







✅作者简介:热爱科研的Matlab仿真开发者,修心和技术同步精进,matlab项目合作可私信。
🍎个人主页:Matlab科研工作室
🍊个人信条:格物致知。
更多Matlab仿真内容点击👇
⛄ 内容介绍
在灰狼优化算法中, C是一个重要的参数,其功能是负责算法的勘探能力.目前,针对参数C的研究工作相对较少.另外,在算法进化过程中,群体中其他个体均向α,β和δ所在区域靠近以加快收敛速度.然而,算法易陷入局部最优.为解决以上问题,本文提出一种改进的灰狼优化算法(Lens imaging learning grey wolf optimizer algorithm, LIL-GWO).该算法首先分析了参数C的作用,提出一种新的参数C策略以平衡算法的勘探和开采能力;同时,分析了灰狼优化算法后期个体均向决策层区域聚集,从而导致群体多样性较差,提出一种基于光学透镜成像原理的反向学习策略以避免算法陷入局部最优.对LIL-GWO算法的收敛性进行了证明.选取12个通用的标准测试函数和30个CEC 2014测试函数进行实验,在相同的适应度函数评价次数条件下, LIL-GWO算法在总体性能上优于基本GWO算法,改进GWO算法和其他比较算法.最后,将LIL-GWO算法应用于辨识光伏模型的参数,获得了满意的结果.
⛄ 部分代码
%___________________________________________________________________%
% Grey Wolf Optimizer (GWO) source codes version 1.0 %
% %
% Developed in MATLAB R2011b(7.13) %
% %
% Author and programmer: Seyedali Mirjalili %
% %
% e-Mail: ali.mirjalili@gmail.com %
% seyedali.mirjalili@griffithuni.edu.au %
% %
% Homepage: http://www.alimirjalili.com %
% %
% Main paper: S. Mirjalili, S. M. Mirjalili, A. Lewis %
% Grey Wolf Optimizer, Advances in Engineering %
% Software , in press, %
% DOI: 10.1016/j.advengsoft.2013.12.007 %
% %
%___________________________________________________________________%
% Grey Wolf Optimizer
function [Alpha_score,Alpha_pos,Convergence_curve]=GWO(SearchAgents_no,Max_iter,lb,ub,dim,fobj)
% initialize alpha, beta, and delta_pos
Alpha_pos=zeros(1,dim);
Alpha_score=inf; %change this to -inf for maximization problems
Beta_pos=zeros(1,dim);
Beta_score=inf; %change this to -inf for maximization problems
Delta_pos=zeros(1,dim);
Delta_score=inf; %change this to -inf for maximization problems
%Initialize the positions of search agents
Positions=initialization(SearchAgents_no,dim,ub,lb);
Convergence_curve=zeros(1,Max_iter);
l=0;% Loop counter
% Main loop
while l<Max_iter
for i=1:size(Positions,1)
% Return back the search agents that go beyond the boundaries of the search space
Flag4ub=Positions(i,:)>ub;
Flag4lb=Positions(i,:)<lb;
Positions(i,:)=(Positions(i,:).*(~(Flag4ub+Flag4lb)))+ub.*Flag4ub+lb.*Flag4lb;
% Calculate objective function for each search agent
fitness=fobj(Positions(i,:));
% Update Alpha, Beta, and Delta
if fitness<Alpha_score
Alpha_score=fitness; % Update alpha
Alpha_pos=Positions(i,:);
end
if fitness>Alpha_score && fitness<Beta_score
Beta_score=fitness; % Update beta
Beta_pos=Positions(i,:);
end
if fitness>Alpha_score && fitness>Beta_score && fitness<Delta_score
Delta_score=fitness; % Update delta
Delta_pos=Positions(i,:);
end
end
a=2-l*((2)/Max_iter); % a decreases linearly fron 2 to 0
% Update the Position of search agents including omegas
for i=1:size(Positions,1)
for j=1:size(Positions,2)
r1=rand(); % r1 is a random number in [0,1]
r2=rand(); % r2 is a random number in [0,1]
A1=2*a*r1-a; % Equation (3.3)
C1=2*r2; % Equation (3.4)
D_alpha=abs(C1*Alpha_pos(j)-Positions(i,j)); % Equation (3.5)-part 1
X1=Alpha_pos(j)-A1*D_alpha; % Equation (3.6)-part 1
r1=rand();
r2=rand();
A2=2*a*r1-a; % Equation (3.3)
C2=2*r2; % Equation (3.4)
D_beta=abs(C2*Beta_pos(j)-Positions(i,j)); % Equation (3.5)-part 2
X2=Beta_pos(j)-A2*D_beta; % Equation (3.6)-part 2
r1=rand();
r2=rand();
A3=2*a*r1-a; % Equation (3.3)
C3=2*r2; % Equation (3.4)
D_delta=abs(C3*Delta_pos(j)-Positions(i,j)); % Equation (3.5)-part 3
X3=Delta_pos(j)-A3*D_delta; % Equation (3.5)-part 3
Positions(i,j)=(X1+X2+X3)/3;% Equation (3.7)
end
end
l=l+1;
Convergence_curve(l)=Alpha_score;
end
⛄ 运行结果
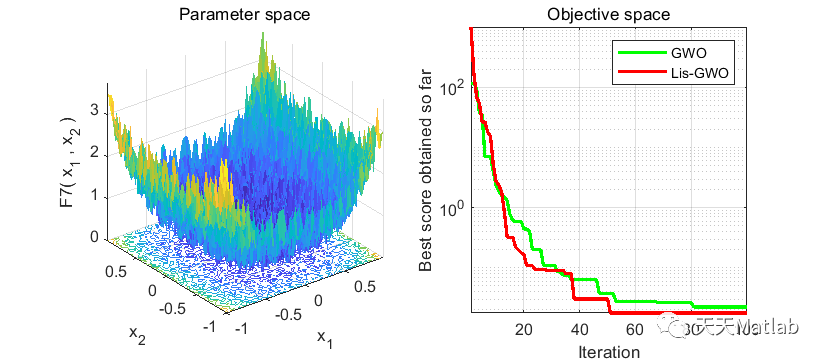

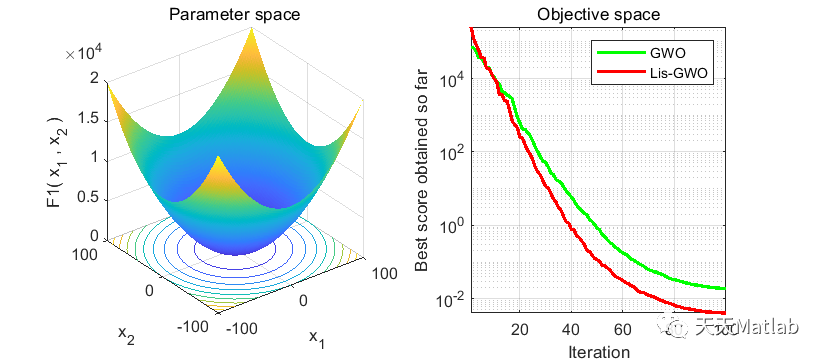
⛄ 参考文献
[1]龙文、伍铁斌、唐明珠、徐明、蔡绍洪. "基于透镜成像学习策略的灰狼优化算法." 自动化学报 46.10(2020):17.
❤️ 关注我领取海量matlab电子书和数学建模资料
❤️部分理论引用网络文献,若有侵权联系博主删除
















 423
423











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











