







本人7年数学建模竞赛经验,历史获奖率百分之百。团队成员都是拿过全国一等奖的硕博,有需要数模竞赛帮助的可以私信我
本题主要涉及统计学习,机器学习,数据处理,推荐算法等知识点,数据特征处理和分类器模型训练是本题的重点
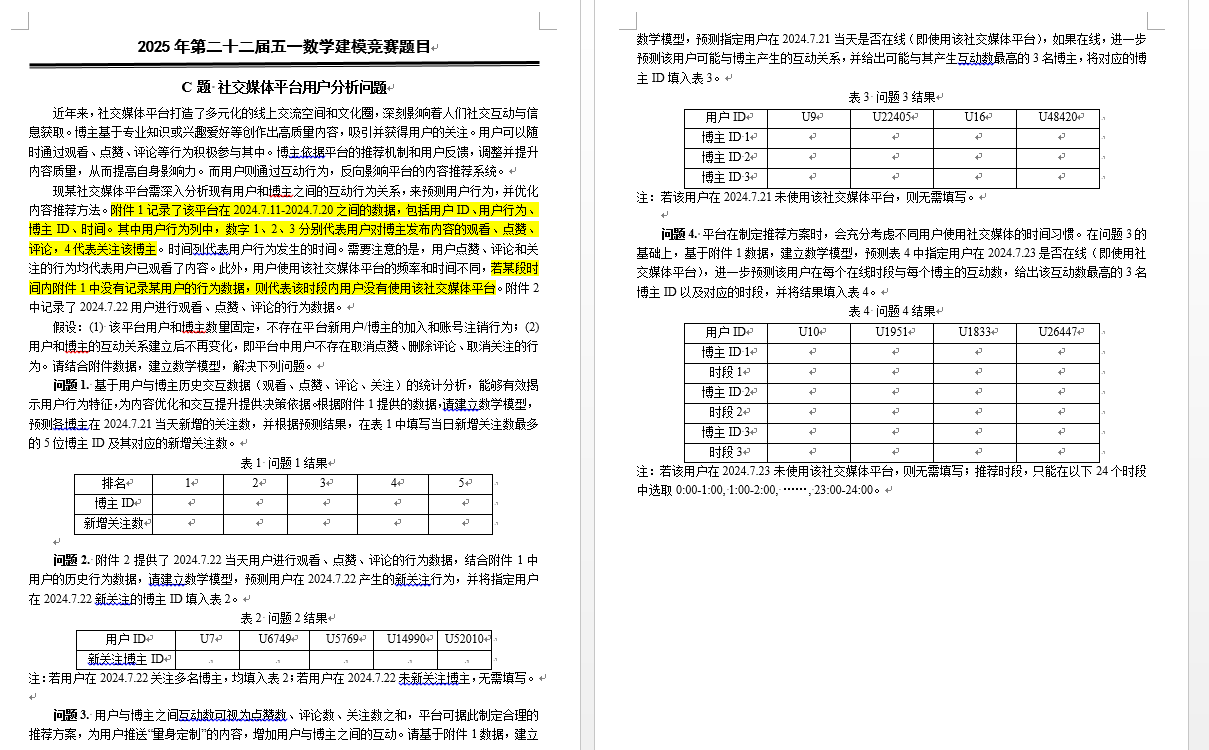
1.问题背景与描述
2.解题思路分析
2.1 问题一的分析
本题要求基于用户与博主历史交互数据,提取有效特征变量,来预测博主的各博主在2024.7.21当天新增的关注数。给出新增关注数最多的5位博主ID及其对应的新增关注数。
这道题有简单的做法有复杂的做法,
-
- 简单的解题思路就是直接从附件数据中抽取每个博主的单日新增关注数。然后利用时间序列基于时间特征去预测未来7.21日的每个博主的关注。但是这种思路没有考虑用户特征,博主特征以及交互特征,可以再挖掘一些细节特征训练预测模型;
-
- 复杂一点的做法就是从用户角度出发,预测用户是否会新关注一个博主,用户的行为包括观看、点赞、评论和关注,其中关注代表用户已经观看了内容。已知用户如果在某天没有记录,说明那天没使用平台。所以,我需要分析用户的历史互动行为,找出哪些因素会影响他们关注博主,然后预测7月21日每个博主的新增关注数。可能的思路是,先统计每个用户在历史期间(7.11-7.20)对各个博主的互动情况,比如观看次数、点赞次数、评论次数,以及是否关注过。然后,可能构建一个回归模型或者分类模型,预测在7月21日用户是否会关注某个博主。但问题是要预测的是每个博主的新增关注数,也就是总的被关注次数。因此,可能需要从用户的角度出发,预测每个用户当天会关注哪些博主,然后将这些汇总到博主层面。这种做法,考虑的特征更加合理,从用户特征出发能够充分考虑用户个性化行为。
== 总的来说不管是那种思路,本题的核心工作量还是在特征工程上面,要想结果做的准确,一个好的特征工程是必须的==
2.2 问题二的分析
问题2要求预测用户在7月22日的新关注行为。附件2给出了7月22日用户的具体互动行为(观看、点赞、评论),但需要预测的是他们当天是否会关注新的博主。这里的数据可能更侧重于当天的实时行为,结合历史数据来预测。可能需要用监督学习的方法,比如逻辑回归、随机森林、梯度提升树等,将用户的历史行为作为特征,预测他们是否会在当天关注某个博主。
可能需要处理多分类问题,因为每个用户可能关注多个博主,或者需要预测具体的博主ID。问题2的结果要填写每个指定用户在7月22日新关注的博主ID,所以可能需要为每个用户生成一个概率分布,然后选择概率最高的几个博主作为预测结果。可以采用多分类模型来预测每个用户对所有博主的关注概率,然后利用排序算法给出概率最高的几个博主作为预测结果。
本题的核心是构造用户特征,包括用户的实时互动数据(观看、点赞、评论数据,基于多分类模型(KNN)等预测用户对所有博主的关注概率
2.3 问题三的分析
问题3要求预测指定用户在7月21日是否在线,如果在线的话,预测他们可能与哪些博主产生互动,并给出互动数最高的三个博主。这里需要考虑用户在线状态的概率,以及在线时的互动模式。
首先建立一个二元分类模型(比如逻辑回归)判别用户是否在线,可以使用历史数据中的活跃时间、频率等信息,比如用户通常在哪些时间段活跃,是否有规律,需要通过特征工程提取出历史活跃时间、近期活跃情况等特征变量;
然后,对于在线的用户,预测他们可能与哪些博主互动。这里的互动可能包括观看、点赞、评论、关注,但问题3中提到的互动数是点赞、评论、关注的总和,所以可能需要综合考虑这些行为的概率。建立多分类预测模型,分别预测用户与所有博主发生互动的概率,然后给出概率最高的前三位。
本题的判断用户是否在线是一个简单的二元分类问题,而对于互动关系的预测,解题思路同问题二,不过对应的特征提取是解题的核心
2.4 问题四的分析
本题基本上是问题三的扩展,
-
- 预测用户是否在线,方法同问题3。
-
- 如果在线,预测每个时段的互动数:可能使用时间序列模型或按时间段分组回归。
-
- 对每个在线时段,选择互动数最高的三个博主填入表4。
时间分段特征:将24小时划分为8个时段(如0-3点、3-6点等)。
模型选择:对每个在线时段,使用线性回归或随机森林回归预测互动数。若用户在线,对每个时段预测互动数,选择前三名博主及对应时段填入表4。使用用户的历史互动数据作为输入,通过矩阵分解预测用户可能感兴趣的博主。或者,使用神经网络,将用户和博主嵌入到低维空间,然后计算相似度,给出用户与博主的互动关系也是一种思路
总的来说,这道题难点在于数据处理,特征工程处理,需要具备较强的计算机编码能力
3.完整代码+结果分享
代码和论文已经全部完成 可以通过下面获取,或者私信我获取
https://mbd.pub/o/bread/aZ6Zmp9w



















 1200
1200

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











