm层的模型。
ImageNet 预训练策略

ImageNet 微调策略

宏观设计部分
宏观设计
- 多级异形特征映射分辨率
- 级别计算比例
- “干细胞”结构
ResNeXt-ify
-
使用可分离卷积,分为逐通道卷积(Depthwise Convolution)和逐点卷积(Pointwise Convolution)。(不同于标准卷积同时对所有channels进行卷积,而是先进行H*W维度的卷积,再进行channels维度的卷积,即各channels分别卷积完,再叠加生成最后的特征图。)
-
可分离卷积
深度可分离卷积
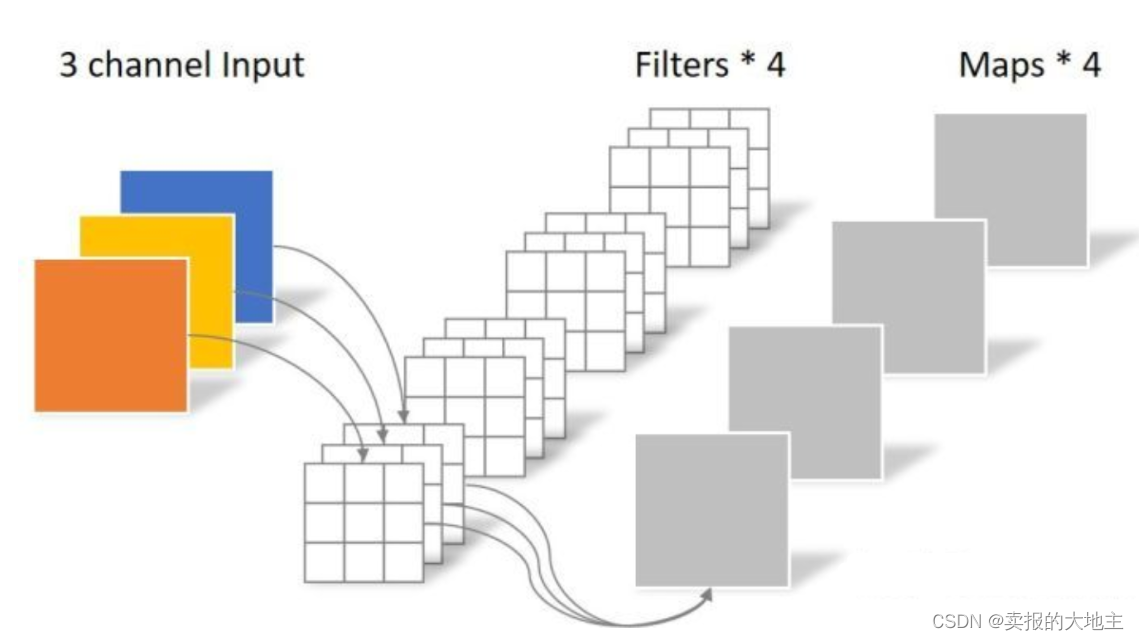
逐通道卷积

逐点卷积


计算量计算公式:

卷积知识补充: [各种卷积的流程和优缺点]((35条消息) 各种卷积的流程和优缺点_深度可分离卷积的优缺点_浪迹天涯的yf的博客-CSDN博客)
-
对于标准卷积,其各channels间的权重是不重叠的,不共享的。
反向Bottleneck
每个Transformer块中的一个重要设计是它创建了一个反向瓶颈,即MLP块的隐藏维度比输入维度宽四倍

大型卷积核
Vison Transformer最显著的特点就是非局部注意力,因为多头自注意力机制,每个序列向量对于其他序列向量进行了相关计算,计算公式如下:
A
t
t
e
n
t
i
o
n
(
Q
,
K
,
V
)
=
S
o
f
t
M
a
x
(
Q
K
T
d
k
)
V
Attention(Q, K, V) = SoftMax(\frac{QK^T}{\sqrt{d_k}})V
Attention(Q,K,V)=SoftMax(dkQKT)V
- 使用向上移动的深度卷积层。复杂/低效模块(MSA,大内核conv)将有更少的通道,而高效、密集的1×1层将做繁重的工作。(就是将复杂较大的卷积层放再通道数较少的阶段,也就是偏向输入层方向,而多通道处(分类头处)更适合使用1×1卷积这样的小型的卷积层。)
- 增加卷积核大小。在每个块中使用7×7卷积核。本文在大模型中验证得出:内核大小增加到7×7以上时,ResNet-200状态模型不会显示出进一步的增益。
微观设计部分
使用GELU替代RELU

注意:gelu作为激活函数训练时,建议使用一个带动量的优化器
pytorch实现:
def gelu(x):
"""Implementation of the gelu activation function.
For information: OpenAI GPT's gelu is slightly different (and gives slightly different results):
0.5 * x * (1 + torch.tanh(math.sqrt(2 / math.pi) * (x + 0.044715 * torch.pow(x, 3))))
Also see https://arxiv.org/abs/1606.08415
"""
return x * 0.5 * (1.0 + torch.erf(x / math.sqrt(2.0)))
补充:[深度学习常用激活函数]((35条消息) 常用激活函数(relu,glu,gelu,swish等)_glu激活函数_栋次大次的博客-CSDN博客)
更少的激活函数。在每个块中使用单个GELU激活。

更少的归一化层。
发现在块的开始添加一个额外的BN层并不能提高性能。
使用LN替代BN
在介绍各个算法之前,我们先引进一个问题:为什么要做归一化处理?
神经网络学习过程的本质就是为了学习数据分布,如果我们没有做归一化处理,那么每一批次训练数据的分布不一样,从大的方向上看,神经网络则需要在这多个分布中找到平衡点,从小的方向上看,由于每层网络输入数据分布在不断变化,这也会导致每层网络在找平衡点,显然,神经网络就很难收敛了。当然,如果我们只是对输入的数据进行归一化处理(比如将输入的图像除以255,将其归到0到1之间),只能保证输入层数据分布是一样的,并不能保证每层网络输入数据分布是一样的,所以也需要在神经网络的中间层加入归一化处理。
BN、LN、IN和GN这四个归一化的计算流程几乎是一样的,可以分为四步:
-
计算出均值
-
计算出方差
-
归一化处理到均值为0,方差为1
-
变化重构,恢复出这一层网络所要学到的分布
训练的时候,是根据输入的每一批数据来计算均值和方差,那么测试的时候,平均值和方差是怎么来的?
对于均值来说直接计算所有训练时batch 均值的平均值;然后对于标准偏差采用每个batch 方差的无偏估计。


分离下采样层
使用带有步长的卷积核进行下采样。
研究表明,在空间分辨率改变的地方添加归一化层有助于稳定训练。
ImageNet的研究结果

下游任务的研究结果
基于COCO的目标检测与分割

基于ADE20K的语义分割

研究展望
混合模型:将卷积和Transformer相结合。
补充:[深度学习模型参数量/计算量和推理速度计算]((35条消息) 深度学习模型参数量/计算量和推理速度计算(一)_flopcountanalysis_曙光_deeplove的博客-CSDN博客)
















 2820
2820











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











