







概述
Mask R-CNN 扩展了 Faster R-CNN,为同时进行物体检测和高质量分割提供了框架。它易于训练,运行速度快,适用于其他任务,在 COCO 套件的不同赛道上都取得了优异成绩,即使没有额外的特征,也比其他模型更胜一筹。作为一种简单有效的方法,它为未来的研究奠定了基础。
导言

如上所述,Mask R-CNN 是一种有效而灵活的框架,可同时进行物体检测和高质量分割。它在现有的 Faster R-CNN 基础上增加了一个掩膜预测分支,一个名为 RoIAlign 的新层提供了精确定位。 Mask R-CNN 运行简单、快速,在 COCO 分割任务中表现优于传统模型、在物体检测方面也表现出色。它既灵活又准确,是未来研究和扩展复杂任务的理想框架。
相关研究
基于区域的 CNN(R-CNN)方法,如 Faster R-CNN,已在物体检测中发展出灵活而强大的性能。在实例分割方面,传统方法面临耗时长、准确率低的挑战,而最新的 Mask R-CNN 可同时预测分割和类别标签,以简单灵活的方法实现高性能结果。在分割优先级策略方面,与其他方法不同的是,它采用了实例优先策略,这也是未来有望发展的方向。
屏蔽 R-CNN
掩码 R-CNN 为快速 R-CNN 增加了一个对象掩码输出分支,它可以同时预测对象掩码以及每个候选对象的类别标签和边界框偏移。这种概念简单的方法主要有助于提取详细的空间布局,如像素之间的对齐,而这正是传统方法所缺乏的。
更快的 R-CNN
快速 R-CNN 包括两个阶段。在第一阶段,区域命题网络(RPN)为候选对象提出边界框;在第二阶段,快速 R-CNN 从这些边界框中提取特征,并执行分类和边界框回归。共享特征用于加快推理速度。
掩码 R-CNN
掩码 R-CNN 采用与 Faster R-CNN 相同的初始阶段(RPN),第二阶段为每个 RoI 生成二进制掩码以及类别和箱偏移预测。与普通系统不同的是,类别预测和掩码生成是分开的,因此在训练过程中生成每个类别的掩码时不会发生冲突。这确保了出色的实例分割。
面具表达
遮罩表示物体的空间排列。与普通的 fc 图层不同,遮罩通过卷积保持像素之间的对应关系,自然地捕捉空间结构。与传统方法相比,它的参数更少,精度更高。为了支持这种像素到像素的行为,作者引入了 RoIAlign 层,以实现更准确、参数更少的遮罩预测。
对齐

RoIPool 在提取每个 RoI 的小特征图时通常会使用量化技术。然而,这种量化会影响每个像素的掩码预测。提议的 RoIAlign 图层避免了量化,并使用双线性插值来计算精确的特征值,从而可以进行精细的掩码预测 RoIAlign 比 RoIPool 有了显著的改进。
网络架构
作者在不同的架构上实现了掩码 R-CNN,并区分了卷积骨干和网络头:除了 ResNet-50 和 ResNeXt 等骨干外,还采用了特征金字塔网络(FPN),FPN 骨干提高了准确性和速度。网络头扩展了卷积掩码预测分支,ResNet-C4 主干网的头包含 ResNet 的第五级,而 FPN 的头效率更高。
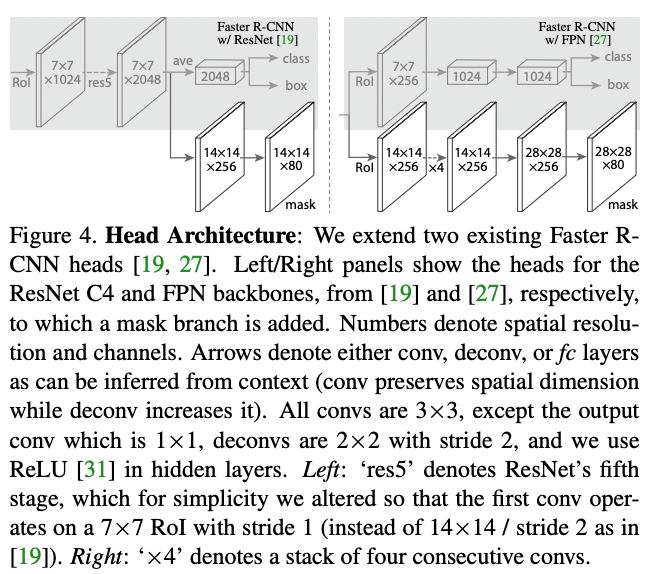 ・实施细节
・实施细节
作者根据快速/更快 R-CNN 研究设置了超参数,并使用以图像为中心的训练和适当的采样率对模型进行了训练。在训练过程中,当 IoU 大于 0.5 时,RoI 被定义为正值,只有当 RoI 为正值时,掩码损失才被定义为正值。在推理过程中,对建议的数量和掩码的处理进行了优化,以实现快速准确的检测。
实例分割
在 COCO 数据集上对屏蔽 R-CNN 和其他最先进的技术进行了全面比较,并用标准指标(AP、AP50、AP75、APS、APM、APL 等)进行了评估。报告中使用了 80,000 张训练图像和 35,000 个子集进行训练,并使用 5,000 张验证图像进行消融。结果也以测试版本报告。
主要成果

在表 1 中,Mask R-CNN 与最先进的实例分割方法进行了比较,表明使用 ResNet-101-FPN 骨干的 Mask R-CNN 优于其他模型。表 1 还显示了一个可视化结果实例,凸显了 Mask R-CNN 在具有挑战性的条件下表现更佳,而且与其他方法相比,其伪影更少。


消融实验
对掩膜 R-CNN 进行了多次消融分析。 结果如表 2 所示,接下来将详细介绍。

建筑
表 2(a) 对具有不同骨干网的掩码 R-CNN 进行了比较。表 2(a) 对采用不同骨干网的掩码 R-CNN 进行了比较,突出显示了更深的网络和先进的设计(如 FPN 和 ResNeXt)有助于提高性能,但也指出了并非所有框架都能从这些元素中获得同样的好处。

多项式和独立掩码
掩码 R-CNN 将方框预测和类别预测分离开来,为每个类别生成一个掩码,而不会产生冲突,因为现有的方框分支会预测类别标签。 表 2(b) 将这种方法与每像素 softmax 和多项式损失进行了比较。在另一种方法中,掩码和类别预测任务是结合在一起的,这就降低了掩码的性能。这意味着,一旦实例被整体分类,只需预测二进制掩码即可,无需担心类别问题,从而使训练变得更容易。
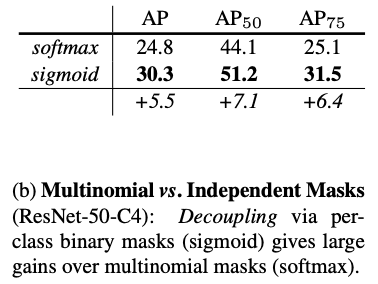
特定类别和独立于类别的掩码
在正常实例化中,每个类别预测一个 m×m 掩码。有趣的是,使用类别感知掩码的掩码 R-CNN (即预测独立于类别的单个 m×m 输出)具有几乎相同的效果。在这种将分类和分割明显分开的方法中,特定类别的对应关系为 30.3,而普通掩码 AP 的对应关系为 29.7,这表明了对分工的重视。
对齐
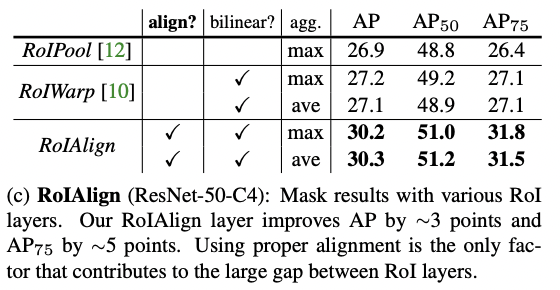
表 2© 显示了对作者提出的 RoIAlign 层的评估。在该实验中,使用步长为 16 的 ResNet50-C4 主干网,RoIAlign 比 RoIPool 的 AP 提高了约 3 个百分点,其优势主要体现在更高的 IoU(AP75)上。 RoIAlign 不受最大/平均池化的影响,与同样使用双线性采样的 RoIWarp 相比也毫不逊色。此外,使用 ResNet-50-C5 主干网和大跨度的 RoIAlign 也经过了评估,结果表明它能显著改善掩码 AP,使用大跨度特征能提高检测和分割精度。

最后,RoIAlign 与 FPN 结合使用时,利用更精细的多级步长,光罩 AP 和方框 AP 分别提高了 1.5 点和 0.5 点。即使使用 FPN,RoIAlign 也能显著提高精度,尤其是在需要精细对齐的情况下,如关键点检测(表 6)。

掩膜分支
分割是一项像素到像素的任务,使用 ResNet-50-FPN 主干网来比较多层感知器 (MLP) 和全卷积网络 (FCN)。 与 MLP 相比,使用 FCN 可将掩码 AP 提高 2.1 个点。 为进行公平比较,FCN 头的卷积层在该骨干网中未进行预训练(表 2e)。
 ・边界框检测结果
・边界框检测结果

在表 3 中,Mask R-CNN 与最先进的 COCO 边框物体检测进行了比较;带有 ResNet-101-FPN 和 ResNeXt-101-FPN 的 Mask R-CNN 优于之前的最先进模型,尤其是 ResNeXt-101-。与之前的最佳单一模型相比,FPN 实现了 3.0 分的方框 AP 改进。此外,带有 RoIAlign 的遮蔽 R-CNN 也优于不带 RoIAlign 的模型,尽管在方框检测方面存在微小差距。这些结果表明,作者的方法有效地弥合了物体检测和实例分割之间的难度差异。
时间安排
在推理方面,ResNet-101-FPN 模型遵循 Faster R-CNN 训练步骤并共享特征。该模型速度很快,在 Nvidia Tesla M40 GPU 上运行约 195 毫秒。ResNet-50-FPN 用时 32 小时,ResNet-101-FPN 用时 44 小时。作者希望这种快速训练能促进研究,帮助更多的人涉足这一领域。
用于人体姿态估计的掩码 R-CNN
作者的框架也适用于人体姿态估计。使用 Mask R-CNN 预测每个关键点的位置时,使用的是单点掩码。实验证明了 Mask R-CNN 框架的灵活性,并且只需最低限度的领域知识。关键点训练为每个关键点使用单次二元掩码,以尽量减少软最大输出的交叉熵损失。模型在 COCO trainval35k 图像上进行训练,推理使用 800 像素的单一比例。
主要结果和消融
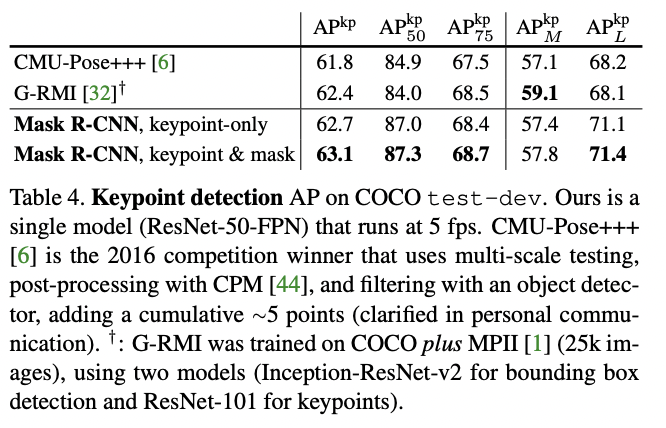
作者评估了人关键点检测的性能,并在 ResNet-50-FPN 骨干网上进行了实验。结果表明,作者的方法实现了 62.7 的 APkp,比 COCO 2016 关键点检测优胜者高出 0.9 分,是一种简单而快速的方法。此外,它还能同时预测盒、段和关键点,增加段分支后,APkp 提高到了 63.1。
在只检测方框或只检测关键点的版本中添加掩码分支会改善这些任务,而添加关键点分支则会略微降低方框/掩码 AP 的效果。这表明,虽然关键点检测可以从多任务训练中获益,但对其他任务却没有影响。尽管如此,同时对所有三个任务进行训练可以使集成系统同时有效地预测所有输出结果。

此外,还研究了 RoIAlign 对关键点检测的影响(表 6)。
虽然 ResNet-50-FPN 主干网的步幅较小,但 RoIAlign 的表现仍优于 RoIPool,其关键点检测的 APkp 提高了 4.4 点。这表明,关键点检测对高定位精度非常敏感,预计 Mask R-CNN 是对象边界框、遮罩和关键点提取的有效框架。
结论
Mask R-CNN 适用于复杂任务,因为它既能进行像素级分割,又能进行物体定位。该方法可同时执行检测、分割和关键点估算,在各种应用中表现出色。在人工智能领域,它是对物体识别和分割的发展做出贡献的模型范例,在现实世界的计算机视觉任务中表现出色。
掩膜 R-CNN 成功地集成了物体检测和分割功能,并在各种应用中表现出卓越的性能。未来,它有望提高模型和实时处理的效率。同时,重要的是要开发出对领域适应和使用较少标签进行训练具有鲁棒性的模型。物体检测技术的进步有望在自动驾驶汽车、医学图像分析和环境监测等多个领域得到实际应用。
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











