







专栏系列:《人工智能AI之机器学习基石》③

选择机器学习的学习方法
图注:机器学习有多种“学习方法”,选择合适的路径至关重要
🚀 引言:AI如何“拜师学艺”?
在前面的文章中,我们了解了机器学习的基本概念(《什么是机器学习?》)以及驱动它的“燃料”——数据(《数据为王》)。我们知道,机器学习模型就像一个聪明的学生,需要从数据中学习经验。但这个“学习”具体是怎么进行的呢?是像学生听老师讲课,有明确的答案指导?还是像探险家自主探索,从未知中发现规律?
这就引出了机器学习中不同的“学习范式”或我们常说的“学习方法”。不同的任务,需要机器采用不同的“拜师学艺”之道。今天,我们就来聊聊机器学习中最主要的两大学习方法:监督学习 (Supervised Learning) 和 无监督学习 (Unsupervised Learning)。它们是如何工作的?又各自擅长解决什么样的问题呢?
👨🏫 一、监督学习:有“老师”指导的学习
想象一下,你正在教一个孩子识别水果。你会指着一个苹果告诉他:“这是苹果。”然后指着一个香蕉告诉他:“这是香蕉。” 在这个过程中,你提供了物体本身(我们称之为“输入特征”)和它的正确名称(我们称之为“标签”或“答案”)。孩子通过大量这样的“输入-答案”对进行学习,最终能够自己识别新的、以前没见过的水果。
监督学习 (Supervised Learning) 就非常类似这个过程。它的核心在于使用有标签的数据 (Labeled Data) 进行训练。
- 什么是标签数据? 简单来说,就是我们已经知道了正确答案的数据。每一条训练数据都包含一组输入特征(X)和一个我们期望模型预测出的输出标签(Y)。这个标签就是“标准答案”。
- 学习目标: 模型的任务是学习从输入特征 X 到输出标签 Y 之间的一个潜在的对应关系或模式,我们通常把它想象成一个函数 f,使得 Y ≈ f(X)。当模型通过学习找到了这个近似的 f 后,就能对新的、未见过的输入数据 X' 预测出相应的输出 Y'。这个 f 就是模型从数据中学到的“知识”或“规则”。
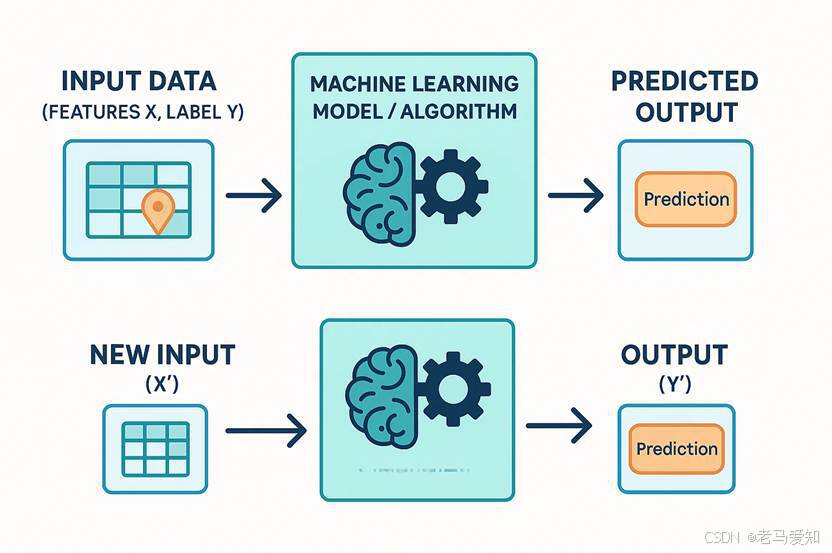 监督学习原理
监督学习原理
图注:监督学习——从带标签的数据中学习映射关系
监督学习主要解决两大类问题:分类 (Classification) 和 回归 (Regression)。
1.1 分类 (Classification):给事物“贴标签”
当我们要预测的输出标签是离散的、有限的类别值时,这就是一个分类问题。可以理解为,模型需要学习如何将输入数据划分到预先定义好的几个类别中的某一个。就像给事物打上正确的“标签”。
常见例子:
- 垃圾邮件识别: 输入是一封邮件的文本内容、发件人信息等特征,输出是“垃圾邮件”或“非垃圾邮件”这两个类别之一。模型学习区分这两类邮件的特征。
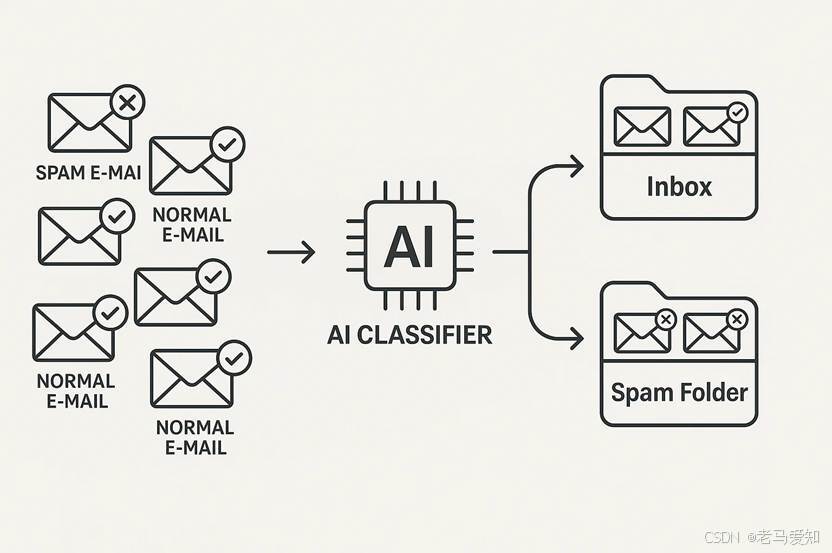
垃圾邮件分类示例
图注: 垃圾邮件分类是一个典型的监督学习分类问题
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 539
539

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









