







课程地址:https://class.coursera.org/ntumlone-001/class
课件讲义:http://download.csdn.net/download/malele4th/10212756
注明:文中图片来自《机器学习技法》课程和部分博客
建议:建议读者学习林轩田老师原课程,本文对原课程有自己的改动和理解
Lecture 5 kernel logistic regression
上节课我们主要介绍了Soft-Margin SVM,即如果允许有分类错误的点存在,那么在原来的Hard-Margin SVM中添加新的惩罚因子C,修正原来的公式,得到新的αn值。最终的到的αn有个上界,上界就是C。Soft-Margin SVM权衡了large-margin和error point之前的关系,目的是在尽可能犯更少错误的前提下,得到最大分类边界。本节课将把Soft-Margin SVM和我们之前介绍的Logistic Regression联系起来,研究如何使用kernel技巧来解决更多的问题。
目录
1 Soft-Margin SVM as Regularized Model
先复习一下我们已经介绍过的内容,我们最早开始讲了Hard-Margin Primal的数学表达式,然后推导了Hard-Margin Dual形式。后来,为了允许有错误点的存在(或者noise),也为了避免模型过于复杂化,造成过拟合,我们建立了Soft-Margin Primal的数学表达式,并引入了新的参数C作为权衡因子,然后也推导了其Soft-Margin Dual形式。因为Soft-Margin Dual SVM更加灵活、便于调整参数,所以在实际应用中,使用Soft-Margin Dual SVM来解决分类问题的情况更多一些。

Soft-Margin Dual SVM有两个应用非常广泛的工具包,分别是Libsvm和Liblinear。 Libsvm和Liblinear都是国立台湾大学的Chih-Jen Lin博士开发的,Chih-Jen Lin的个人网站为:Welcome to Chih-Jen Lin’s Home Page
下面我们再来回顾一下Soft-Margin SVM的主要内容。我们的出发点是用ξn来表示margin violation (违反),即犯错值的大小,没有犯错对应的ξn=0。然后将有条件问题转化为对偶dual形式,使用QP来得到最佳化的解。

经过这种转换之后,表征犯错误值大小的变量ξn就被消去了,转而由一个max操作代替。

为什么要将把Soft-Margin SVM转换为这种unconstrained form呢?我们再来看一下转换后的形式,其中包含两项,第一项是w的内积,第二项关于y和w,b,z的表达式,似乎有点像一种错误估计err^,则类似这样的形式:


这里提一下,既然unconstrained form SVM与L2 Regularization的形式是一致的,而且L2 Regularization的解法我们之前也介绍过,那么为什么不直接利用这种方法来解决unconstrained form SVM的问题呢?有两个原因。一个是这种无条件的最优化问题无法通过QP解决,即对偶推导和kernel都无法使用;另一个是这种形式中包含的max()项可能造成函数并不是处处可导,这种情况难以用微分方法解决。
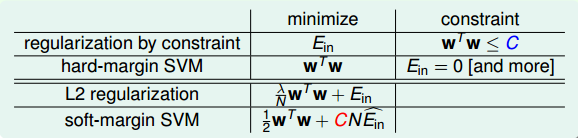
我们在第一节课中就介绍过Hard-Margin SVM与Regularization Model是有关系的。Regularization的目标是最小化Ein,条件是
wTw≤C
w
T
w
≤
C
,而Hard-Margin SVM的目标是最小化
wTw
w
T
w
,条件是Ein=0,即它们的最小化目标和限制条件是相互对调的。对于L2 Regularization来说,条件和最优化问题结合起来,整体形式写成:


C减小,或者
λ
λ
增大,效果是一致的。
Large margin 等同于 regularization,都起到了防止过拟合的作用

建立了Regularization和Soft-Margin SVM的关系,接下来我们将尝试看看是否能把SVM作为一个regularized的模型进行扩展,来解决其它一些问题。
2 SVM vs Logistic Regression
上一小节,我们已经把Soft-Margin SVM转换成无条件的形式:
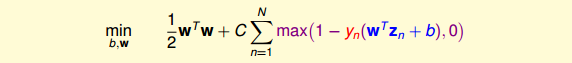



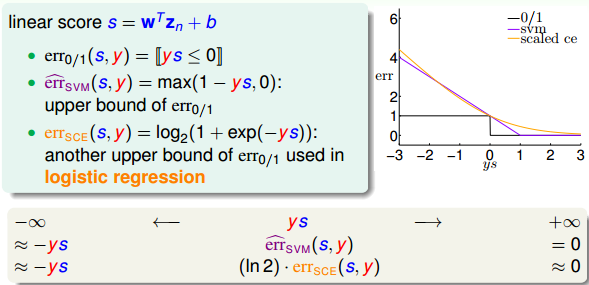

至此,可以看出,求解regularized logistic regression的问题等同于求解soft-margin SVM的问题。反过来,如果我们求解了一个soft-margin SVM的问题,那这个解能否直接为regularized logistic regression所用?来预测结果是正类的几率是多少,就像regularized logistic regression做的一样。我们下一小节将来解答这个问题。
3 SVM for soft Binary Classification
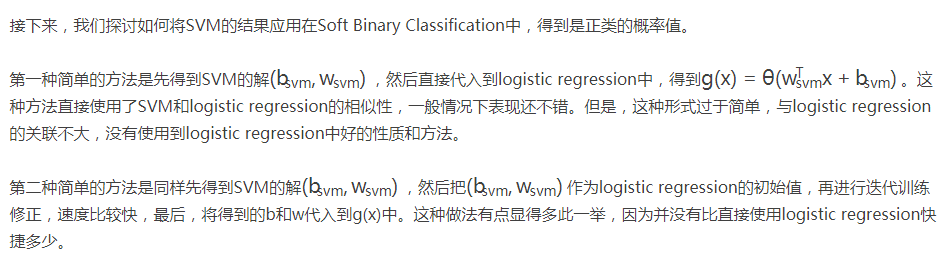



那么,新的logistic regression表达式为
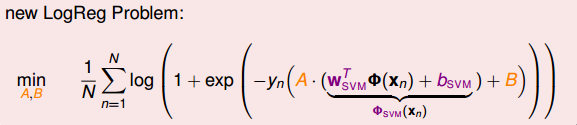
这个表达式看上去很复杂,其实其中的(bsvm,Wsvm)已经在SVM中解出来了,实际上的未知参数只有A和B两个。归纳一下,这种Probabilistic SVM的做法分为三个步骤:

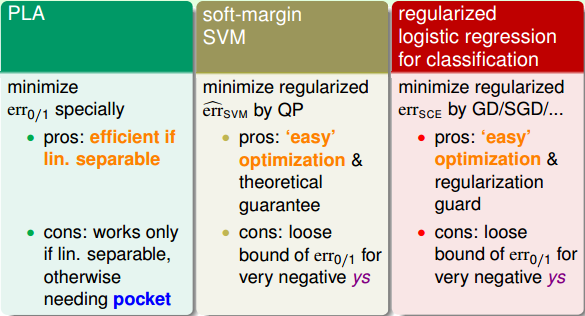
这种soft binary classifier方法得到的结果跟直接使用SVM classifier得到的结果可能不一样,这是因为我们引入了系数A和B。一般来说,soft binary classifier效果更好。至于logistic regression的解法,可以选择GD、SGD等等。
4 Kernel logistic regression




5 总结
本节课主要介绍了Kernel Logistic Regression。首先把Soft-Margin SVM解释成Regularized Model,建立二者之间的联系,其实Soft-Margin SVM就是一个L2-regularization,对应着hinge error messure。然后利用它们之间的相似性,讨论了如何利用SVM的解来得到Soft Binary Classification。方法是先得到SVM的解,再在logistic regression中引入参数A和B,迭代训练,得到最佳解。最后介绍了Kernel Logistic Regression,证明L2-regularized logistic regression中,最佳解w∗一定可以写成z的线性组合形式,从而可以将kernel引入logistic regression中,使用kernel思想在z空间直接求解L2-regularized logistic regression问题。















 2236
2236

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









