







一.Supervised Learning(监督学习)
1.监督学习之-回归问题
监督学习,意指给出一个算法,需要部分数据集已经有明确的答案。比如给定房价数据集,对于里面每个占地面积,算法都知道对应的正确房价(即这房子实际卖出的价格),如图1-1。

图1-1
这里监督学习算法真正在做的事情是根据很多已知的面积-房价数据集来计算出很多未知价格但知道面积的房子的房价。用更术语的方式来定义:监督学习又叫回归问题(应该说是回归问题属于监督学习中的一种),意指要预测一个连续值的输出,比如房价(虽然房价是个离散值,但通常把它看作实际数字,一个连续的数值)。而术语回归, 意味着给定一个变量,我们要预测出这个变量对应的取值结果(个人见解)。
2.监督学习之-分类问题
2.1 单特征分类问题
接下来通过医学上的一个例子来引出分类问题。让我们看一个收集好的数据集, 假设在数据集中,横轴表示肿瘤的大小, 纵轴用0或1来表示肿瘤是良性的还是恶性的,如图1-2。这里对应的机器学习问题就是,根据肿瘤(Tumor)的大小,你能否估算出一个概率,即肿瘤为恶性或者良性的概率。其实这只有两个结果,良性或者恶性。所以说,这是个分类问题。分类是要预测一个离散值输出,0或1,良性或恶性。
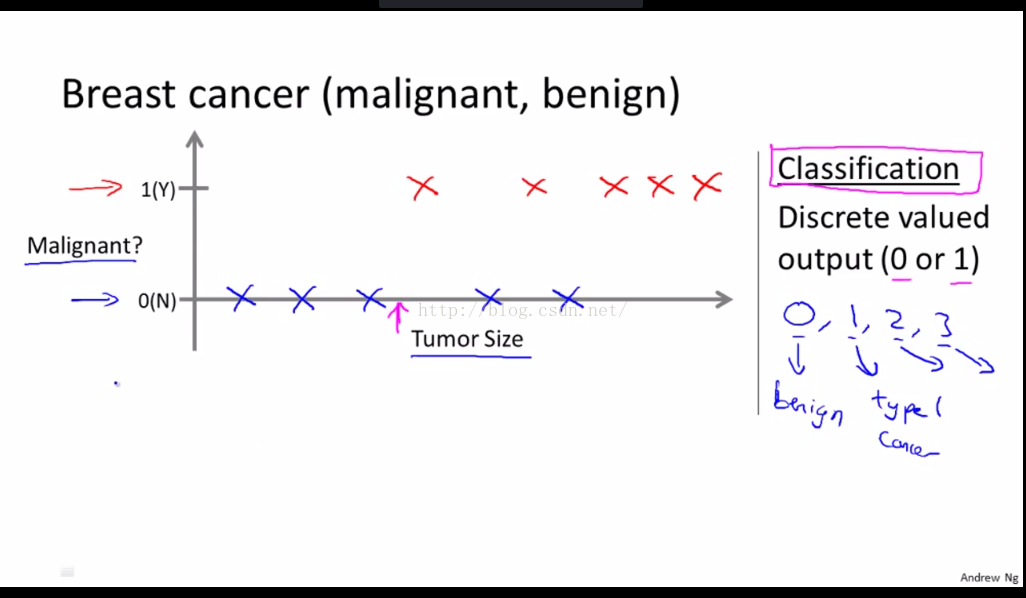
图1-2
事实证明, 在分类问题中,有时预测结果会有超过两个的值, 输出的值可能超过两种。举个具体例子,见上图右侧, 胸部肿瘤可能有三种类型,所以要预测离散值0,1,2,3,0就是良性肿瘤,没有癌症;1表示1号癌症(假设总共有三种癌症 ),2是2号癌症,3就是3号癌症。这同样是个分类问题,因为它的输出的离散值集合分别对应于无癌,1号,2号,3号癌症。
在分类问题中,还有另一种作图方式来描述数据,如图1-3。要用到些许不同的符号集合 来描绘数据。如果肿瘤大小作为唯一属性, 被用于预测恶性良性,可以把数据作图成如下图这样。
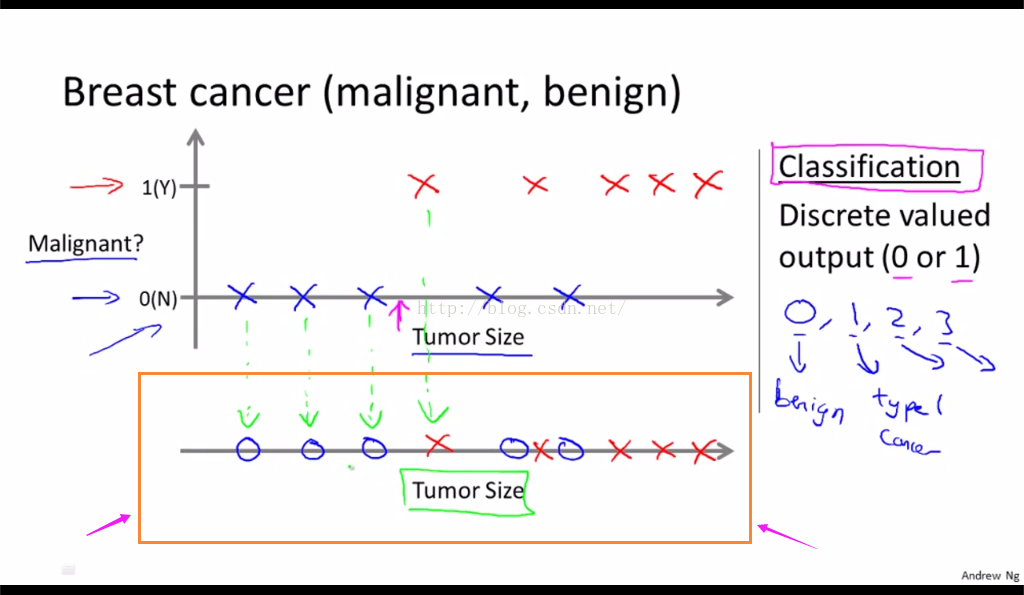
图1-3
解释一下,这里使用不同的符号来表示良性和 恶性。所以,这里就不再统一画叉叉了,改用圈圈来代表良性肿瘤,就像图上的蓝色圈圈这样;仍沿用X(叉叉)代表恶性肿瘤。希望能明白,这里做的就是把在上面的数据一一映射下来,然后用不同的符号(圈和叉)来分别代表良性和恶性。
2.2多特征分类问题
在上例中,我们只使用了一个特征属性(即肿瘤块大小)来预测肿瘤是恶性良性。但是在其它机器学习问题里, 往往有着不只一个的特征和属性。 这里举个栗子,现在我们不只知道肿瘤的大小,还知道病人的年龄。这种情况下, 数据集如表图1-4所示。图中恶性肿瘤用叉来表示;良性肿瘤用圈来表示。
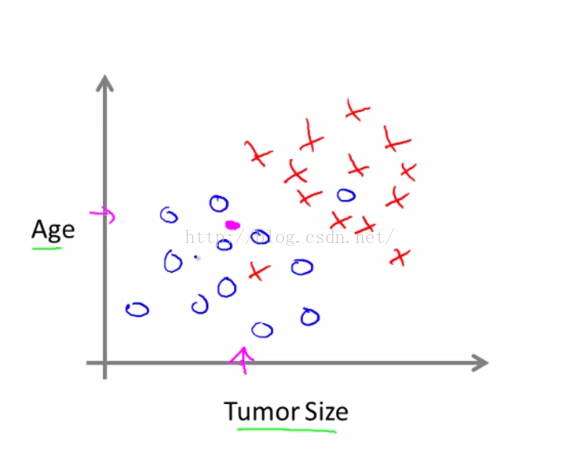
图1-4
假设 有一人得了肿瘤,肿瘤大小和年龄落在图上洋红色的地方。那么依据这个给定的数据集,学习算法所做的就是像这样画一条直线(图1-5),区分开恶性肿瘤和良性肿瘤。 如果它在线的左下方,学习算法就说肿瘤在良性一边,因此很有可能是良性的。

图1-5
以上例子中,总共有两个特征,即病人年龄和肿瘤大小。在别的ML问题中,经常会用到更多特征,别人在研究这个问题时, 通常使用如下这些特征:比如肿瘤的厚度,肿瘤细胞大小和形状的一致性等等。 真正对于一些学习问题,用到的不只是三五个特征,经常要用到无数多个特征,非常多的属性。所以,你的学习算法要利用很多的属性或特征、线索来进行预测。那么,如何处理 无限多特征呢?甚至你如何存储无数的东西进电脑里,又要避免内存不足? 事实上,以后会介绍一种叫支持向量机的算法,就知道存在一个简洁的数学方法,能让电脑处理无限多的特征。
3.小结
第一部分中介绍了监督学习,其基本思想是:在监督学习中,对于数据集中的每个数据,都有相应的正确答案,算法就是基于这些来做出预测。就像房价,后面介绍了回归问题(回归是监督学习中的一种), 即通过回归来预测一个连续值输出。 我们还谈到了分类问题, 目标是预测离散值输出。
二.Unsupervised Learning(无监督学习)
回顾下上一部分内容,上部分我们讲了监督学习。回想下当时的数据集,每个样本都已经被标明为 正样本或者负样本,即良性或恶性肿瘤(如图2-1所示)。
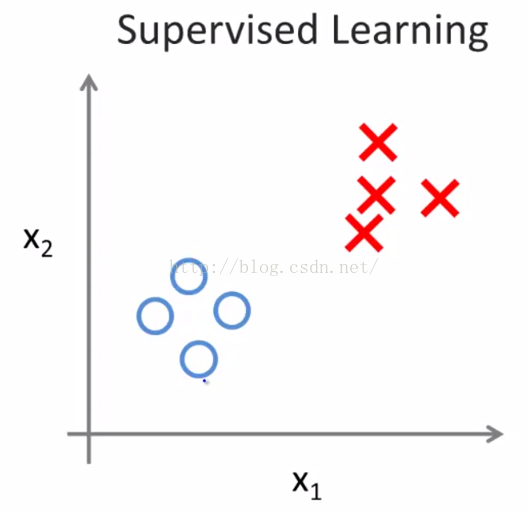
图2-1
这一部分将会介绍无监督学习。在无监督学习中,我们用的数据会和监督学习里的看起来有些不一样,在无监督学习中没有属性或标签这一概念,也就是说所有的数据都是一样的没有区别,如图2-2所示。
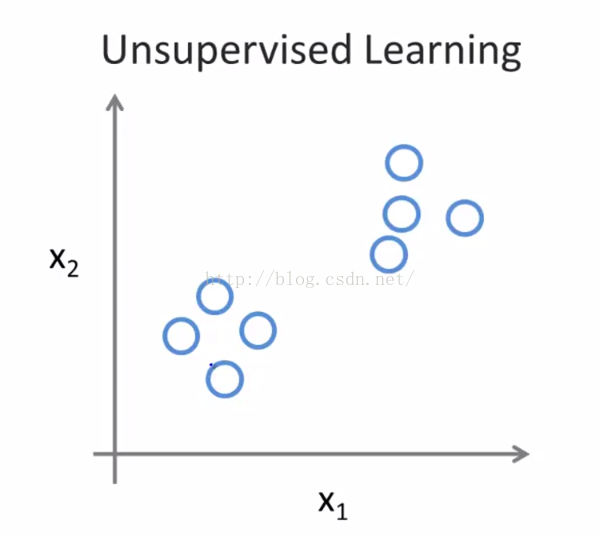
图2-2
也就是说在无监督学习中我们只有一个数据集,没人告诉我们该怎么做,我们也不知道每个数据点究竟是什么意思。相反,它只告诉我们现在有一个数据集,你能在其中找到某种结构吗?对于给定的数据集,无监督学习算法可能判定 该数据集包含两个不同的聚类,如图2-3所示。这就是所谓的聚类算法。
。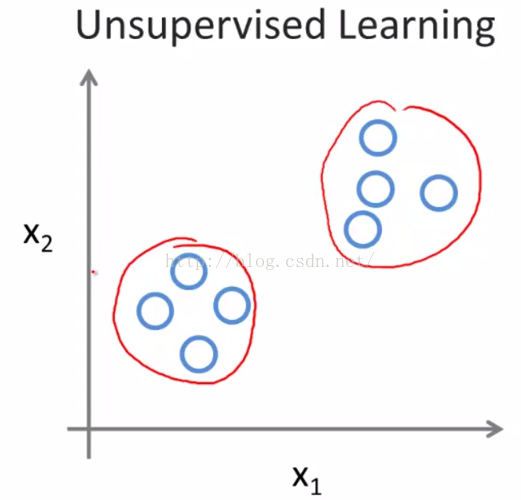
图2-3
聚类算法实际上还被用在很多地方。我们来举一个聚类算法的栗子 ,关于Google 新闻的例子。我们可以到这个news.google.com 去看看 谷歌新闻每天都在干什么。他们每天会去收集成千上万的网络上的新闻,然后将他们分组 组成一个个新闻专题。让我们看下BP油井事故的报道,如图2-4。
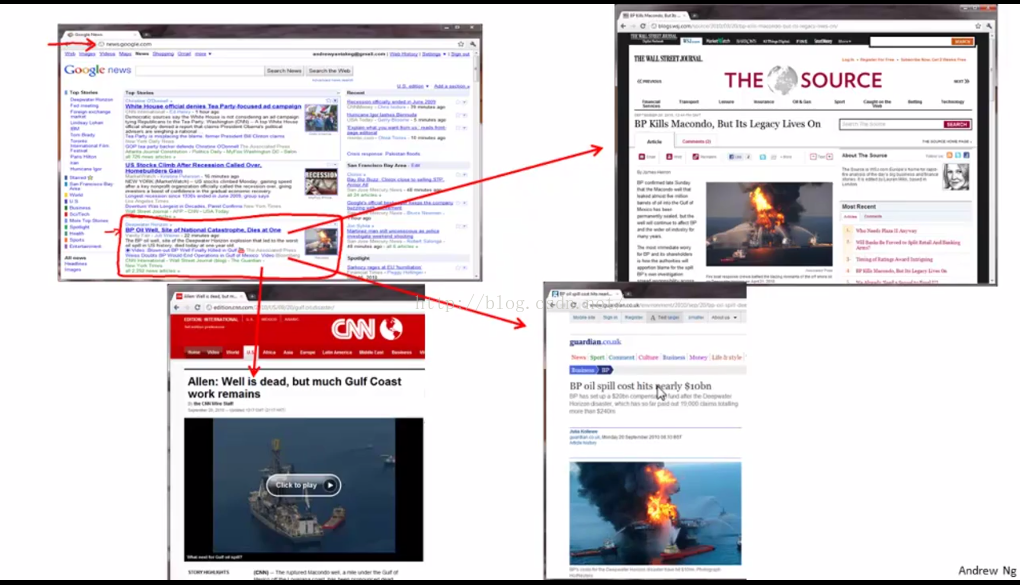
图2-4
所以谷歌新闻所做的就是去搜索成千上万条新闻,然后自动的将他们聚合在一起。因此,有关同一主题的新闻被显示在了一起。
实际上,聚类算法和无监督学习算法也可以被用于许多其他的问题,这里我们举个他再基因组学中的应用。如图 2-5所示,这是一个关于基因芯片的例子,基本的思想是 给定一组不同的个体,对于每个个体,检测它们是否拥有某个特定的基因。也就是说你要去分析有多少基因显现出来了,因此,这些颜色红,绿,灰等等, 它们展示了这些不同的个体是否拥有一个特定基因的不同程度,然后你能做的就是 运行一个聚类算法 把不同的个体归入不同的类 或归为不同类型的人 。
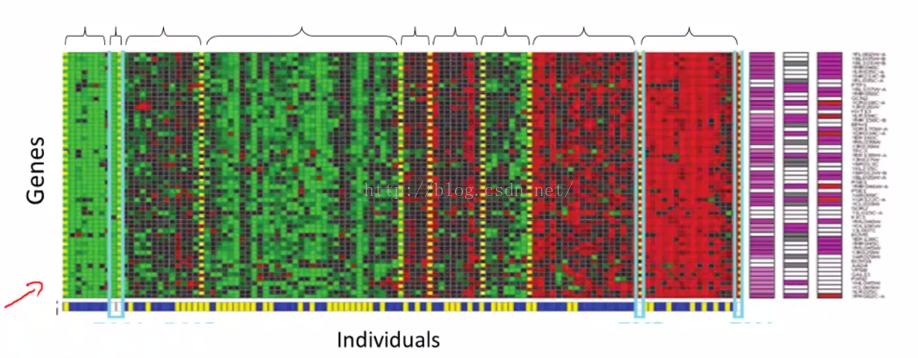
图2-5
无监督学习或聚类算法在其他领域也有着大量的应用:
比如组织大型的计算机集群,管理大型数据中心,试图找出哪些机器趋向于协同工作,如果把这些机器放在一起,你就可以让你的数据中心更高效地工作。见图2-6左上角。
比如用于社交网络的分析,如果可以得知哪些朋友你用email联系的最多或者知道你的Facebook好友或者你Google+里的朋友, 知道了这些之后,我们就可以自动识别哪些是很要好的朋友组,哪些仅仅是互相认识的朋友组。见图2-6右上角。
还有在市场分割中的应用,许多公司拥有庞大的客户信息数据库, 那么给你一个 客户数据集,能否自动找出不同的市场分割,并自动将你的客户分到不同的细分市场中,从而有助于在不同的细分市场中进行更有效的销售。这也是无监督学习,我们现在有这些客户数据,但我们预先并不知道有哪些细分市场,而且对于我们数据集的某个客户 我们也不能预先知道谁属于细分市场一,谁又属于细分市场二等等,但我们必须让这个算法自己去从数据中发现这一切。 见图2-6左下角。
最后,事实上无监督学习也被用于 天文数据分析,通过这些聚类算法,我们发现了许多惊人的、有趣的以及实用的关于星系是如何诞生的理论。见图2-6右下角。
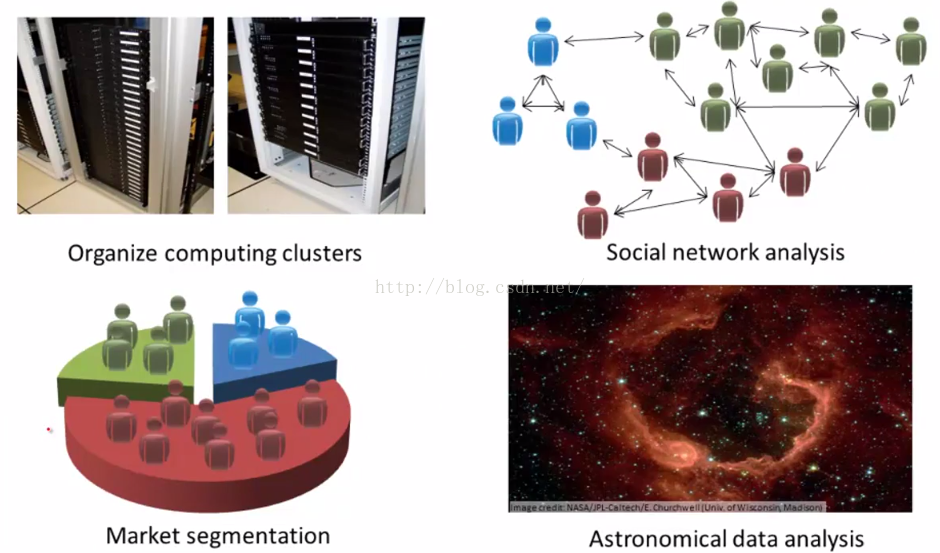
图2-6
笔记会一直更新!同时欢迎大牛批评指正!!














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









