







支持向量机SVM
逻辑回归
h θ ( x ) = 1 1 + e − θ T x (1) h_{\theta}(x)=\frac{1}{1+e^{-\theta^{T} x}} \tag{1} hθ(x)=1+e−θTx1(1)
If y = 1 , w e w a n t h θ ( x ) ≈ 1 , θ T x ≫ 0 If y = 0 , w e w a n t h θ ( x ) ≈ 0 , θ T x ≪ 0 (2) \text{If} \quad y=1, we \,\,\, want \,\,\, h_{\theta}(x) \approx 1, \quad \theta^{T} x \gg 0\\ \text{If} \quad y=0, we \,\,\, want \,\,\, h_{\theta}(x) \approx 0, \quad \theta^{T} x \ll 0 \tag{2} Ify=1,wewanthθ(x)≈1,θTx≫0Ify=0,wewanthθ(x)≈0,θTx≪0(2)
代价函数:
Cost
=
−
(
y
log
h
θ
(
x
)
+
(
1
−
y
)
log
(
1
−
h
θ
(
x
)
)
)
=
−
y
log
1
1
+
e
−
θ
T
x
−
(
1
−
y
)
log
(
1
−
1
1
+
e
−
θ
T
x
)
(3)
\begin{aligned} \text{Cost} = &-\left(y \log h_{\theta}(x)+(1-y) \log \left(1-h_{\theta}(x)\right)\right)\\ =&-y \log \frac{1}{1+e^{-\theta^{T} x}}-(1-y) \log \left(1-\frac{1}{1+e^{-\theta^{T} x}}\right) \end{aligned} \tag{3}
Cost==−(yloghθ(x)+(1−y)log(1−hθ(x)))−ylog1+e−θTx1−(1−y)log(1−1+e−θTx1)(3)
改进代价函数
SVM的代价函数是在逻辑回归的代价函数上进行改进,将 ( 3 ) (3) (3)式中的 − log h θ ( x ) -\log h_{\theta}(x) −loghθ(x)替换为 Cost 1 ( x ) \text{Cost}_1(x) Cost1(x), − log ( 1 − h θ ( x ) ) -\log \left(1-h_{\theta}(x)\right) −log(1−hθ(x))替换为 Cost 0 ( x ) \text{Cost}_0(x) Cost0(x)。下面两图是对 Cost 1 ( x ) \text{Cost}_1(x) Cost1(x)和 Cost 0 ( x ) \text{Cost}_0(x) Cost0(x)的介绍(红线部分代表 Cost \text{Cost} Cost函数)。

最终,SVM的代价函数修改为如下格式:
min
θ
C
∑
i
=
1
m
[
y
(
i
)
cost
1
(
θ
T
x
(
i
)
)
+
(
1
−
y
(
i
)
)
cost
0
(
θ
T
x
(
i
)
)
]
+
1
2
∑
i
=
1
n
θ
j
2
(4)
\min _{\theta} C \sum_{i=1}^{m}\left[y^{(i)} \operatorname{cost}_{1}\left(\theta^{T} x^{(i)}\right)+\left(1-y^{(i)}\right) \operatorname{cost}_{0}\left(\theta^{T} x^{(i)}\right)\right]+\frac{1}{2} \sum_{i=1}^{n} \theta_{j}^{2} \tag{4}
θminCi=1∑m[y(i)cost1(θTx(i))+(1−y(i))cost0(θTx(i))]+21i=1∑nθj2(4)
SVM代价函数共修改三处:
- 把逻辑回归里的两处函数改为 cost 1 \text{cost}_1 cost1和 cost 0 \text{cost}_0 cost0;
- 去掉了最前方的 1 m \frac{1}{m} m1(并不影响最优化),并且给第一项添加权重系数C,控制其权值;
- 去掉了正则项处的权重系数,由C控制相对权重。
SVM最终的输出有别于逻辑回归输出的概率。最小化代价函数获得参数
θ
\theta
θ时,支持向量机所做的是直接预测y值等于1还是等于0。
h
θ
(
x
)
{
1
if
θ
T
x
⩾
0
0
othervire
(5)
h_{\theta}(x) \begin{cases}1 & \text { if } \theta^{T} x \geqslant 0 \\ 0 & \text { othervire }\end{cases} \tag{5}
hθ(x){10 if θTx⩾0 othervire (5)
大间距分类器
下图是SVM的代价函数,左边是 Cost 1 ( θ T x ) \text{Cost}_1(\theta^Tx) Cost1(θTx),用于正样本,右边是 Cost 0 ( θ T x ) \text{Cost}_0(\theta^Tx) Cost0(θTx),用于负样本。最小化代价函数的条件是:当 θ T x ≥ 1 \theta^Tx \geq 1 θTx≥1时, Cost 1 ( θ T x ) \text{Cost}_1(\theta^Tx) Cost1(θTx)才等于0。对于逻辑回归来说,当 y = 0 y=0 y=0时,希望 θ T x ≤ 0 \theta^Tx \leq 0 θTx≤0,当 y = 1 y=1 y=1时,希望 θ T x ≥ 0 \theta^Tx \geq 0 θTx≥0。换句话说,SVM的要求更高,相当于SVM中嵌入了安全的间距因子。

对于式
(
4
)
(4)
(4)来说,如果
C
C
C非常大,则最小化代价函数的时候,会希望找到使得第一项为0的最优解。因此可以等价为在代价项第一项为0情形下的优化问题。等价于下式。
min
C
×
0
+
1
2
∑
i
=
1
n
θ
i
2
s
.
t
.
θ
T
x
(
i
)
⩾
1
i
f
y
(
i
)
=
1
,
θ
T
x
(
i
)
⩽
−
1
i
f
y
(
i
)
=
0.
(6)
\min C \times 0+\frac{1}{2} \sum_{i=1}^{n} \theta_{i}^{2}\\ s.t. \theta^{T} x^{(i)} \geqslant 1 \quad if \,\,\, y^{(i)}=1,\\ \quad \,\,\,\theta^{T} x^{(i)} \leqslant-1 \quad if \,\,\, y^{(i)}=0.\tag{6}
minC×0+21i=1∑nθi2s.t.θTx(i)⩾1ify(i)=1,θTx(i)⩽−1ify(i)=0.(6)
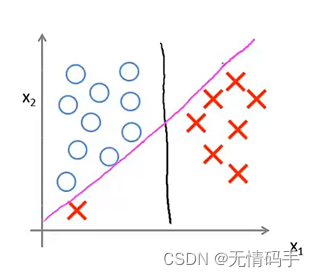
SVM会训练得到间距最大的黑色分界线,而并非下图中其他颜色的分界线。也就是说SVM鲁棒性较高,它用最大间距来分离样本。
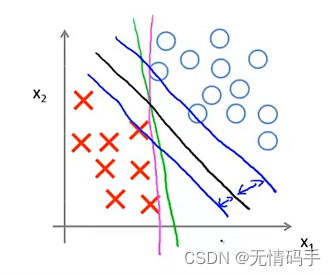
当 C C C设置较x小时,分界线为黑色(因为第一项没有占非常重要的地位,允许分错),但它的间距较大。当 C C C设置较大(第一项占据地位较大),分界线为由黑色变为紫色,间距变小。
大间距分类器的原因
要搞清楚这个问题,首先需要明白向量内积的另一种形式。
θ
T
x
(
i
)
=
θ
1
x
1
(
i
)
+
θ
2
x
2
(
i
)
=
p
(
i
)
∥
θ
∥
(7)
\begin{aligned} \theta^{T} x^{(i)} &= \theta_{1} x_{1}^{(i)}+\theta_{2} x_{2}^{(i)}\\ &=p^{(i)}\|\theta\| \end{aligned} \tag{7}
θTx(i)=θ1x1(i)+θ2x2(i)=p(i)∥θ∥(7)
其中,
p
i
p^i
pi表示
θ
\theta
θ在
x
i
x^i
xi上的投影,它有正有负。两向量夹角KaTeX parse error: Undefined control sequence: \textless at position 1: \̲t̲e̲x̲t̲l̲e̲s̲s̲ ̲90°时,
p
i
p^i
pi为正,两向量夹角KaTeX parse error: Undefined control sequence: \textgreater at position 1: \̲t̲e̲x̲t̲g̲r̲e̲a̲t̲e̲r̲ ̲90°时,
p
i
p^i
pi为负。
min
θ
1
2
∑
j
=
1
n
θ
j
2
s.t.
p
(
i
)
⋅
∥
θ
∥
≥
1
if
y
(
i
)
=
1
p
(
i
)
⋅
∥
θ
∥
≤
−
1
if
y
(
i
)
=
1
(8)
\begin{aligned} &\min _{\theta} \frac{1}{2} \sum_{j=1}^{n} \theta_{j}^{2}\\ &\text { s.t. } p^{(i)} \cdot\|\theta\| \geq 1 \quad \text { if } y^{(i)}=1\\ &\quad \,\,\,\,\, p^{(i)} \cdot\|\theta\| \leq-1 \quad \text { if } y^{(i)}=1 \end{aligned} \tag{8}
θmin21j=1∑nθj2 s.t. p(i)⋅∥θ∥≥1 if y(i)=1p(i)⋅∥θ∥≤−1 if y(i)=1(8)
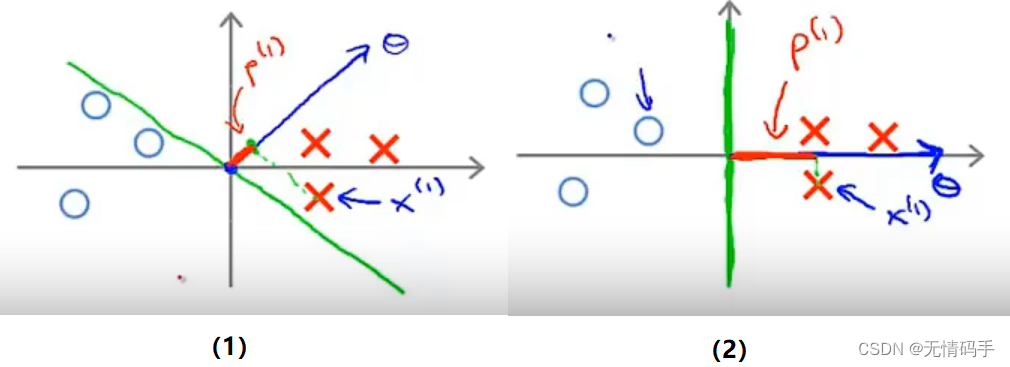
对于下图的两种情况来说,下图(1)中所示的
p
p
p很小,因为有
p
(
i
)
⋅
∥
θ
∥
≥
1
p^{(i)} \cdot\|\theta\| \geq 1
p(i)⋅∥θ∥≥1和
p
(
i
)
⋅
∥
θ
∥
≤
−
1
p^{(i)} \cdot\|\theta\| \leq -1
p(i)⋅∥θ∥≤−1的约束,他会试图增大
∥
θ
∥
\|\theta\|
∥θ∥,显然这不符合我们的优化目标。换句话说,为达到我们的优化目标让
∥
θ
∥
\|\theta\|
∥θ∥尽可能小,SVM会选择较大的
p
i
p^i
pi也就是下图(2)中所示的较大间距的决策边界。
提示:
- θ 0 = 0 \theta_0=0 θ0=0表示决策边界过原点, θ 0 ! = 0 \theta_0\,\, !=0 θ0!=0表示决策边界不过原点;
- θ \theta θ与决策边界为垂直关系。因为边界公式为 θ T x = θ 1 x 1 + θ 2 x 2 = 0 \theta^{T} x=\theta_{1} x_{1}+\theta_{2} x_{2}=0 θTx=θ1x1+θ2x2=0,斜率为 − θ 1 θ 2 \frac{-\theta_1}{\theta_2} θ2−θ1, θ \theta θ为 [ θ 1 , θ 2 ] T [\theta_1,\theta_2]^T [θ1,θ2]T,斜率为 θ 2 θ 1 \frac{\theta_2}{\theta_1} θ1θ2,因此他们相互垂直。
核函数
核函数也可以称作similarity function,它描述了训练点和标记点之间的相似度(距离)。SVM可以定义标记点和核函数去构造一组新的特征
f
f
f代替原特征
x
x
x去进行模型的训练。一般来说,有多少训练点就有多少标记点。这里我们代表性地介绍一下高斯核函数。
f
(
i
)
=
(
f
1
(
i
)
⋮
f
m
(
i
)
)
f
j
(
i
)
=
exp
(
−
∥
x
(
i
)
−
l
(
j
)
∥
2
2
σ
2
)
(9)
f^{(i)} = \left( \begin{array}{c} f_{1}^{(i)} \\ \vdots \\ f_{m}^{(i)} \end{array} \right)\\ f_{j}^{(i)}=\exp \left(-\frac{\left\|x^{(i)}-l^{{(j)}}\right\|^{2}}{2 \sigma^{2}}\right) \tag{9}
f(i)=⎝⎜⎜⎛f1(i)⋮fm(i)⎠⎟⎟⎞fj(i)=exp(−2σ2∥∥x(i)−l(j)∥∥2)(9)
其中,
f
(
i
)
f^{(i)}
f(i)是由高斯核函数和标记点构造出的新的特征,代表第
i
i
i个点与其他标记点间的相似度。
f
j
(
i
)
f_j^{(i)}
fj(i)代表原
x
(
i
)
x^{(i)}
x(i)与第
j
j
j个标记点
l
(
j
)
l^{(j)}
l(j)的相似度。也就是说,原来的特征
x
x
x被替换成了新的特征
f
f
f,它的格式由
(
m
,
n
)
(m,n)
(m,n)转变为了
(
m
,
m
)
(m,m)
(m,m)。此处
σ
\sigma
σ越小,函数下降越剧烈,计算相似度(距离)敏感度越高。
σ
\sigma
σ越大,函数下降越平缓,计算相似度(距离)敏感度越低。
最终,SVM的假设被修改为:给定
x
x
x,计算新特征
f
f
f,当
θ
T
f
≥
0
\theta^Tf\geq0
θTf≥0时,预测
y
=
1
y=1
y=1,否则反之。相应地,代价函数修改为如下公式。
min
C
∑
i
=
1
m
[
y
(
i
)
cost
1
(
θ
T
f
(
i
)
)
+
(
1
−
y
(
i
)
)
cost
0
(
θ
T
f
(
i
)
)
]
+
1
2
∑
j
=
1
n
=
m
θ
j
2
(10)
\min C \sum_{i=1}^{m}\left[y^{(i)} \operatorname{cost}_{1}\left(\theta^{T} f^{(i)}\right)+\left(1-y^{(i)}\right) \operatorname{cost}_{0}\left(\theta^{T} f^{(i)}\right)\right]+\frac{1}{2} \sum_{j=1}^{n=m} \theta_{j}^{2} \tag{10}
minCi=1∑m[y(i)cost1(θTf(i))+(1−y(i))cost0(θTf(i))]+21j=1∑n=mθj2(10)
需要注意的是,在计算
∑
j
=
1
n
=
m
θ
j
2
=
θ
T
θ
\sum_{j=1}^{n=m} \theta_{j}^{2}=\theta^{T} \theta
∑j=1n=mθj2=θTθ时,为简化计算提高计算效率,用
θ
T
M
θ
\theta^TM\theta
θTMθ来代替。
另外,SVM也支持不使用核函数,也就是直接使用原来的特征
x
(
m
,
n
)
x(m,n)
x(m,n)进行计算,代价函数也就是
(
4
)
(4)
(4)式,预测准则如下。
predict "y=1"
if
θ
T
x
⩾
0
(
θ
0
+
θ
1
x
1
+
⋯
+
θ
n
x
n
⩾
0
)
(11)
\text { predict "y=1" \,\, if } \,\theta^{T} x \geqslant 0 \quad \left(\theta_{0}+\theta_{1} x_{1}+\cdots+\theta_{n} x_{n} \geqslant 0 \right) \tag{11}
predict "y=1" if θTx⩾0(θ0+θ1x1+⋯+θnxn⩾0)(11)
总结
SVM参数 σ \sigma σ和 C C C的影响
- C = 1 / λ C = 1/\lambda C=1/λ;
- C C C较大时( λ \lambda λ)较小,可能会导致过拟合,高方差;
- C C C较小时( λ \lambda λ)较大,可能会导致欠拟合,高偏差;
- σ \sigma σ较大时,可能会导致低方差,高偏差;
- σ \sigma σ较小时,可能会导致高方差,低偏差。
使用准则
n为特征数,m为训练样本数。
- 如果相较于m而言,n要大许多,即训练集数据量不够支持训练一个复杂的非线性模型,我们选用逻辑回归模型或者不带核函数的支持向量机。
- 如果n较小,而且m大小中等,例如n在1-1000之间,而m在10-10000之间,使用高斯核函数的支持向量机。
- 如果n较小,而m较大,例如n在1-1000之间,而m大于50000,则使用支持向量机会非常慢,解决方案是创造、增加更多的特征,然后使用逻辑回归或不带核函数的支持向量机。
代码
使用 DataFrame加载数据
raw_data = loadmat('data/ex6data1.mat')
# print(raw_data)
data = pd.DataFrame(raw_data['X'], columns=['X1', 'X2'])
data['y'] = raw_data['y']
# 把data['y']是1的data拿出来放在positive里
# 把data['y']是0的data拿出来放在negative里
positive = data[data['y'].isin([1])]
negative = data[data['y'].isin([0])]
绘制散点图
# figsize 设置图形的大小,a 为图形的宽, b 为图形的高
fig, ax = plt.subplots(figsize=(12,8))
# s 标记的大小
ax.scatter(positive['X1'], positive['X2'], s=50, marker='x', label='Positive')
ax.scatter(negative['X1'], negative['X2'], s=50, marker='o', label='Negative')
ax.legend()
plt.show()
不使用核函数的SVM(sklearn.svm.LinearSVC)
mat = sio.loadmat('./data/ex6data1.mat')
# 从mat里提取数值出来变成DataFrame
data = pd.DataFrame(mat.get('X'), columns=['X1', 'X2'])
# 增加新的一列'y'
data['y'] = mat.get('y')
#head()根据位置返回对象的前n行。如果你的对象中包含正确的数据类型, 则对于快速测试很有用。
#此方法用于返回数据帧或序列的前n行(默认值为5)。
print(data.head())
#可视化数据
fig, ax = plt.subplots(figsize=(8,6))
#c 颜色区分 ->按y来区分颜色
ax.scatter(data['X1'], data['X2'], s=50, c=data['y'], cmap='Reds')
ax.set_title('Raw data')
ax.set_xlabel('X1')
ax.set_ylabel('X2')
plt.show()
#try C = 1
#loss : string, ‘hinge’ or ‘squared_hinge’ (default=’squared_hinge’)
#指定损失函数。 “hinge”是标准的SVM损失(例如由SVC类使用),而“squared_hinge”是hinge损失的平方。
svc1 = sklearn.svm.LinearSVC(C=1, loss='hinge')
svc1.fit(data[['X1', 'X2']], data['y'])
print(svc1.score(data[['X1', 'X2']], data['y']))
#try C = 100
svc100 = sklearn.svm.LinearSVC(C=100, loss='hinge')
svc100.fit(data[['X1', 'X2']], data['y'])
print(svc100.score(data[['X1', 'X2']], data['y']))
使用高斯核函数的SVM(sklearn.svm.SVC)
# kernek function
def gaussian_kernel(x1, x2, sigma):
return np.exp(- np.power(x1 - x2, 2).sum() / (2 * (sigma ** 2)))
#load data
mat = sio.loadmat('./data/ex6data2.mat')
print(mat.keys())
data = pd.DataFrame(mat.get('X'), columns=['X1', 'X2'])
data['y'] = mat.get('y')
#可视化数据
#palette 调色板
sns.set(context="notebook", style="white", palette=sns.diverging_palette(240, 10, n=2))
# data 参数是DataFrame
# ‘X1’ 'X2'表示横纵坐标名称
# hue 表示区分的名称 这里是y 用于分类
# fit_reg:(可选)此参数接受bool值。如果为True,则估计并绘制与x和y变量相关的回归模型。
# height:(可选)此参数是每个构面的高度(以英寸为单位)。
sns.lmplot('X1', 'X2', hue='y', data=data,
height=5,
fit_reg=False,
scatter_kws={"s": 10}
)
plt.show()
# try built-in Gaussian Kernel of sklearn
# radial basis function(Gaussian)kernel,简称 RBF kernel
svc = svm.SVC(C=100, kernel='rbf', gamma=10, probability=True)
print(svc)
svc.fit(data[['X1', 'X2']], data['y'])
print(svc.score(data[['X1', 'X2']], data['y']))
置信水平计算
# 查看每个类别预测的置信水平
data['SVM 1 Confidence'] = svc.decision_function(data[['X1', 'X2']])
fig, ax = plt.subplots(figsize=(12,8))
ax.scatter(data['X1'], data['X2'], s=50, c=data['SVM 1 Confidence'], cmap='seismic')
ax.set_title('SVM (C=1) Decision Confidence')
#plt.show()
data['SVM 2 Confidence'] = svc2.decision_function(data[['X1', 'X2']])
fig, ax = plt.subplots(figsize=(12,8))
ax.scatter(data['X1'], data['X2'], s=50, c=data['SVM 2 Confidence'], cmap='seismic')
ax.set_title('SVM (C=100) Decision Confidence')
plt.show()
#从图中可以看出 C = 1 的分类效果更好,置信度更高
最佳 C C C和 σ \sigma σ寻找
#找最佳的 C 和 \sigma
raw_data = loadmat('data/ex6data3.mat')
X = raw_data['X']
Xval = raw_data['Xval']
y = raw_data['y'].ravel()
yval = raw_data['yval'].ravel()
C_values = [0.01, 0.03, 0.1, 0.3, 1, 3, 10, 30, 100]
gamma_values = [0.01, 0.03, 0.1, 0.3, 1, 3, 10, 30, 100]
best_score = 0
best_params = {'C': None, 'gamma': None}
for C in C_values:
for gamma in gamma_values:
svc = svm.SVC(C=C, gamma=gamma)
svc.fit(X, y)
score = svc.score(Xval, yval)
if score > best_score:
best_score = score
best_params['C'] = C
best_params['gamma'] = gamma
print(best_score, best_params)
使用SVM构建垃圾邮件分类器
spam_train = loadmat('data/spamTrain.mat')
spam_test = loadmat('data/spamTest.mat')
X = spam_train['X']
Xtest = spam_test['Xtest']
y = spam_train['y'].ravel()
ytest = spam_test['ytest'].ravel()
svc = svm.SVC()
svc.fit(X, y)
print('Training accuracy = {0}%'.format(np.round(svc.score(X, y) * 100, 2)))
print('Test accuracy = {0}%'.format(np.round(svc.score(Xtest, ytest) * 100, 2)))














 1273
1273











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









