







导言
论文地址:https://arxiv.org/abs/2403.06738
源码地址:https://github.com/heheyas/V3D.git
人工智能的最新进展使得自动生成 3D 内容的技术成为可能。虽然这一领域取得了重大进展,但目前的方法仍面临一些挑战。有些方法速度较慢,产生的结果也不一致,还有一些方法需要在大型 3D 数据集上进行训练,从而限制了高质量图像数据的使用。
这篇评论文章的重点是利用视频扩散模型生成 3D 内容。视频扩散模型是生成详细、一致的视频场景的典型模型。由于许多视频都会从不同角度捕捉物体,因此这些模型有助于理解三维世界。
本文提出了一种名为 V3D 的新方法,它利用视频扩散模型生成物体或场景的多个视点,并根据这些视点重建三维数据。这种方法既适用于单个物体,也适用于大型场景。
在生成3D物体时,使用 360° 旋转的 3D 物体视频来训练模型,以提高准确性。此外,还引入了新的损失和模型结构,以提高生成视点的一致性和质量。
此外,为了使该方法在实际应用中切实可行,还提出了一种根据生成的数据创建三维网格的方法。该方法还扩展到支持场景级三维生成,实现了精确的摄像机路径控制和多输入视点处理。
广泛的实验,包括定性和定量评估,证明了所提出方法的卓越性能。特别是在生成质量和多视角一致性方面,它明显优于以往的研究。预计所提出的方法将克服当前三维生成技术的局限性,为基于人工智能的三维内容生成开辟新的可能性。
算法架构
概述
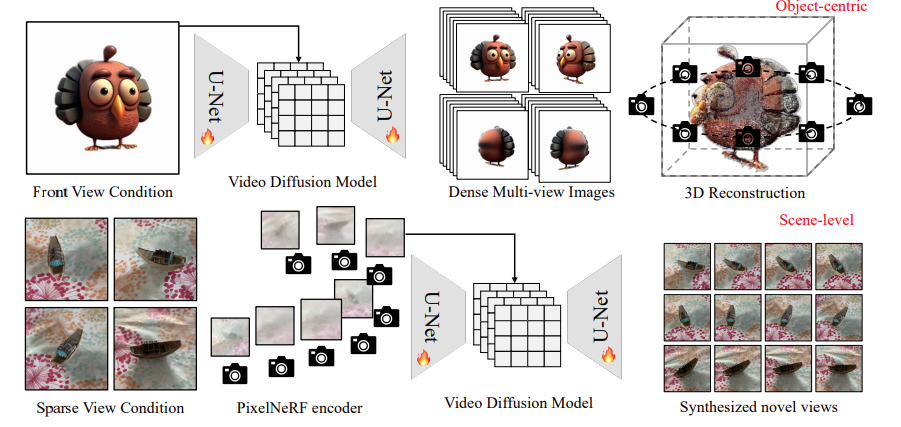
图 1:V3D 概述。
如图 1 所示,V3D 利用视频生成模型,通过利用预先训练的大型视频扩散模型的结构和强大的先验知识,促进一致的多视角生成。
为了从物体图像生成三维图像,利用在固定圆形摄像机位置绘制的合成三维物体的 360° 轨道视频对基础视频扩散模型进行了微调,并提出了适合生成的多视角的重建和网格提取管道。
场景级 3D 生成将 PixelNeRF 编码器纳入基础视频扩散模型,以精确控制生成帧的摄像机位置,使其能够无缝适应任意数量的输入图像。详情如下
根据目标物体的图像生成 360 度视图
为了从单一视角生成多视角图像,V3D 将围绕物体旋转的连续多视角图像解释为视频,并将以正面观看为条件的多视角生成视为一种图像到视频的生成形式。这种方法利用了大规模预训练视频扩散模型提供的对三维世界的全面理解,并解决了缺乏三维数据的问题。它还利用视频扩散模型固有的网络结构,有效生成足够数量的多视角图像。
具体来说,稳定视频扩散(SVD, Blattmann 等人,2023 年)是视频生成的一个代表性模型,在 Objaverse 数据集上进行了微调。为了增强图像到 3D 的适应性,删除了运动桶 ID 和 FPS ID 等无关条件,并使其与高度角无关。取而代之的是,物体被随机旋转,以使生成的模型能够响应非零高度的输入。
稳健的三维重建和网格提取
-三维重建使用微调视频扩散模型获取物体周围的图像后,下一步就是将其重建为三维模型。3D 高斯拼接技术(Kerblet.al, 2023 年)可用于此任务。
确保视图之间每个像素的一致性非常困难,而且会导致三维重建中出现伪影。为了解决这个问题,我们采用了逐像素损失 MSE 的方法。此外,还引入了图像级感知损失和相似性损失,以防止因 MSE 而导致纹理浮动或模糊。最终的损失定义为
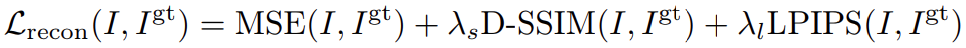
-网格提取为满足实际应用的要求,我们还提出了一个生成视图的网格提取管道。为实现快速曲面重建,采用了使用多分辨率哈希网格的 NeuS(Wang etl.al,2021 年);V3D 使用法线平滑损失和稀疏正则化损失来改进几何形状,从而生成比通常 NeuS 使用情况更少的视图。V3D 使用以下方法改进几何图形。
为改善因生成的图像不一致而导致的纹理模糊,在生成的多视图中使用 LPIPS loss 对纹理进行细化,而几何图形保持不变。通过高效的可微分网格渲染,这一过程可在 15 秒内完成,从而提高最终输出的质量。
扩展到场景级 3D 生成
与对象视图生成不同,场景级 3D 生成需要沿着摄像机的路径生成图像,这就要求精确控制摄像机的方向,并适应多个输入图像。
为了应对这一挑战并保持一致性,V3D将PixelNeRF特征编码器集成到视频扩散模型中,如图 1 底部所示。
这种方法可以无缝支持任意数量的图像。模型的其他设置和结构与以对象为中心的生成类似。
试验
以对象为中心的 3D 生成

图 2:在图像到 3D 任务中与以往研究结果的比较。
本节将评估拟议的 V3D 在图像到 3D 转换中的性能,并描述与其他方法的比较结果。在图 2 的上半部分,V3D 比基于 3DGS 的 TriplaneGaussian 和 LGM 显示出更好的质量。这些方法由于生成的高斯数量有限,会产生模糊的外观。
在图 2 的底部,V3D 在前视图一致性和保真度方面优于基于 SDS 的最新 Magic123 和 ImageDream,Magic123 会产生几何形状不准确和模糊的后视图,而 ImageDream 则会产生过度饱和的纹理。所提出的方法可在不到三分钟的时间内获得结果,速度明显快于基于优化的方法。
同时,还对生成的 3D 物体进行了人体评估研究。具体来说,58 名志愿者被要求在观看根据 30 幅条件图像渲染的 360° 螺旋视频时,对 V3D 和其他方法生成的物体进行评价。两个评价标准是
- (a) 一致性:三维资产与条件图像的匹配程度。
- (b) 保真度:生成物体的逼真程度。
表 1 显示了每种方法在这两个标准上的胜率。
总体而言,V3D 被评为最有说服力的模型,在图像一致性和保真度方面都明显优于其他竞争方法。
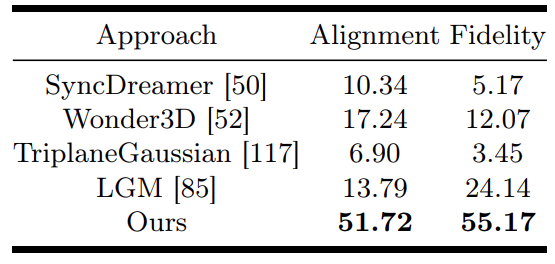
表 1.人类评估结果
场景级 3D 生成
在 CO3D 数据集的 10 个类别子集上测试了提议的 V3D 在场景级 3D 生成中的性能。在每个视频类别中,只对 V3D 的一个历元进行了微调,以便与之前研究中的设置相匹配。
结果见表 2。
所提出的方法在图像指标方面始终优于以往的研究,证明了使用预训练视频扩散模型进行场景级 3D 生成的有效性。零镜头版本的 V3D(完全在 MVImgNet 上训练)也优于之前的大多数研究。
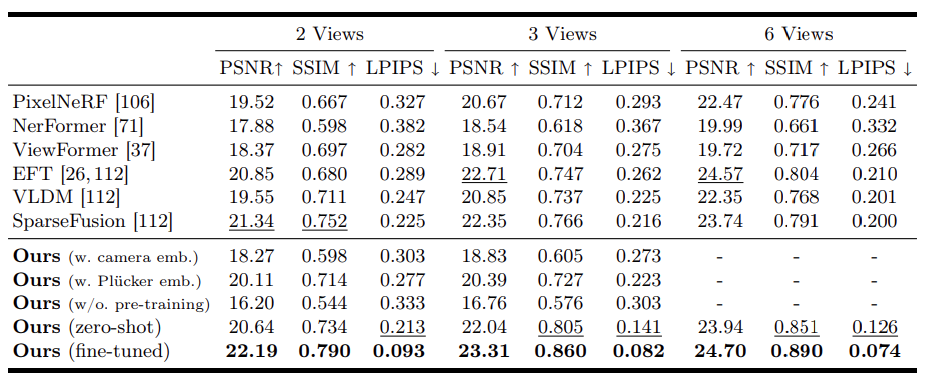
表 2. 与之前 CO3D 研究的比较结果
图 3 显示了 SparseFusion 和 V3D 在 CO3D 数据集的消防栓子集中生成的多视图的定性比较。为了进行更详细的比较,我们在 COLMAP 中使用相机姿态进行了多视角立体重建,图 3 显示了生成的点云中的点数以及与真实图像重建的点云之间的倒角距离。
结果表明,由 V3D 生成的图像重建的点云包含更多的点,而且更接近于由真实图像重建的点云。换句话说,无论是在重建质量还是多视角一致性方面,拟议方法都具有显著优势。

图 3. CO3D 中的定性评估。
总结
本文介绍了 V3D,它能从单张图像生成 3D 物体。
V3D 利用视频生成模型,利用大型预训练视频扩散模型的结构和丰富的先验知识,实现一致的多视角生成。此外,还提出了一种新的重建管道和学习损失,以实现一致且高精度的三维物体重建。
通过广泛的定性、定量和人工评估,证明了所提出方法的卓越性能。特别是在生成质量和多视角一致性方面,它明显优于以往的研究。所提出的方法有望突破当前三维生成技术的限制,为基于人工智能的三维内容生成开辟新的可能性。



















 3745
3745

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











