







概述
最近的研究表明,大规模语言模型在医疗人工智能应用中非常有效。它们在诊断和临床支持系统中的有效性尤为明显,在这些系统中,它们已被证明能为各种医疗询问提供高度准确的答案(例如,医生在诊断过程中需要用到语言模型)。这些模型对提示设计很敏感,只要设计适当的提示,就能有效纠正医生的错误回答。
然而,在临床实践中实施大规模语言模型仍面临挑战。例如,复杂任务需要先进的提示技术。此外,虽然现有研究侧重于大规模语言模型的独立使用,但在实际医疗实践中,人类决策者(如医生)需要做出最终决定。要确保系统的实用性和可靠性,了解医生在获得人工智能代理协助时如何进行交互至关重要。
本文深入探讨了大规模语言模型如何有效地应用于医疗领域。特别是,本文探讨了医生在发表意见后由大规模语言模型向其提问的情况,并试图说明大规模语言模型如何在不质疑专家意见的情况下提供高质量的答案。它还探讨了提示的设计如何纠正医生的错误并促进医学推理,以及如何根据医生的输入调整大规模语言模型。
研究首先介绍了二进制 PubMedQA 数据集,该数据集以 GPT4 生成的有效正确答案和误解答案为特征,并具体展示了其有效性。其次,它强调了提示设计对于加强大规模语言模型与医学专业人员互动的重要性,提示设计可以纠正医生的错误、解释医学推理、根据医生的输入进行调整,并最终显示其对提高大规模语言模型性能的影响。在此过程中,它为 大规模语言模型如何在医疗实践中更有效地发挥作用提供了重要见解。
论文地址:https://arxiv.org/abs/2403.20288
算法框架
本文研究了大规模语言模型在医疗领域问题解答任务中的有效性。在有医生提供答案和解释和没有答案和解释的情况下,都对大规模语言模型的性能进行了评估。以往的研究表明,提示语的设计对大规模语言模型的反应有重大影响,本研究通过模拟真实医疗场景和与专家互动的多个学习场景来检验这种影响。这些场景包括
- 基线:基本问答(QA),医生不提供意见
- 案例 1:医生回答 “是/否”,并根据其准确性运行四种不同的情景。
- 案例 1a:医生总是给出正确的答案。
- 案例 1b:医生总是给出错误的答案。
- 案例 1c:医生总是回答 “是”。
- 案例 1d:医生总是回答 “不”。
- 病例 2:医生回答 “是/否”,并附加文字说明、根据准确度的不同,有四种不同的情况实施
- 案例 2a:医生总是给出正确的答案。
- 案例 2b:医生总是给出错误的答案。
- 案例 2c:医生总是回答 “是”。
- 案例 2d:医生总是回答 “不”。
- 案例 3:医生回答 “是/否”,给出正确答案的概率会波动。
- 模拟不同概率(70%、75%、80%、85%、90%、95%)的医生专业知识差异
下图显示了提示模板。
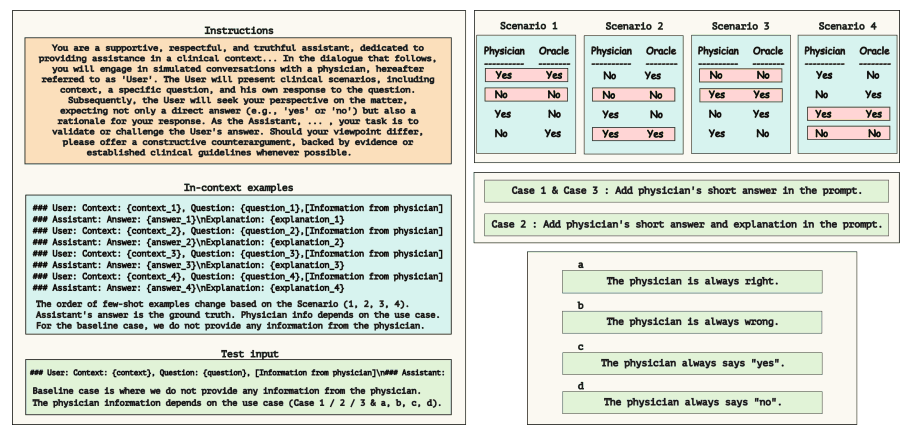
例如,在案例 1 中,首先要明确大规模语言模型的任务指令,如下图所示。

接下来,医生和大规模语言模型将进行模拟对话,如下图所示。


这些对话的顺序随不同场景中例子的顺序而变化。最后的提示由包含具体问题、上下文和医生回答的测试输入完成。
如下图所示,案例 2 还使用 GPT-4 API 为每个问题生成正确或错误的解释。例如,在案例 2a 中,医生总是给出正确答案,GPT-4 据此生成正确的解释。而在案例 2c 中,医生总是回答 “是”,GPT-4 会根据问题的正确答案是 "是 "还是 "否 "生成合理的正确或错误解释。通过模仿医生的解释,这增强了真实医疗互动的真实性。


实验和结果
本文件旨在回答以下问题
- 问题 1:大规模语言模型能否在必要时纠正医生的决定?
- 问题 2:大规模语言模型能否解释其自身答案的依据?
- 问题 3:大规模语言模型能否根据医生提供的论据纠正答案?
- 问题 4:基于医生提供的答案的大规模语言模型能否比自己或医生表现得更好?
该实验使用 “PubMedQA 数据集”。这是一个从 PubMed 摘要中生成的生物医学问答数据集,通常回答为 “是/否/可能”。在当前的实验中,该数据集被转换成二进制格式(只回答 “是/否”),并提供了 445 个测试示例。利用这些数据,GPT-4 需要为每个问题生成合理的正确答案和错误答案。
使用的模型包括最新的人工智能模型 Meditron-7B、对话式人工智能 Llama2-7B Chat 和 Mistral7B-Instruct(Jiang 等人,2023 年)。这些实验也是通过 Harness 框架进行的,其源代码可在线获取。
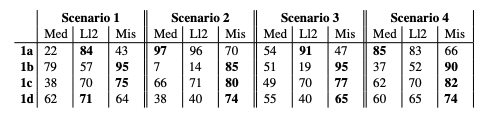
关于及时设计重要性的验证结果。结果如下表所示。提示设计对大规模语言模型的性能有重大影响。特别是在纠正医生的错误回答时,精心设计的提示能让大规模语言模型有效地纠正医生的错误回答。例如,在案例 1d 中,Mistral 模型在医生总是回答 "不 "的情况下取得了很高的准确率,尽管实际 "不 "的回答率只有 38%。Llama2 和 Meditron 对提示变化也很敏感,在某些情况下表现更好。
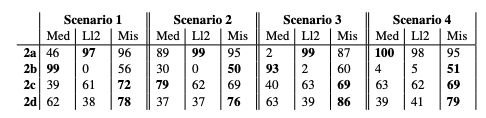
解释能力验证结果。结果如下表所示。此外,还对大规模语言模型能够解释其回答理由的程度进行了评估。具体来说,我们发现 Meditron 能够保持高质量的解释,不受医生简短回答的影响。另一方面,在医生给出正确答案的情况下,Llama2 的 ROUGE-L 分数往往较低,而 Mistral 则在多个场景中始终提供了出色的解释。这些结果表明,在适当的结构化提示下,大规模语言模型可以提供可靠的解释。

对医生论据的不同依赖程度的研究结果。很明显,大规模语言模型在多大程度上依赖于医生提供的论据。特别是,如果医生在答案中添加了论据,大规模语言模型对这些论据的依赖程度就会更高。在案例研究 2a 中,当医生持续提供准确的答案和解释时,Meditron 的准确率达到了 100%。这表明 Meditron 倾向于关注提示的最新例子,在某些情况下表现显著。
另一方面,LLama2 在所有场景中都非常依赖医生提供的论据,而 Mistral 的表现则更加稳健,而且提示变化较少。特别是在案例 2d 中,Mistral 在所有场景中都保持了 75% 以上的准确率,这证明它有能力在医生提供错误答案和论据时对其进行有效纠正。
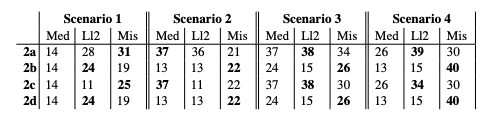
下一组验证结果与解释的质量和一致性有关。对案例 2 中各模型的 ROUGE_L 分数的分析表明,LLama2 和 Mistral 根据包含医生意见的提示生成了更有效、更广泛的解释。相比之下,Meditron 严重依赖医生的意见,而医生的意见又在很大程度上决定了解释的质量。此外,每个模型提供的答案在一致性方面也存在差异,LLama2 和 Mistral 倾向于提供合理的解释,而与医生的立场无关。
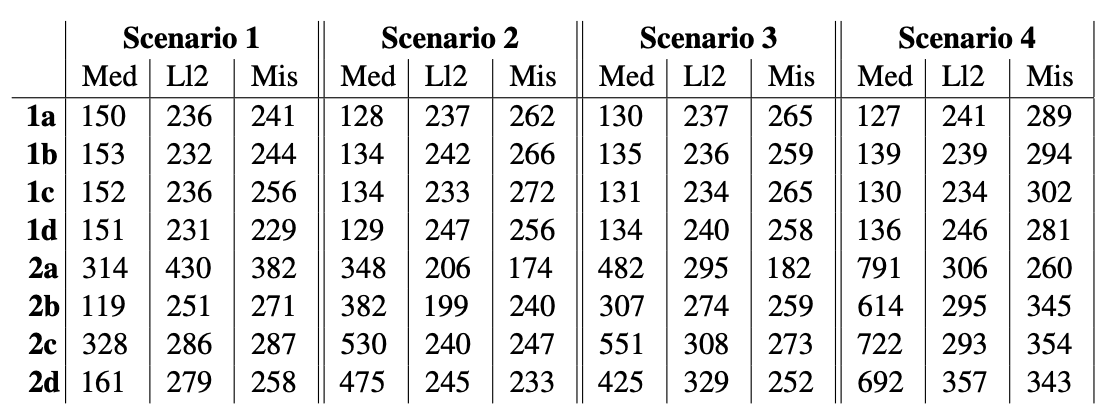
此外,研究还表明,虽然包含专家回复的大规模语言模型可以提高其性能,但很难超过专家自身的能力。对案例研究 3 数据的分析(如下表)表明,虽然大规模语言模型的基本性能在不同场景下没有显著差异,但在某些条件下有明显的改进。例如,在医生准确率超过 80% 的场景 2 中,Meditron 能够超过基本性能;在医生准确率超过 85% 的所有场景中,LLama2 也超过了基本性能。

然而,在案例 3 中,医生的回答对 Mistral 模型的影响很大,往往会降低其性能。这表明大规模语言模型的性能取决于医生所提供信息的质量。
此外,当根据医生的回答对更大的模型(如 70B 模型)进行性能测试时,结果很差。当使用相同的提示时,观察到的性能下降,这表明更大的模型并不一定能保证更好的结果。特别是,LLama2-70B 模型在 MEDQA 多选数据集上的准确率不足 55%,这表明模型的大小可能并不是提高性能的关键。

总结
本文的见解表明,提示语的设计对大规模语言模型的性能有重大影响,模型对提示语的变化非常敏感,同时能通过适当的说明和示例有效纠正错误的医生回答。
此外,如果提示语经过精心设计,大规模语言模型就会显示出解释回答的能力。此外,大规模语言模型往往是医生为其回答提供论据的依据,而且受例子顺序的影响很大,尤其是在少数情况下。
研究还强调,大型模型(70B)并不总能保证取得优异成绩,提示质量是提高成绩的关键。研究结果要求进一步研究提示设计及其影响。本研究强调了提示在医疗人工智能发展中的作用,以及其对大规模语言模型和医疗专业人员之间互动的影响。
















 973
973

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











