







台湾国立大学机器学习基石.听课笔记(第十五讲)
:validation
1,模型选择的问题(Model selection problem)
我们在前面的10几讲中已经学到很多算法的模型,那我们在给出一个实际问题后,怎么选择模型呢?

在实际情况中,很容易出现过拟合(overfitting)和计算量过大的问题,
所以如何选择A_m和E_in是我们现在要解决的问题。

我们就想出找出一个D_(test),在测试集中找出最好的E_(test),但是D_(test)我们在做实验时真的能找出么?
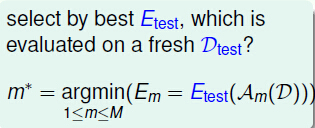

正是因为E_(in)是从A_m的训练集得出的,A_m和E_(in)的测试集和训练集都来自于同一个训练集,所以算出的结果不是很好。
而E_(test)来自训练集D_(test),A_m和D_(test)是来自于不同的集合,但是D_(test)的寻找依然是一个问题,那我们能不能择中的选取一个方法呢?

2,Validation(验证)
那D_(val)到底是是怎样的,该如何选取呢??

那我们能不能把E_(g^-_m)与E_(g)联系起来呢?
先来想想他们之间的区别,g^-_m的训练集是D_(test),测试集是D_(val);而E_(g)的训练集和测试集都是D,但是D与D_(test)、D_(val)都是独立同分布,那我求出来的
E_(out)(g^-_m)应该与E_(out)(g)有一定的关系:

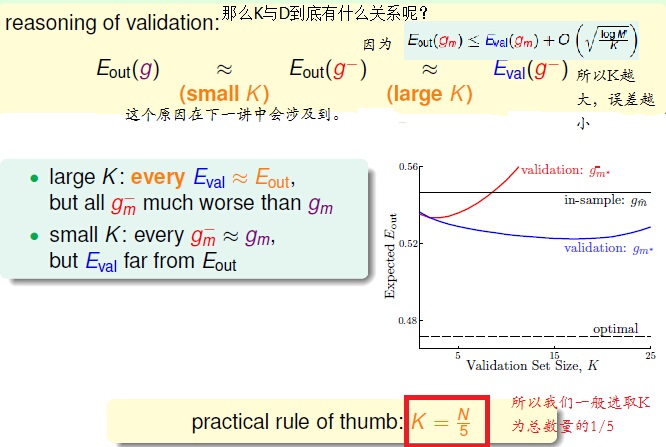
各个E之间的关系根据K的不同,我们绘制一下图片:

那么我们如何选取K呢?


那么E_(looce)(H,A)与E_(out)(g)有啥关系呢?
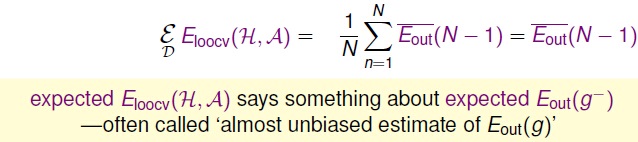
我们用数字识别的例子来举例说明,当:

所以我们可以用E_(loocv)(H,A)可以近视E_in.
4,V—FoldCross Validation
我们刚才说了Leave-one-out Cross Validation的优点,那他在实际应用中他有什么缺陷呢?
第一点, 计算复杂度大大增加;
第二点, 稳定性
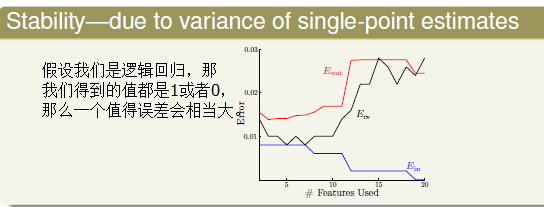

那么我们要怎么改进呢?

所以我们一般选取:

Validation的优点是:


总结
















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









