







源码下载
本文所有源码在GitHub当中发布,喜欢的话麻烦点个star
GitHub - Dominic23331/yolov8_tensorrt
前期准备
硬件准备
在前期的准备当中,你需要有以下硬件:
- 个人PC
- Jetson Nano开发板
- TF卡
- 路由器
- 网线
软件准备
在个人电脑当中,你需要安装以下软件:
- Anaconda
- Pytorch
- ultralytics
- MobaXtern
- balenaEtcher
- Clion
- Pycharm(可选)
接下来主要讲解一下jetson nano当中的软件安装过程。
1、首先,你需要准备一个 Jetson Nano(B01或A02 均可,建议采用 4GB 版的开发板),以及一张容量大于 16GB 的 TF 卡。


2、在英伟达网站中下载jetson nano的镜像文件。
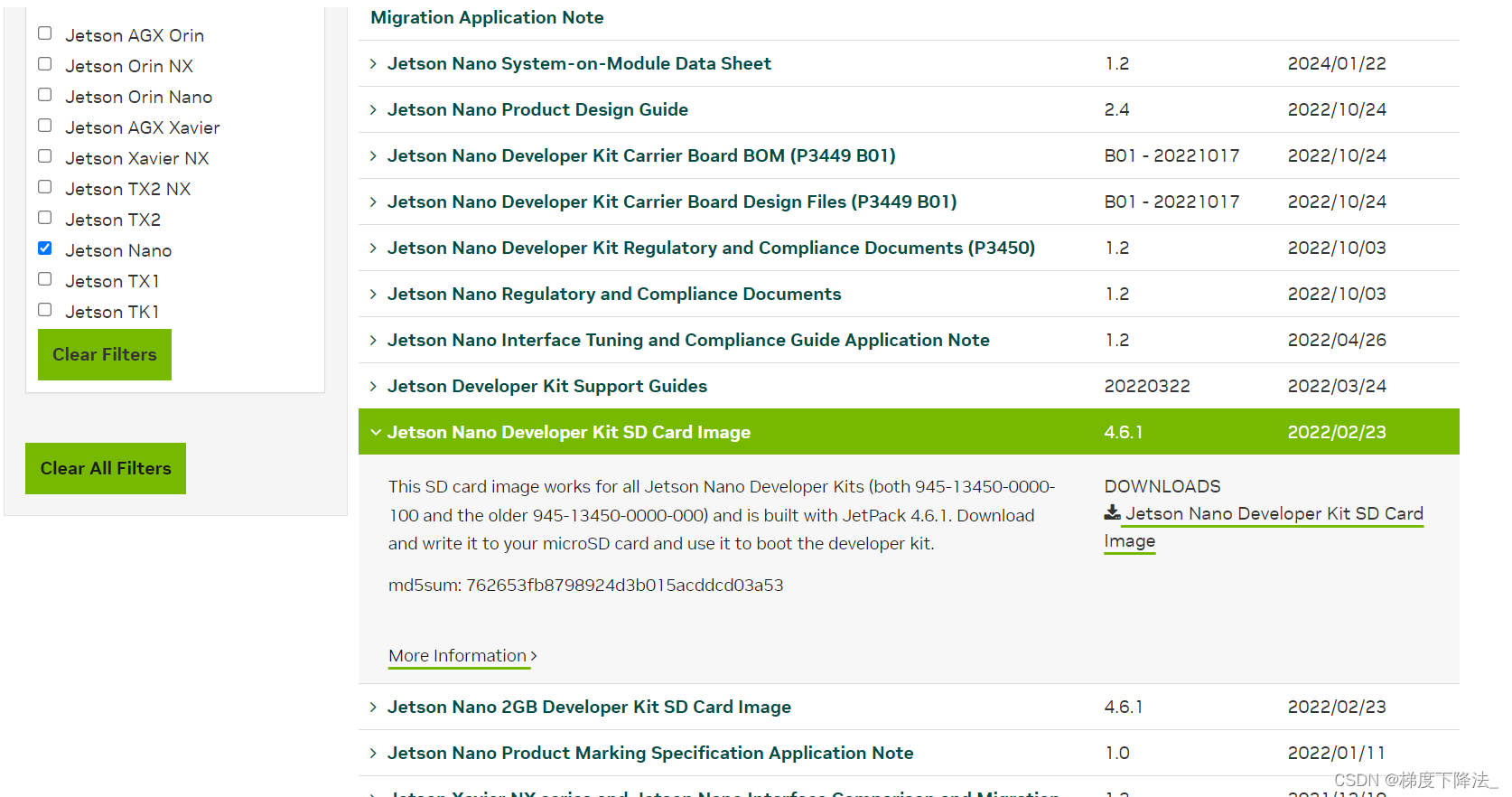
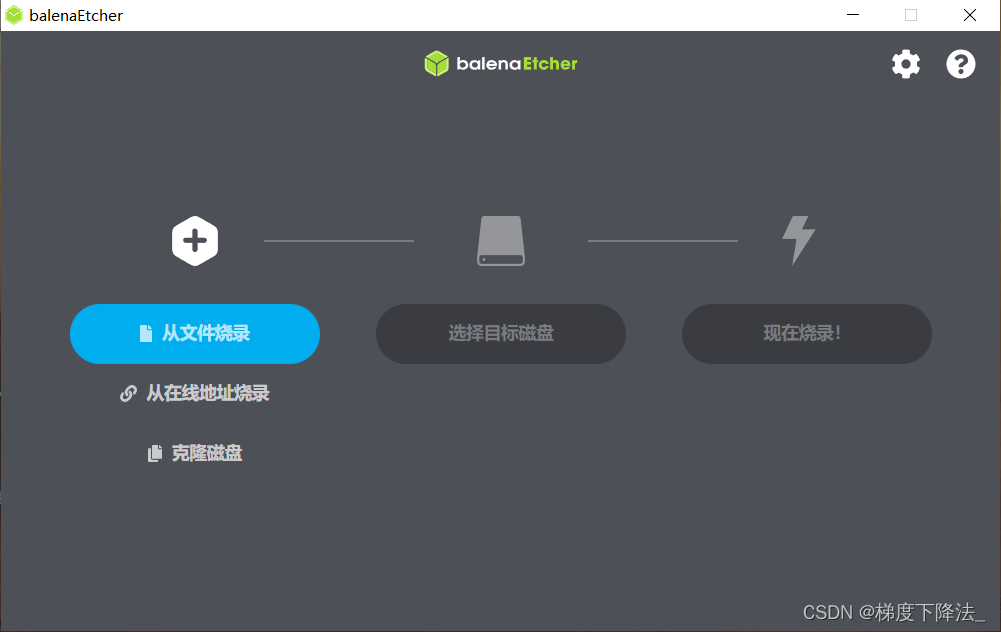
3、使用balenaEtcher软件将镜像写入TF卡当中。
4、将TF卡插入jetson nano当中,并进行初始化设置。
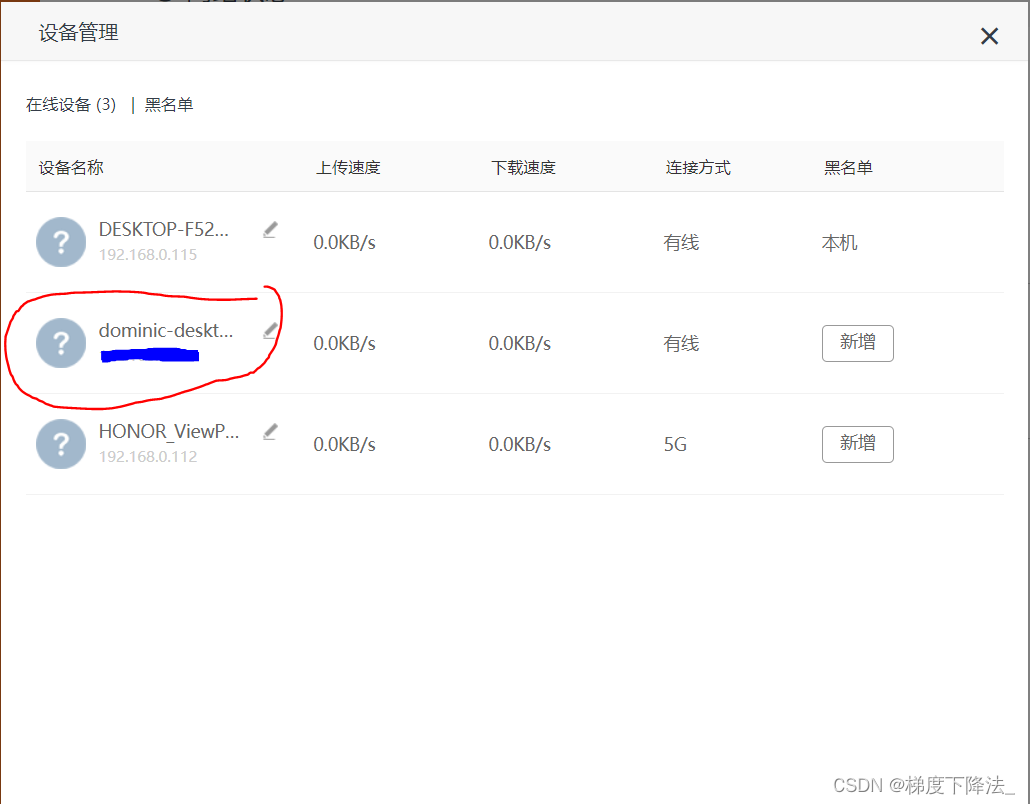
5、 使用网线或无线连接将 Jetson Nano 与路由器相连接,然后在浏览器中输入路由器的管理界面地址(通常是 192.168.0.1)。从管理界面中查找 Jetson Nano 的 IP 地址。
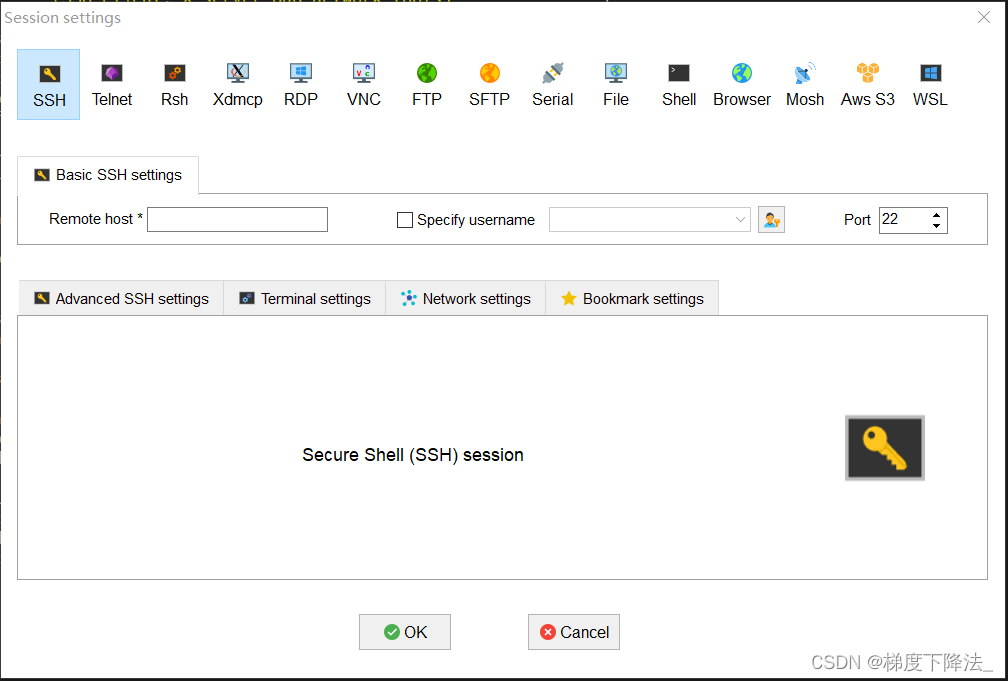
6、使用 MobaXterm 软件的 SSH 功能,输入 Jetson Nano 的 IP 地址以及账号密码,连接到 Jetson Nano。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1942
1942

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









