







给实习生聊到决策树、GBDT,有几个概念这里再用易懂的方式解释下
-
信息熵是决策树的基础
-
信息增益-ID3算法构建决策树
-
信息增益率-C4.5算法构建决策树
-
基尼指数-Cart算法构建决策树
信息熵
-
用另外一个词来说就是纯度,一个盒子里只有白球,说明这个盒子很纯,纯度很高。一个集合里只有一类样本,比如表示男女的样本集合U={男,男,…}都是男的,那么就说这个集合纯度很高。
-
纯度相对于信息熵呢?首先熵,是热力学的概念,表示体系混乱度的度量,这个可以去百度哈,体系越混乱,熵越大。学过物理的一定听说过熵增熵减!
-
信息熵:就是说信息的混乱程度,信息混乱程度越大,信息熵越大!对于纯度,就是信息熵越大,纯度越低!
-
在信息论中,随机离散事件出现的概率存在着不确定性。为了衡量这种信息的不确定性,信息学之父香农引入了信息熵的概念。不确定性越大,信息熵越大
还是那个例子,一个盒子里只有白球,说明信息熵很低,纯度很高。那么此时,随着你一个一个往盒子里增加黑球,盒子里纯度就会越来越低,随之信息熵越来越高,啥时候达到最大呢,就是当黑球和白球数量相等的时候。
香农总结出一个信息熵量化的公式
H
(
X
)
=
E
n
t
r
o
p
y
(
x
)
=
−
Σ
x
x
ϵ
X
p
(
x
)
log
p
(
x
)
H\left(X\right)=Entropy\left(x\right)=-\underset{x\epsilon X}{\overset{x}{\varSigma}}p\left(x\right)\log p\left(x\right)
H(X)=Entropy(x)=−xϵXΣxp(x)logp(x)
- H表示信息熵的符号
- 性质:单调性。概率越高的事件,其不确定性越低,携带的信息量越低,信息熵越低
- 性质:非负性。信息熵可以看作为一种广度量,无需多言,总不能有负数信息熵吧
- 性质:累加性,即多随机事件同时发生存在的总不确定性的量度是可以表示为各事件不确定性的量度的和,这也是广度量的一种体现
条件熵
熵按上文解释,表示随机变量的不确定性
条件熵,顾名思义,在一个条件下,随机变量的不确定
条件熵是在特定条件下的信息量的期望
信息增益
决策树中ID3算法就是用信息增益来选取树节点
信息增益 = 熵 - 条件熵。在一个条件下,信息不确定性减少的程度
G
a
i
n
(
Y
,
X
)
=
H
(
Y
)
−
H
(
Y
∣
X
)
Gain\left( Y,X \right) =H\left( Y \right) -H\left( Y|X \right)
Gain(Y,X)=H(Y)−H(Y∣X)
其中H(Y|X)是条件熵
H
(
Y
∣
X
)
=
Σ
x
ϵ
X
p
(
x
)
H
(
Y
∣
X
=
x
)
=
−
Σ
x
ϵ
X
p
(
x
)
Σ
y
ϵ
Y
p
(
y
∣
x
)
log
p
(
y
∣
x
)
=
−
Σ
x
ϵ
X
Σ
y
ϵ
Y
p
(
y
,
x
)
log
p
(
y
∣
x
)
H\left( Y|X \right) =\underset{x\epsilon X}{\varSigma}p\left( x \right) H\left( Y|X=x \right) \\ \\ =-\underset{x\epsilon X}{\varSigma}p\left( x \right) \underset{y\epsilon Y}{\varSigma}p\left( y|x \right) \log p\left( y|x \right) \\ =-\underset{x\epsilon X}{\varSigma}\underset{y\epsilon Y}{\varSigma}p\left( y,x \right) \log p\left( y|x \right)
H(Y∣X)=xϵXΣp(x)H(Y∣X=x)=−xϵXΣp(x)yϵYΣp(y∣x)logp(y∣x)=−xϵXΣyϵYΣp(y,x)logp(y∣x)
在决策树中信息增益通常有这样一个公式:
G
a
i
n
(
D
,
a
)
=
E
n
t
(
D
)
−
Σ
v
v
=
1
∣
D
v
∣
∣
D
∣
E
n
t
(
D
v
)
Gain\left( D,a \right) =Ent\left( D \right) -\underset{v=1}{\overset{v}{\varSigma}}\frac{|D^v|}{|D|}Ent\left( D^v \right)
Gain(D,a)=Ent(D)−v=1Σv∣D∣∣Dv∣Ent(Dv)
-
其中D是数据集,a是选择的属性,a中共有v个取值。
-
信息增益在决策树里概念上的一个公式:信息增益=划分前信息熵 - 划分后信息熵。划分前信息熵就是H(D)对吧,这里也写做Ent(D),划分后的信息熵就是说根据某个属性进行划分后的信息熵,也就是所谓的条件熵H(D|a)
-
决策树里ID3算法为啥选信息增益最大的作为划分点呢?划分前-划分后的值越大,不就说明你用这个方式划分减少的信息熵越大,不就说明划分后信息熵减少了,数据集纯度更纯了。所以就选信息增益最大的。
-
再用个生活中的例子,暂且不考虑费用问题且陆路只有深圳有直达香港的列车,你从北京陆路前往香港,要转车的次数最少,那就希望每一趟车都行驶最大的距离对吧,这里就有个贪心的思想。ID3根据信息增益最大选取划分点就是这个思路
信息增益率
有些文献又叫信息增益比
上公式
信息增益率
G
a
i
n
R
a
t
i
o
(
D
,
a
)
=
G
a
i
n
(
D
,
a
)
I
V
(
a
)
其中
I
V
(
a
)
=
−
Σ
V
v
=
1
p
(
D
v
)
log
p
(
D
v
)
=
−
Σ
V
v
=
1
∣
D
v
∣
∣
D
∣
log
∣
D
v
∣
∣
D
∣
,就等于
H
(
a
)
,只是含义不一样
\text{信息增益率} \\ GainRatio\left( D,a \right) =\frac{Gain\left( D,a \right)}{IV\left( a \right)} \\ \text{其中}IV\left( a \right) =-\underset{v=1}{\overset{V}{\varSigma}}p\left( D^v \right) \log p\left( D^v \right) =-\underset{v=1}{\overset{V}{\varSigma}}\frac{|D^v|}{|D|}\log \frac{|D^v|}{|D|}\text{,就等于}H\left( a \right) \text{,只是含义不一样}
信息增益率GainRatio(D,a)=IV(a)Gain(D,a)其中IV(a)=−v=1ΣVp(Dv)logp(Dv)=−v=1ΣV∣D∣∣Dv∣log∣D∣∣Dv∣,就等于H(a),只是含义不一样
就是给信息增益一个惩罚值,这里就是除以IV(a),IV(a)计算公式和H(a)一样,也就是求a的信息熵。那么如果a的信息熵越大,也就是特征a的混乱度很大,那它的信息增益率GainRatio(D,a)就会相对来说惩罚的越大。公式能看懂这些关系吧
-
ID3算法在数据集不充足,某些特征取值非常多的时候会有偏向性,就偏向特征取值非常多的那类特征
-
C4.5算法使用信息增益率。原理就是通过惩罚项来惩罚特征取值较多的属性值
-
首先得说一个定理:大数定理,就是数据量或者样本量足够大的情况下,频率才可以近似概率。就比如我抛5次硬币,1次正,4此反,那你就能说接下来我抛硬币正的概率是1/5?不行的,实际上硬币正反的概率都是1/2,只有你抛百万次千万次,你计算你的正面概率才会更接近1/2
基尼指数
有些文章又叫基尼系数。。。有没有听过国家统计局的基尼系数?去百度下
决策树里的所谓基尼系数实际上是基尼指数,最好专业点别叫错
基尼指数实际上也是个表示数据集纯度的指标:基尼指数越小,数据集纯度越高
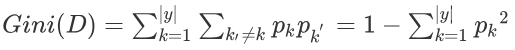
表示在样本集合中一个随机选中的样本被分错的概率。
举例来说,现在一个袋子里有2种颜色的球若干个,伸手进去掏出2个球,颜色不一样的概率,这下明白了吧。随机两个球对应公式里的就是k和k'
- 决策树中CART算法就是使用Gini来进行选举切分点
- 关于决策树的CART算法这里不展开















 8692
8692











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









