







lecture 20:sk-learn
目录
1why sklearn?
机器学习的方法包括:
- 监督学习 supervised learning;
- 非监督学习 unsupervised learning;
- 半监督学习 semi-supervised learning;
- 强化学习 reinforcement learning;
- 遗传算法 genetic algorithm.

2sklearn一般使用
2.1选择学习方法
安装完 Sklearn 后,不要直接去用,先了解一下都有什么模型方法,然后选择适当的方法,来达到你的目标。
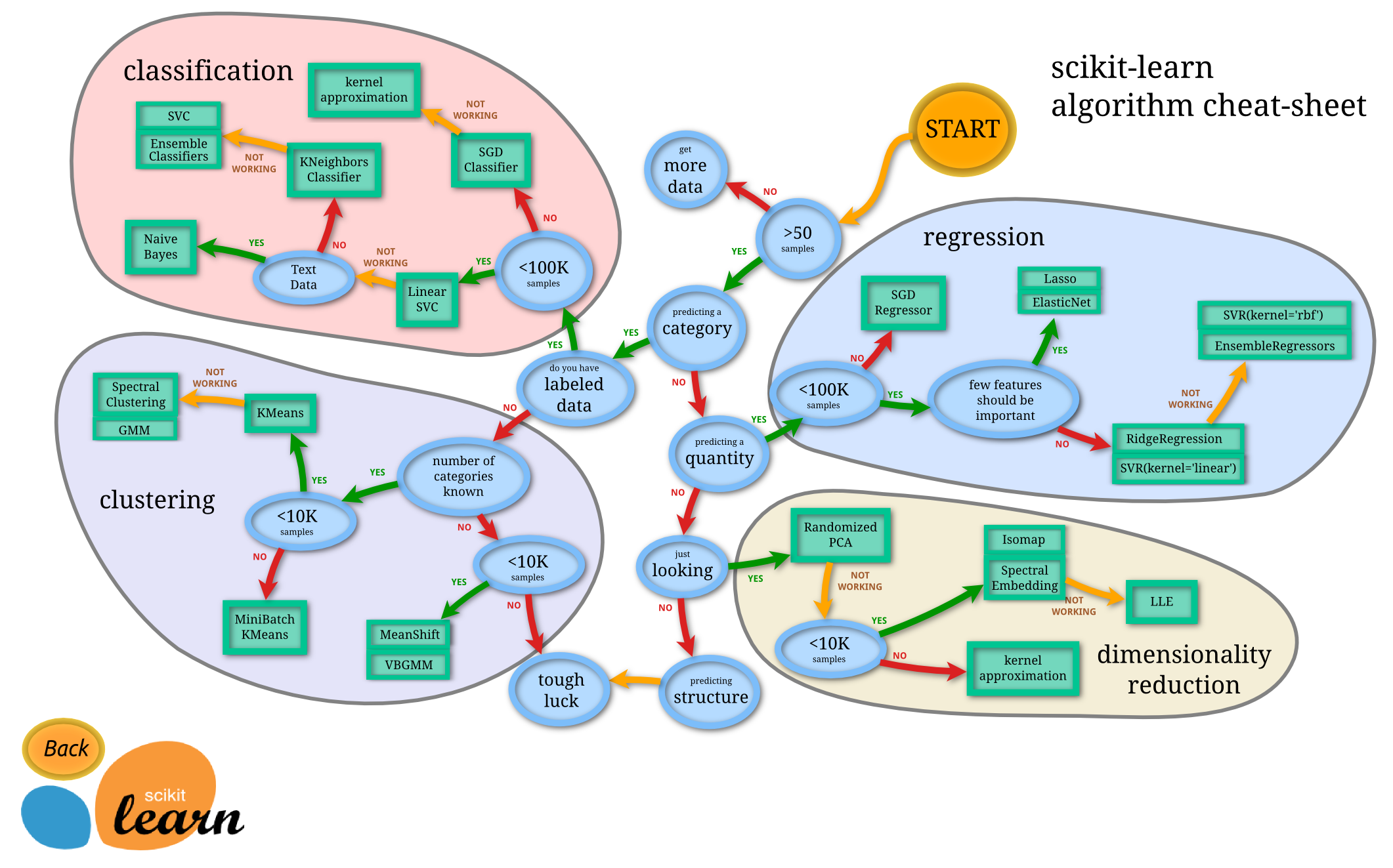
Sklearn官网提供了一个流程图,蓝色圆圈内是判断条件,绿色方框内是可以选择的算法
http://scikit-learn.org/stable/tutorial/machine_learning_map/index.html

2.2通用学习模式
Sklearn 把所有机器学习的模式整合统一起来了,学会了一个模式就可以通吃其他不同类型的学习模式。
例如,分类器,今天用 KNN classifier,就是选择几个临近点,综合它们做个平均来作为预测值。
Sklearn 本身就有很多数据库,可以用来练习。 以 Iris 的数据为例,这种花有四个属性,花瓣的长宽,茎的长宽,根据这些属性把花分为三类。
我们要用 分类器 去把四种类型的花分开。

导入模块、创建数据、建立模型、训练&预测
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
iris = datasets.load_iris()
iris_X = iris.data
iris_y = iris.target
#把数据集分为训练集和测试集,其中 test_size=0.3,即测试集占总数据的 30%
#分开后的数据集,顺序也被打乱,这样更有利于学习模型
X_train, X_test, y_train, y_test = train_test_split(iris_X, iris_y, test_size=0.3)
knn = KNeighborsClassifier()
knn.fit(X_train, y_train)
print(knn.predict(X_test))
print(y_test)2.3sklearn 强大数据库
Sklearn 中的 data sets,很多而且有用,可以用来学习算法模型。
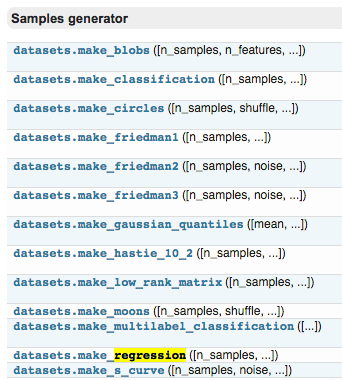
例如,点击进入 boston 房价的数据,可以看到 sample 的总数,属性,以及 label 等信息。
如果是自己生成数据,按照函数的形式,输入 sample,feature,target 的个数等等。
X, y = datasets.make_regression(n_samples=100, n_features=1, n_targets=1, noise=10)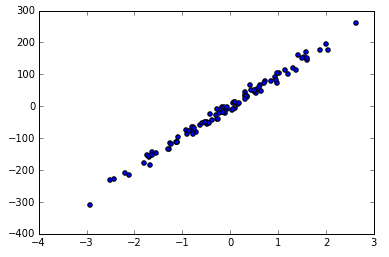
noise 越大的话,点就会越来越离散,例如 noise 由 10 变为 50.
X, y = datasets.make_regression(n_samples=100, n_features=1, n_targets=1, noise=50)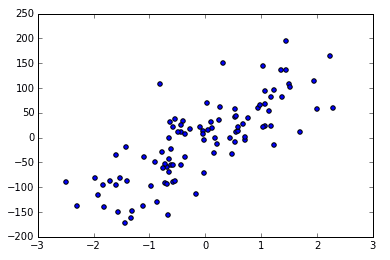
2.4sklearn 常用属性与功能
3高级使用
3.1正则化
由于资料的偏差与跨度会影响机器学习的成效,因此正规化(标准化)数据可以提升机器学习的成效。首先由例子来讲解:


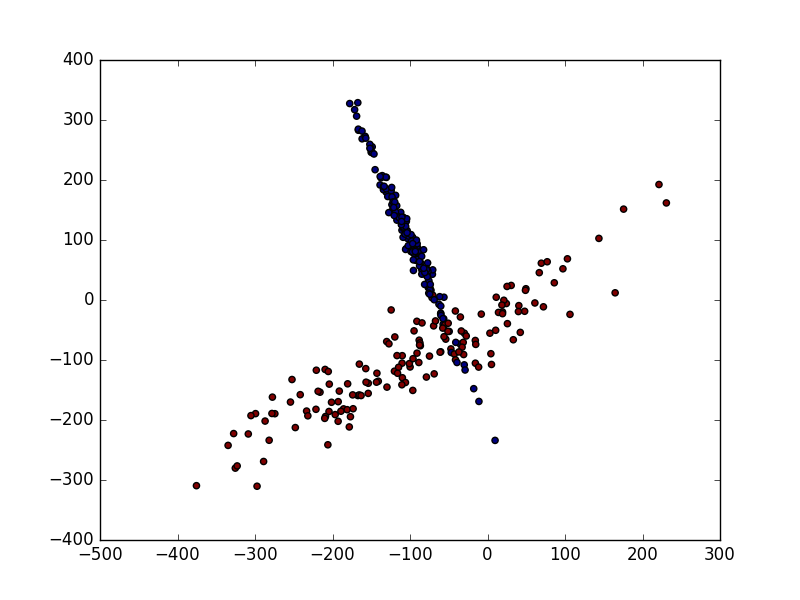
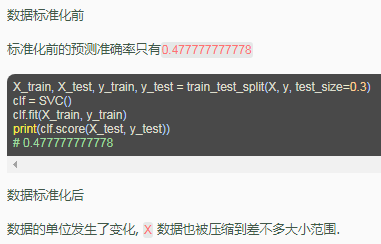

4实例:DT、GBDT、XGBoost
(1)导入模块、数据集
import sys
import os
import time
import numpy as np
import matplotlib.pyplot as plt
from sklearn import metrics
from sklearn.datasets import make_blobs
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import train_test_split
"""导入模型:bayes、(KNN、LR、SVM、DT)、(RF、AdaBoost、GBDT、ET)、XGBoost"""
from sklearn.naive_bayes import MultinomialNB
from sklearn.neighbors import KNeighborsClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import AdaBoostClassifier
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.ensemble import ExtraTreesClassifier
from xgboost import XGBClassifier
data, label = make_blobs(n_samples=10000, n_features=2, centers=10, random_state=0) #4000个样本,每个样本6维,10类数据
print(data.shape)
print(label.shape)
print(label[0:100])
train_x, test_x, train_y, test_y = train_test_split(data, label, test_size=0.2) # 20%的测试数据
(10000, 2)
(10000,)
[9 6 7 9 3 5 8 8 6 8 2 0 1 6 4 9 0 1 4 3 0 9 4 5 7 7 3 4 9 2 5 8 0 6 8 6 5
4 0 1 8 0 8 2 5 7 0 4 9 8 6 8 1 3 3 3 4 3 9 8 3 4 8 4 2 9 7 3 0 9 6 7 8 5
9 3 0 6 1 6 1 3 2 7 7 0 6 1 5 9 2 7 4 6 4 7 5 7 0 9]
(2)创建模型,并训练
Bayes = MultinomialNB()
KNN = KNeighborsClassifier()
LR = LogisticRegression()
SVM = SVC()
DT = DecisionTreeClassifier(max_depth=None, min_samples_split=2, random_state=0)
RF = RandomForestClassifier(n_estimators=100, max_depth=None, min_samples_split=2, random_state=0)
AdaBoost = AdaBoostClassifier(DecisionTreeClassifier(),algorithm="SAMME",n_estimators=200, learning_rate=0.8)
GBDT = GradientBoostingClassifier(n_estimators=200)
ET = ExtraTreesClassifier(n_estimators=100, max_depth=None, min_samples_split=2, random_state=0)
XGBoost = XGBClassifier( n_estimators= 200, max_depth= 4, min_child_weight= 2, gamma=0.9, subsample=0.8,
colsample_bytree=0.8, objective= 'binary:logistic', nthread= -1, scale_pos_weight=1)
##训练
"""
start_time = time.time()
scores = cross_val_score(SVM, train_x, train_y, cv=5) # 返回交叉验证后得到的分类率
print(scores)
print(scores.mean())
print ('training took %fs!' % (time.time() - start_time))
"""
start_time = time.time()
#Bayes.fit(train_x, train_y)
KNN.fit(train_x, train_y)
LR.fit(train_x, train_y)
SVM.fit(train_x, train_y)
DT.fit(train_x, train_y)
RF.fit(train_x, train_y)
AdaBoost.fit(train_x, train_y)
GBDT.fit(train_x, train_y)
ET.fit(train_x, train_y)
XGBoost.fit(train_x, train_y)
print ('training took %fs!' % (time.time() - start_time))
(3)预测测试集
predict_KNN = KNN.predict(test_x)
predict_LR = LR.predict(test_x)
predict_SVM = SVM.predict(test_x)
predict_DT = DT.predict(test_x)
predict_RF = RF.predict(test_x)
predict_AdaBoost = AdaBoost.predict(test_x)
predict_GBDT = GBDT.predict(test_x)
predict_ET = ET.predict(test_x)
predict_XGBoost = XGBoost.predict(test_x)
accuracy_KNN = metrics.accuracy_score(test_y, predict_KNN)
accuracy_LR = metrics.accuracy_score(test_y, predict_LR)
accuracy_SVM = metrics.accuracy_score(test_y, predict_SVM)
accuracy_DT = metrics.accuracy_score(test_y, predict_DT)
accuracy_RF = metrics.accuracy_score(test_y, predict_RF)
accuracy_AdaBoost = metrics.accuracy_score(test_y, predict_AdaBoost)
accuracy_GBDT = metrics.accuracy_score(test_y, predict_GBDT)
accuracy_ET = metrics.accuracy_score(test_y, predict_ET)
accuracy_XGBoost = metrics.accuracy_score(test_y, predict_XGBoost)
print('KNN accuracy: %.2f%%' % (100 * accuracy_KNN))
print('LR accuracy: %.2f%%' % (100 * accuracy_LR))
print('SVM accuracy: %.2f%%' % (100 * accuracy_SVM))
print('DT accuracy: %.2f%%' % (100 * accuracy_DT))
print('RF accuracy: %.2f%%' % (100 * accuracy_RF))
print('AdaBoost accuracy: %.2f%%' % (100 * accuracy_AdaBoost))
print('GBDT accuracy: %.2f%%' % (100 * accuracy_GBDT))
print('ET accuracy: %.2f%%' % (100 * accuracy_ET))
print('XGBoost accuracy: %.2f%%' % (100 * accuracy_XGBoost))
KNN accuracy: 92.50%
LR accuracy: 89.15%
SVM accuracy: 93.10%
DT accuracy: 90.65%
RF accuracy: 92.35%
AdaBoost accuracy: 90.90%
GBDT accuracy: 92.40%
ET accuracy: 92.35%
XGBoost accuracy: 93.00%














 1961
1961

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









