







集成学习
贝叶斯分析
原理
数理统计学处理的信息
总体信息:当前总体样本符合某种分布。比如抛硬币,二项分布。学生的某一科的成绩符合正态分布。
样本信息:通过抽样得到的部分样本的某种分布。
抽样信息=总体信息+样本信息
基于抽样信息进行统计推断的理论和方法称为经典统计学。
先验信息:抽样之前,有关推断问题中未知参数的一些信息,通常来自于经验或历史资料。
基于总体信息+样本信息+先验信息进行统计推断的方法和理论,称为贝叶斯统计学。
贝叶斯定理
贝叶斯定理告诉我们如何交换条件概率中的条件与结果,即如
果已知P(X|H),要求P(H|X),那么可以使用下面的计算方法:
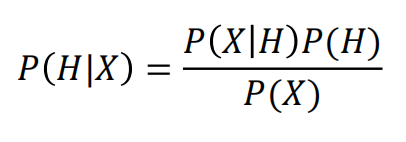

朴素贝叶斯(Naive Bayes)
假设:特征X1,X2,X3……之间都是相互独立的
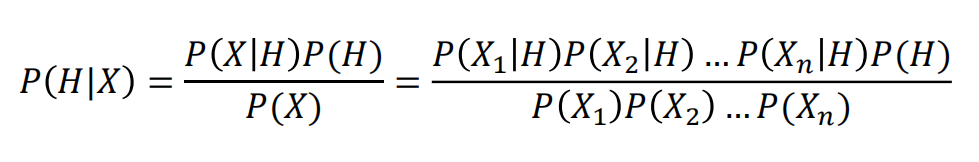
四个模型

高斯模型
有些特征可能是连续型变量,比如说人的身高,物体的长度,这些特征可以转换成离散型的值,比如如果身高在160cm以下,特征值为1;在160cm和170cm之间,特征值为2;在170cm之上,特征值为3。也可以这样转换,将身高转换为3个特征,分别是f1、f2、f3,如果身高是160cm以下,这三个特征的值分别是1、0、0,若身高在170cm之上,这三个特征的值分别是0、0、1。不过这些方式都不够细腻,高斯模型可以解决这个问题。
词袋模型(Bag of Words)


TF-IDF
提取词频(Term Frequency,缩写TF)。
“逆文档频率”(Inverse Document Frequency,缩写为
IDF)用统计学语言表达,就是在词频的基础上,要对每个词分配一个"重要性"权重。最常见的词(“的”、“是”、“在”)给予最小的权重,较常见的词(“中国”)给予较小的权重,较少见的词(“蜜蜂”、“养殖”)给予较大的权重。这个权重叫做"逆文档频率"(Inverse Document Frequency,缩写为IDF),它的大小与一个词的常见程度成反比。


算法实现
# 导入算法包以及数据集
import numpy as np
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report,confusion_matrix
from sklearn.naive_bayes import MultinomialNB,BernoulliNB,GaussianNB #朴素贝叶斯中多项式、伯努利、高斯模型
# 载入数据
iris = datasets.load_iris()
x_train,x_test,y_train,y_test = train_test_split(iris.data, iris.target)
mul_nb = GaussianNB()
mul_nb.fit(x_train,y_train)
print(classification_report(mul_nb.predict(x_test),y_test))
print(confusion_matrix(mul_nb.predict(x_test),y_test))

















 2158
2158











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









