







lecture 4:逻辑回归Logistic Regression
目录
1分类和模型表示
先来谈谈二分类问题。课程中先给出了几个例子。
邮件是垃圾邮件还是非垃圾邮件;
网上交易是的欺骗性(Y or N);
肿瘤是恶性的还是良性的。
对于这些问题,我们可以通过输出值y ϵ {0, 1} 来表示。
注意:分类结果是离散值,这是分类的根本特点。
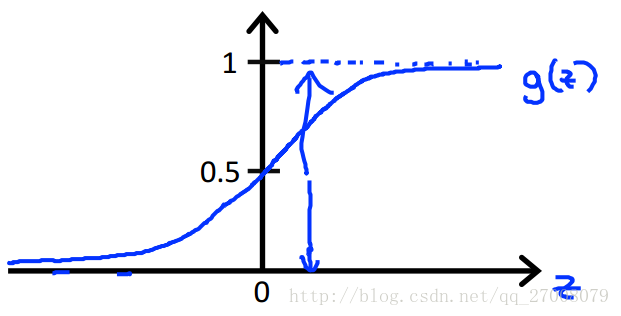
普通的hθ(x)函数存在函数值大于1和小于0的情况(没有意义),于是我们要构造特殊函数使0≤hθ(x)≤1
我们提出了一种新的回归模型:
称之为Logistic function或者sigmoid function


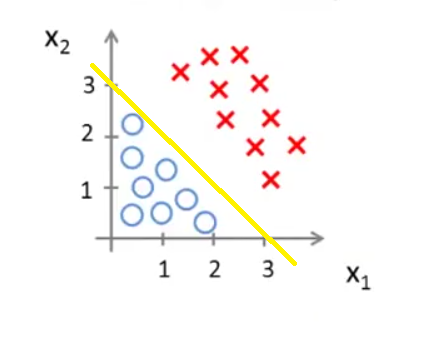
我们可以直观地看出,当(x1,x2)在这条直线的上方,则预测 y=1;当(x1,x2)在这条直线的下方,则预测 y=0。
−x1+x2=3这条直线就是这里的决策边界(Decision Boundary)。它将空间分为两个区域,预测y=0和预测y=1。这条直线并不是数据集本身的属性,而是假设函数(hypothesis)和其参数θ的属性。
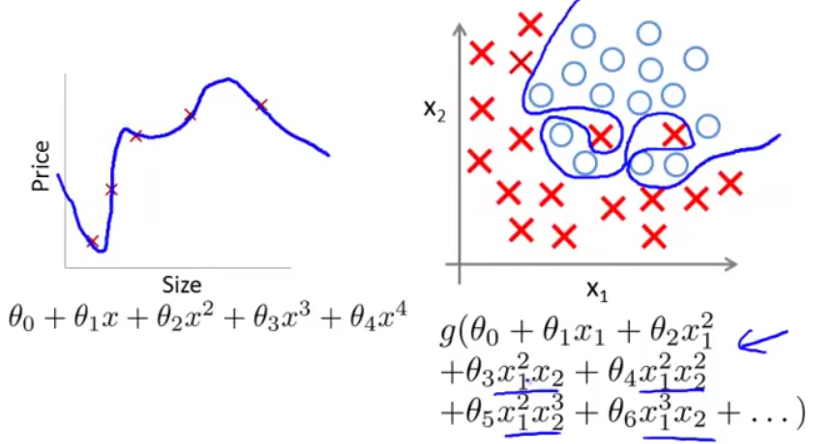
上面的决策边界−x1+x2=3属于线性决策边界,再看一个非线性决策边界的例子。假设训练数据的分布如下图所示,则可用高阶多项式进行拟合。

2逻辑回归
2.1逻辑回归的代价函数的选取

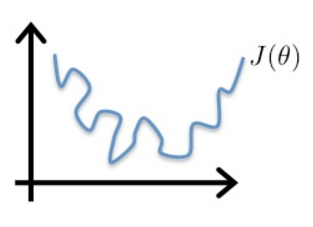
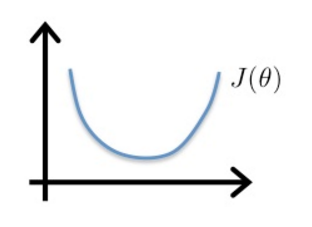
因此,在逻辑回归中,需要另寻一个代价函数,使其是凸函数(单弓形),如下图,这样就可以使用梯度下降法找到全局最小值。
我们选择如下的代价函数来表示单个样本的代价:
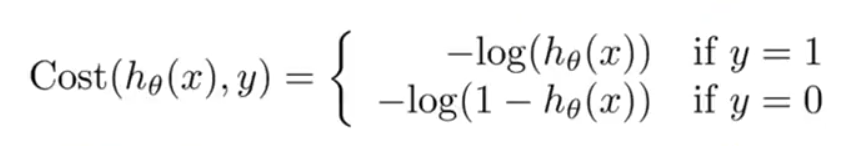
这个函数看起来很复杂。下面我们通过画出它的图像来解释选择它的原因。
1、当y=1,Cost(hθ(x),y) 关于hθ(x)的图像:
注意横坐标为hθ(x),而hθ(x)的取值范围为(0,1),所以图像只取(0,1)段。
我们可以看出,当hθ(x)=1,则假设函数预测结果与事实一致,Cost=0;
当hθ(x)=0,则预测结果与事实不符,Cost=∞,说明要通过一个很大的代价 Cost→∞ 来惩罚学习算法。
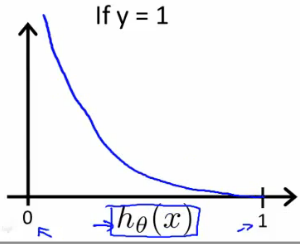
2、当y=1,Cost(hθ(x),y) 关于hθ(x)的图像:
横坐标为hθ(x),而hθ(x)的取值范围为(0,1),所以图像只取(0,1)段。
同理,若y=0,而hθ(x)=1,将通过一个很大的代价 Cost→∞ 来惩罚学习算法。
- 以上说明在求解参数θ时,当选择合适的代价函数(代价函数转化为一个凸函数),我们就可以将问题转化为凸优化问题(convex optimization problem),方便我们求解全局最小值。
简化代价函数

梯度下降法求解参数与线性回归是一样的
3过拟合和正则化
- 欠拟合:高偏差,拟合出的假设函数在训练集上不能很好地拟合数据
- 过拟合:高方差,由于特征变量太多,导致学习到的假设函数太过适合于训练集,导致无法泛化到新的数据样本
泛化能力:指一个假设模型能够应用于新样本(没有出现在训练集)的能力。
这里给出两种规避过拟合的方法:
- 减少特征变量的数量
人工选择保留或舍弃哪些变量,也可以通过模型选择算法自动选择采用哪种特征变量。- 正则化(regularization)
保留所有特征变量,但要减小 θj 的数量级或值。
正则化

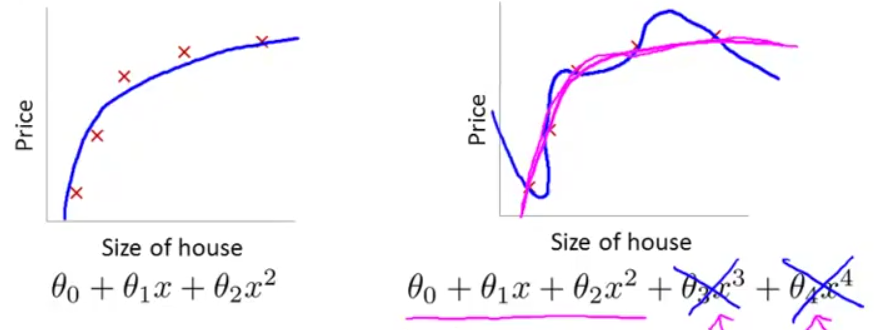

正则化的两个目标:
- ① 更好的拟合训练数据,使假设函数很好的适应训练集
- ② 保持 θ 参数值较小,避免过拟合
正则化参数λ的影:
- ① λ 如果太小,则相当于正则化项没起到作用,无法控制过拟合;
- ② λ如果太大,则除了θ0,其余的参数都会约等于0,相当于去掉了那些项,使hθ(x)=θ0,毫无疑问这会得不偿失地导致欠拟合。
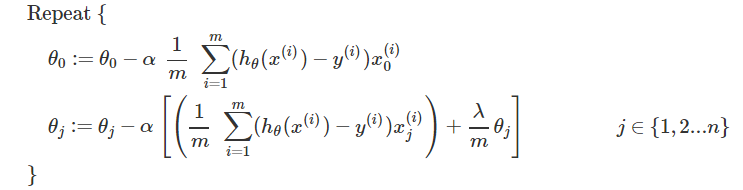















 2671
2671

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









