







 本文详细介绍PowerBI在数据获取、清洗、建模及可视化方面的应用技巧。覆盖PowerPivot、PowerQuery等工具介绍,以及M函数、DAX公式的使用方法。通过实际案例帮助读者掌握PowerBI的数据分析全流程。
本文详细介绍PowerBI在数据获取、清洗、建模及可视化方面的应用技巧。覆盖PowerPivot、PowerQuery等工具介绍,以及M函数、DAX公式的使用方法。通过实际案例帮助读者掌握PowerBI的数据分析全流程。
通过动手实践一些教程,总结一些经验。
PowerBI常用工具:PowerPivot、PowerQuery
一、数据获取-PoweBI 支持从多种数据源导入数据
1、自本地获取数据(本地文件更新,模型数据也会更新)
- 自本地文件夹
- 自本地文件
- Excel、 SQL Server、 Access
- SAP、 Oracle、 MySQL、 DB2
2、自Web抓取数据
二、数据清洗
1、提升/拉低标题
- 在 Excel 中第一行为标题行,从第二行开始才是数据,但在 PQ 中,从第一行开始就需要是数据记录,标题在数据之上
- 点击「转换」的「将第一行作为标题」or「将标题作为第一行」
2、更改数据类型
- 后期数据建模和可视化过程中,很有可能会出现一些意想不到的错误,最后发现是数据类型设置的不对,所以一开始就养成设置数据类型的好习惯
3、删除错误(Error)/空值(null)
- 数据导入后,有可能出现错误(Error)或者空值(null)
- 「删除错误」、「替换错误」、「取消勾选(null)」
4、删除重复项
- 选中需要删重的列,右键选择「删除重复项」
5、填充
- 在 Excel 数据中经常会见到合并单元格的情况,导入后就变成了空值
- 「转换」->「填充」->「向下」
6、合并列
- 选择需要合并的列,然后在「转换」中找到”合并列“,弹出合并列窗口
7、拆分
- 拆分相当于是合并列的反动作,不过功能更丰富,可以选着按字符数,也可以选择按分隔符,如果列中包含多个分隔符,还可以选择按哪个位置的分隔符来拆分
- 「转换」->「拆分列」
8、分组
- 相当于 Excel 中的分类汇总功能
- 「转换」->「分组依据」
9、提取
- PQ 的提取功能可以按照长度、首字符、尾字符、范围等来提取
10、行列转置
- 数据处理有的时候需要行列互相转换一下
- 「转换」->「将标题作为第一行」->「转置」
11、行列操作
- 「选择行/列」、「删除行/列」、「保留行/列」
12、逆透视列
- 由于数据分析的需要,我们经常要将二维表变为一维表,之前在 Excel 中需要很多操作步骤才能完成,而通过逆透视功能,可以一键降为一维表,多列属性表转为一维表【属性】+【值】
- 「转换」->「逆透视其他列」
注:
| 一维表 | 二维表 | ||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 概念 | 每一个字段都是独立参数,如姓名、科目、分数 | 字段非独立字段,如数学、英语、语文是属于科目维度,不是独立字段 | |||||||||||||||||||||||||||||||||||||||||
| 优点 | 一维表最适合透视、数据分析的数据存储结构 | 二维表用于展示数据更直观 | |||||||||||||||||||||||||||||||||||||||||
|
| ||||||||||||||||||||||||||||||||||||||||||
| 转换 方式 | 一维表转二维表:
| 二维表转一维表:
| |||||||||||||||||||||||||||||||||||||||||
| 总结 | 数据录入建议都采用一维表 数据分析人员建议使用一维表,无论是表格还是数据库计算都简单方便 对外展示建议使用二维表 | ||||||||||||||||||||||||||||||||||||||||||
13、透视列
- 做分析需要一维表,而为了展现的需要,常常还要把一维表变成二维表,也就是 Excel 中的数据透视,在 PQ 中同样可以一键透视,比如把刚才的一维表变成原样,聚合方式选择“不要聚合”。
三、数据丰富
做数据分析的时候还经常需要在原有数据的基础上增加一些辅助数据,比如加入新列、新行,或者从其他表中添加进来更多维度的数据,这些就是数据丰富的过程。
1、添加列
Power Query 中添加列有四种形式,重复列、索引列、条件列、自定义列:
- 添加重复列:重复列就是把选中的列复制一列,以便对该列的数据进行处理而不损坏原有列的数据
- 添加索引列:索引列就是为每行增加个序号,记录每一行所在的位置,可以从 0 或者 1 开始
- 添加条件列:添加一列根据指定条件从其他列计算的数据,打开窗口看看,其实就是 if 函数
- 添加自定义列:自定义列就是用 M 函数生成新的一列
2、追加查询
追加查询是在现有记录的基础上,在下边添加新的行数据,是一种纵向合并,比如有两个表格式相同,需要合并为一个表,点击“追加查询”
3、合并查询
如果说追加查询是纵向合并,那么合并查询就是横向合并,相当于 Excel 的 VLOOKUP 功能,就是匹配其他表格中的数据,不过 PQ 中的合并查询要比 VLOOKUP 功能强大的多,并且操作也更简单。
四、M函数
简单的操作通过鼠标点击,有些复杂的操作必须借助 M 函数,M 函数更加灵活,简洁高效。
M 函数基本规范:
- M 函数对大小写敏感,每一个字母必须按函数规范书写,第一个字母都是大写
- 表被称为 Table,每行的内容是一个 Record,每列的内容是一个 List
- 行标用大括号{ },比如取第一行的内容: =表{0} //PQ 的第一行从 0 开始
- 列标用中括号[ ],比如取自定义列的内容: =表[自定义]
- 取第一行自定义列的内容: =表{0}[自定义
常用的 M 函数:
• 聚合函数:
求和: List.Sum()
求最小值: List.Min()
求最大值: List.Max()
求平均值: List.Average()
• 文本函数:
求文本长度: Text.Length()
去文本空格: Text.Trim()
取前 n 个字符: Text.Start(文本,n)
取后 n 个字符: Text.End(文本,n)
• 提取数据函数:
从 Excel 表中提取数据: Excel.Workbook()
从 Csv/Txt 中提取数据: Csv.Document()
• 条件函数:
if else then (相当于 Excel 中的 IF)
五、数据建模
基数:
- 基数就是两个连接字段的对应关系,分为多对一、一对一和一对多,一对多和多对一其实是一样的,实际上就是两种关系:
- 多对一(*: 1):这是最常见的类型,代表一个表中的关系列有重复值,而在另一个表中是单一值
- 一对一(1: 1):两个表是一对一的关系,列中的每个值在两个表中都是唯一的
- 具有唯一值的表通常称为“查找表”,而具有多个值的表称为“引用表”。在上述的关系图上,产品明细表上类别手机、平板、电脑都不是唯一的,每个品牌都有这种类型,是个引用表;但类别表上,几种类别都是唯一值,因此这两个表是多对一的关系,类别表也就是查找表
交叉筛选方向:
表示数据筛选的流向,有两种类型:
- 双向:两个表可以互相筛选
- 单向:一个表只能对另一个表筛选,而不能反向
度量值:用DAX公式创建一个虚拟字段的数据值,她不改变源数据,也不改变数据模型
【主页】->【输入数据】->【表名称】:度量值->【加载】,创建度量值表。
上下文:度量值所处的环境,筛选表的行列标签、切片器的选中,都是度量值的上下文
度量值特点:
- 度量值不浪费内存,只有被拖到图表上才执行运算,如果数据量非常大的时候这点非常有利
- 度量值可以循环使用,直接调用之前建立好的度量值,在以后模型中新建度量值的时候,推荐从最简单的度量值开始建
DAX:Data Analysis Expression的缩写,意思是数据分析表达式,DAX公式是用作数据分析的
注:除非特别有必要,不建议用新建列的方式做数据丰富,这样更占用内存,如果想增加一列,可以在源数据上,回到查询编辑器里面增加一列然后上载到数据模型中使用。
DAX参数的基本格式:
- 表名用单引号' '括着 // '日期表'
- 字段用中括号[ ]括着 //[日期]
- 度量值也是用中括号[ ]
- 引用字段始终要包含表名,以和度量值区分开
聚合函数
- SUM
- AVERAGE
- MIN
- MAX
- SUMX
- AVERAGEX
- MINX
- MAXX
- RANKX
- COUNT:计数
- COUNTROWS:计算行数
- DISTINCTCOUNT:计算不重复值的个数
X这几个函数可以循环访问表的每一行,并执行计算,所以也被称为迭代函数。
时间智能函数
- PREVIOUSYEAR/Q/M/D:上一年/季/月/日
- NEXTYEAR/Q/M/D:下一年/季/月/日
- TOTALYTD/QTD/MTD:年/季/月初至今
- SAMEPERIODLASTYEAR:上年同期
- PARALLELPERIOD:上一期
- DATESINPERIOD:指定期间的日期
关于时间智能函数,利用它可以灵活的筛选出一段我们需要的时间区间,做同比、环比、滚动预测、移动平均等数据分析时,都会用到这类函数。
筛选函数
- FILTER:筛选
- ALL:所有值,可以清除筛选
- ALLEXCEPT:保留指定列
- VALUES:返回不重复值
这几个函数,就是典型的DAX查询函数,通过筛选来操纵上下文的范围。
重要且常用函数CALCULATE
CALCULATE(<expression>,<filter1>,<filter2>…)
- 第一个参数是计算表达式,可以执行各种聚合运算
- 从第二个参数开始,是一系列筛选条件,可以为空;如果多个筛选条件,用逗号分隔
- 所有筛选条件的交集形成最终的筛选数据集合
- 根据筛选出的数据集合执行第一个参数的聚合运算并返回运算结果
使用时:
- 筛选条件为空,不影响外部上下文
- 添加限制条件,缩小上下文
- 结合ALL函数,扩大上下文(通常用于做占比分析)
- 重置上下文
FILTER(<table>,<filter>)
- 第一个参数<table>是要筛选的表
- 第二个参数<filter>是筛选条件
- 返回的是一张表,不能单独使用,需要与其他函数结合使用
CALCULATE([产品数量],'产品明细'[品牌]="苹果")
等同于:
CALCULATE([产品数量], FILTER(ALL('产品明细'[品牌]),'产品明细'[品牌]="苹果"))
如果要做更复杂的运算,通过简单的布尔表达式根本无法实现,必须借助FILTER。
EARLIER(<column>, <number>)
- 第一个参数是列名
- 第二个参数一般可省略
- EARLIER 函数提取本行对应的该列的值,实际上就是提取本行和参数列交叉的单元格
六、可视化
1、柱形图
- 堆积柱形图
- 簇状柱形图
- 百分比堆积柱形图
| 柱形图 | 堆积柱形图 | 簇状柱形图 | 百分比堆积柱形图 |
|---|---|---|---|
| 特征 |
|
|
|
| 样式 | 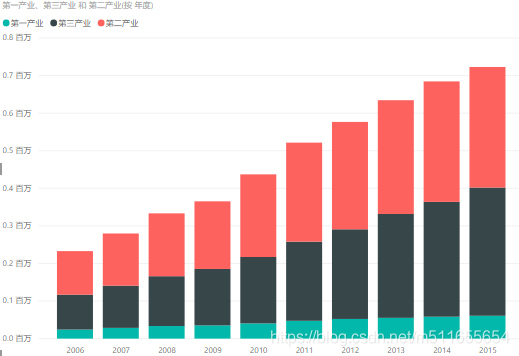 | 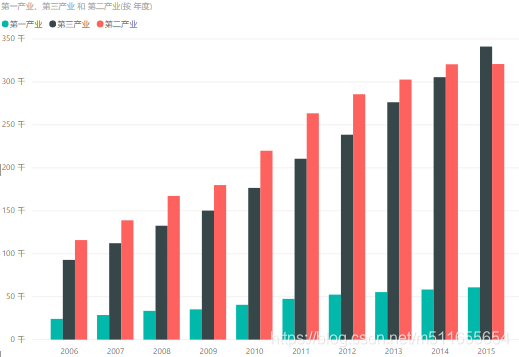 | 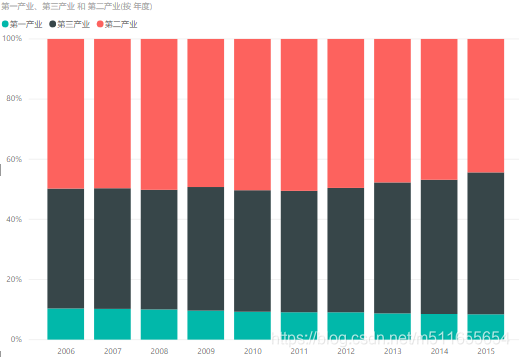 |
一个合格的柱形图:纵横轴清晰、有图例、有数据单位、和图表呼应的标题,养眼的色彩搭配。
2、树状图(矩形树图)
- 单层树状图
- 双层树状图
树状图的使用场景:
- 要显示大量的分层数据
- 条形图不能有效地处理大量值
- 要显示每个部分与整体之间的比例
- 要显示层次结构中指标在各个类别层次的分布的模式
- 要使用大小和颜色编码显示属性
- 要发现模式、离群值、最重要因素和异常
- 相比条形图、折线图,没有任何空白区域,空间利用率高
3、地图
- 气泡地图-Bubble Map
- 着色地图-Filled Map
- ArcGIS Map
七、图表钻取交互
查看可视化图表的时候,我们可能想深入了解某个视觉对象的更详细信息,或者进行更细粒度的分析,比如看到2017年的总体数据,同时想知道每个季度甚至每个月的数据,通过PowerBI的钻取功能,可以点击鼠标轻松实现。其实只要是数据结构有层级关系,无论是什么类型,都可以进行钻取操作。(钻取日期时间、地理位置)
钻取到下级层级的数据有两种方式:
- 通过图表右上角的向下箭头“启用深化”,启用“深化”以后,直接点击需要钻取的数据对象
-
使用顶部 Power BI“数据/钻取”选项卡
编辑交互:选中任何一个可视化对象,在 Desktop 中,点击“格式”>“交互”,选择“编辑交互”。
针对现在选中的筛选条件,对每个可视化对象进行设置:
- 如果需要响应该筛选,则选择“筛选”图标
- 如果不希望被筛选,则选择“不起作用”图标
- "突出显示"与上面的筛选功能相比,最大的优点就是不仅被筛选出来,还可以保留其余数据点的上下文

















 9126
9126

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









