







 本文利用Python的Jupyter Notebook,对不同性别与受教育程度对象的幸福指数数据进行多因素方差分析。先查看、转换数据,进行正态性和方差齐性检验,判断交互作用,再进行多因素方差分析和事后比较。结果表明性别对幸福指数无影响,教育有显著影响,且两者存在交互作用。
本文利用Python的Jupyter Notebook,对不同性别与受教育程度对象的幸福指数数据进行多因素方差分析。先查看、转换数据,进行正态性和方差齐性检验,判断交互作用,再进行多因素方差分析和事后比较。结果表明性别对幸福指数无影响,教育有显著影响,且两者存在交互作用。
1. 前言
背景:表格为随机挑选的不同性别与受教育程度的对象的幸福指数数据,
目的:现要求分析幸福指数是否受不同的性别和受教育程度影响。
分析方法:两个自变量是分类变量,因变量是连续变量,所以选择多因素方差分析。
方差分析需要满足的条件:
- 1.各样本须是相互独立的随机样本;
- 2.各样本来自正态分布总体;
- 3.各样本方差齐性。
显著性水平:选取为0.05
工具:Jupyter Notebook(Python 3.8)
2. Python
数据查看
data = [['Male', '高中及以下', 63.0],
['Male', '高中及以下', 64.0],
['Male', '高中及以下', 60.0],
['Male', '高中及以下', 63.0],
['Male', '高中及以下', 66.0],
['Male', '高中及以下', 65.0],
['Male', '高中及以下', 61.0],
['Male', '高中及以下', 62.0],
['Male', '高中及以下', 68.0],
['Male', '大学本科', 66.5],
['Male', '大学本科', 67.0],
['Male', '大学本科', 69.5],
['Male', '大学本科', 70.0],
['Male', '大学本科', 69.0],
['Male', '大学本科', 71.5],
['Male', '大学本科', 67.0],
['Male', '大学本科', 68.5],
['Male', '大学本科', 63.5],
['Male', '研究生及以上', 88.0],
['Male', '研究生及以上', 89.0],
['Male', '研究生及以上', 86.0],
['Male', '研究生及以上', 92.0],
['Male', '研究生及以上', 90.0],
['Male', '研究生及以上', 84.0],
['Male', '研究生及以上', 91.0],
['Male', '研究生及以上', 87.0],
['Male', '研究生及以上', 88.0],
['Male', '研究生及以上', 85.0],
['Female', '高中及以下', 65.0],
['Female', '高中及以下', 66.0],
['Female', '高中及以下', 61.0],
['Female', '高中及以下', 64.0],
['Female', '高中及以下', 69.0],
['Female', '高中及以下', 70.0],
['Female', '高中及以下', 67.0],
['Female', '高中及以下', 63.0],
['Female', '高中及以下', 63.0],
['Female', '高中及以下', 66.0],
['Female', '大学本科', 70.0],
['Female', '大学本科', 71.0],
['Female', '大学本科', 66.0],
['Female', '大学本科', 69.0],
['Female', '大学本科', 74.0],
['Female', '大学本科', 73.0],
['Female', '大学本科', 72.0],
['Female', '大学本科', 68.0],
['Female', '大学本科', 65.0],
['Female', '大学本科', 64.0],
['Female', '研究生及以上', 82.0],
['Female', '研究生及以上', 83.0],
['Female', '研究生及以上', 88.0],
['Female', '研究生及以上', 91.0],
['Female', '研究生及以上', 90.0],
['Female', '研究生及以上', 86.0],
['Female', '研究生及以上', 84.0],
['Female', '研究生及以上', 80.0],
['Female', '研究生及以上', 85.0],
['Female', '研究生及以上', 76.0]]
df = pd.DataFrame(data, columns = ['gender', 'education', 'Index'])
df.head()
转换
df1 = pd.DataFrame()
data_list = []
for i in df.gender.unique():
for j in df.education.unique():
data = df[(df.gender == i)&(df.education == j)]['Index'].values
data_list.append(data)
df1 = df1.append(pd.DataFrame(data, columns = pd.MultiIndex.from_arrays([[i],[j]])).T)
df1 = df1.T
df1
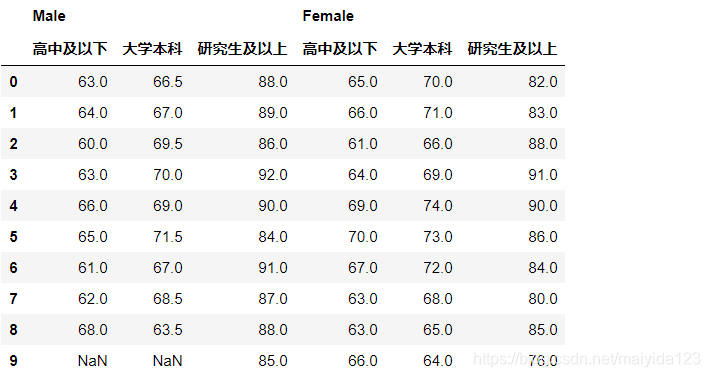
- 转换成更直观的形式,方便后续的操作
各组数量统计
# 查看各组数量分布
df1.count().to_frame()
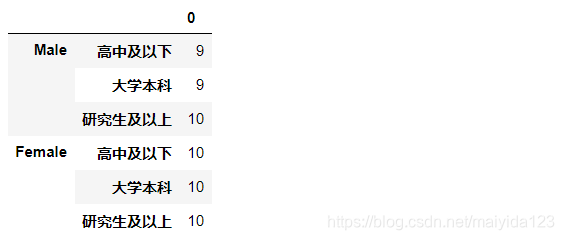
- 各组数量存在差异
箱线图查看异常值
plt.figure(figsize = (12,8))
sns.boxplot(x = 'gender', y = 'Index', data = df, hue = 'education')
plt.show()
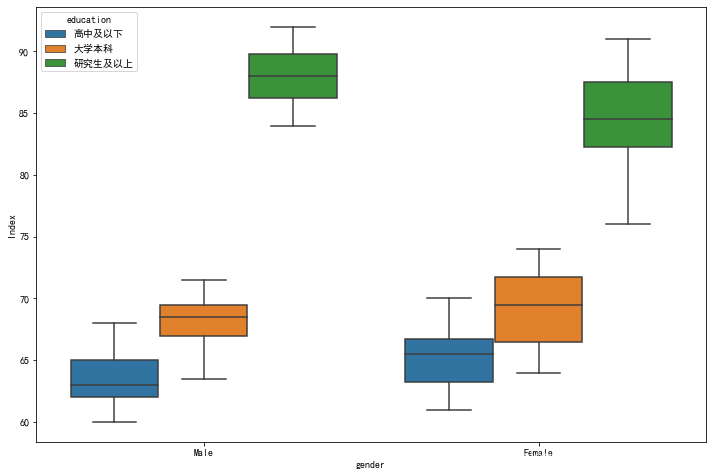
- 各组数据均没有异常值
正态性检验
# Shapiro-Wilk 检验
sw_test_res = pd.DataFrame()
for i in df1.columns:
statistic,pvalue = stats.shapiro(df1[i].dropna())
sw_test_res[i] = [statistic, pvalue]
sw_test_res.index = ['statistic', 'p_value']
sw_test_res.T.round(3)
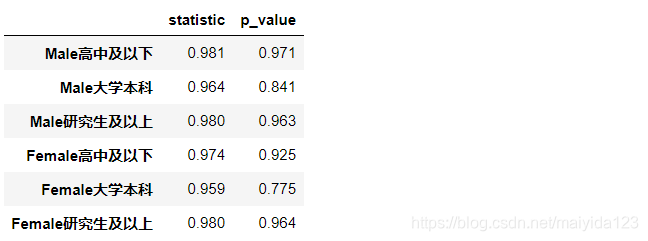
- 以上各组p值均大于0.05,满足正态分布
方差齐性检验
# levene test
print('基于中位数的levene test P值:', stats.levene(*data_list, center='median').pvalue)
- P值为0.286,大于0.05,即任一分类都具有等方差性
判断交互作用
计算平均值
df_mean = df1.mean().to_frame().unstack().round(1)
df_mean.columns = ['大学本科', '研究生及以上', '高中及以下']
df_mean = df_mean[['高中及以下', '大学本科', '研究生及以上']]
df_mean

绘制交互图
# 定义一个绘图函数
def draw_pics(data, feature):
fig, ax = plt.subplots(figsize=(8, 6))
for i in data.index:
ax.plot(data.columns, data.loc[i,], label = i, marker='o')
ax.legend()
ax.set_title("幸福指数平均值")
ax.set_xlabel(feature, fontdict={'fontsize': 14})
ax.set_ylabel("平均值", fontdict={'fontsize': 14})
plt.show()
# 绘制不同的性别在不同的教育程度下的均值变化
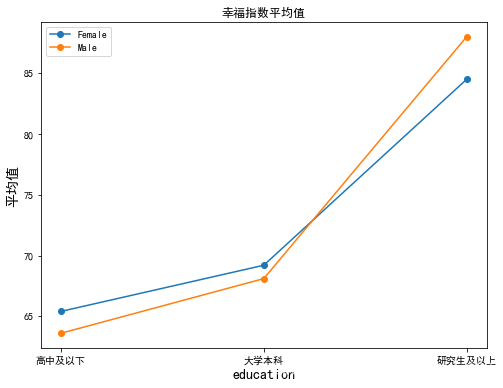
draw_pics(data_mean, 'education')
# 绘制不同的教育程度在不同的性别下的均值变化
draw_pics(data_mean.T, 'gender')
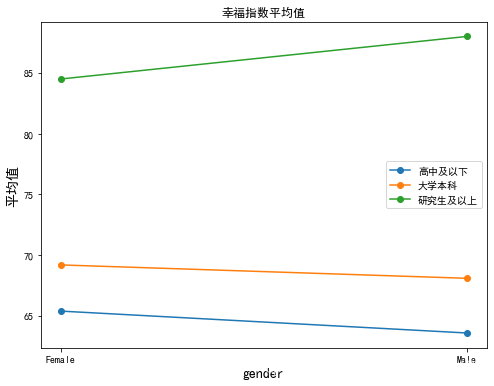
- 可以看到受教育程度与性别在对幸福指数的影响上可能存在交互作用。
- 男性和女性的幸福指数都随受教育程度的增加而增加。但两者的增加趋势不同。男性的受教育程度在高中及以下、大学本科时幸福指数比女性低;但当男性的受教育程度达到研究生及以上时,其幸福指数比女性高。可见,在提高受教育程度增加幸福指数的过程中,男性比女性获益更大。
多因素方差分析
将交互项放入方差分析
anova = smf.ols('Index ~ C(gender) + C(education) + C(gender)*C(education)',data = df).fit()
sm.stats.anova_lm(anova, typ=1)

结果显示:
- 性别P = 0.404大于0.05,表明性别对幸福指数没有影响
- 教育P < 0.001,表明教育对于幸福指数有显著影响
- 交互项具F(2,52)=4.148,P= 0.021,有统计学意义,表明性别和受教育程度在对幸福指数的影响上存在交互作用
事后比较
不同教育程度的事后比较
# 事后多重比较
sm.stats.multicomp.pairwise_tukeyhsd(groups = df.education, endog=df.Index).summary()
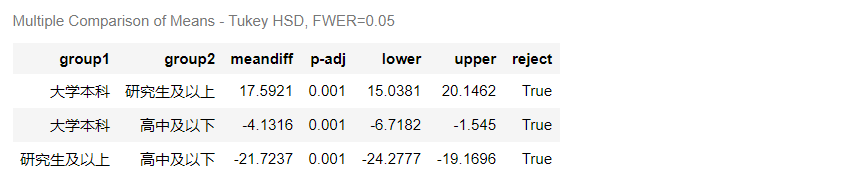
由事后比较可得:
- 大学本科学历 的幸福指数比 高中及以下学历 的人高4.13(95%CI:1.55-6.72),P=0.001;
- 研究生及以上学历 的幸福指数比 高中及以下学历 的人高21.72(95%CI:19.17-24.28),P<0.001;
- 研究生及以上学历 的幸福指数比 大学本科学历 的人高17.59(95%CI:15.04-20.15),P<0.001。
单独效应的解释
性别的单独效应
# 性别的单独效应
gender_pc_df = pd.DataFrame()
for i in df.gender.unique():
pc = sm.stats.multicomp.pairwise_tukeyhsd(groups = df.query("gender == @i").education,
endog=df.query("gender == @i").Index).summary()
pc_df = pd.DataFrame(pc, index = [i] * (df.education.nunique() + 1), )[1:]
gender_pc_df = gender_pc_df.append(pc_df)
gender_pc_df.columns = ['group1', 'group2', 'meandiff', 'p-adj', 'lower', 'upper', 'reject']
gender_pc_df
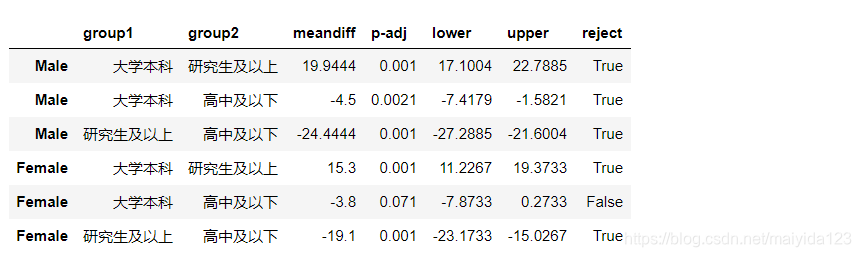
从结果中可得:
-
男性中:
- 高中及以下学历 的幸福指数评分比 大学本科学历 的低4.50(95%CI:1.58 - 7.42),P = 0.0021;
- 高中及以下学历 的幸福指数评分比 研究生及以上学历 的低24.44(95%CI:21.60 - 27.29),P = 0.001。
- 大学本科学历 的幸福指数评分比 研究生及以上学历 的低19.94(95%CI:17.10 - 22.79),P = 0.001。
-
女性中:
- 高中及以下学历 的幸福指数评分比 大学本科学历 没有显著性差异,P = 0.071;
- 高中及以下学历 比 研究生及以上学历 的低19.10(95%CI:15.02 - 23.17),P = 0.001。
- 大学本科学历 的幸福指数评分比 研究生及以上学历 的低15.30(95%CI:11.23 - 19.37),P = 0.001。
结论
- 1.采用因素方差分析性别和受教育程度对幸福指数的影响,显著性水平选取为P = 0.05。满足方差分析前提条件:用分箱图检验没有异常值,用Shapiro-Wilk检验均满足正态性,用Levene方差齐性检验均满足等方差性(P = 0.286)。
- 2.本研究中,性别对幸福指数没有影响(P = 0.404),教育对于幸福指数有显著影响(P < 0.001),性别和受教育程度在对幸福指数的影响上存在交互作用(P = 0.021)。
- 3.不同性别中不同教育水平对于幸福指数的影响:
男性中:
- 高中及以下学历 的幸福指数评分比 大学本科学历 的低4.50(95%CI:1.58 - 7.42),P = 0.0021;
- 高中及以下学历 的幸福指数评分比 研究生及以上学历 的低24.44(95%CI:21.60 - 27.29),P = 0.001。
- 大学本科学历 的幸福指数评分比 研究生及以上学历 的低19.94(95%CI:17.10 - 22.79),P = 0.001。
女性中:
- 高中及以下学历 的幸福指数评分比 大学本科学历 没有显著性差异,P = 0.071;
- 高中及以下学历 比 研究生及以上学历 的低19.10(95%CI:15.02 - 23.17),P = 0.001。
- 大学本科学历 的幸福指数评分比 研究生及以上学历 的低15.30(95%CI:11.23 - 19.37),P = 0.001。
参考链接:两因素方差分析-SPSS教程点击链接

















 1548
1548

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









