






Titanic: Machine Learning from Disaster
目录
1数据集
train.csv :(891人)
test.csv :(418人)
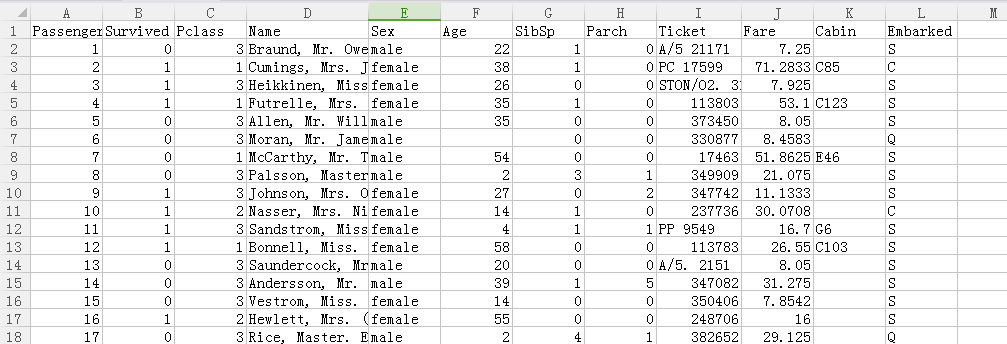
12列数据(有的乘客信息不全)
- 1 passengerId (1~891) 训练集样本数
- 2 Survived (0、1) 标签值
- 3 Pclass (1、2、3) 客舱等级(重要指标)
- 4 Name(姓名:可以提取出很多信息,名门、王氏家族等)
- 5 Sex(female、male)(重要指标)
- 6 Age(0~100)(重要指标)
- 7 SibSp(旁系:兄弟姐妹、夫妻)(0~10)
- 8 Parch(直系:父母、子女)(0~10)
- 9 Ticket(票编号)(比较乱,有纯数字,有的带字母)
- 10 Fare(乘客票价)
- 11 Cabin(客舱编号)
- 12 Embarked(上船港口号)
2数据总览
import re
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
warnings.filterwarnings('ignore')
%matplotlib inline观察前几行的源数据:
train_data = pd.read_csv('data/train.csv')
test_data = pd.read_csv('data/test.csv')
sns.set_style('whitegrid')
train_data.head()
test_data.head()
数据信息总览:
train_data.info()
print()
print("-" * 60)
print()
test_data.info()<class 'pandas.core.frame.DataFrame'>
RangeIndex: 891 entries, 0 to 890
Data columns (total 12 columns):
PassengerId 891 non-null int64
Survived 891 non-null int64
Pclass 891 non-null int64
Name 891 non-null object
Sex 891 non-null object
Age 714 non-null float64
SibSp 891 non-null int64
Parch 891 non-null int64
Ticket 891 non-null object
Fare 891 non-null float64
Cabin 204 non-null object
Embarked 889 non-null object
dtypes: float64(2), int64(5), object(5)
memory usage: 83.6+ KB
------------------------------------------------------------
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 418 entries, 0 to 417
Data columns (total 11 columns):
PassengerId 418 non-null int64
Pclass 418 non-null int64
Name 418 non-null object
Sex 418 non-null object
Age 332 non-null float64
SibSp 418 non-null int64
Parch 418 non-null int64
Ticket 418 non-null object
Fare 417 non-null float64
Cabin 91 non-null object
Embarked 418 non-null object
dtypes: float64(2), int64(4), object(5)
memory usage: 36.0+ KB
- 从上面我们可以看出,Age、Cabin、Embarked、Fare几个特征存在缺失值。
绘制存活的比例:
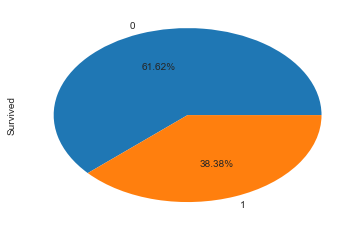
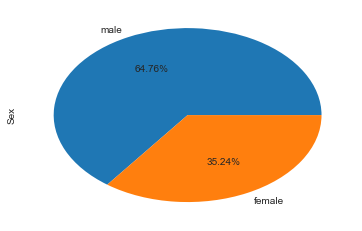
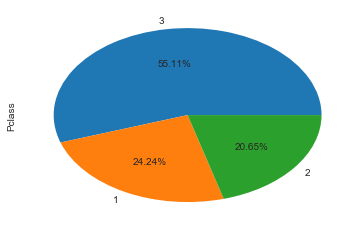
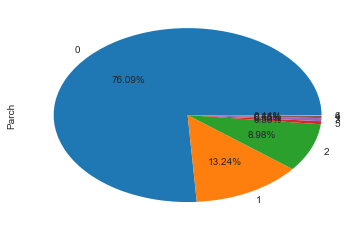
绘制出男女比例、客舱等级比例、父母子女比例等
3缺失值的处理方法
对数据进行分析的时候要注意其中是否有缺失值。
- 从上面我们可以看出,Age、Cabin、Embarked、Fare几个特征存在缺失值。
一些机器学习算法能够处理缺失值,比如神经网络,一些则不能。对于缺失值,一般有以下几种处理方法:
(1)如果数据集很多,但有很少的缺失值,可以删掉带缺失值的行;
(2)如果该属性相对学习来说不是很重要,可以对缺失值赋均值或者众数。
比如在哪儿上船Embarked这一属性(共有三个上船地点),缺失俩值,可以用众数赋值
train_data.Embarked[train_data.Embarked.isnull()] = train_data.Embarked.dropna().mode().values(3)对于标称属性,可以赋一个代表缺失的值,比如‘U0’。因为缺失本身也可能代表着一些隐含信息。比如船舱号Cabin这一属性,缺失可能代表并没有船舱。
#replace missing value with U0
train_data['Cabin'] = train_data.Cabin.fillna('U0') # train_data.Cabin[train_data.Cabin.isnull()]='U0'(4)使用回归随机森林等模型来预测缺失属性的值。
因为Age在该数据集里是一个相当重要的特征(先对Age进行分析即可得知),所以保证一定的缺失值填充准确率是非常重要的,对结果也会产生较大影响。
一般情况下,会使用数据完整的条目作为模型的训练集,以此来预测缺失值。对于当前的这个数据,可以使用随机森林来预测也可以使用线性回归预测。这里使用随机森林预测模型,选取数据集中的数值属性作为特征。
(因为sklearn的模型只能处理数值属性,所以这里先仅选取数值特征,但在实际的应用中需要将非数值特征转换为数值特征)
from sklearn.ensemble import RandomForestRegressor
#choose training data to predict age
age_df = train_data[['Age','Survived','Fare', 'Parch', 'SibSp', 'Pclass']]
age_df_notnull = age_df.loc[(train_data['Age'].notnull())]
age_df_isnull = age_df.loc[(train_data['Age'].isnull())]
X = age_df_notnull.values[:,1:]
Y = age_df_notnull.values[:,0]
# use RandomForestRegression to train data
RFR = RandomForestRegressor(n_estimators=1000, n_jobs=-1)
RFR.fit(X,Y)
predictAges = RFR.predict(age_df_isnull.values[:,1:])
train_data.loc[train_data['Age'].isnull(), ['Age']]= predictAges
让我们再来看一下缺失数据处理后的DataFram:
train_data.info()<class 'pandas.core.frame.DataFrame'>
RangeIndex: 891 entries, 0 to 890
Data columns (total 12 columns):
PassengerId 891 non-null int64
Survived 891 non-null int64
Pclass 891 non-null int64
Name 891 non-null object
Sex 891 non-null object
Age 891 non-null float64
SibSp 891 non-null int64
Parch 891 non-null int64
Ticket 891 non-null object
Fare 891 non-null float64
Cabin 891 non-null object
Embarked 891 non-null object
dtypes: float64(2), int64(5), object(5)
memory usage: 83.6+ KB4分析数据关系
- 每个特征(如年龄、姓名、票价等)与survived(1、0)的关系















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









